

JDBC 批量调用数据库 SQL, 函数与存储过程
source link: https://yanbin.blog/jdbc-batch-sql-function-procedure/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

JDBC 批量调用数据库 SQL, 函数与存储过程
继续上一篇数据库相关操作的话题,在有大量的数据操作时(如增删改,甚至调用函数或存储过程),我们应该尽可能的采用批量化操作(先摆下结论,后面我们会看到原由)。想像一下我们要向数据库插入 10 万条记录,如果逐条插入的话,客户端与数据库之间将会有 10 万网络请求响应来回; 而假如以 1000 条记录为一个 batch, 客户端与数据库之间的网络请求响应次数将缩小到 100。 业务数据的内容总量未变,但 Batch 操作除了可重用预编译的 Statement 外还, 可避免每次请求中重复的元数据,所以从 100,000 到 100 的缩减在时效上的表现是非常可观的,有时就是 60 分钟与 1 分钟的区别(在最后面测试结果显示这一差异更为恐怖)。
当然, JDBC 的批处理功能具体还要相应驱动的支持,通过数据库连接的 conn.getMetaData().supportsBatchUpdates() 可探知是否支持批量操作。
API 方面, 在 Statement 接口中定义了如下 batch 相关的操作方法
- void addBatch(String sql): 将显式的 SQL 语句编入到当前 Batch 中
- void clearBatch(): 清除当前 Batch 列表,以便于建立新的 Batch
- int[] executeBatch(): 执行当前 Batch 列表中的语句,返回每条语句受影响行数组成的数组。0 可能表示执行语句无法确知受影响的行
- long[] executeLargeBatch(): 当 Batch 中语句受影响行数可能会超过整数最大值时用这个
另外在 Statement 的子接口 PreparedStatement 中定义了
- void addBatch(): 当动态 SQL 语句,函数和存储过程也支持 Batch 操作
而 CallableStatement 是 PreparedStatement 的子接口,所以数据库函数和存储过程也能 Batch 操作
执行 Batch 时只有 executeBatch() 或 executeLargeBatch(),它们只用来更新,没有像 executeQuery() 这样的方法或获得查询数据。如果简单的用 Statement 同时执行多条语句的话,可用分号对多条语句进行分隔,然后用 getMoreResults() 去遍历 ResultSet.
下面开始各种演示
我们要使用的数据库是 PostgreSQL, 预先创建一个表并插入几条记录
create table users( id serial, name varchar(32), age int insert into users(name, age) values ('Scott', 20), ('Tiger', 18), ('Rose', 5); |
Statement 执行多条语句获得多个 ResultSet
private static void testReturnMultipleResultSets() throws SQLException { Connection conn = dataSource.getConnection(); Statement stmt = conn.createStatement(); stmt.execute("select * from users; select * from users where id=1"); System.out.println("--- first result ---"); ResultSet rs = stmt.getResultSet(); while (rs.next()) { System.out.println(rs.getString("name")); System.out.println("--- more results ---"); while (stmt.getMoreResults()) { rs = stmt.getResultSet(); while (rs.next()) { System.out.println(rs.getString("name")); |
注:连接从一个连接池中,另外本文所有代码中未处理资源的关闭,实际应用中必须正确的关闭数据 ResultSet, Statement, 和 Connection 资源。这里只是为了演示同时执行分号隔开的多条语句,当然,同质的 SQL 语句写成 UNION 查询就行了。
以上代码执行得到了两个 ResultSet, 输出如下
--- first result ---
Scott
Tiger
Rose
--- more results ---
Scott
用 Statement 也可以批量执行像 update/delete 等操作,但如何获得 ResultSet 就像多加验证了。例如我们可以执行
stmt.execute("delete from users where id=1; update users set age=1 where id=2; select * from users"); |
addBatch(String sql), executeBatch() 的批量操作
接下来开始体验 Statement 的 addBatch(String sql), executeBatch() 那样的批量操作
private static void executeBatch() throws SQLException { Connection conn = dataSource.getConnection(); Statement stmt = conn.createStatement(); for (int i = 1; i <= 5; i++) { stmt.addBatch("insert into users(name, age) values('%s', 10)".formatted("user" + i)); int[] affected = stmt.executeBatch(); System.out.println(Arrays.toString(affected)); |
输出为每条语句所影响的行数
[1, 1, 1, 1, 1]
若要重用 Statement 进行多次 Batch 操作的代码是
stmt.addBatch(sql1); stmt.addBatch(sql2); ...... stmt.executeBatch(); stmt.clearBatch(); stmt.addBatch(sql3); stmt.addBatch(sql4); ...... stmt.executeBatch(); |
Batch 和非 Batch 时,数据库客户端与服务端间的交互我们可以观察通讯数据包。
如与执行单条语句时
stmt.execute("insert into users(name, age) values('user1', 10)"); |
的网络数据报文对比就是
执行单条语句:
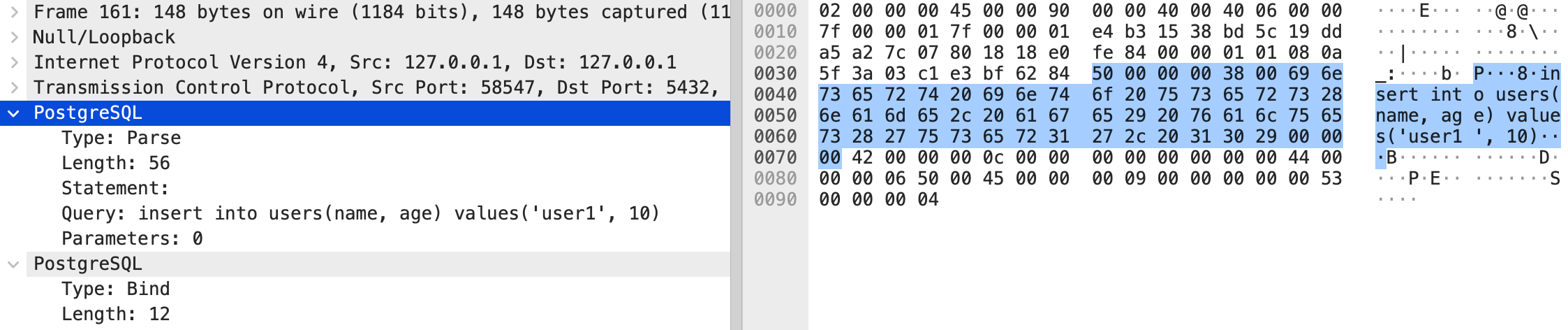
executeBatch() 执行多条语句时
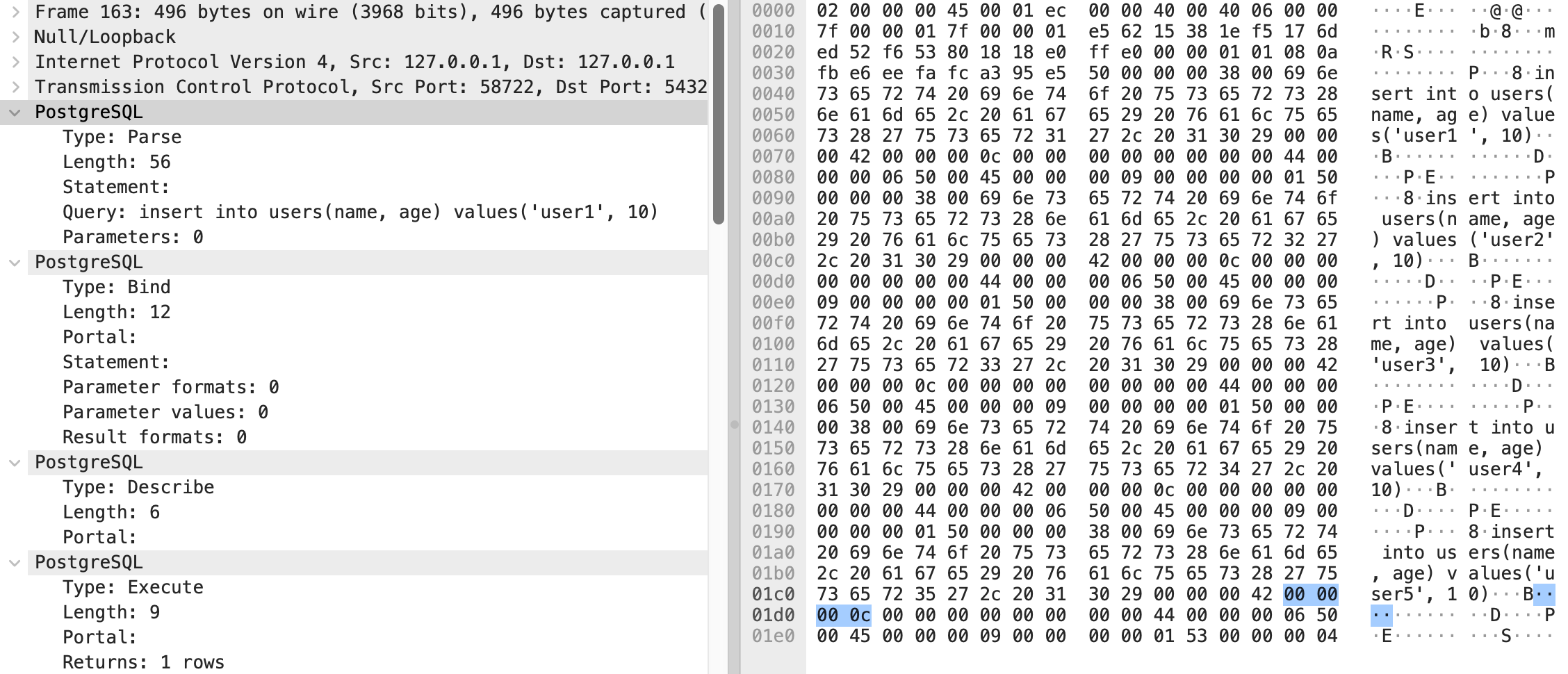
addBatch(String sql) 只是减少了网络请求次数,但在报文中的 SQL 语句仍然是简单重复。如果用 PreparedStatement 的方式进行 Batch 将只会传送一次 SQL 语句, 再往下看
更高效的 PreparedStatement 批量操作
如果使用 PreparedStatement 则只需要发送 SQL 语句一次,然后伴随着每次执行需要不同的参数组,
private static void executePrepareStatementBatch() throws SQLException { Connection conn = dataSource.getConnection(); PreparedStatement pstmt = conn.prepareStatement("insert into users(name, age) values(?, ?)"); for (int i = 1; i <= 5; i++) { pstmt.setString(1, "user" + i); pstmt.setInt(2, 10); pstmt.addBatch(); int[] affected = pstmt.executeBatch(); System.out.println(Arrays.toString(affected)); |
执行的输出自然还是一样的
[1, 1, 1, 1, 1]
此时我们再来看看数据报文,有两个基本的报文
发送 SQL 语句到数据库,将得到一个预编译语句的句柄
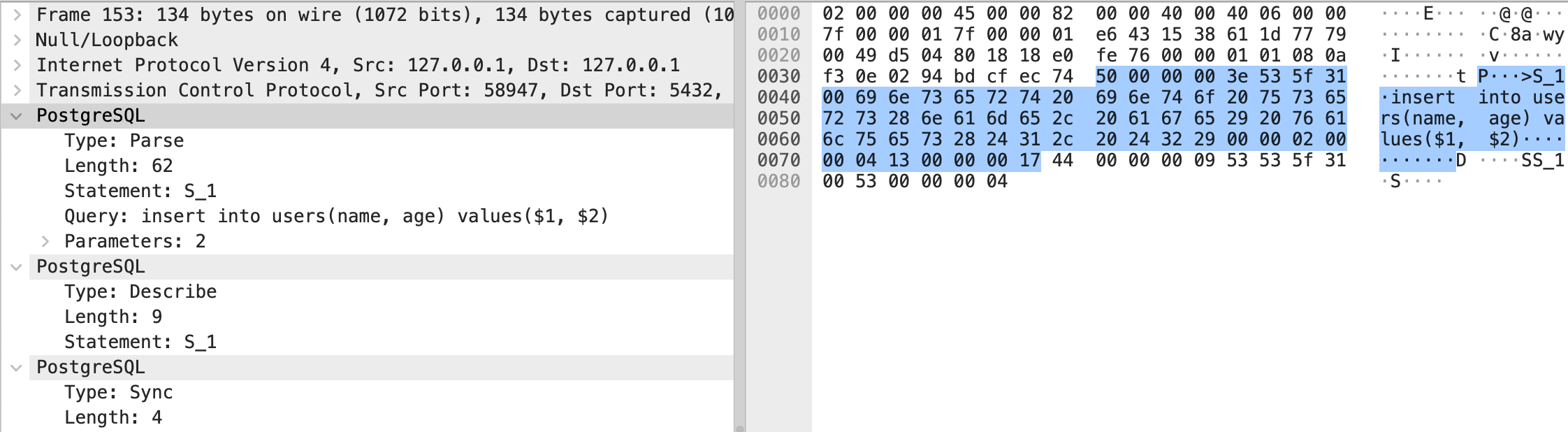
最后发送所有批量操作时的 Statement ID, 这里是 (S_1) 和参数组,如 (user1, 10), (user2, 10), (user3, 10), (user4, 10), (user5, 10)
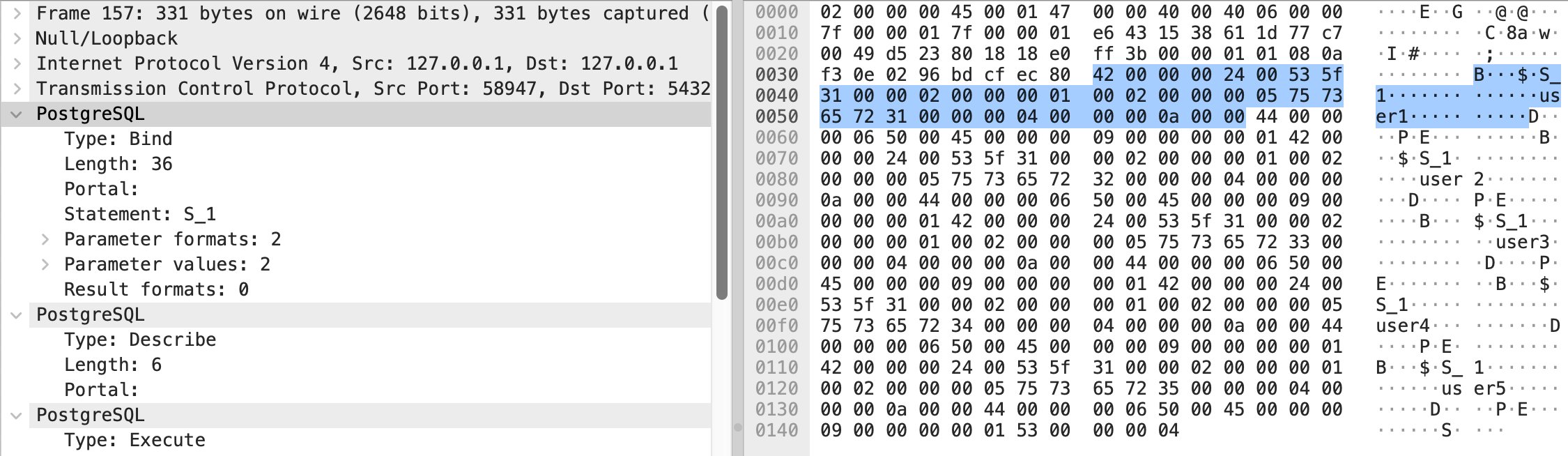
所以当我们使用 JDBC 时希望能采用 Batch 操作改善性能时十分有必要考虑 PreparedStatement 的 Batch 操作,而非 addBatch(String sql) 的简单堆叠 -- 从后面的测试来看这两种方法性能上差异产不大。
Batch 操作调用数据函数与存储过程
如果是以 select func1(?, ?) 的方式调用函数,那和普通 insert/delete/update 等操作没什么分别,这里只尝试 {? = call func1(?, ?)} 或 call proc1(?, ?) (用 Spring JdbcTemplate 调用存储过程也要写成 {call proc1(?, ?)}) 调用的批量操作。由于暂时未找到 executeBatch() 返回每条语句结果(集)的办法,所以 Batch 操作函数时只能忽略掉返回值,剩下要做的就是如何用 Batch 调用存储过程了, 或者说把数据库函数当成存储过程来调用。
我们创建一个数据库函数
create or replace function insert_user_fn(p_name character varying, p_age int) returns integer language plpgsql declare var_count integer; begin insert into users(name, age) values(p_name, p_age); select lastval() into var_count; return var_count; |
把上面的 function 替换成 procedure, 再去掉 returns void, return var_count 就是一个存储过程了
其实和 PreparedStatement 没什么区别,见代码如下
private static void batchCall() throws SQLException { Connection conn = dataSource.getConnection(); CallableStatement call = conn.prepareCall("{call insert_user_fn(?, ?)}"); for (int i = 1; i <= 5; i++) { call.setString(1, "user" + i); call.setInt(2, 10); call.addBatch(); int[] affected = call.executeBatch(); System.out.println(Arrays.toString(affected)); |
唯一的不同就是 conn.prepareCall() 中的语句不一样,然后就是打印出的 affected 不同
[0, 0, 0, 0, 0]
全为零并非每次执行时未产生效果,而是调用函数或存储过程时无法获知明确的受影响行数
对于 PostgreSQL 虽然写成了用 {call insert_user_fn(?, ?)} 来调用函数,但驱动会转换为 select 语句
select * from insert_user_fn($1, $1) as result
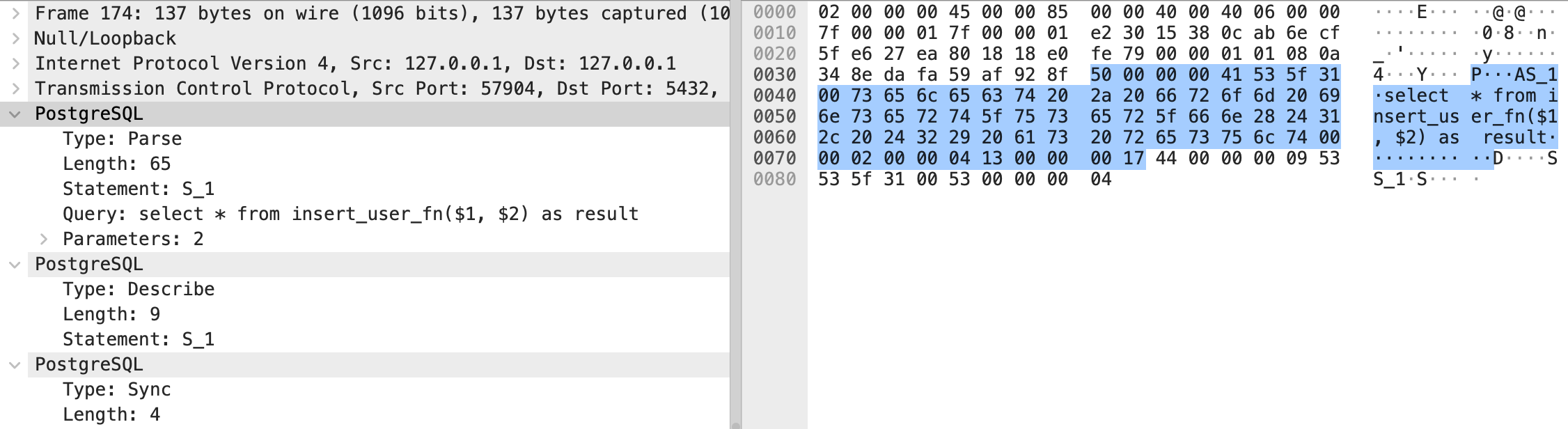
而后的套入参数批量操作与 PreparedStatement 是一样的,只是无法获得每次操作的返回值
在 PostgreSQL 中如果操作一个真正的存储过程
create or replace procedure insert_user_pr(p_name character varying, p_age int) language plpgsql begin insert into users(name, age) values(p_name, p_age); |
直接用 JDBC 操作存储过程时,语句的写法不能用大括号括起来(Spring 的 JdbcTemplate 需以一致的方式 {call insert_user_pr(?, ?)} 来调用存储过程)
private static void batchCall() throws SQLException { Connection conn = dataSource.getConnection(); CallableStatement call = conn.prepareCall("call insert_user_pr(?, ?)"); for (int i = 1; i <= 5; i++) { call.setString(1, "user" + i); call.setInt(2, 10); call.addBatch(); int[] affected = call.executeBatch(); System.out.println(Arrays.toString(affected)); |
发送到数据库端的语句就不是 select * from insert_user_pr($1, $2) 了,而是 call insert_user_pr($1, $2)

输出也是一样无法判定每次执行影响的行数
[0, 0, 0, 0, 0]
文中小节一下 JDBC 如何进行批量操作
- 判断数据库或 JDBC 驱动能不能支持批量操作,可通过 conn.getMetaData().supportsBatchUpdates() 获知
- 简单的批量操作可由 Statement 的 execute(), executeQuery(), executeUpdate() 执行分号分隔的多条 SQL 语句
- Statement 的 addBatch(String sql) 可进行静态 SQL 的批量操作
- PreparedStatement 的 addBatch() 可对带参数的 SQL, 函数和存储过程进行批量操作
逐条语句与批量操作的性能对比
我们为什么要选择 JDBC 批量操作,关键就是性能,前面只是从理论上分析了批量操作可获得较好的性能,但这个好有多好,有没有一个量级的差别,还需要有一个感性的对比数据。为此我们用以下三个方法来看每次往一个新创建的空表中插入 10 万条记录的各自时长
为体现出实际应用中的网络因素,测试用的是一个远程数据库
public class TestBatchPerformance { public static void main(String[] args) throws SQLException { Connection conn = dataSource.getConnection(); long start = System.currentTimeMillis(); insertOneByOne(conn); System.out.println("timeMs: " + (System.currentTimeMillis() - start)); private static void insertOneByOne(Connection conn) throws SQLException { Statement stmt = conn.createStatement(); for (int i = 1; i <= 100_000; i++) { stmt.execute("insert into users(name, age) values('%s', 10)".formatted("user" + i)); private static void executeBatch1(Connection conn, int batchSize) throws SQLException { Statement stmt = conn.createStatement(); for (int i = 1; i <= 100_100; i++) { stmt.addBatch("insert into users(name, age) values('%s', 10)".formatted("user" + i)); if(i % batchSize == 0) { stmt.executeBatch(); stmt.clearBatch(); private static void executeBatch2(Connection conn, int batchSize) throws SQLException { PreparedStatement stmt = conn.prepareStatement("insert into users(name, age) values(?, ?)"); for (int i = 1; i <= 100_100; i++) { stmt.setString(1, "user" + i); stmt.setInt(2, 10); stmt.addBatch(); if(i % batchSize == 0) { stmt.executeBatch(); stmt.clearBatch(); |
下面是不同调用时统计的时长(单位为毫秒)
| 方法调用 | BatchSize | 批处理方式 | 耗时(毫秒) | 说明 |
| insertOneByOne | N/A | N/A | 6186544 | 1 小时 43 分 6 秒, 16.17 记录/s |
| executeBatch1 | 1000 | Statement.addBatch(sql) | 31243 | 31 秒, 3.2 batch/s, 3200 记录/s |
| executeBatch2 | 1000 | PreparedStatement.addBatch() | 30684 | 30 秒 |
| executeBatch1 | 2000 | Statement.addBatch(sql) | 31700 | 31 秒 |
| executeBatch2 | 2000 | PreparedStatement.addBatch() | 30590 | 30 秒 |
以上的测试结果应该够冲击力吧,还有什么理由在进行大批量操作时不采用 Batch 吗?至于是用 Statement.addBatch(sql) 还是 PreparedStatement.addBatch() 性能上并不没本质上的差别。现实在多为执行动态的 SQL 语句(含函数与存储过程),为防止可能的 SQL Injection, 多考虑用 PreparedStatement.addBatch() 的方式。
最后一个遗留问题: 是否能在批量调用函数时获得每次的返回值?
从本人目前所找到的资料来看,executeBatch() 可用来批量执行 insert/update/delete 语句,以及函数和存储过程,但无法获得函数的返回值和 OUT 参数。
下方的代码调在执行 cstmt.executeBatch() 时会报错
private static void batchCallFunctionGetReturn(Connection conn) throws SQLException { CallableStatement cstmt = conn.prepareCall("{? = call insert_user_fn(?, ?)}"); cstmt.registerOutParameter(1, Types.INTEGER); cstmt.setString(2, "yy"); cstmt.setInt(3, 3); cstmt.addBatch(); cstmt.executeBatch(); |
Exception in thread "main" java.lang.IllegalArgumentException: can't getV3Length() on a null parameter
at org.postgresql.core.v3.SimpleParameterList.getV3Length(SimpleParameterList.java:434)
at org.postgresql.core.v3.QueryExecutorImpl.sendBind(QueryExecutorImpl.java:1690)
at org.postgresql.core.v3.QueryExecutorImpl.sendOneQuery(QueryExecutorImpl.java:2014)
at org.postgresql.core.v3.QueryExecutorImpl.sendQuery(QueryExecutorImpl.java:1534)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:565)
at org.postgresql.jdbc.PgStatement.internalExecuteBatch(PgStatement.java:912)
at org.postgresql.jdbc.PgStatement.executeBatch(PgStatement.java:936)
注册了 OUT parameter 的函数或存储过程不能用 executeBatch() 执行,那么直接 select 函数不注册 OUT parameter 会怎么样呢?
下面的代码试图 executeBatch 调用函数,获得结果
private static void callFunctionGetReturn(Connection conn) throws SQLException { PreparedStatement pstmt = conn.prepareStatement("select insert_user_fn(?, ?)"); pstmt.setString(1, "yy"); pstmt.setInt(2, 3); pstmt.addBatch(); pstmt.executeBatch(); ResultSet rs = pstmt.getResultSet(); if(rs.next()) { System.out.println(rs.getObject(1)); |
pstmt.executeBatch() 执行没问题,但是 pstmt.getResultSet() 是 null
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "java.sql.ResultSet.next()" because "rs" is null
同样走不通。既要用 Batch, 又想从 Batch 中每条语句中获得返回结果的念头该断绝了。
附一段执行 insert 语句后如何获得自增 ID 值的代码
private static void insertGetGeneratedKey(Connection conn) throws SQLException { PreparedStatement pstmt = conn.prepareStatement( "insert into users(name, age) values('xx', 5)", Statement.RETURN_GENERATED_KEYS); pstmt.execute(); // or pstmt.executeUpdate(); ResultSet rs = pstmt.getGeneratedKeys(); if (rs.next()) { System.out.println(rs.getInt(1)); |
private static void insertGetGeneratedKey(Connection conn) throws SQLException { Statement stmt = conn.createStatement(); stmt.executeUpdate("insert into users(name, age) values('xx', 5)", Statement.RETURN_GENERATED_KEYS); ResultSet rs = stmt.getGeneratedKeys(); if (rs.next()) { System.out.println(rs.getInt(1)); |
上面两段代码可用来替代之前的 returning id 写法
private static void insertGetGeneratedKey(Connection conn) throws SQLException { Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("insert into users(name, age) values('xx', 5) returning id"); if (rs.next()) { System.out.println(rs.getInt(1)); |
Statement.RETURN_GENERATED_KEYS 只能用于返回自动产生的 ID 上,而 returning 可返回当前插入记录的任意字段,如
insert into users(name, age) values('xx', 5) returning name
看来只能打消 executeBatch() 时获得函数返回值或存储过程 OUT 的参数了。
对于试图 Batch 方式调用函数或存储过程,还希望得到每次调用的返回值时,我们必须转换一下思维,有必要改造函数或存储过程,使之能处理 Table 或对象数组输入,输出 Table 或 Cursor, 也就是说让函数或存储过程自身具体批处理的能力。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK