

乘风破浪,川流入海 —— LLM在阿里妈妈智能文案的应用
source link: https://zhuanlan.zhihu.com/p/694444538
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

✍ 本文作者:次况
欢迎微信关注:阿里妈妈技术;
1.引言
在现代广告系统中,文案是不可或缺的一部分,几乎参与了广告素材的各个地方。随着NLP技术的极速发展,广告主逐渐学会并习惯使用文案生成工具直接或者间接的参与到广告的制作中,这为NLP技术在广告场景的应用提供了巨大的潜力和机会。阿里妈妈智能创作与AI应用团队在广告文案方面做了长期的工作,并积累的一定的技术能力。
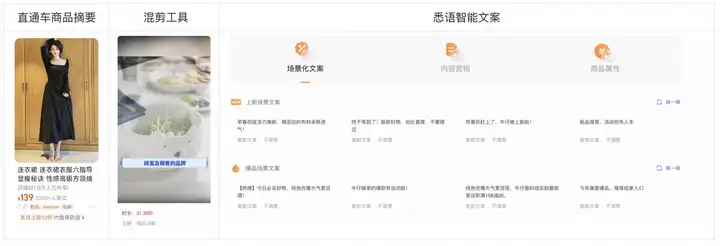
图1:智能文案应用场景举例
2022年底,ChatGPT的横空出世,为NLP技术的发展的应用打开了新的局面。面临大模型的时代潮流,是否使用大模型、怎么样使用大模型、怎么样更好的使用大模型、大模型能给广告文案生成带来哪些变化,是团队亟需探索、研究和尝试回答的问题。
本文从业务背景出发,尝试通过分析大模型在智能文案上的应用,对上述问题进行探索和分析。首先我们从智能文案面向的业务出发,讨论智能文案生成业务面对的困难及大模型可能带来的提升。然后总结了在面对如雨后春笋般涌出的中文大模型时的选型过程和方法。在怎么样更好的使用大模型方面,我们主要从数据源和训练方法进行了讨论。在大模型落地到广告智能文案生成后,给业务带来了一定的提效。最后,在使用大模型的过程中,我们发现了一些可能的问题,并尝试对未来的发展进行展望。
2.模型的选择
2.1 模型那么大,我想试试看
大语言模型在NLP方面的强大能力和巨大潜力已经为大家所公认,但是这是否意味着所有的自然语言处理任务都应该使用大语言模型来处理呢?答案显然是否定的,不管是从开发成本还是服务成本上来说,大语言模型的花费都是巨大的。大模型的落地显然要充分考虑到应用场景的特点后进行选择和决定。
从阿里妈妈智能文案创意业务的角度来看,主要面临着以下几个挑战:
图2:广告智能文案业务
1.文案种类要求多。智能文案面向直通车、展示、外投、工具等多种服务场景,每个场景都有其特定的文案种类和风格要求,加上上下游各种文案预处理和后处理模型,文案支持涉及的模型池巨大。包含从传统的NLP算法到大规模神经网络算法的各种类型,从分类到生成的各种任务,开发时间从几年前到几个月前。这耗费了前人无数心血,结合众多的业务逻辑的文案服务,在很好的支持了现有文案生成服务之外,也带来较大的维护成本,后续的开发和迭代相对困难。分久必合,一个功能强大的、能同时支持多个文案种类的模型,会给算法和模型的维护、开发迭代、升级改进、服务扩展等都带来收益。
2.文案内容要求丰富。作为智能文案,大多数服务的最终出口是生成和商品相关的创意文案,这对文案的创造性有很强的需求。一个能够根据商品信息生成更具创意的文案,自然会提升广告的投放效果。大模型有着强大的基础写作能力和创意能力,在广泛的世界知识的基础上进行创意生成,可以极大的扩展创意的丰富度。
3.新兴创意业务的需求。随着短视频潮流的席卷而来,对广告创意也有了进一步的需求。在图文创意的基础上,视频类创意的需求逐步增加。面对从看文案到听文案的转变,从短文案到长文案的需求,文案创意需要提升文案服务能力,服务更多的新兴业务,支持新兴需求。大模型在这方面同样有着很强的潜力。
基于上面的考虑,我们选择使用大模型来对现有的文案种类进行统一收口和支持,降低服务的支持维护和开发更新的难度。同时利用大模型强大的写作能力,提升文案创意的丰富度,扩展文案创意的新表现形式,满足更多场景的文案需求。
2.2 模型那么多,我用哪一个
在过去的一年里,大模型的迭代速度和相关工作爆发式的增长,可供选择的底模玲琅满目。面对鱼龙混杂的庞大的开源大模型库,选择和业务适配的大模型就是一个亟待解决的问题。
评价指标
为了对比和选择模型,首先需要确定评价指标。基于广告文案创意的业务背景,我们将评价指标首先分为客观和主观。
客观指标主要包括模型对于输出的控制能力,例如能否满足字数要求、能否满足输出格式要求、能否区分不同业务的文案等。客观指标基于指标定义制定评测流程即可。
图3:指标分类图
主观指标参考人对广告文案的判断标准,总结人对优质文案的喜好,分为了文案的流畅度、文案的优美度、和商品信息的对应关系等。主观指标的评测相对比较复杂,原则上来说应该通过细化评价维度和标准、众包人工评测来完成。但是人工评测方法成本高、周期长,对模型的迭代不友好。
业内另一种相对成熟的评测方式是使用更强大的模型进行评测,例如GPT系列模型。通过人工标注和GPT标注结果进行对比我们发现,GPT和人工标注结果的趋势基本相似,且GPT在标注上更加的一致。因此最终选用GPT作为评价标注,对比两个模型的输出进行选择得到模型胜率,作为模型的评分。
在前期的测评中我们发现,GPT存在较为明显的“端水”现象,且存在于多个指标的内和外。在一个指标内,除非两个文案有明显的大的差别,否则GPT倾向于打平,导致最终的打分区分度不足。而在多个指标之内,GPT会自然的倾向于在不同指标之间维持平衡,在一个指标上的上升往往会伴随着另一个指标的下降。为了解决上面两个问题,我们通过调整prompt,指定GPT做互斥评价,在两个文案中必须选择一个。同时多个指标通过不同的prompt分别进行打分,避免指标之间的互相影响。
模型系列的选择
参考社区的下载量和评论等,我们首先将选择范围限定在LLaMA的中文版、Baichuan系列、ChatGLM系列和QWen系列等。具体的模型背景在此不再赘述。
LLaMA-Alpaca-Chinese、Openbuddy-LLaMA2等以LLaMA系列模型为基础的中文模型,对原始词表进行扩展,从而支持更多的中文字符。同时使用中文数据进行CT和SFT,使得模型获得在中文上的指令跟随能力。Baichuan、ChatGLM、QWen等是原生的中文大模型。
我们首先测试了直接使用prompt进行zero-shot的文案生成。通过精心设计prompt,模型的回答满足了一定的流畅度和优美度的要求,对于文案风格的需求也可以在一定程度上满足。但是对于字数限制、格式需求、更加精细的文案需求,通用的大模型距离可用还有一定的差距。因此我们收集了一批广告文案生成的文本数据,经过简单的SFT之后,再对模型的能力进行评测。
在客观指标方面,包括文案输出格式、文案数量控制、文案字数控制上,各个模型的表现都相对较好,能够输出符合要求的文案格式,文案数量控制的准确率都超过了97%。在文案字数控制上,Openbuddy-LLaMA2表现相对较差,输出文案长度不在合理的范围内的超过3.5%,其次是ChatGLM、Baichuan,QWen在字数控制上表现最好。值得注意的是,原生的中文大模型都显著的好于LLaMA的中文版,但中文大模型之间的差距较小。
有趣的现象出现在主观指标上。Baichuan和ChatGLM像是浪漫的诗人遇到了严谨的学者,在文案的流畅、优美等方面,Baichuan都表现出了明显的优势,发挥了丰富的想象力,但是商品的准确率略差。QWen1虽然在流畅度和商品准确方面好于Baichuan,在优美度上也是落了下风。LLaMA的中文版相对来说表现最差,在所有指标上均没有显出明显优势。
在后续的持续迭代中,我们也注意到,随着开源模型的不断改进,同一系列模型的效果也会有明显的提升。例如QWen1.5模型(QWen模型的最新版本),相比Baichuan系列、QWen1、ChatGLM系列等模型,QWen1.5模型的效果在客观指标上基本持平,但在所有的主观指标上均有明显的提升。 考虑到广告智能文案的业务特点,我们最终选择了各方面都更加优秀的QWen1.5模型作为底模。
模型参数的选择
除了不同的底模,模型的参数量也是我们需要考虑的因素。从直觉上来说,bigger is better,但是在具体的业务落地中,更多的参数会带来更大的资源需求和更长的RT。我们尝试了6B-14B的中小规模的模型,并用上述的评估方法进行选择。
在客观指标上,更大的模型确实会带来更好的效果。同一系列的模型,增大模型规模可以一定程度的提升模型的控制能力,QWen系列的14B模型比7B模型,在文案字数控制能力上有了一定的提升,字数波动的范围也更小。
但是在主观指标上,更大的模型并没有带来明显的性能提升。我们猜测,对于固定种类的文案生成任务,我们的文案类别尚没有达到小规模模型的上限。
同时考虑到对计算资源的需求,14B模型相比7B模型存在质变,14B模型需要经过量化才能在单卡A10提供服务,而7B模型通常可以在FP16下载入。更小的显存占用,也可以通过batch的方法显著的提升平均文案生成速度。因此我们最终选择了QWen1.5-7B的模型提供服务。
3.模型训练
3.1 数据准备
为了实现大模型在广告文案场景的落地,高质量、多样化的数据是重中之重。得益于团队长久以来的工作,我们积累了大批量的数据,难点主要在于数据清洗。
图4:数据准备
纯文本数据的清洗相对比较直接。我们基于业务场景需要,定义了多种文案类型及其特点,包括长短文案的字数、输出格式等,使用多样化的规则对海量数据进行清洗,并基于商品类目覆盖、输出字数覆盖、输出数量覆盖等多样性标准进行了筛选和过滤,最终形成了纯文本的训练数据。
此外,由于文案还被用于视频解说等场景,对文案的口语化、吸睛开头、各种有趣形象的描述也有了进一步的要求。基于此,我们增加了高质量的视频解说数据,以增强模型的口语化能力,并产出更吸引人的高质量的文案。我们从线上的高质量视频数据出发,通过ASR、OCR增强和修复等方法,获得了高质量多样化的口语化文案数据。
最后,利用更强大的大模型进行数据生成也是一种重要的获取数据的手段。针对新兴的、没有存量数据或难以获取存量数据的文案需求,我们根据文案的特点和要求,使用更强大的大模型,例如GPT4等,作为生成器,通过prompt工程和answer engineering,生成了高质量的数据,增强的较小规模模型的生成能力。 同时,为了尽可能的保留模型原始的指令跟随能力,避免模型在业务数据上过度训练,完全拟合成为业务特点模型,我们还收集了通用的指令跟随数据集,以供在训练中进行数据混合。
3.2 训练过程
为了更好的对大语言模型进行微调,众多的微调方法被开发出来,例如Prompt Tuning、Prefix Tuning、P-Tuning、LoRA等,deepspeed和ZeRO等优化模型显存占用和模型并行的方法也极大的降低了微调大模型的难度。我们尝试了P-Tuning、LoRA、全参数微调后,最终选择了全参数微调作为主要的训练方法。
4.效果
大模型的使用,为广告智能文案业务打开了新的局面。一方面,我们可以接受更大量的文本信息的输入,从商品的标题、属性,到商品详情页的文本,大模型强大的理解能力,为我们打开了输入的大门。另一方面,大模型能够生成更加高质量的文案,完成对原有文案的替换和升级,打开了文案优选的候选池,打破了原有文案生成的能力边界,让智能文案生成的可能性和发展方向更加的多元。我们的文案生成大模型,集成了多种类型的文案生成能力,并对外提供统一的服务。
图5:智能文案生成流程
4.1 原有文案的升级和替换
基于大语言模型,我们对原有的文案生成能力进行了统一的升级和替换。针对原有文案生成能力分布在多个模型的问题,我们使用统一的大模型进行了替换,并使用不同的prompt进行能力的激发和提供服务,提升了文案服务的易维护性和易用性。
在悉语文案生成工具中的通用场景文案生成功能中,我们提供的4种10条文案均出自同一个模型,生成的文案相比原有文案质量高、表述多样。流量实验证明,我们的新文案相对老文案,用户的采纳率有明显提升。
图6:悉语智能文案工具改进效果对比
通过例子也可以看出,新模型提供的相同类别文案可以描述商品的不同的特点,更加多样化。长文案摆脱了过于模式化的表达,增强的文案的吸引力。
在外投场景中,受限于原有模型的生成能力,为商品生成的外投标题相对比较单一,且存在较多的bad case,例如商品和标题关联性弱等问题,导致需要人工复核,文案生成成本高且效率低,线上覆盖率很低。我们使用大模型生成了多种长度、多种风格的外投标题,使得外投标题更加易读且提现商品特点,极大的提升了智能文案的覆盖率,支持了多个外投场景的落地。
4.2 原有业务的升级
原有业务,例如直通车、外投等,受限于文案生成能力,对外输出文案以原始的商品名称和模式化相对严重的数据统计类文案为主,文案的可读性和吸引度都不高。在大模型强大的文案生成能力的加持下,我们根据业务特点,生成了表达通顺、多样化、有吸引力的文案。
在直通车场景中,我们主要扩展了多种表述风格的商品摘要。通过挖掘商品信息输入大模型中,生成了描述商品卖点的、风格化的商品摘要,例如浮夸风、科普风等。流量实验表明,浮夸风和科普风均有相当的提效。将风格化摘要文案加入文案优选池后,显著提升了广告效果。
图7:直通车摘要改进效果
在混剪工具中,受限于原有模型的长文案生成能力,剪辑得到的视频仅使用背景音乐,而缺乏商品解说。绘剪工作同样如此。我们将大模型生成的长文案引入混剪和绘剪中,支持设计亮点、卖点讲解、网红推荐、买家体验、凡尔赛文学、大促优惠等风格的文案解说,扩展了视频生成能力,为广告主提供了更全面的广告内容。
图8:智能文案引入绘剪和混剪
4.3 新业务的扩展和探索
更准、更好、更吸睛的文案生成
在基础的文案生成能力已经得到较大的满足后,我们将目光放在了高质量文案的生成方面。相比于简单的、平铺直叙的产品解说,有着精致的开头、形象化的表达、极强的感染力和号召力的视频文案无疑更能得到广告主和消费者的青睐。同时,优质文案的生成,也对文案的可控性有了更强的需求,控制精准的、广告主深度参与的文案生成也是一个很重要的命题。基于此,我们对模型的口语化水平、高质量开场白、形象化描述、文案可控性等进行了增强训练。我们筛选了高质量的商品解说视频,通过ASR获取其文案,并通过OCR、文本分类、大模型等对文案进行订正和关键信息提取,同时使用重放策略,加强输出和输出之间的连续,增强可控性。
基于上面的改进,我们对视频文案进行了升级,使得生成文案更适合视频解说,且更加的高质量。结合团队积累的视频相关技术,为广告主提供了高质量的多模态创意。
更可解释、可合理的关键词
关键词是广告召回阶段重要的一环,联系了人、货、词。原有的关键词来源相对局限,和商品强相关而与用户意图联系不强。借助于大模型长上下文的信息总结能力,我们从用户意图和更广泛的商品信息中,提取了关键词,实现了对关键词的升级和更新。大模型生成的关键词,在来源上,从标题扩展到了商品属性、商品详情页等;从语义上,是结合了用户意图的、对商品信息的高度总结。
5.展望
大模型是个高速发展的技术,大模型的应用也随着大模型的高速发展不断出现新的机会和新的范式。随着技术的不断积累和进步,业务的不断迭代和更新,我们对大模型应用的探索也逐渐深刻。在未来,大模型在广告智能文案生成方面,将会有越来越广泛、越来越深度的应用。我们以后可能的努力方向有以下几个:
1) 越来越大,探索大模型生成能力的极限,和广告主协同,生成更个性化的文案。现有的工作,主要范式是预先定义的生成模式结合特点的商品信息,文案类型的扩展依赖人工的发现和定义。广告主对商品的文案和投放效果的联系有着更深刻的认识,和广告主协同,生成更个性化的文案,是一个很有潜力的发展方向。我们猜测,这种个性化、丰富的输入和思考的能力,在更大的模型规模下,会有更好的效果。因此,通过更大规模的模型,探索大模型在文案生成方面的极限,是一个可能的问题。
2) 越来越小,通过极高质量的数据,降低业务的成本。微软在phi上的成功表明了,小规模的模型加极高质量的数据,有可能复现较大规模模型加大规模数据的效果,而国内的开源大模型,类如QWen,也在逐渐探索小规模模型的能力。考虑到小规模模型在训练、部署、推理、服务等方面,都有着一定的优势,因此在未来,将某些或者某类的文案生成任务,逐渐迁移或者改造到小规模模型上,是一个可能的显著降低业务成本的方法。
3) 大模型的世界知识的探索和应用。大模型从海量的预训练数据中,获取了海量的世界知识,这些世界知识不但体现在文案生成任务中,简单的增强数据的强泛化性上,也应该体现在对商品本身的理解、对用户偏好的联想和对未来的推断中。从大模型中提取这方面知识,可以扩展文案生成推断能力,提供情理之中的、辅助广告主畅想的文案,提供“眼前一亮”的闪光点,想广告主所不及,从而打造优势壁垒。
▐ 关于我们
我们是阿里妈妈智能创作与AI应用,专注于图片、视频、文案等各种形式创意的智能制作与投放,以及短视频多渠道投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP和推荐系统相关背景同学加入!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK