

计算机是如何存储小数的?在C语言编程中,应该注意什么?
source link: https://blog.popkx.com/%E8%AE%A1%E7%AE%97%E6%9C%BA%E6%98%AF%E5%A6%82%E4%BD%95%E5%AD%98%E5%82%A8%E5%B0%8F%E6%95%B0%E7%9A%84-%E5%9C%A8c%E8%AF%AD%E8%A8%80%E7%BC%96%E7%A8%8B%E4%B8%AD-%E5%BA%94%E8%AF%A5%E6%B3%A8/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

浮点型在内存中的存储分布方式因机器平台而异,完全理解所有机器平台中的浮点型存储无疑是一件相当麻烦的事。幸运的是,大多机器平台都遵守 IEEE-754 标准,很可能读者和我使用的平台正是使用的 IEEE-754 标准。
IEEE-754是如何存储浮点数的?
IEEE-754浮点(32位)或双精度(64位)有三个部分(在IEEE-854下也有类似的96位扩展精度格式):符号位,表示数字是正的还是负的;指数位;以及指定实际数字的尾数位。以C语言中的单精度浮点数为例,下面是某位浮点数的位布局:
该浮点数的值等于尾数乘以 2^x。读者应该注意,上图是二进制分数,因此 0.1表示 1/2。为了方便理解,我们可以将其与十进制的小数对应起来:十进制的 0.1 等于 1*10^-1,所以二进制的 0.1 等于1*2^-1,也即 1/2。
“尾数+指数”模式存储浮点数可能有一点问题,例如:2x10^-1=0.2x10^0=0.02x10^1,依此类推。同样一个数字可能有多种“尾数+指数”的表示方法,而同时兼顾多种表示方法势必会造成巨大的浪费(也可能使在硬件中实现数学操作变得困难和缓慢)。
所以,“尾数+指数”的存储模式需要一个统一的标准。事实上,IEEE-754 确实已经有标准了:假设给定一个二进制的浮点数,那么除非这个数是 0,否则总有某个位是 1。将小数点移到第一个 1 之后,调整指数位,这样一来,“尾数+指数”的唯一存储方式就固定下来了,也即“1.m x 2^n”形式。
既然小数点前总是 1,那么上述标准下的“尾数+指数”的存储模式甚至都不需要再花费空间存储小数点前的 1.
但是如果数字是零呢?IEEE Standards Committee 通过将零作为一种特殊情况来解决这一问题:如果数字的每一位都为零,那么数字就被认为是零。
现在读者可能又有疑问了,因为 1.0 =1.0x2^0,上述存储模式不存储小数点前的 1,也即尾数和指数部分都为 0,而“如果数字的每一位都为零,那么数字就被认为是零”,这样看来,1.0 似乎是没有办法存储的。
当然可以存储 1.0。单精度浮点数的指数部分是“shift-127”编码的,也即实际的指数等于 eeeeee 减去 127,所以 1.0 的表示方法实际上是 1.0x2^127。同样的道理,最小值本应该是 2^-127,按照“shift-127”编码指数部分,也即 2^0,可是这样又变成“指数部分和尾数部分都为零”了,因此在该标准下的最小值,实际上的写法是 2^1,也即 2^-126。
在我看来,为了表示 0 和 1,舍弃最小值(2^-127)是非常可取的做法。
零不是唯一的“特殊情况”。对于正无穷大和负无穷大,非数字(NaN),以及没有数学意义的结果(例如,非实数,或无穷大乘以零之类的计算结果)也有表示:如果指数的每一位都等于1,那么这个数字是无穷大,如果指数的每一位都等于1,并且尾数位也都等于1,那么这个数字就是NaN。符号位仍然区分+/-inf和+/-nan。
现在,读者应该明白IEEE-754浮点数的表示方法了,下面是几个数字的表示方法:

作为程序员,了解浮点表示的某些特性是很重要的,下标列出了单精度和双精度IEEE浮点数的示例值:
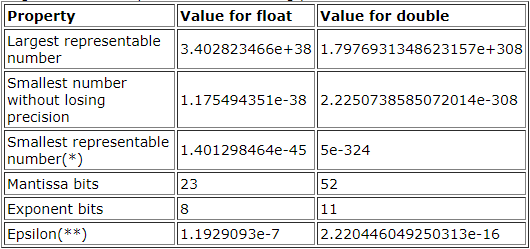
注意,本文中的所有数字都假定为单精度浮点数;上面包含双精度浮点数用于参考和比较。
在C语言程序开发中,数值的处理是一门值得深究的科学。本文不可能将复杂的数值算法以及相关的C语言程序开发经验一一列出。事实上,讨论如何以理想的数值精度进行计算,就和讨论如何编写最快的C语言程序,如何设计一款优秀的软件一样,主要取决于程序员本身的综合素质。
鉴于此,这里将尝试介绍一些基础的,我认为每个C语言程序员都应该知道的内容。
首先,我们应该明白C语言程序开发中的两个浮点数何时相等。可能读者并不觉得难,因为似乎C语言中的 == 运算符就能判断两个浮点数是否完全相等。
然而实际上,C语言中的 == 运算符是逐位比较两个操作数的,而两个浮点数的精度总是有限的,在这种场景下,== 运算符的实际使用意义就没有那么大了。
读者应该已经明白,计算机存储浮点数时,很有可能是需要舍弃一些位的(如果该浮点数过长),如果 CPU 或者相应的程序没有按照预期四舍五入,那么使用 == 运算符判断两个浮点数是否相等可能会失败。
例如,标准C语言函数库三角函数 cos() 的实现其实只是一种多项式近似,也就是说,我们并不能指望 cos(π/2) 结果的每一个位都为零。在C语言程序开发中,我们甚至不能准确的表示 π。
看到这里,读者应该思考“相等到底是什么意思呢?”,对于大多数情况来说,两个数“相等”意味着这两个数“足够接近”。本着这种精神,在实际的C语言程序开发中,程序员通常定义一个很小的值模拟“足够接近”,并以此判断两个浮点数是否“足够接近到相等”,例如:
#define EPSILON 1.0e-7
#define flt_equals(a, b) (fabs((a)-(b)) < EPSILON)
宏 flt_equals(a, b) 正是通过判断 a 和 b 的距离是否小于 EPSILON(10的-7次方),来断定 a 和 b 是否可以被认为“相等”的。这样的近似模拟技术有时候是有用的,有时候却可能导致错误结果,读者应该自行判断它是否符合自己的程序。
在本例中,EPSILON 可以看作是一种用于说明程序精度的标尺。应该明白,衡量精度的应该是有效数字,纠结 EPSILON 的具体大小并无意义,下面是一个例子。
假设在某段C语言程序中有两个数字 1.25e-20 和 2.25e-20,它俩的差值是 1e-20,远小于 EPSILON,但是显然它俩并不相等。但是如果这两个数字是 1.2500000e-20和1.2500001e-20,那么就可以认为它们是相等的。也就是说,两个数字距离足够接近时,我们还需要关注需要匹配多少有效数字。
计算机存储空间总是有限的,因此数值溢出是C语言程序员最关心的问题之一。读者应该已经知道,如果向C语言中的最大无符号整数加一,该整数将归零,令人崩溃的是,我们并不能只通过看这个数字的方式获知是否有溢出发生,归零的整数看起来和标准零一模一样。
当溢出发生时,实际上大多数 CPU 是会设置一个标志位的,如果读者懂得汇编,可以通过检查该标志位获知是否有溢出发生。
float 浮点数溢出时,我们可以方便的使用 +/- inf(无穷)。+inf(正无穷)大于任何数字,-inf(负无穷)小于任何数字,inf+1 等于 inf ,依此类推。因此在C语言程序开发中,一个小技巧是,将整数转换为浮点数,这样就方便判断后续处理是否会造成溢出了。处理完毕后,再将该数转换回整数即可。
不过,将整数转换为浮点数判断是否溢出也是要付出代价的,因为浮点数可能没有足够的精度来保存整个整数。32 位的整数可以表示任何 9 位十进制数,但是 32 位的浮点数最多只能表示 7 位的十进制数。所以,如果将一个很大的整数转换为浮点数,可能不会得到期望的结果。
此外,在C语言程序开发中,int 与 float 之间的数值类型转换,包括 float 与 double 之间的数值类型转换,实际上是会带来一定的性能开销的。
读者应该明白,在C语言程序开发中,不管是否使用整数,都应该小心避免数值溢出的发生,不仅仅是最开始和最终结果数值可能溢出,在一些计算的中间过程,可能会产生一些更大的值。一个经典的例子是“C语言数字配方”计算复数的幅度问题,极可能造成数值溢出的C语言实现是下面这样的:
double magnitude(double re, double im)
{
return sqrt(re*re + im*im);
}
假设该复数的实部 re 和虚部 im 都等于 1e200,那么它们的幅度约为 1.414e200,这的确在双精度的允许范围内。但是,上述C语言代码的中间过程将产生 1e200 的平方值,也即 1e400,这超出了 inf 的范围,此时上面的实现函数计算的平方根将仍然是无穷大。
因此,magnitude() 函数的更佳C语言实现如下:
double magnitude(double re, double im)
{
double r;
re = fabs(re);
im = fabs(im);
if (re > im) {
r = im/re;
return re*sqrt(1.0+r*r);
}
if (im == 0.0)
return 0.0;
r = re/im;
return im*sqrt(1.0+r*r);
}
应该明白,上述C语言代码为了避免数值溢出,给出的实现实际上是一种近似。例如 im 等于 1e200,re 等于 1,那么 im/re 的平方仍然能够达到 1e400,这会造成数值溢出。但是平方 re/im 却是可以的,因为 1e-400 会被四舍五入到零,足够接近得到正确的答案。
有效数字丢失
上面讨论的浮点数精度,以及相等问题只是C语言程序数值运算中的冰山一角。“有效数字丢失”指的是一类情况,在这种情况下,程序员很可能丢失数值的准确性。
前面我们提到,1.m 的尾数形式确保小数点前总是 1(非零时),既然如此,我们没有必要再花费一个位的空间用于存储 1。此时,即使尾数只有最后一位为 1,其他位都为 0,那么它的有效数字也是全部的,因为最前方有个“隐藏的 1”。但是,如果两个比较接近的浮点数相减,这个“隐藏的1”就会被抵消,最终得到的答案可能只剩下一位有效数字的精度。
幸运的是,就像上面求复数幅度避免出现数值溢出一样,避免两个接近的数字相减出现精度损失的方法也是有的,但是并没有一个通用的方法。这里给出一个简单的实例就是使用 1/x 的函数代替 x 的函数,这对于处理二次运算很有效。我的建议是,如果读者发现自己的C语言程序给出了令人怀疑的数值,就应该检查一下相应的减法运算了。
看到这里,相信读者应该想到C语言程序中的加法可能也有同样的问题:假设有数字 1.0,现在将其与 1e-20 相加。程序很可能认为 1e-20 很小,小于 EPSILON,于是忽略它,得到答案 1.0。这实际上也是一种精度损失。
要完全规避C语言程序中的浮点数可能带来的问题,工作量无疑是巨大的。为了简化问题,我们通常认为浮点数带来的精度问题是这样的:对浮点数的操作越多,损失的精度也会越多。
正如前文举的例子 cos(π/2),C语言它的实现实际上是一种近似,得到的答案并不是 0,而是 6.12303E-17。不过就这个答案本身而言,它已经足够小,认为等于 0 也没什么大问题。但是如果我们下一步计算是除以 1e-17,那么得到的答案就约是 6 了,这与预期的零相差甚远。
不要忘记整数
最后,在C语言程序开发中,并不是只有浮点数才重要的,整数同样重要,它的精确性是一个有用的工具。有时程序需要跟踪变化的分数(例如比例因子)。在这种情况下,既然浮点数受各种因素影响,那么我们完全可以将该分数存储为整数分子和分母来避免问题。在需要使用浮点数时,随时再做一次除法运算就可以了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK