

C语言内联函数(inline),普通函数,和函数式宏定义的区别,与使用场景
source link: https://blog.popkx.com/c%E8%AF%AD%E8%A8%80%E5%86%85%E8%81%94%E5%87%BD%E6%95%B0inline-%E6%99%AE%E9%80%9A%E5%87%BD%E6%95%B0-%E5%92%8C%E5%87%BD%E6%95%B0%E5%BC%8F%E5%AE%8F%E5%AE%9A%E4%B9%89%E7%9A%84%E5%8C%BA/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

前几天,有粉丝(@学无止境攻城狮)在我的一篇介绍C语言宏定义的文章的评论区回复说:
希望写一个关于内联函数和普通函数的区别,内联函数和宏函数的区别。

@学无止境攻城狮 提到,对C语言中的内联函数、普通函数以及函数式宏定义的适用场景不够了解,也就是说在C语言程序开发中,“不清楚什么时候用函数式宏定义好,还是用内联函数,或者普通函数好”。
可能读者也有这样的疑惑,所以本文讨论这几种“函数”的区别,在了解区别后,相信读者自然就明白在何种场景应该使用何种“函数”了。
内联(inline)函数
内联函数会在它被调用的位置上展开,这一点表现的和 define 宏定义是非常相似的。展开是指内联函数的C语言代码会在其被调用处展开,这么看来,内联函数的“调用”应该加上引号,因为系统在“调用”内联函数时,无需再在为被调用函数做申请栈帧和回收栈帧的工作,即少了普通函数的调用开销,C语言程序的效率会得到一定的提升。
另外,将内联函数的代码展开后,C语言编译器会将其与调用者本身的代码放在一起优化,所以也有进一步优化C语言代码,提升效率的可能。
不过,天下没有免费的午餐,C语言程序要实现内联函数的上述特性是要付出一定的代价的。普通函数只需要编译出一份,就可以被所有其他函数调用,而内联函数没有严格意义上的“调用”,它只是将自身的代码展开到被调用处的,这么做无疑会使整个C语言代码变长,也就意味着占用更多的内存空间,以及更多的指令缓存。
显然,如果滥用内联函数,cpu 的指令缓存肯定是不够用的,这会导致 cpu 缓存命中率降低,反而可能会降低整个C语言程序的效率。因此,建议把那些对时间要求比较高,且C语言代码长度比较短的函数定义为内联函数。如果在C语言程序开发中的某个函数比较大,又会被反复调用,并且没有特别的时间限制,是不适合把它做成内联函数的。
函数式宏定义
C语言中的函数式宏定义可以像函数那样接收参数,不过不能像函数那样提供参数的类型检查,这个特点在有些程序员看来是不安全的。但是,函数式宏定义不关心参数类型这个特点,有时候也会被利用起来,写出一些适用性更广的C语言代码,例如:
#define max(__a, __b) ( (a)>(b)?(a):(b) )
上面这段C语言宏定义代码实现了一个 max() 方法,它接收两个参数,并返回较大的那个参数,max() 方法不关心参数的类型,因此 __a 和 __b 可以是 int 型的,也可以是 char 型或者 double 型以及其他数据类型的。
如果按照普通的函数来实现 max() 方法,程序员将不得不为每一种数据类型都实现对应的方法:
int int_max(int a, int b);
char char_max(char a, char b);
double double_max(double a, double b);
// 等其他几种数据类型...
虽然在C语言程序中调用普通函数,传递的参数会得到类型检查,更安全一些,但是可以看出这样也要求程序员写出更多功能雷同的C语言代码。这其中的取舍,读者自己定夺。
不少C语言程序员认为,除非宏能够带来不可替代的便捷,否则应该尽量避免使用宏,如果希望提升效率,应该尽量使用更安全的内联函数。
C语言代码示例
关于C语言内联函数和函数式宏定义,其实我之前的文章有过更详细的讨论,读者可参考:
《》
《》
接下来将给出一段C语言代码示例,进一步讨论普通函数、内联函数,以及函数宏定义的区别,请看:
int n_add(int a, int b)
{
return a+b;
}
__attribute__((always_inline))
inline int i_add(int a, int b)
{
return a+b;
}
#define d_add(a, b) (a+b)
int main()
{
int a = 1, b = 2;
int c = a+b;
c = n_add(a, b);
c = i_add(a, b);
c = d_add(a, b);
return 0;
}
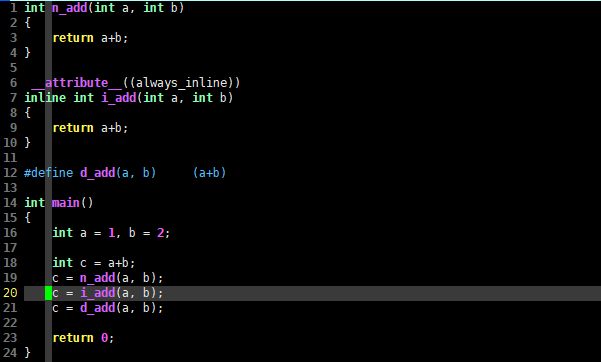
上述C语言代码很简单,其实就是计算两个 int 变量的和,不过这一计算过程使用了 4 种方法:
- 直接使用 + 运算符计算:c = a+b;
- 编写普通C语言函数,并调用:c=n_add(a,b);
- 编写内联函数,并调用:c=i_add(a,b);
- 编写函数式宏定义,并调用:c=d_add(a,b);
只看C语言代码是看不出什么分别的,要搞清楚这几种方法的区别需要深入到指令一层。在编译这段C语言代码之前,先来重点考察一下函数式宏定义。
相信读者应该明白,C语言中的 define 宏定义在编译之前的预处理阶段就会被处理,所以我们输入 gcc -E 命令查看预处理后的C语言代码:
# gcc -E t.c
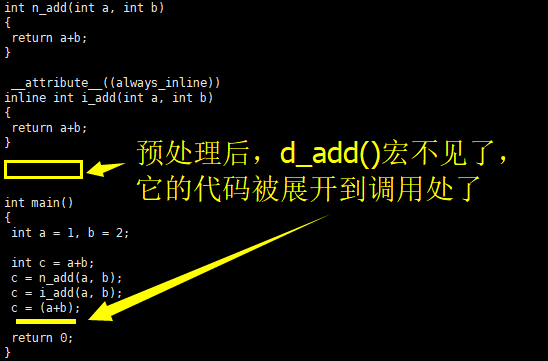
可见,在编译之前的预处理阶段,宏 d_add() 已经不见了,它的C语言代码则被替换到被调用处了,这是它与函数的区别之一——根本不会有调用过程的开销。实际上,函数式宏定义的这个特性可以做到一些普通函数和内联函数无法做到的工作,具体实例可参考我之前的文章。
现在编译这段C语言代码,并查看其汇编代码:
# gcc -g t3.c
# objdump -dS a.out
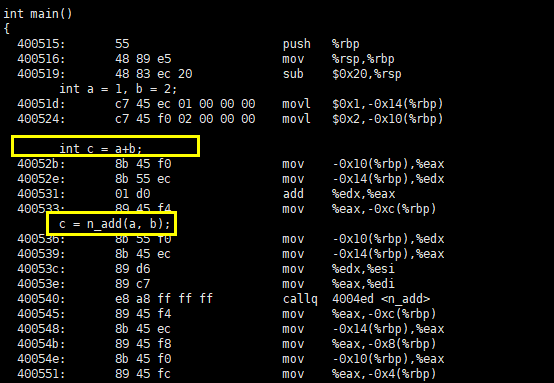
显然,与直接使用 “+”运算符计算相比,调用普通函数的开销更大,效率更低。再来考察一下内联函数的汇编代码,请看:
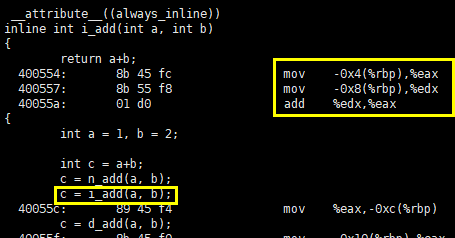
可见,虽然在预处理阶段,内联函数没有像宏那样被展开,但是在生成指令时,编译器将它的指令展开到调用处了。
读者可对比直接使用 “+”运算符计算的汇编代码,和调用内联函数的汇编代码,应该能够发现二者是等价的,也就是说“调用”内联函数实际上是没有调用(callq)过程的,它的开销和宏,和直接使用 “+”运算符计算是一样的,都低于普通函数,效率都更高一点。
本文主要讨论了C语言程序开发中的普通函数、内联函数,以及函数式宏定义的区别和使用场景,并给出了一段具体的C语言代码示例,可以看出,C语言中的内联函数和宏都可以在一定程度上提升效率。
但是鉴于函数式宏定义无法方便的提供参数类型检查,除非不得已,否则是不建议使用函数式宏定义的。另外,内联函数也不可以滥用,只建议把那些对时间要求比较高,且C语言代码长度比较短的函数定义为内联函数,否则程序的效率反而可能会降低,原因文章已经分析。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK