

开源delta lake 3.0 优势和发展
source link: https://zhuanlan.zhihu.com/p/694991321
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

开源delta lake 3.0 优势和发展
导读 本文将分享 Delta Lake 3.1 版本的最新特性。
主要包括以下三大部分:
1. Delta Lake 发布版本介绍
2. Delta Lake 3.1 最新特性
3. Delta Lake 测评和比较
分享嘉宾|刘兆磊 databricks staff software engineer
编辑整理|张昂
内容校对|李瑶
出品社区|DataFun
01
Delta Lake 发布版本介绍
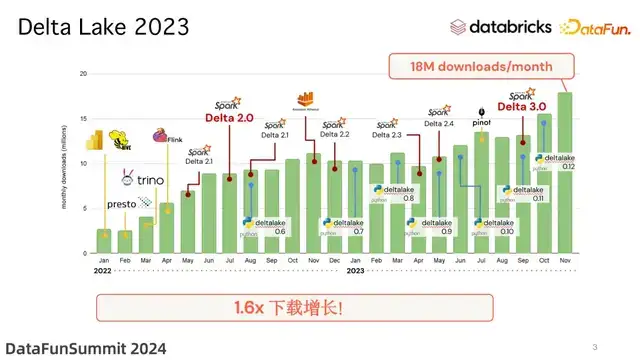
在 2023 年,Delta Lake 经历了从 2.x 版本到 3.x 版本的更新,最为主要的是 Delta Lake 3.0 这个重大版本的发布。在过去一年间,无论是发布的 feature 的数量,还是下载的数量,都有显著的增长。目前最新的版本是 3.1 版本,下面就来看一下 3.1 版本有哪些新特性。
02
Delta Lake3.1 最新特性
Delta Lake 3.1 版本中的最新特性包括:
- 将 Deletion Vector 加在了数据 Update 和 Merge 命令中,从而实现了这两个命令的加速;
- count/min/max 操作通过元数据查询优化;
- Universal Format(Iceberg)统一格式,写入 Delta 可以同时产生 Hudi、Iceberg 等元数据,使得在不同引擎中可以通过不同格式来访问数据;
- Delta Sharing 支持直接查询被 Delta Share 的表;
- Delta Kernel dataskipping 内核支持基于 count/min/max 的数据跳过;
- Delta Flink 启动延迟优化。
本次分享主要对前 3 个新特性进行重点讲解。
1. Deletion Vector 删除向量
在 Deletion Vector 之前,更新一行需要重写整个文件。有了 Deletion Vector 之后,如果需要更新 file002.parquet 这个文件的第 2 行数据,只需要将更新的数据写入到 file024.parquet 这个新文件,然后在元数据中记录 file002.parquet 的删除信息和 file024.parquet 这个新文件的信息即可完成。
Delta Lake 3.1 在将 Deletion Vector 加在了数据 Update 和 Merge 命令中后,表数据的写入速度提升显著(见左侧图),但是对于数据读取性能影响不大(见右侧图)。
Deletion Vector 在 Iceberg 和 Hudi 中也通过其它方式实现。Iceberg 在format version 2 里支持 merge on read,是通过支持“delete file”实现的,相当于一个独立的文件;Hudi 支持 merge on read,是通过 row based change log 文件实现。这两种实现方式在读取 MOR 表时均需读取额外的数据文件及计算,性能会有一定损失。Delta Lake 可以在元数据里写入 Deletion Vector,不需要读取额外数据,这也就是 Delta Lake 在读取性能方面影响不大的原因。
2. 元数据查询优化
一般执行查询的过程是,先通过表元数据得到数据文件列表,然后通过引擎读取所有数据文件执行聚合操作。如果查询的表特别大,需要读取所有的文件,则性能较慢。
Delta Lake 3.1 会在元数据中加入一些统计信息(如上图所示),在进行count/min/max 操作时,不用读取实际文件数据,可直接通过查询元数据获得结果,速度得到了大幅提升。
3. Universal Format 统一格式
不同平台有各自的生态系统,对数据的支持度有差异。Delta Lake Universal Format 统一格式的理念,是为了打破不同平台数据兼容的问题,让所有引擎都可以无障碍地读取数据,这是 3.1 版本的一个重要特征。
Universal Format 统一格式的实现方式是,在数据写入 Delta Lake 时,产生其它数据湖(Iceberg 和 Hudi)适配的元数据,保证同一份表支持不同引擎对数据的访问。
具体流程为,当一个 Delta 写入发生,即插入或创建一个表,首先 Delta 会产生自己的元数据和 transaction log,提交给底层 S3 或 HDFS 等存储系统。因为 Delta 是基于文件系统的,一般不需要 catalog 或 Hive Metastore,所以在写完文件系统后就结束了。Delta Lake 统一格式在写完 Delta 后,会将 Delta 的元数据转换为 Iceberg 或 Hudi 的元数据,因为 Iceberg 需要 Hive metastore 或其它 catalog 去存元数据的位置和版本信息,Delta Lake 就会将 Iceberg 的元数据提交给 Hive metastore,这样不同引擎查询时既可以使用支持 Delta 的查询,也可以通过支持 Iceberg 的引擎来查询。这样就实现了一份数据被不同格式访问。
Uniform Iceberg 已在 Delta Lake 3.1 版本里正式发布,对于 Hudi 的支持也即将发布。
03
Delta Lake 测评和比较
在北美地区,数据湖主流三大格式为 Delta、Hudi 和 Iceberg。这三种数据湖背后有不同的组织,具体的功能特性如下:
这三种格式都支持 merge on read,有利于提升写入和更改的性能。对应 file size,不同格式也有不同的优化方法,比如 Delta 通过 optimized write 功能,在写入时自动选择合适的文件大小,Hudi 和 Iceberg 也有类似的功能,不过 Iceberg 需要手动操作。在 data layout 方面,三种格式都支持 zorder,这已经是一项成熟的功能,来改善读取性能。三种格式也都支持 ACID guarantee,不同点是 Iceberg 的 transaction 是在 catalog 上实现的,而 Delta 和 Hudi 则是通过一个单独的服务实现的,会更灵活也相对更复杂。
Delta Lake 的读写性能在一些评测结果中表现优异。评测结果如下:
由于评测会和真实生产环境中存在差异,因此建议要根据实际业务情况选择合适的格式。
以上就是本次分享的内容,谢谢大家。

Recommend
-
66
Reading Delta Lake Tables natively in PowerBI Working with analytical data platforms and big data on a daily basis, I was quite happy when Microsoft finally
-
8
SmartData Collective > Big Data > Data Lake
-
9
Diving deeper into Delta Lake Reading Time: 6 minutes In this blog, I am going to explain about delta lake. Now before tak...
-
4
Delta Lake To the Rescue Reading Time: 4 minutesWelcome Back. In our previous blogs, we tried to get some insights about Spark RDDs and also tried to explore some new things in Spark 2.4. You can go through thos...
-
9
Time Travel: Data versioning in Delta Lake Reading Time: 3 minutes In today’s Big Data world, we process large amounts of data continuously and store the resulting data into data lake. This keeps changing the s...
-
9
Native Delta Lake Connector for Presto ·Co-authors Denny Lee, Sr. Staff Developer Advocate at Databricks This is a joint publication by the PrestoDB and Delta...
-
4
数据湖表格式比较(Iceberg、Hudi 和 Delta Lake) 表...
-
4
This article was published as a part of the Data Science Blogathon. Introduction Delta lakes lakehouses have gained tremendous popularity due to the support...
-
4
Databricks Delta Lake - A Friendly Intro This article introduces Databricks Delta Lake. A revolutionary storage layer that brings reliability and improve performance of data lakes using Apache Spark. First, we'll go through the dry...
-
8
数据湖仓比较:Apache Hudi、Delta Lake、Apache Iceberg
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK