

C语言编译器会如何处理a = b---c?按照a=(b--)-c,还是a=b-(--c)?
source link: https://blog.popkx.com/c%E8%AF%AD%E8%A8%80%E7%BC%96%E8%AF%91%E5%99%A8%E4%BC%9A%E5%A6%82%E4%BD%95%E5%A4%84%E7%90%86a-b-c-%E6%8C%89%E7%85%A7ab-c-%E8%BF%98%E6%98%AFab-c/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

C语言编译器会如何处理a = b---c?按照a=(b--)-c,还是a=b-(--c)?
今天有读者问我,C语言编译器会如何解释下面这行代码:
int a = 5, b = 3, c = 7;
a = b---c;
编译器在处理这行C语言代码时,会将其按照 a = b - (--c); 处理,还是按照 a = (b--) -c; 处理呢?或者会不会编译器也无法处理这样又“歧义”的语句呢?
在实际的C语言程序开发中,应该没有程序员会写出这样可读性极差的代码。于是问了该读者题目来源,回答是二级C语言试卷里的一个题目(果然是应试教育啊)。
虽说这样的C语言代码实用性几乎为零,但是它背后确实隐藏着一些初学者应该明白的知识点,所以本节将以该题为切入点,重点讨论它背后隐含的知识点。
首先,得到答案最简单直接的方法就是做实验。我们先将这段C语言代码补写完整,请看:
#include <stdio.h>
int main()
{
int a = 5, b = 3, c = 7;
a = b---c;
printf("a=%d, b=%d, c=%d\n", a, b, c);
return 0;
}

其实就是将题目中的C语言代码塞入 main() 函数而已。现在编译这段代码,注意添加 -Wall 参数,观察是否有警告信息:
# gcc t.c -Wall
# ./a.out
a=-4, b=2, c=7
可见,gcc 编译器处理这段C语言代码完全没有问题,甚至连警告信息都没有,执行生成的C语言程序,得到相关输出如上所示。可见,gcc 编译器在处理 a=b---c; 时,是按照 a = (b--) -c; 处理的。
但是为什么呢?C语言编译器这么处理有什么依据吗?
编译器这么处理 a=b---c; 自然是有依据的。事实上,C语言标准对这种情况是做了说明的,请看:
If the input stream has been parsed into preprocessing tokens up to a given character, the next preprocessing token is the longest sequence of characters that could constitute a preprocessing token. ...
大意是,如果输入流被解析为预处理 tokens(可理解为代码中的关键字符,如减法运算符 -)遇到给定字符停止,那么下一个预处理 token 应该尽量长。
所以C语言编译器在处理 a=b---c; 时,解析到 b 时,发现后面的 --- 可以被解析为两个 token:-- 和 -,或者 - 和 --,按照C语言标准,下一个预处理 token 应该尽量长,因此选择将 --- 解析为 -- 和 -,这样一来:
a = b---c;
// 会被C语言编译器解析为
a = b-- -c;
再来看一个例子
如果读者喜欢折腾,应该写过类似于下面这样的C语言代码:
int main ()
{
int a = 5,b = 2;
printf("%d",a+++++b);
return 0;
}
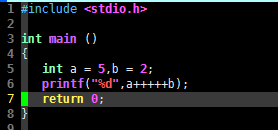
请注意关键语句 a+++++b。使用gcc编译这段代码,会发现无法通过,编译器报错了:
# gcc t2.c
t2.c: In function ‘main’:
t2.c:6:19: error: lvalue required as increment operand
printf("%d",a+++++b);
^

但是如果多写两个空格,也即下面这样写:
...
printf("%d",a++ + ++b);
...
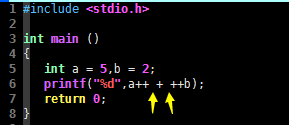
再来使用 gcc 编译这段C语言代码,会发现编译通过了,并且生成的可执行文件能够被正常执行:
# gcc t2.c
# ./a.out
8
这是怎么回事呢?其实还是同样的原因,C语言编译器在遇到有“歧义”的语句时,解析 token 会按照尽可能长的 token 解析,所以对于 gcc 来说,a+++++b 会被理解为 (a++)++ +b。相信读者应该明白,a++ 是不能作为 ++ 运算符的左值(lvalue)的,所以 gcc 会给出“error: lvalue required as increment operand”的错误。
可见,在C语言程序开发中,空格有时也是有用的,它不仅能够增加代码的可读性,还可以帮助编译器理解代码。
本节通过两段极其简单的C语言代码,讨论了编译器在处理“有歧义”的代码时的一个原则:“尽可能长”的原则。可以看出,即使是应试味很足的代码,也是有可能帮助我们学到新知识的。当然了,本文所述的内容只是抛砖引玉,希望能够对读者有所帮助。
阅读更多: C语言
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK