

大模型+强化学习_精典方法_RLHF
source link: https://blog.51cto.com/u_15794627/10681174
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
大模型+强化学习_精典方法_RLHF
精选 原创英文名称:Deep Reinforcement Learning from Human Preferences
中文名称:从人类偏好中进行深度强化学习
链接:https://arxiv.org/abs/1706.03741
作者:Paul F Christiano, Jan Leike, Tom B Brown...
机构:OpenAI, DeepMind
日期:2017-06-12 v1
RLHF 是 LLM 的重要组成部分。这篇论文早在 2017 年 OpenAI 和 DeepMind 联合发表的,他主要是为优化强化学习(RL)而设计的方法,主要在游戏领域进行实验,更多讨论机器人场景。
强化学习常用于解决真实世界中的复杂问题。以往的强化学习需要定义奖励函数,而 RLHF 使用了普通人定义的问答对来提供不到 1% 代理与环境交互反馈,从而大大降低了人工监督的成本。
其原理是:没有绝对评分,但有相对的更好。
先不考虑大语言模型,只考虑强化学习本身。这里讨论的是如何将机器在环境中的自主探索和人工指导结合起来。如果把 agent 比作一个学生,那么 reward 函数就扮演了教师的角色。文中提出的方法并不直接告诉学习应该怎么做,而是在可选的几种可能性中指示哪种更好。
再看 RL 与大语言模型的关系。像训练大模型时,训练数据和真实世界分布一定不同。在这种情况下,如何在可能的多个生成中选择人类更喜欢的呢?RLHF 就解决了这个问题。它利用了 RL 的策略选择和人类反馈训练的奖励函数来优化模型。
另一个我喜欢这篇文章的原因是,它还介绍了很多其他很棒的方法,可以拓宽我们的思路。
目的:为了解决强化学习系统在与真实世界环境交互时需要理解复杂目标的问题。
方法:研究使用了以非专家人类偏好为基础的目标定义方法,将轨迹片段进行比较。通过这种方法,在没有访问奖励函数的情况下,成功地解决了包括 Atari 游戏和模拟机器人运动在内的复杂强化学习任务。与环境交互时,只需对代理机器人与环境进行少于 1% 次数的反馈。
实验结果:实验结果表明,该方法可以降低人工监督成本,并能够实际应用于最先进的强化学习系统中。此外,该方法还具有很大灵活性,在仅使用大约一小时的人工时间内就能成功训练出复杂且新颖的行为。这些行为和环境比以往任何从人类反馈中学到的都更加复杂。
3 引言&相关工作
许多任务涉及复杂、定义不明确或难以指定的目标。假设我们想使用强化学习来训练机器人打扫桌子或炒鸡蛋,目前尚不清楚如何构建合适的奖励函数。
如果我们有所需任务的演示,可以使用逆强化学习提取奖励函数。然后,可以使用此奖励函数来训练具有强化学习的智能体。更直接地说,我们可以使用模仿学习来克隆展示的行为。但这种方法不适用于没见过、过于复杂或无法列举的场景。
另一种方法是允许人类提供有关我们系统当前行为的反馈,并以此反馈来定义任务。但这会给人带来很大工作量。
文中提出的方法是从人类反馈中学习奖励函数,然后优化该奖励函数。奖励函数需要:
- 能够解决那些只能识别出期望的行为,但不一定能展示出来的任务。
- 允许非专家用户教导智能体。
- 能够扩展到大规模的问题。
- 更为经济和有效地利用用户反馈方面。
算法根据人类的偏好拟合奖励函数,并通过训练策略来优化当前预测的奖励函数。这样,人们只需提供相对偏好(更喜欢 A 还是 B),而无需提供具体分数。
相关的研究还包括:逆强化学习(Finn 等人,2016)、模仿学习(Ho 和 Ermon,2016;Stadie 等人,2017)、半监督技能泛化(Finn 等人,2017)以及从演示中引导强化学习(Silver 等人,2016;Hester 等人,2017)。它们都是将机器自主学习和人工指导相结合的方法。
假设有一个人类监督者可以表达轨迹段之间的偏好,轨迹段是一系列观测值和操作。
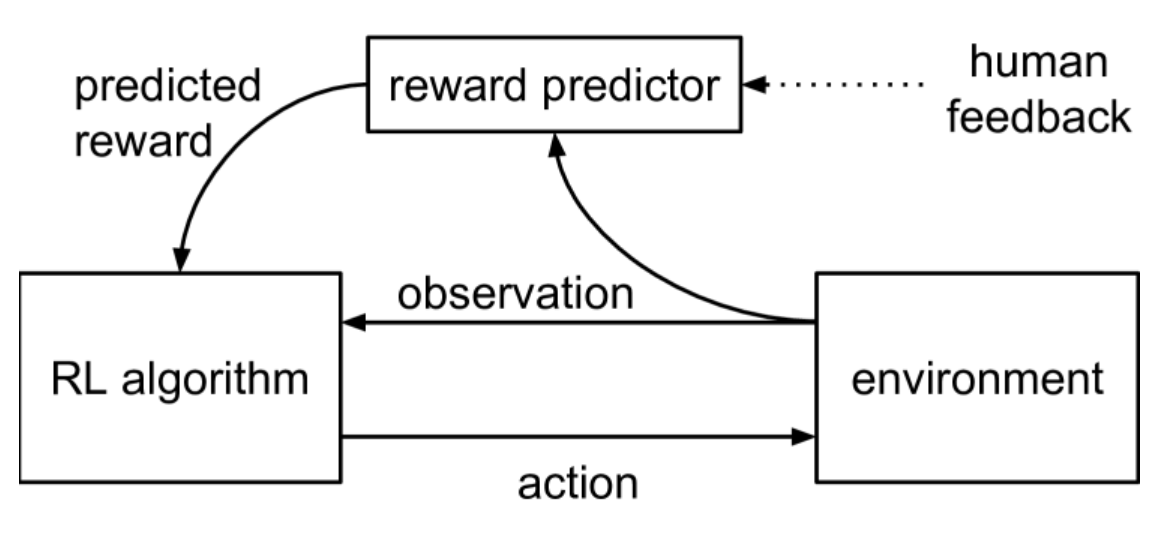
这里同时训练了策略模型和奖励模型,它们都使用深度学习网络实现。网络通过三个步骤进行更新:
- 策略与环境相互作用,生成一组轨迹。然后使用传统的强化学习算法更新参数,以最大化预测奖励的总和。
- 从上一步生成的轨迹中选择成对的片段 o1 和 o2,将它们发送给人类进行比较。
- 使用监督学习优化奖励模型的参数,以适应从人类那里收集到的比较结果。
以上过程是异步运行的。与传统的强化学习(图中下面部分)相比,这里加入了人工反馈和奖励模型的训练(图中上面部分)。
4.1 优化策略
理论上,RLHF 方法可以利用任何强化学习方法来实现。本文实验选择了 A-C 方法中的 TRPO 作为实现 RLHF 方法的方式。
鉴于 PPO 论文是在 2017 年发表的,因此在大型模型中,通常会使用更具鲁棒性的 PPO 方法来实现强化学习策略,例如 GPT。
4.2 偏好诱导
在实验中,研究人员以短片剪辑的形式向参与者展示了两个轨迹段的可视化图像。这些片段的长度介于 1 到 2 秒之间。参与者需要表明他们对于这两个片段有哪种偏好:更喜欢其中一个、认为两者一样好或者无法进行比较。
人类的判断被记录在一个三元组的数据库 (o1,o2,µ) ,其中 o1 和 o2 是两个段, µ 指示用户更喜欢哪段。如果人类选择一个部分作为可取的,那么 µ 就将其所有质量都放在该选择上。如果人类将这些段标记为同样可取,则 µ 是均匀的。最后,如果人类将这些段标记为不可比,则比较不包括在数据库中。
4.3 拟合奖励函数
如果我们将 r 视为影响人类判断的潜在因素,并假设人类对片段 oi 的偏好概率取决于潜在奖励在片段长度上的累积值的指数,那么我们可以将奖励函数估计 r 视为一个偏好预测器。
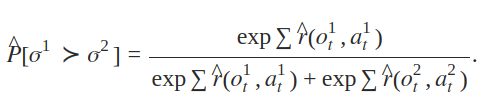
最小化这些预测与实际人类标签之间的交叉熵损失。
遵循 Bradley-Terry 模型,将奖励等同于偏好排名量表,两个轨迹段的预测奖励差异估计了人类选择其中一个而不是另一个的概率。
4.4 选择查询
从大量的轨迹片段中抽取出一对一对的片段,然后用的奖励模块去预测人更偏好哪一段轨迹。最后,我们选择那些预测结果在各个预测工具中差异最大的轨迹(明显更好的轨迹)。
在 TensorFlow 中实现了我们的算法。通过 OpenAI Gym 与 MuJoCo 和 Arcade 学习环境(进行交互。
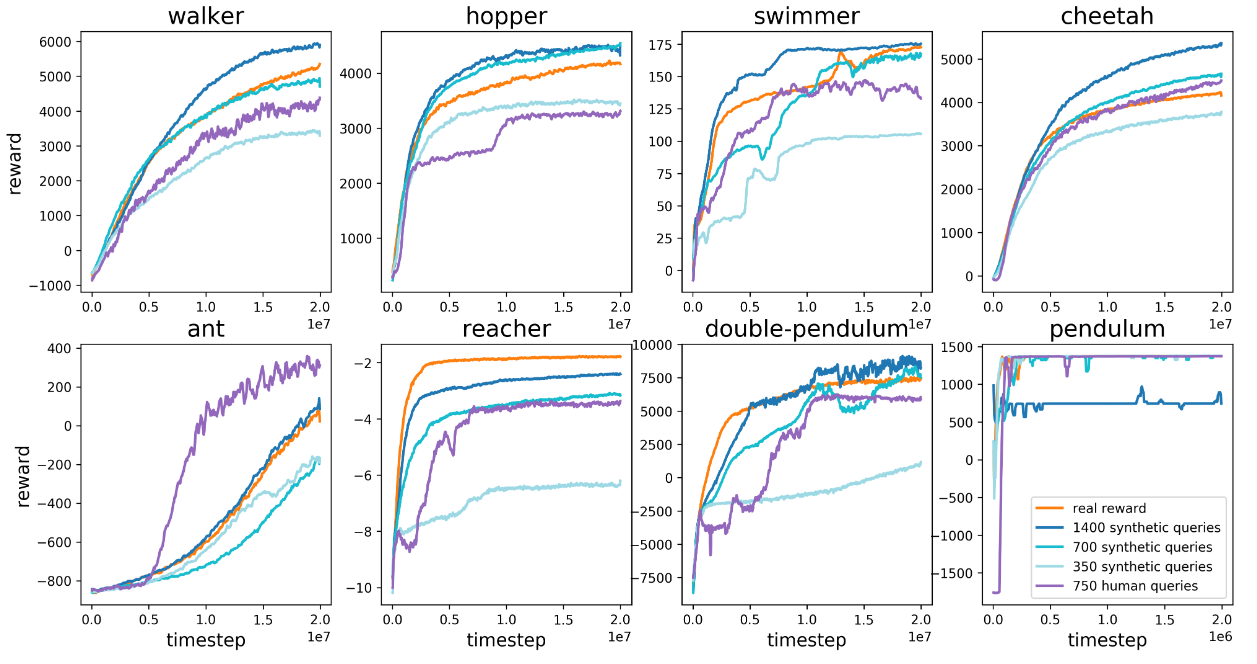
5.1 模拟机器人
在第一组实验中,我们尝试解决深度强化学习的一系列基准任务,而不观察真正的奖励。相反,智能体只能通过询问人类哪个轨迹段更好来了解任务的目标。我们的目标是在合理的时间内使用尽可能少的查询来解决任务。
实验还将真实奖励与 RL 训练的基线进行了比较。我们旨在依靠更稀缺的反馈,在没有获得奖励信息的情况下做得几乎和 RL 一样好。需要注意的是,真实人类提供的反馈有可能胜过 RL,因为人类反馈可能提供更好的奖励。
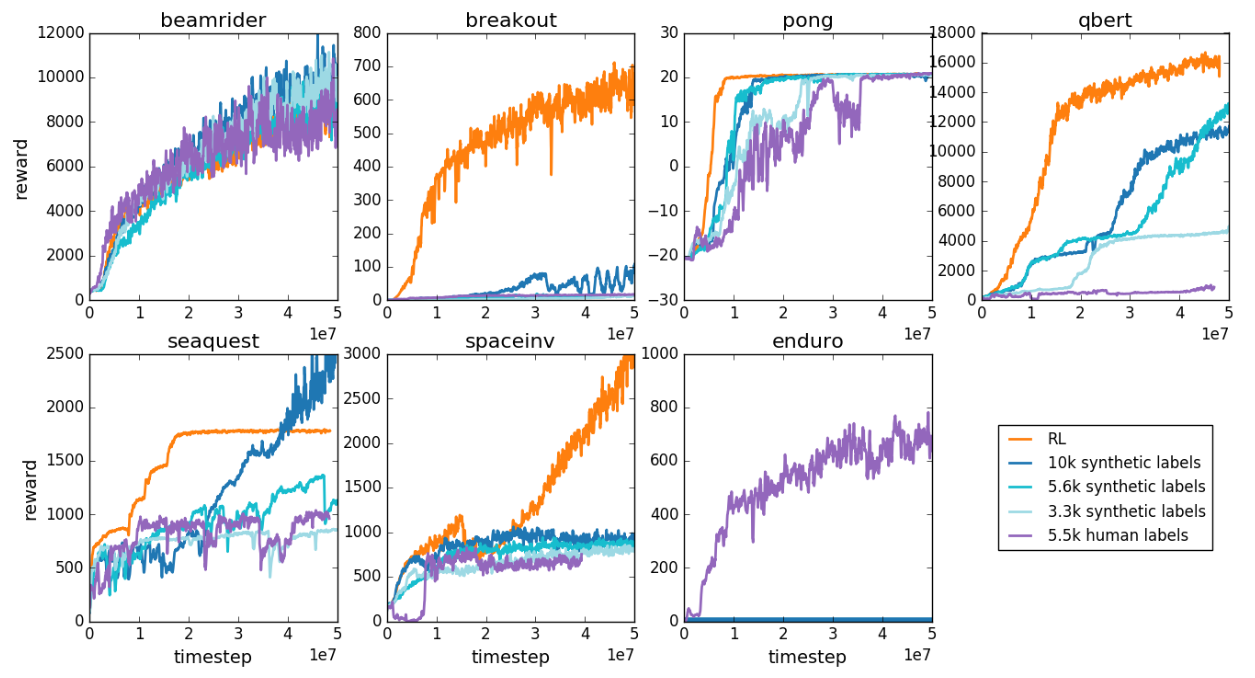
5.2 雅达利
第二组任务是街机学习环境中的一组七款雅达利游戏。这个实验结果是:对于不同的任务,不同方法各有优势。
(复杂任务中,RL 经过多轮自学,效果常常更好,比如下棋)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK