

线程池的运行逻辑与你想象的不一样,它是池族中的异类 - 顾志兵
source link: https://www.cnblogs.com/guzb/p/18108245/difference-of-thread-pool-implementation
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

只要是 web 项目,程序都会直接或间接使用到线程池,它的使用是如此频繁,以至于像空气一样,大多数时候被我们无视了。但有时候,我们会相当然地认为线程池与其它对象池(如:数据库连接池)一样,要用的时候向池子索取,用完后归还给它即可。然后事实上,线程池独树一帜、鹤立鸡群,它与普通的对象池就是不同。本文本将先阐述这种差异,接着用最简单的代码实现一个线程池,最后再对 JDK 中与线程池相关的 Executor 体系做一个全面介绍。
线程池与普通资源池的差异
提到 pool 这个设计思想,第一反映是这样的:从一个资源容器中获取空闲的资源对象。如果容器中有空闲的,就直接从空闲资源中取出一个返回,如果容器中没有空闲资源,且容器空间未用尽,就新创建一个资源对象,然后再返回给调用方。这个容器就是资源池,它看起来就像这样:

图中的工人队伍里,有3人是空闲的,工头(资源池的管理者)可以任选两人来提供劳务服务。同时,队队伍尚未饱和,还可以容纳一名工人。如果雇主要求一次性提供4名劳工服务,则工头需要再招纳一名工人加入队伍,然后再向雇主提供服务。此时,这个团队(资源池)已达到饱和,不能再对外提供劳务服务了,除非某些工人完成了工作。
以上是一个典型资源池的基本特点,那么线程池是否也同样如此呢。至少第一感觉是没问题的,大概应该也是这样吧,毕竟拿从池中取出一个线程,再让它执行对应的代码,这听上去很科学嘛。等等,总感觉哪里不对呢,线程这东西能像普通方法调用那样,让我们在主程序里随意支配吗?没错,问题就在这里,线程一旦运行起来,就完全闭关锁国了,除了按照运行前约定好的方式进行数据通信外,再也不能去打扰它老人家了。因此,线程池有点像发动机,池中的各个线程就对应发动机的各个汽缸。整个发动机一旦启动(线程池激活),各个汽缸中的活塞便按照预定的设计,不停地来回运动,永远也不停止,直到燃油耗尽,或人为地关闭油门。在此期间,我们是不能控制单个汽缸的活动方向的。就如同我们不能控制正在运行的线程,让其停止正在执行的代码,转而去执行其它代码一样(利用 Thread.interrpt() 方法也达不到此目的,而 Thread.stop() 更是直接终止了线程)①。
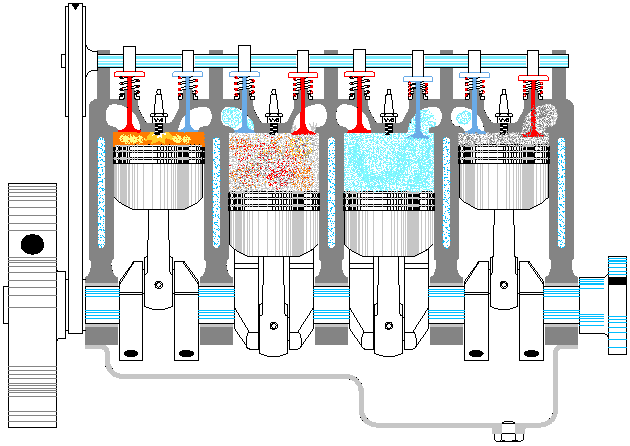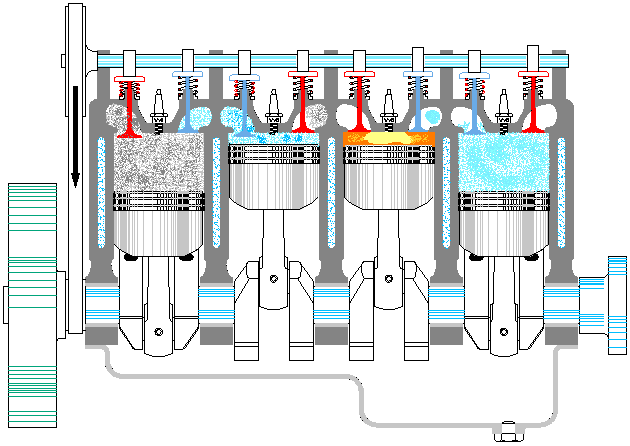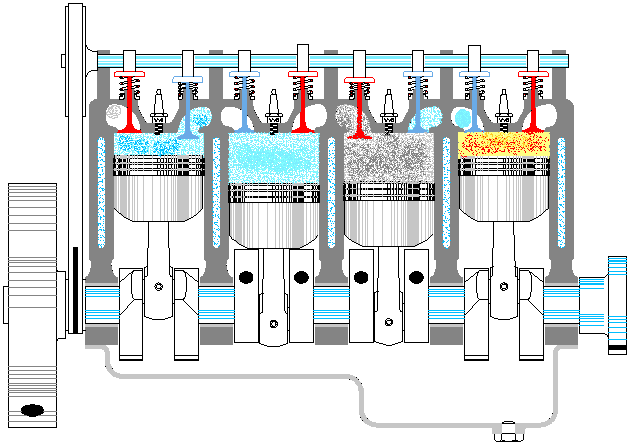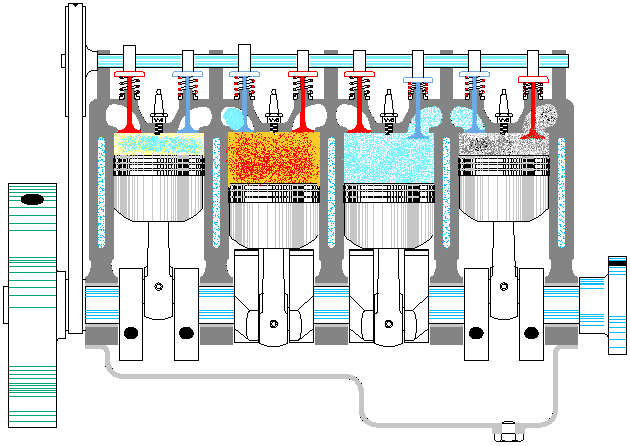
既然不能直接给线程池里的单个线程明确指派任务,那线程池的意义何在呢?意义就在于,虽然不能一对一精确指派任务,但可以给整个线程池提交任务,至于这些任务由池中的哪个线程来执行,则是不可控的。此时,可以把线程池看作是生产流水线上的单个工序。这里以给「老干妈香辣酱」的玻璃瓶加盖子为例,给瓶子加盖就是要执行的任务,最初该工序上只设置了一个机械臂,加盖子也顺序操作的。但单个机械臂忙不过来,后来又加了一个机械臂,这样效率就提高了。瓶子被加盖的顺序也是不确定的,但最终所有瓶子都会被加盖。
手动编写一个简易的线程池
如上小节所述,线程池与其它池类组件不一样,调用方不可能直接从池中取出一个线程,然后让它执行一段任务代码。因为线程一旦启动起来,就会在自己的频轨道内独立运行,不受外部控制。要让这些线程执行外部提交的任务,需要提供一个数据通道,将任务打包成一个数据结构传递过去。而这些运行起来的线程,他们都执行一个相同的循环操作:读取任务 → 执行任务 → 读取任务 → ...... ②
┌──────────┐ ┌──────────────┐ ┌─→ │Take Task │ -→ │ Execute Task │ ─┐ │ └──────────┘ └──────────────┘ │ └─────────────────────────────────────┘
这个读取任务的数据通道就是队列,池中的所有线程都不断地执行 ② 处的循环逻辑,这便是线程池运行的基本原理。
相对于线程池这个叫法,实际上「执行器 Executor」这个术语在实践中使用得要更多些。因为在 jdk 的 java.util.concurrent 包下,有一个 Executor 接口,它只有一个方法:
public interface Executor { void execute(Runnable command);}
这便是执行器接口,顾名思义,它接受一个 Runnable 对象,并能够执行它。至于如何执行,交由具体的实现类负责,目前至少有以下四种执行方式 ③
- 在当前线程中同步执行
- 总是新开线程来异步执行
- 只使用一个线程来异步串行执行
- 使用多个线程来并发执行
本小节将以一个简易的线程池方式来实现 Executor。
编写只有一个线程的线程池
这是线程池的最简形式,实现代码也非常简单,如下所示
public class SingleThreadPoolExecutor implements Executor { // 任务队列 private final Queue<Runnable> tasks = new LinkedBlockingDeque<>(); // 直接将任务添加到队列中 @Override public void execute(Runnable task) { tasks.offer(task); } public SingleThreadPoolExecutor() { // 在构造函数中,直接创建一个线程,作为为线程池的唯一任务执行线程 // 它将在被创建后立即执行,执行逻辑为: // 1. 从队列中获取任务 // 2. 如果获取到任务,则执行它,执行完后,返回第1步 // 3. 如果未获取到任务,则简短休息,继续第1步 Thread taskRunner = new Thread(() -> { Runnable task; while (true) { task = tasks.poll(); if (task != null) { task.run(); continue; } try { TimeUnit.MILLISECONDS.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); break; } } }); taskRunner.start(); }}
上述的单线程执行器实现中,执行任务的线程是永远不会停止的,获取到任务时,就执行它,没有获取到,就一直不断的获取。下面是这个执行器的测试代码:
public class SingleThreadPoolTest { public static void main(String[] args) throws InterruptedException { SingleThreadPoolExecutorstp stp= new SingleThreadPoolExecutor(); // 连续添加 5 个任务 for (int i = 1; i <= 5; i++) { stp.execute(new SpeakNameTask("Coding Change The World " + i)); } System.out.println("主线程已结束"); } // 一个模拟的任务:简单地输出名称 static class SpeakNameTask implements Runnable { private String name; public SpeakNameTask(String name) { this.name = name; } @Override public void run() { Random random = new Random(); int milliseconds = 500 + random.nextInt(1000); try { TimeUnit.MILLISECONDS.sleep(milliseconds); System.out.println("["+Thread.currentThread().getName()+"]: I believe " + name); } catch (InterruptedException e) { throw new RuntimeException(e); } } }}
下面是输出结果:
主线程已结束[Thread-0]: I believe Coding Change The World 1[Thread-0]: I believe Coding Change The World 2[Thread-0]: I believe Coding Change The World 3[Thread-0]: I believe Coding Change The World 4[Thread-0]: I believe Coding Change The World 5
可以看到:作为测试程序的主线程,已经先执行结束了,而线程池还在顺序地执行主线程添加的任务。并且线程池在执行完所有任务后,并没有退出,jvm 进程会一直存在。
改进为拥有多个线程的线程池
多线程版本的线程池执任务执行器,只是在单线程版本上,增加了执行线程的数量,其它的变化不是很大。但为了更好的组织代码,需要将任务执行线程的逻辑单独抽取出来。另外,为了模拟得更像一个池,本示例代码还增加了以下特性
-
支持核心线程数功能
核心线程数在执行器创建时,一起创建,并永不结束 -
支持最大线程数功能
当核心线程执行任务效率变慢时,增加执行线程 -
支持空闲线程移除功能
当非核心线程空闲时长超过限定值时,结束该线程,并从池中移除
主要代码如下:
MultiThreadPoolExecutor.java (点击查看代码)
public class MultiThreadPoolExecutor implements Executor { // 线程池 private final Set<TaskRunner> runnerPool = new HashSet<>(); // 任务队列 private final Queue<Runnable> tasks = new LinkedBlockingDeque<>(); // 单个线程最大空闲毫秒数 private int maxIdleMilliSeconds = 3000; // 核心线程数 private int coreThreadCount = 1; // 最大线程数 private int maxThreadCount = 3; public MultiThreadPoolExecutor() { // 初始化核心线程 for (int i = 0; i < coreThreadCount; i++) { addRunner(true); } } private void addRunner(boolean isCoreRunner) { TaskRunner runner = new TaskRunner(isCoreRunner); runnerPool.add(runner); runner.start(); } @Override public void execute(Runnable task) { tasks.add(task); addRunnerIfRequired(); } // 视情况增加线程数,这里简化为当任务数超过线程数的两倍时,就增加线程 private void addRunnerIfRequired() { if (tasks.size() <= 2 * runnerPool.size()) { return; } // 未达到最大线程数时,可增加执行线程 if (runnerPool.size() < maxThreadCount) { synchronized (this) { if (runnerPool.size() < maxThreadCount) { addRunner(false); } } } } class TaskRunner extends Thread { // 是否为核心线程 private final boolean coreRunner; // 已空闲的毫秒数 private long idleMilliseconds = 0; TaskRunner(boolean coreRunner) { this.coreRunner = coreRunner; } @Override public void run() { Runnable task; while (true) { task = tasks.poll(); if (task != null) { task.run(); continue; } try { TimeUnit.MILLISECONDS.sleep(10); idleMilliseconds += 10; if(coreRunner) { continue; } if (idleMilliseconds > maxIdleMilliSeconds) { // 超过最大空间时间,线程结束,并从池中移徐本线程 runnerPool.remove(this); break; } } catch (InterruptedException e) { e.printStackTrace(); break; } } } }}
完整代码已上传至 thread-pool-sample
其实多线程版本的主要难点,是判定增加新线程来执行任务的算法,即如何确定当前需要添加新线程,而不是保持当前的线程数量来执行任务,以保证最高的效率。以这个粗糙的原始版本为基准,不断丰富细节和增强健壮性,就可以慢慢演进出 Jdk 中的 Executor 体系。
JDK 线程池任务执行器浅析
Executor 体系类结构
Executor 接口是任务执行器的顶级接口,它仅定义了一个方法,但并未限制如何执行传递过来的任务。正如第③处所述,「线程池执行」也只是多种方式中的一种,也是用得最多的一种。由于 Executor 接口定义的功能过于单一,于是在 JDK 的并发包下,又对它进行了扩展,这个扩展就是 ExecutorService,如下所示:
public interface ExecutorService extends Executor { Future<?> submit(Runnable task); <T> Future<T> submit(Callable<T> task); <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException; <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit) throws InterruptedException; <T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException; <T> T invokeAny(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; void shutdown(); List<Runnable> shutdownNow(); boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException; boolean isShutdown(); boolean isTerminated();}
这些扩展方法共分为三组,分别是:任务提交类、状态控制类、状态检查类。从分类上可以看出,ExecutorService 增加了「提交任务」的概念(相对于 Executor 的「执行任务」)。另外,还有「关闭」操作,以及检测执行器当前的状态,这些都是 Exector 不具备的。下面这个分类列表更加清晰:
-
方法 异步提交 批量提交 超时等待 submit(Runnable task) √ submit(Callable task) √ invokeAll(Collection<? extends Callable> tasks) √ invokeAll(Collection<? extends Callable> tasks,long timeout, TimeUnit unit) √ √ invokeAll(Collection<? extends Callable> tasks) √ invokeAny(Collection<? extends Callable> tasks,long timeout, TimeUnit unit) √ √ -
- shutdown()
- shutdownNow()
- awaitTermination(long timeout, TimeUnit unit)
-
- isShutdown()
- isTerminated()
除了增加了新的方法外,还新增加了一种任务类型,即:java.util.concurrent.Callable,而 Executor 接口定义的任务接口是 java.lang.Runnable。二者的区别是,Callable#call() 方法有返回值,而后者没有。一般而言,任务提交给执行器后,通常都会异步执行。提交任务的线程是拿不到这个 call() 方法执行完毕后的返回值的,既然这样,那定义这个有返回值的方法还有什么意义呢?
为了拿到返回值,引入了 java.util.concurrent.Future 接口,它定义了获取单个异步任务执行结果的方法,不仅如此,它还定义了其它一些访问和控制单个任务的方法,见下表:
| 方法 | 解释 |
|---|---|
| get() | 阻塞调用线程,直到所关联的任务执行结束,拿到返回值,或任务执行结束(取消操作和发生异常均会导致结) |
| get(long timeout, TimeUnit unit) | 同上,但会有一个最大等待时长,若超过该时长后,任务依然未执行结束,则结束等待,并抛出 TimeoutException |
| cancel(boolean mayInterruptIfRunning) | 尝试取消关联的任务,只是尝试,遇到以下情况,均无法取消 · 任务已经取消 · 任务已完成 · 其它原因 通常任务一旦开始执行,就无法取消, 除非是极其特定的任务,这类任务的代码本身会与外界通信,判断是否应该取消自己的执行。 因此本方法提供了一个 mayInterruptIfRunning 参数,用来做这种信息传达, 但也仅仅是一个信息传达,表达了期望已运行的任务能自我终止, 但能否真的终止,取决于任务本身的代码逻辑 |
| isCancelled() | 检测关联的任务是否已「取消」 |
| isDone() | 检测关联的任务是否已「结束」,任务正常执行完毕、遭遇异常和被取消均视为任务已「结束」 |
📌 特别说明
Future#cancel() 方法只是从执行角度上讲,取消了任务的执行。它没有 “回滚” 这种业务上的含义。对于接受 mayInterruptIfRunning 参数的任务,若要实现 “回滚”效果,需要任务自身代码来实现
Future 只是一个接口,要怎么来实现接口的这些功能呢,以 get() 方法为例,大致分为以下3步:
- 在 Future 实现类的内部持有它要访问和控制的 Callable 任务实例、执行该任务的线程以及任务执行结果。
- Future 实现类自己要实现 Runnable 接口, 并在 Runnable#run() 方法实现中,调用真实任务 Callable 的 run 方法并获取返回值,然后将返回值写入到 Future 实现类的「任务执行结果」字段中。这样一来,Executor 直接要执行的方法就从原始的 Callable 实例,变成了 Future 实例。
- 有了上面两步,get() 方法实现就简单了,一直获取「任务执行结果」这个字段的值就可以了。
下而是 get() 方法的简化版(非线程安全)实现样例:
public class MyFutureImpl<T> implements Future<T>, Runnable { // 是否运行结束了 private volatile complete; // Callable 任务执行的结果 private volatile T result; // 实际执行 Callable 任务的线程 private volatile Thread runner; private Callable<T> task; public MyFutureImpl(Callable<T> task) { this.task = task; // ⑴ 持有真实任务实例 } @Override public void run() { this.runner = Thread.currentThread(); // ⚠️ ⑴ 持有实际执行此任务的线程 T result = task.call(); // ⑵ 调用真实任务的 call 方法,并在实际执行线程中获得返回值 this.complete = true; // ⚠️ Future 对象的状态设置为「完成」 this.result = result; // ⚠️ ⑵ 将实际执行线程中获得的返回值,回写到 Future 实例的字段中 } @Override public T get(long timeout, TimeUnit unit) { long remainsMillis = unit.toMillis(timeout); while( !complete ) { // ⚠️ ⑶ 检查任务是否执行完毕,未执行完毕则一直检查(更好的办法是阻塞自己) TimeUnit.MILLISECONDS.sleep(10); remainsMillis -= 10; if( remainsMillis <=0 ) { // 超时检查 throw new TimeoutException(); } } return this.result; // 任务已执行完毕,直接返回结果 }}
以上这个一点也不线程安全的 Future 实现类,由于去除了复杂的同步操作代码,核心逻辑反而更加清晰了。代码中有感叹号 ⚠️ 的地方,都是存在线程同步问题的。感兴趣的码友,在对这个基本的核心逻辑有了认知后,再去看 JDK 的源码就更加容易了(JDK 源码中,使用了 sun.misc.Unsafe 中的相关原子方法来处理并发问题)。
JDK 的并发包下,真实的 Future 实现类是 FutureTask, 它没有直接实现 Future, 因为根据实现步骤的第 2 步,实现类自身还需要实现 Runnable 接口, 因此,又增加了一个中间接口 RunnableFuture,该接口继承了 Runnable,而 FutureTask 直接实现的接口正是 RunnableFuture,如下图所示:

ExecutorService 的直接实现类是 AbstractExecutorService,这是一个抽象类,最终的实现类是 ThreadPoolExecutor。至此终于是回到本文的主题了,即线程池任务执行器,不过 JDK 并发包在此基础上还提供了一个扩展: ScheduledExeuctorService,所谓 Scheduled(可调度的),即可以安排提交的任务在什么时候执行,也就是经常提到的定时任务。OK,至此我们可以看到整个 Executor 体系的类继承结构了,如下图所示:

Executor 核心实现类
从 Executor 的继承类图中可以看出,最终实现类只有 ThreadPoolExecutor 和 ScheduledThreadPoolExecutor, 但实际上,大部分逻辑都在 AbstractExecutorService 这个抽象类中实现了。这三个类各自实现了整个 Executor 体系中的一部分方法,为更清晰地呈现它们之间的分工,我整理了这个体系下各个接口方法与对应实现类间的关系表,如下所示:
| Method | AbstractExecutorService | ThreadPoolExecutor | ScheduledThreadPoolExecutor |
|---|---|---|---|
| Executor#execute(Runnable command) | √ | ||
| ExecutorService#submit(Runnable task) | √ | ||
| ExecutorService#submit(Callable task) | √ | ||
| ExecutorService#invokeAll(Collection<? extends Callable> tasks) | √ | ||
| ExecutorService#invokeAll(Collection tasks,long timeout, TimeUnit unit) | √ | ||
| ExecutorService#invokeAny(Collection<? extends Callable> tasks) | √ | ||
| ExecutorService#invokeAny(Collection tasks,long timeout, TimeUnit unit) | √ | ||
| ExecutorService#shutdown() | √ | ||
| ExecutorService#shutdownNow() | √ | ||
| ExecutorService#awaitTermination(long timeout, TimeUnit unit) | √ | ||
| ExecutorService#isShutdown() | √ | ||
| ExecutorService#isTerminated() | √ | ||
| ScheduledExecutorService#schedule(Runnable command,long delay, TimeUnit unit) | √ | ||
| ScheduledExecutorService#schedule(Callable command,long delay, TimeUnit unit) | √ | ||
| ScheduledExecutorService#scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit) | √ | ||
| ScheduledExecutorService#scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit) | √ |
程序分层设计的基本准则是:一个层级只负责一件事,无论是 jdk 的基准库还是 spring 这样的框架,它们都遵循这样的理念。上面这个三个类,就是很好的贯彻了这一原则,三者各自负责的内容为:
-
AbstractExecutorService
只关注如何提交任务,至于提交任务后,如何去执行它,交由子类去处理。之所以要把提交任务的逻辑写在一个抽象类里边,是因为这些提交任务的逻辑具有通用性,不需要有多种实现,子类直接复用就好了。 -
ThreadPoolExecutor
关注如何执行任务,这也是执行器的核心。同时,由于它直接负责任务的执行,因此,整个执行器的控制和状态检测,也理应由它负责。 -
ScheduledThreadPoolExecutor
关注如何让任务在指定的时间执行,即所谓的「调度」。它也不关注如何执行任务,所谓在指定的时间执行,其实是在指定的时间提交任务。至于提交后是否会被立刻执行,则取决于真正负责处理执行任务的组件, 这个组件就是ThreadPoolExecutor。
下面是 ThreadPoolExecutor 中最核心的 execute() 方法源码
public class ThreadPoolExecutor { public void execute(Runnable command) { int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true))  ̄ ̄ ̄ ̄ ̄ ̄ ➋ return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) {  ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ➊ int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false);  ̄ ̄ ̄ ̄ ̄ ̄ ➋ } else if (!addWorker(command, false)) reject(command); }}
要彻底读懂源码,还需要掌握并发包下的 Lock 体系,这个体系比 Executor 体系更难。不过有了第二小节「手写简易线程池」的经验,即使我们对 Lock 体系没有全面掌握,也能从上述源码中梳理出核心逻辑。比如 ➊ 处,就是向任务队列里添加任务,➋ 处就是在尝试增加执行线程,其它地方都是做各种并发控制与内部状态的控制。
现在可以来看看 AbstractExecutorService 实现的 submit(Callable task) 方法,其底层的逻辑是什么了。所谓提交,其实就是调用父接口 Executor 的 execute(Runnable command) 方法,最简单的实现是将 Callable 对象包装成一个 Runnable,然后直接调用 execute() 方法,将包装出来的 Runnable 对象作为参数传递过去即可。事实上,AbstractExecutorService 的源码就是这么做的,以下是 submit 方法的源码:
public class AbstractExecutorService { public <T> Future<T> submit(Callable<T> task) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task); // 将 Callable 包装成 Runnable  ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ execute(ftask); // 以上一步包装的 Runnable 对象为参数,调用父接口的 execute 方法  ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ return ftask; } protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) { return new FutureTask<T>(callable); }}
源码中的行为与我们预想的一致,现在问题的是:将 Callable 包装成 Runnable 的核心逻辑是什么?从上述源码看,这个包装过程极其简单,只是简单的用 Callable 作为参数,新创建了一个 FutureTask 实例。这个 FutureTask 正是在「Executor 体系类结构」小节中提到的 FutrueTask,它的核心逻辑,我们已用简易的非线程安全代码演示过了。
有了 ThreadPoolExecutor 和 ScheduledThreadPoolExecutor,我们就可以方便的处理任务了。不过 Jdk 并发包的设计大师为我们考虑得更周到,她还提供一个任务执行器的工厂类 Excutors。Executors 提供的都是静态方法,通过这些静态方法,可以创建拥有不同特性的 ExecutorService 对象。比如 Executors#newFixedThreadPool(int threadCount, ThreadFactory threadFactory) 方法,就可以快速创建一个拥有固定线程数量的 ThreadPoolExecutor 实例。
- 线程池不是普通的对象池,池中的线程不受外界控制,也不存在 borrow(借出)与 return(归还) 一说。这些线程会不断地从内部的任务队列里提取任务,然后执行它。
- JDK 并发包构成了一个 Excutor 体系,核心方法的实现有层次地分摊到了 AbstractExecutorService、ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 三个类中。
- Executor 体系提供了一 Executors 工厂类,使得可以快速创建 ExecutorService 实例。
- Executor 体系的实现代码,还非常依赖并发包下的 Lock 体系,需要该体系来提供线程安全保障。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK