

C语言面试题详解第18节
source link: https://blog.popkx.com/interview-questions-in-c-language-section-18/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

上一节讨论了有趣的“迷宫问题”,我们一起基于栈这种数据结构编写C语言程序,找到了从迷宫起点到迷宫终点的路线。
深度优先和广度优先
现在回想上一节的内容,应该能够发现,因为数据结构栈“先进后出”的特性,C语言程序在寻找迷宫终点的过程中,遇到分岔口时,总是先把所有可能的路线做好记号,然后一条一条试,遇到死路就原路回到分岔口试其他的岔路。这种搜索路径的方法叫作“深度优先法”,“深度优先法”优先选择其中一条路径,不走到迷宫最深处就不会回头。
在现实中,“深度优先搜索法”非常适合一个人使用,因为一个人不可能同时走多条路线,遇到分岔路时,只能一条一条的试。假设小明挑战迷宫时迷路了,在迷宫中待的时间超过了他与同学们约定的时间,所以同学们决定一起进迷宫找小明。

因为是找人,所以每个同学都带了迷宫地图,只要有一个同学找到小明,任务就算完成了。这种情况下,再使用“深度搜索法”就非常不合适了,想想也是,要是那么多同学都挤在一起,一条一条路的搜索,效率就太低下了,没有发挥人数多的优势。
假如小明的同学数目很多,在遇到分岔路时,可以每个岔路都分配一些同学搜索,这样肯定比同学们挤在一起,使用“深度优先搜索法”效率高。事实上,这种不放过任一岔路的搜索方法,常被称作“广度优先搜索法”。事实上,“广度优先搜索法”和“深度优先搜索法”常常是一起作为面试题出现的,它们也是解决一类问题的两种思路,所以,我们对这两种方法都应该有所了解。
那么,使用C语言该怎样实现“广度优先搜索法”呢?请继续往下看。
广度优先搜索法的C语言代码实现
按照上一节的讨论,在设计C语言算法之前,应该根据实际需求设计合适的数据结构,那什么样的数据结构适合处理“广度优先搜索法”呢?
再来看一下问题,请注意这两句话:“只要有一个同学找到小明,任务就算完成了。”“可以每个岔路都分配一些同学搜索”,很明显,广度优先搜索法是不会走回头路的,换句话就是走过的路不会再走第二遍,每个同学下一步要走的就是眼前的路,走过之后就不用再关心回头路了(找到小明之前)。显然,C语言中的队列非常适合处理这种需求。

队列在某种程度上和栈有些相似,它也是一组元素的集合,也只有两种基本操作:入队和出队。入队将元素排到队列的尾部,出队则是从队列的头部取出元素。就很像排队买票一样,后排队的人要排在队伍后面,先排队的人先被售票员服务。队列这种“先进先出”的特性,和栈“后进先出”的特性恰恰是相反的。
小明是个调皮鬼,他躲在出口等同学们找。那该如何编写C语言程序,实现“广度优先搜索法”呢?首先应该把队列的出队和入队操作实现,相关C语言代码如下,请看:
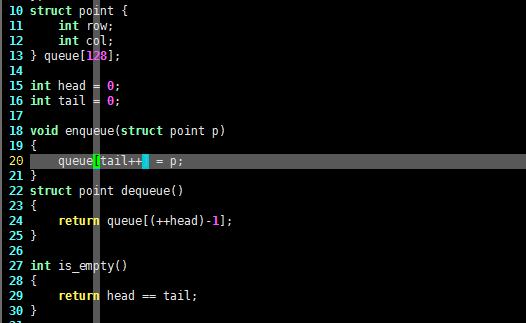
struct point {
int row;
int col;
} queue[128];
int head = 0;
int tail = 0;
和上一节一样,上面的C语言代码首先定义了 point 结构体用于描述迷宫的坐标,并且定义了 head 和 tail 分别指向队列的头部和尾部,这一点和栈不同,栈只需要一个指向栈顶的 top 就可以了。定义好了队列和首尾指针,就可以实现队列的“入队”和“出队”操作了,相关C语言代码如下,请看:
void enqueue(struct point p)
{
queue[tail++] = p;
}
struct point dequeue()
{
return queue[(++head)-1];
}
判断栈是否空,可以检查 top 是否为 0(即指向栈底)。判断队列是否空,可以判断是否 head 与 tail 相等,因此 is_empty() 的C语言代码可以如下定义,请看:
int is_empty()
{
return head == tail;
}
假设小明走的迷宫和上一节提到的迷宫一样,那么搜索的每一步 walk() 函数可以如下定义:
int walk(struct point p)
{
struct point next_pos;
if(4==p.row && 4==p.col)
return 1;
if(p.col+1 < 5 && 'o'==maze[p.row][p.col+1]){
next_pos.row = p.row;
next_pos.col = p.col+1;
maze[next_pos.row][next_pos.col] = '*';
enqueue(next_pos);
}
if(p.row+1 < 5 && 'o'==maze[p.row+1][p.col]){
next_pos.row = p.row+1;
next_pos.col = p.col;
maze[next_pos.row][next_pos.col] = '*';
enqueue(next_pos);
}
if(p.col-1 >=0 && 'o'==maze[p.row][p.col-1]){
next_pos.row = p.row;
next_pos.col = p.col-1;
maze[next_pos.row][next_pos.col] = '*';
enqueue(next_pos);
}
if(p.row-1 >= 0 && 'o'==maze[p.row-1][p.col]){
next_pos.row = p.row-1;
next_pos.col = p.col;
maze[next_pos.row][next_pos.col] = '*';
enqueue(next_pos);
}
return 0;
}
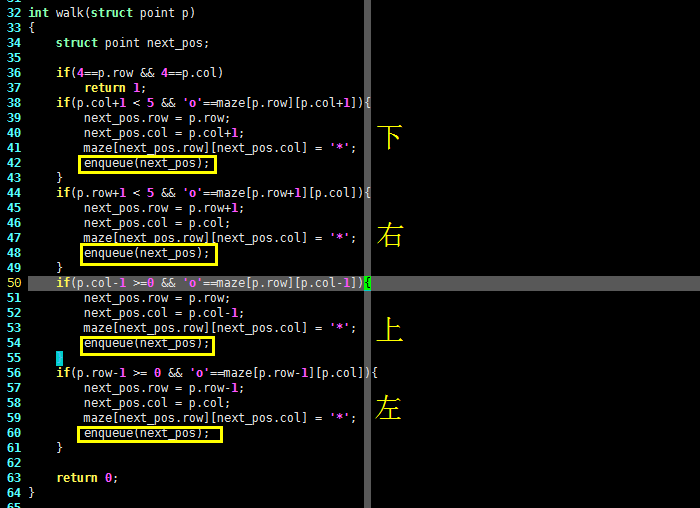
从上面的C语言代码可以看出,基于队列的 walk() 函数和基于栈的 walk() 函数非常相似,逻辑过程是一样的,都是判断右下上左是否有路,若有路则记录。不同的是,基于栈的 walk() 函数是将可以走的路线压入栈中,而基于队列的 walk() 函数则是将路线排在队列尾部。
关于 walk() 函数的详细说明参考上一节,这里就不赘述了。
不像“深度优先搜索法”把从迷宫入口到出口的路径都存放在堆栈中,“广度优先搜索法”只把最后一次要走的坐标放在队列里,因此判断迷宫是否没有出路(dead maze),只需判断队列中最后的坐标是否重点坐标就可以了,相关C语言代码如下,请看:
if(4!=p.row || 4!=p.col)
printf("dead maze!\n");
现在基于数据结构队列的迷宫路径搜索算法的C语言代码实现基本上就完成了,在main()函数中调用设计好的算法,相关C语言代码如下,请看:
int main()
{
struct point p = {0,0};
maze[p.row][p.col] = '*';
enqueue(p);
while(!is_empty()){
p = dequeue();
if(1==walk(p))
break;
print_maze();
}
if(4!=p.row || 4!=p.col)
printf("dead maze!\n");
return 0;
}
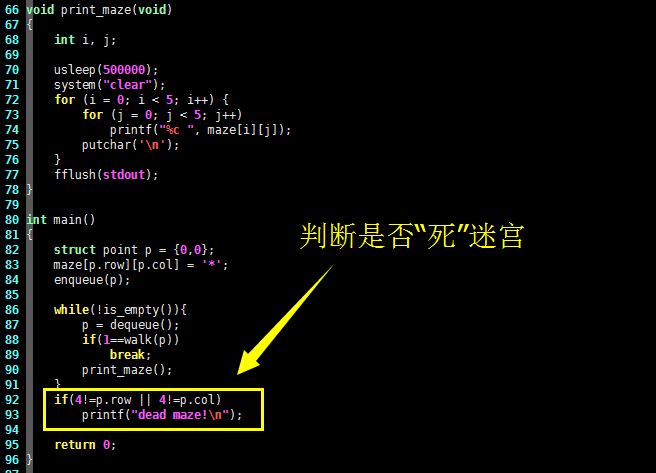
编译上面的C语言代码并执行,得到如下输出:
这样,我们就基于“队列”这种数据结构完成了迷宫路径的“广度优先搜索”C语言代码,从输出结果可以看出,它与“深度优先搜索法”的搜索方式是不同的。
广度优先法是一种步步为营的策略,每次探索不会放过任何一个方向,逐步把前线推进,下图中的虚线就表示这种前线,队列中每次存放的点就是虚线上的点。
广度优先搜索还有一个特点是可以找到从起点到终点的最短路径,而深度优先搜索找到的不一定是最短路径,比较本节和上一节程序的运行结果可以看出这一点,想一想为什么。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK