

C语言基本功修炼秘籍第1节,序列点(sequence point)是什么?C语言程序什么时候会产...
source link: https://blog.popkx.com/c%E8%AF%AD%E8%A8%80%E5%9F%BA%E6%9C%AC%E5%8A%9F%E4%BF%AE%E7%82%BC%E7%A7%98%E7%B1%8D%E7%AC%AC1%E8%8A%82-%E5%BA%8F%E5%88%97%E7%82%B9-sequence-point-%E6%98%AF%E4%BB%80%E4%B9%88/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

C语言程序开发中,有时候一条很不起眼的语句,就能导致非常难排查的 bug 产生。相应的,一段很C语言代码即使很简单,背后可能也隐藏着比较深入的知识点。例如下面这段C语言代码,请看:
#include <stdio.h>
int main()
{
int i = 0;
int a[3] = {};
a[i] = i++;
printf("a[i]: %d, i: %d\n", a[i], i);
return 0;
}
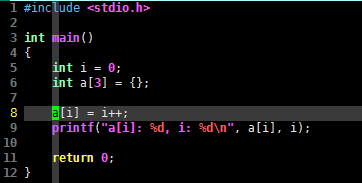
这段C语言代码足够简单,但是比较有经验的程序员应该能够发现不妥之处,事实上,使用 gcc 编译这段C语言代码,是会产生警告的:

为什么会有这样的警告呢?
读者应该能够注意到“may be”这两个单词,“operation on ‘i’ may be undefined”意为“对‘i’的操作可能是未定义的”。
“可能”这个词出现在人类交谈使用的自然语言里并不稀奇,但是它出现在决不允许出现歧义的“形式语言”(C语言属于“形式语言”)中就非常不可思议了。对于计算机来说,要么是,要么不是,怎么可能出现“可能”这样模棱两可的情况呢?
读者应该听说过“C语言是一门可移植的编程语言”,这里的可移植并不是指我们在随意一个平台编译的C语言程序,能够在所有其他平台运行。而是指程序员编写一份C语言代码,可以在其他平台编译,并且运行结果一致。
要实现这种“可移植性”,各个平台的C语言编译器需要遵守同一个标准——即程序员常说的C语言标准。需要说明的是,C语言标准并不包含所有的情况,对于C标准未明确要求的语法,编译器们可以根据实际情况自我调整。
例如,C语言标准规定 char 类型占用一个字节内存空间,所有规范的C语言编译器都应遵守,所以不管什么平台,C语言程序中所有的 char 类型通常都占用一个字节内存空间。至于 int 类型,C语言标准并没有规定其占用多少内存空间,因此有的平台 int 类型占用 2 字节,有的平台 int 类型占用 4 字节,这是允许的。
可移植的C语言代码,不能假定自己将要运行的平台,编写时应考虑所有未定义的标准。
现在回到前面的C语言代码示例:“对‘i’的操作可能是未定义的”,这里的“可能”实际上就是指C语言标准没有定义,在不同的平台运行结果可能会不一致。
什么“未定义”呢?
编译器在处理上述示例C语言代码时,引发警告的是下面这句:
a[i] = i++;
这句有什么问题吗?当然了,i 的初值为 0,那么程序处理这句代码时,a[i] 中的 i 是执行过 i++ 后的 i 呢,还是执行 i++ 之前的 i 呢?遗憾的是,C语言标准并没有对这一顺序做出约束,所以这两种情况都有可能,因此上述C语言语句经过不同的编译器处理,是有可能产生不同的结果的。
读者请注意编译器警告信息里的“[-Wsequence-point](序列点)”,这是很多C语言初学者容易忽略,但是又非常重要的知识点。
序列点(sequence point)
序列点(sequence point),或者翻译为“顺序点”,它在C语言程序中的作用是:当C语言程序执行到某个序列点时,程序保证该点之前所有语句的副作用(side effect)都执行完毕,该点之后的所有语句的副作用则全都不执行。
关于“副作用”的概念,可以参考我之前的文章《》。
可见,序列点其实就是用于确定C语言语句执行顺序的概念。在实际的C语言程序开发中,其实我们不经意间就会用到这个概念了,主要涉及以下 3 点:
- 表达式与表达式之间具有确定的执行顺序
- 表达式与表达式之间没有确定的执行顺序
- 表达式的计算未排序
执行无确定顺序的C语言表达式可能导致比较严重的不可预测的情况发生,这种情况可能在并行处理中出现,导致竞争条件。即使是非并发的情况,也有可能出现问题。例如下面这个表达式:
(a=1) + (b=a);
读者应该明白,虽然对 a 的赋值语句 a=1 只有一句,但是计算机处理时仍然可能需要多条指令才能完成,很有可能出现这种情况:程序对 a 赋值才完成前半段时,b=a 被执行了,然后对 a 赋值的下半段才完成,这将导致 b 中存储的实际上是 a 无意义的中间状态。
序列点实例
首先,C语言中的“+”运算符不关联序列点,假设某段程序中有两个函数 f() 和 g(),那么在处理 f()+g() 表达式时,f() 和 g() 的执行顺序实际上是不确定的,在不同的编译器上,f() 和 g() 都有可能先执行。
C语言中的逗号“,”运算符则可引入序列点,因此在处理表达式 f(), g() 时,执行顺序就确定了:C语言程序必定先执行 f(),再执行 g()。
在单个表达式中多次修改同一变量时,序列点也会起作用。例如这句C语言代码:
i = i++;
这句C语言代码不仅仅对 i 做了赋值操作,还对其做了自加操作。因此,在不同的编译器上,最终 i 的值实际上是不确定的,自加操作可能在赋值之前执行,也可能在赋值之后执行,甚至还有可能与赋值操作交叉运行,导致“中间态”的出现。
C#区分了赋值和自加运算符的优先级, 从而保证了该类型表达式的确定结果。
C语言中的序列点
上面的实例中讨论了C语言中的“+”不产生序列点,“,”产生序列点,那么还有哪些运算符产生序列点呢?
- 逻辑运算符 && 和 ||,以及前面已经讨论的逗号“,”运算符是能够产生序列点的。
例如,在表达式*p++ !=0 && *q++ !=0中,因为 && 运算符产生序列点,所以在程序访问 q 之前,可以保证*p++ !=0所有的副作用都完成。 - 三元运算符“?:”第一个操作数结束处将产生序列点。
例如在表达式a=(*p++)?(*q++):0中,*q++执行之前,可以确保*p的自加副作用已经完成。 - 完整的表达式末尾将产生序列点。
包括一条普通的以“;”结尾的C语言语句(例如赋值语句 a=b;),return 语句,if、switch、while、do while 以及 for 语句的控制表达式。 - 函数调用处将产生序列点。
虽然被调用函数的各个参数计算顺序是没有指定的,但是能够确保的是,在进入被调用函数之前,传递给它的所有参数的副作用都将完成。
例如在表达式 f(i++) + g(j++) + h(k++) 中,在进入函数 f() 之前,i会完成自加。同样的,j和k在进入 g() 和 h() 之前也会完成自加。但是正如前面所说,f()、g()、h() 三个函数本身的计算顺序是不确定的,如果 f() 访问了 j 和 k,它可能会发现两者都没有自加,或者只有一个完成了自加。
5. 函数返回时将产生序列点。
这是肯定的,C语言程序中,调用者调用函数后,总是会等待其完成,这其实隐含着一种顺序。
6. 各个声明运算符之间将产生序列点。
例如在表达式 int x=a++, y=a++ 中,对两个 a++ 的计算之间。
7. 在输入/输出格式说明符关联的转换之后将产生序列点。
例如,在表达式 printf("%n%d", &a, 3) 中,在计算 %n 之后,打印 3 之前有一个序列点。
本文以一段非常简单的C语言程序为切入点,较为详细的讨论了很多初学者容易忽略的C语言中的“序列点”概念。文章最后列举了C语言中产生序列点的场景,希望能够对读者有所参考,便于读者写出更加稳健的C语言程序。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK