

ZMonster's 每日摘要 2020-11-18
source link: https://www.zmonster.me/2020/11/18/daily-post-of-20201118.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ZMonster's 每日摘要 2020-11-18
2020-11-18
尝试在本周每天写一个当日摘要发到博客上,对于当日摘要要写些什么东西,暂定会有「笔记」和「时间」两块,不过我的想法随时可能会变,也许会在之后的几天产生新的想法,这一周时间一来是想确认一下我每天可以输出什么东西,然后也看一下自己是否能坚持这种写作方式吧。
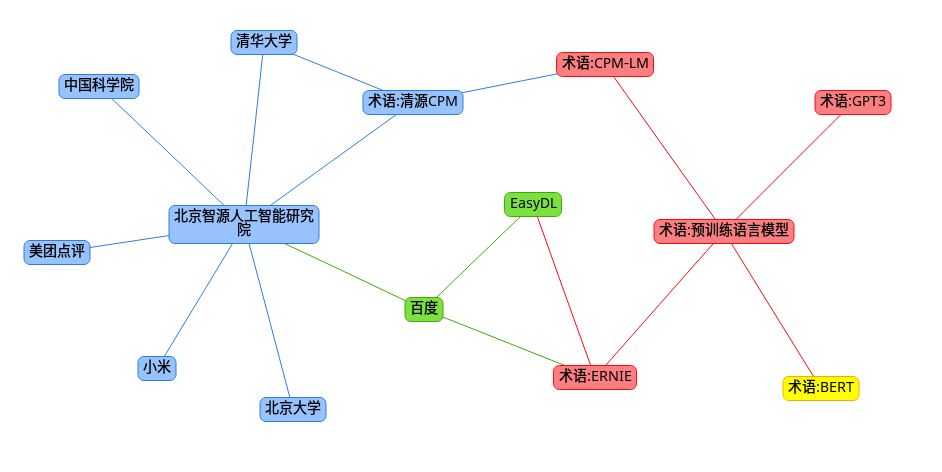
机构: 北京智源人工智能研究院
北京智源人工智能研究院(简称“智源研究院”)是落实“北京智源行动计划”的重要举措,是在科技部和北京市委市政府的指导和支持下,由北京市科委和海淀区政府于2018年11月推动成立的新型研发机构。其组织架构中的成员有旷视、百度、小米、美团各大公司的高管以及清华、北大、中科院、加州大学、普林斯顿大学、康奈尔大学的学术研究者。
看起来是一个重量级的机构,可以保持关注。
术语: 清源CPM
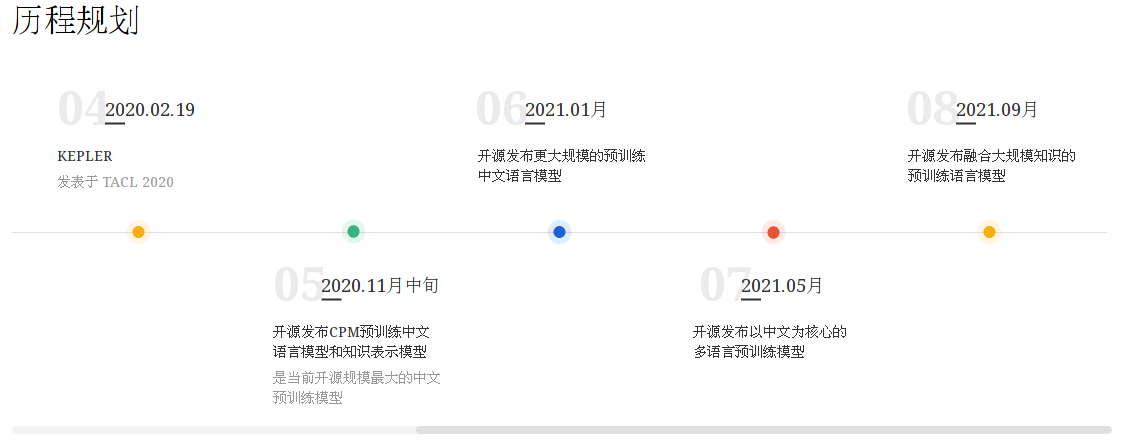
智源研究院清华大学合作开展的大规模预训练模型开源计划,首期开源内容包括预训练中文语言模型和预训练知识表示模型,可广泛应用于中文自然语言理解、生成任务以及知识计算应用,所有模型免费向学术界和产业界开放下载,供研究使用。
术语: CPM-LM
清源CPM 推出的 26 亿参数的中文预训练语言模型,是至 2020 年 10 月为止最大的中文预训练语言模型,从宣传上来看是在对标 GPT3 模型。

详细介绍见智源研究院公众号的文章1。
术语: 预训练语言模型
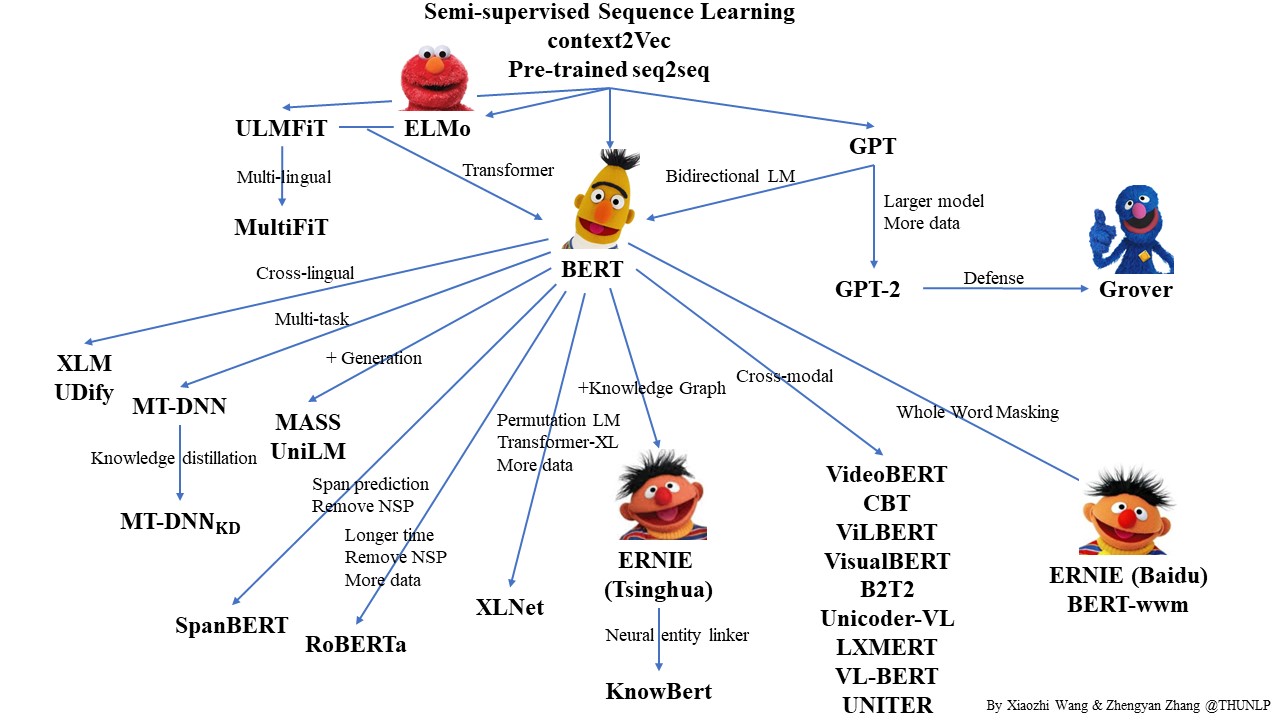
指用大量文本数据训练出来的语言模型,这种模型可以在之后后用做各种各样的 NLP 任务的基础设施,在这些 NLP 任务上只需要对模型结构做微小修改(通常是输出层)然后用该特定任务的数据进行少量继续训练(这种训练一般称之为「微调」)后,通常就能取得不错的效果。
术语: ERNIE
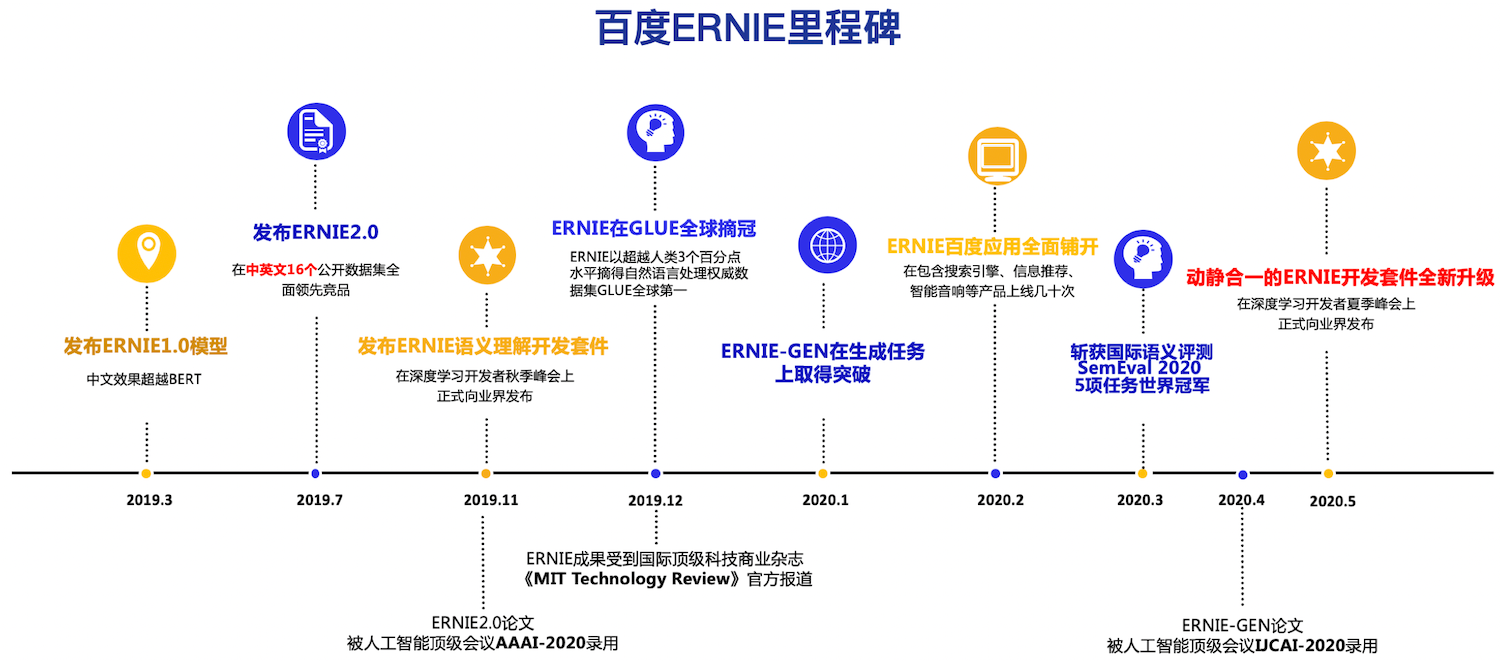
百度提出的使用知识图谱进行增强的预训练语言模型。
平台: EasyDL
主页: https://ai.baidu.com/easydl/
百度的 AI 平台,和以前那些提供 API 的功能不一样,这个平台可以让用户管理数据、选择和训练模型、发布模型,有点对标 AWS SageMaker 的感觉。EasyDL 对非 AI 技术人员很友好。
提供三种不同的模式:
经典版2:用户不需要关心(也不让关心)模型细节,只需要上传数据后触发训练然后发布模型即可使用,非技术人员也可以轻松上手
经典版可处理的任务类型有:
- 图像领域:图像分类、物体检测、图像分割
- 文本领域:文本分类(单标签)、文本分类(多标签)、情感倾向分析、文本相似度
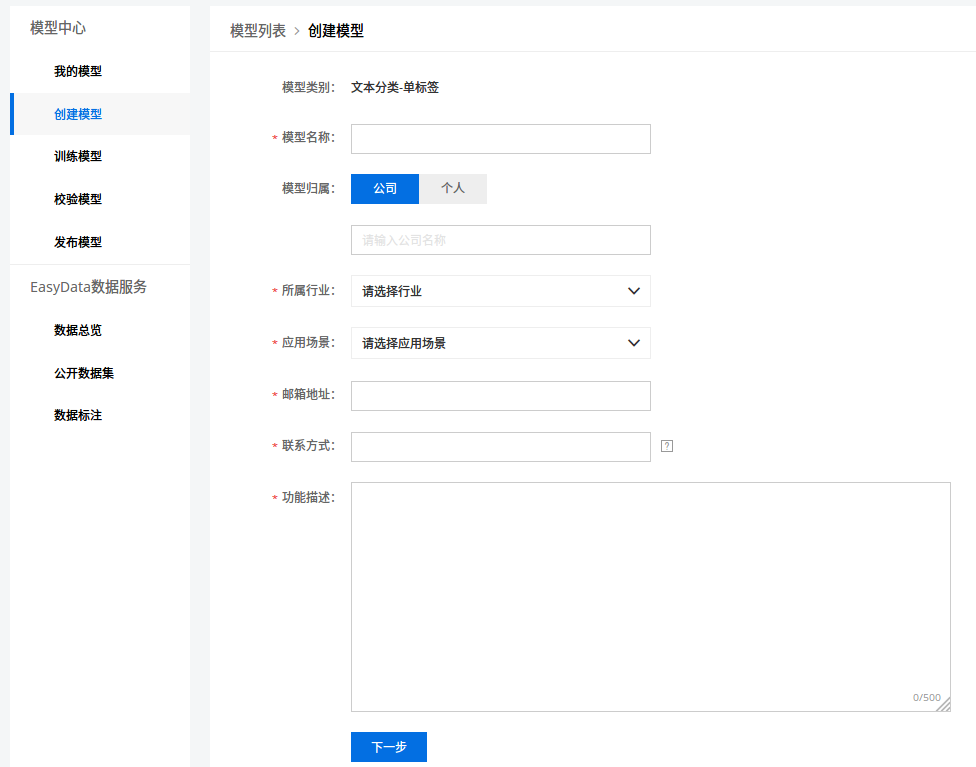
我比较关心文本方面的,以文本分类(单标签)为例,其操作如下:
-
-
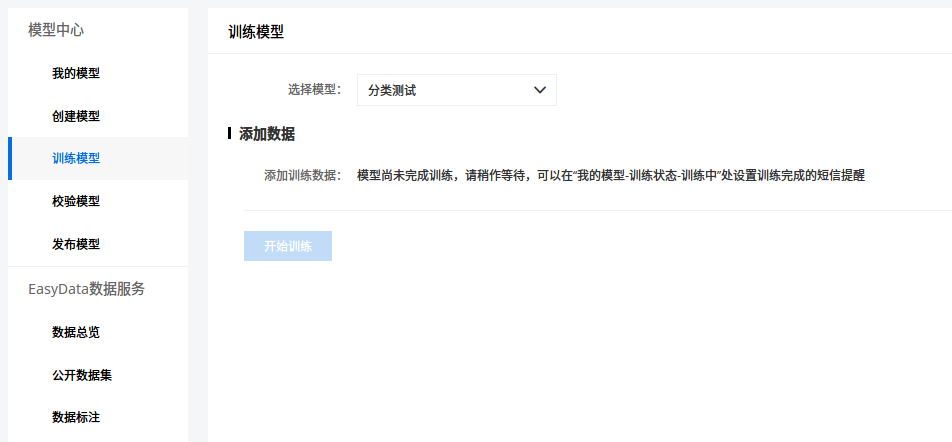
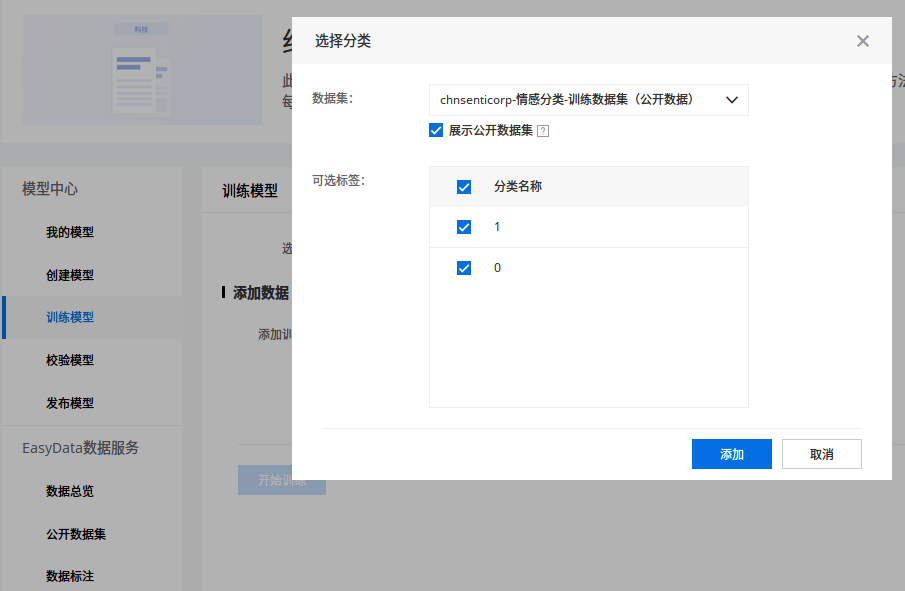
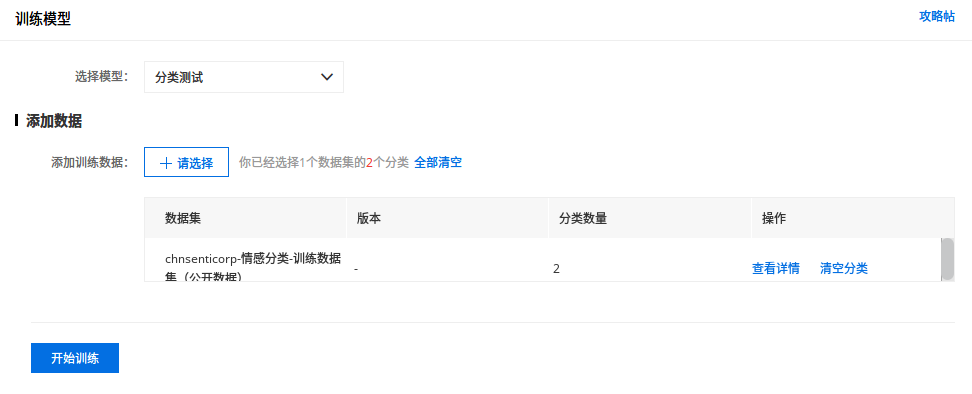
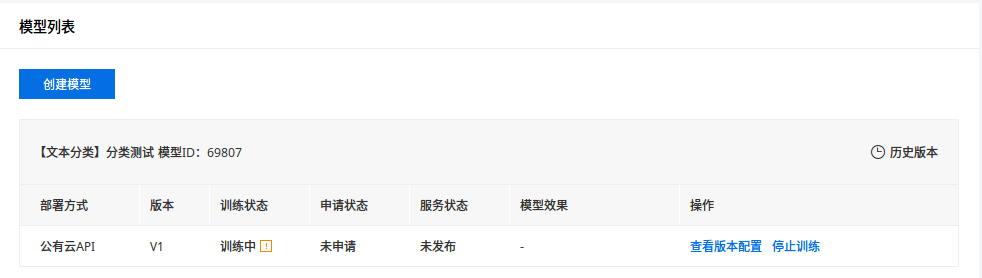
「训练中」后面那个感叹号点击后有一个选项,开启后可以在训练完成后发送短信通知用户。我用 cnsenticorp 情感分类数据 8249 条数据进行训练,用时 8 分钟,应该是用到了预训练模型(很有可能就是 ERNIE),不然不可能这么慢的。
整体的使用体验还挺好的。
专业版3:面向算法工程师的服务,让用户可以自主选择使用什么深度学习模型(CNN/BiLSTM 等)并进行参数调整
专业版可处理的任务类型有
- 图像领域:图像分类、物体检测
- 文本领域:文本分类(单标签)、文本分类(多标签)、短文本匹配、序列标注
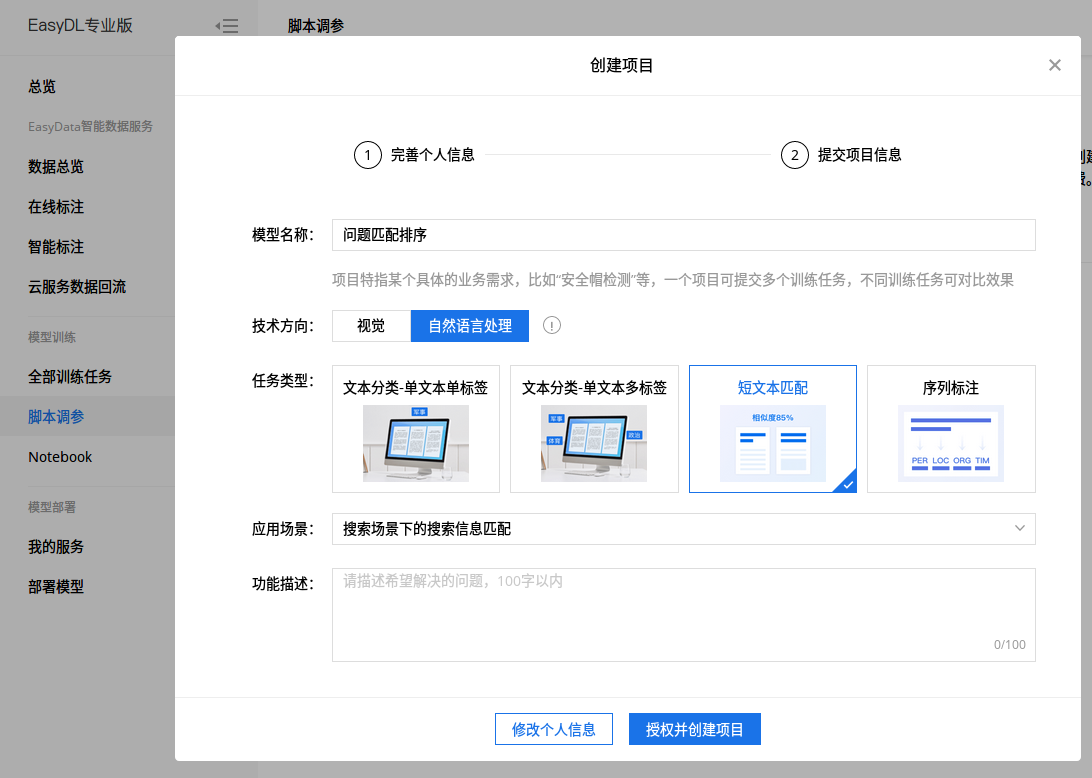
以短文本匹配为例来看下其使用过程:
-
-
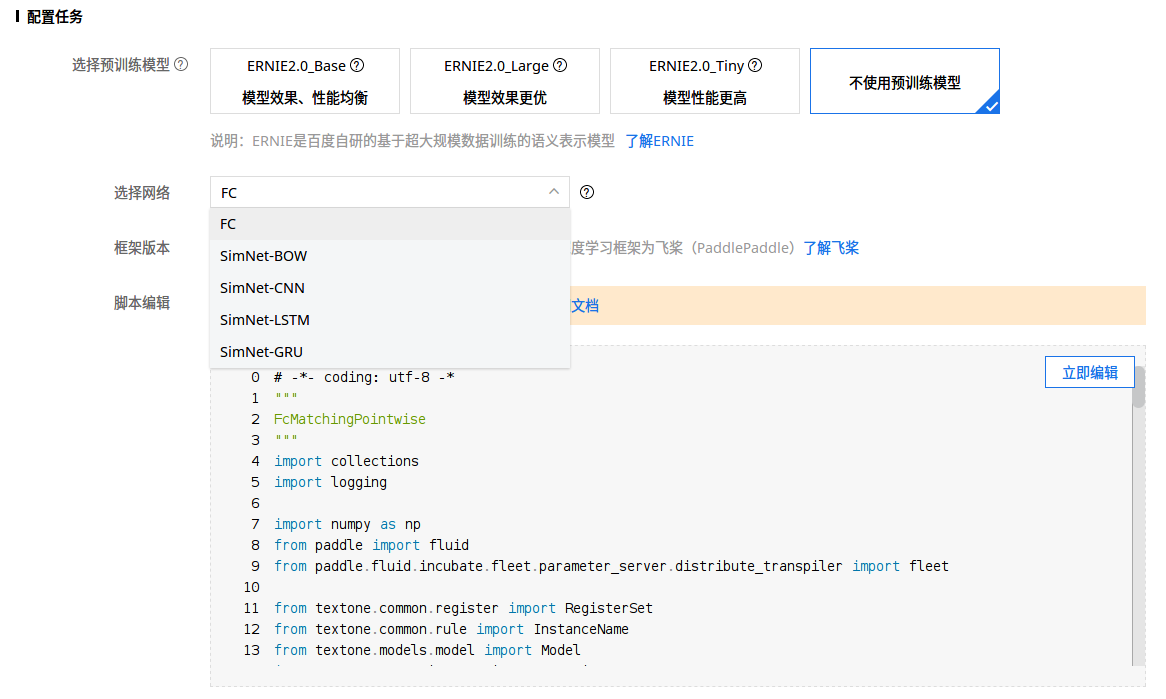
这里会确定模型结构,同时直接生成代码,需要的话用户可以编辑这个代码。如果使用预训练语言模型 ERNIE 的话,选择网络那里就只有 FC(全连接层) 可选了。如果想对模型做一些自定义修改的话,可以且仅可以在这个时候编辑模型的代码。
-
运行环境居然有 GPU V100,16G 显存,56G12U,可以啊……

完成前面的设置后即可提交训练任务。我选择了 LCQMC 数据集用于训练,共 23w 条数据,耗时 55 分钟,也还行哦。
可以看到训练过程产生的日志
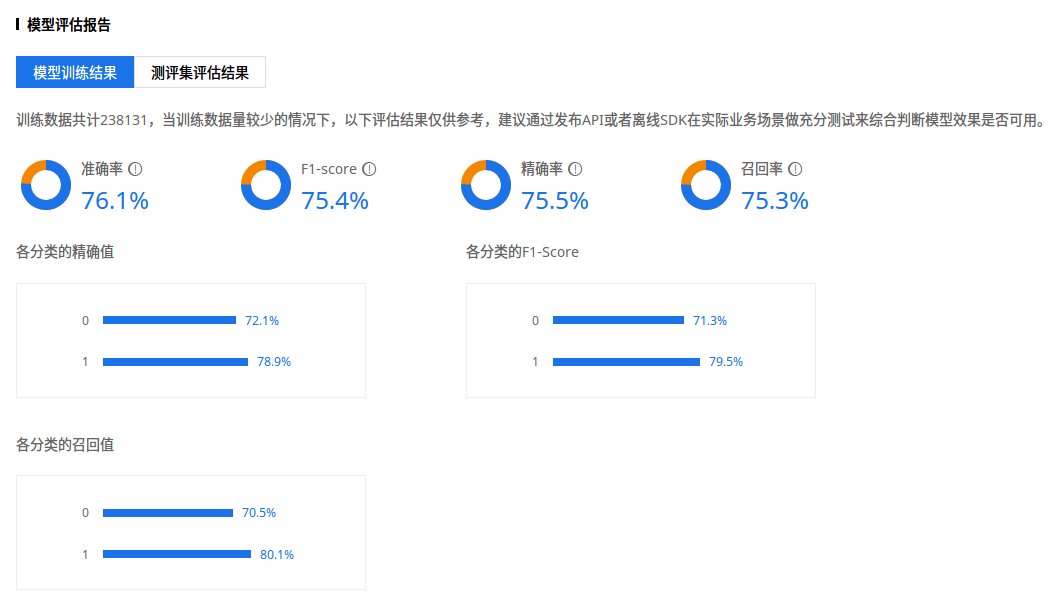
训练完成后可以看到模型评估报告
- 零售版4:面向零售行业,提供商品检测、货架拼接及其他零售方面的 AI 能力
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK