

Is The Hot Hand Fallacy A Fallacy?
source link: https://rjlipton.com/2015/10/12/is-the-hot-hand-fallacy-a-fallacy/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Is The Hot Hand Fallacy A Fallacy?
A simple idea that everyone missed, and more?
Joshua Miller and Adam Sanjurjo (MS) have made a simple yet striking insight about the so-called hot hand fallacy.
Today Ken and I want to discuss their insight, suggest an alternate fix, and reflect on what it means for research more broadly.
I believe what is so important about their result is: It uses the most elementary of arguments from probability theory, yet seems to shed new light on a well-studied, much-argued problem. This achievement is wonderful, and gives me hope that there are still simple insights out there, simple insights that we all have missed—yet insights that could dramatically change the way we look at some of our most important open problems.
I would like to point out that I first saw their paper mentioned in the technical journal WSJ—the Wall Street Journal.
The Fallacy
Our friends at Wikipedia make it very clear that they believe there is no hot-hand at all:
The hot-hand fallacy (also known as the “hot hand phenomenon” or “hot hand”) is the fallacious belief that a person who has experienced success with a random event has a greater chance of further success in additional attempts. The concept has been applied to gambling and sports, such as basketball.
The fallacy started as a serious study back in 1985, when Thomas Gilovich, Amos Tversky, and Robert Vallone (GTV) published a paper titled “The Hot Hand in Basketball: On the Misperception of Random Sequences” (see also this followup). In many sports, especially basketball, players often seem to get hot. For example, an NBA player who normally usually shoots under 50% from the field may make five shots in a row in a short time. This suggests that he is “in the zone” or has a “hot hand.” His teammates may pass him the ball more often in expectation of his staying “hot.”
Yet GTV and many subsequent studies say that this is wrong. They seem to show rather that shooting is essentially a series of independent events: that each shot is independent from previous ones, and that this is equally true of free throws. Of course given the nature of this problem, there is no way to prove mathematically that hot hands do not exist. There are now many papers, websites, and a continuing debate about whether hot hands are real or not.
The Fallacy Of The Fallacy
Let me start by saying that Ken and I are mostly on the fence about the fallacy. I can imagine many situations that make it mathematically possible. For one, what if a player in basketball is not doing independent trials but rather executing a Markov process. That is, of course, a fancy way of saying that the player has “state.” Over a long term they will make about 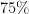
I personally once experienced something that seems to suggest that there is a hot hand. I was a poor player of stick-ball when I was young, but one day played like the best in the neighborhood. Oh well. Let me explain this in more detail another day.
Ken chimes in: This folds into a larger question that is not fallacious, and that concerns me as I monitor chess tournaments:
What is the time or game unit of being in form?
In chess I think the tournament more than game or move is the “unit of form” though I am still a long way from rigorously testing this. In baseball the saying is, basically, “Momentum stops with tomorrow’s opposing starting pitcher.”
Nevertheless, I (Ken) wonder how far “hot hand” has been tested in fantasy baseball. In my leagues on Yahoo! one can exchange players at any time. Last month I dropped the slumping Carlos Gomez in two leagues even though Yahoo! still ranked him the 8th-best player by potential. In one league I picked up Jake Marisnick, another Houston outfielder who had been hot. Marisnick soon went cold with the bat but stole 6 bases to stay within the top 100 performers anyway. The leagues ended with the regular season, but had they continued into the playoffs I definitely would have picked up Houston’s Colby Rasmus after 3 homers in 3 games. While I’ve been writing the last three main sections of this post, Rasmus hit another homer today.
The New Insight
MS have a new paper with the long title, “Surprised by the Gambler’s and Hot Hand Fallacies? A Truth in the Law of Small Numbers.” Their paper is interesting enough that it has already stimulated another paper by Yosef Rinott and Maya Bar-Hillel, who do a great job of explaining what is going on. The statistician and social science author Andrew Gelman explained the basic point in even simpler terms on his blog in July, and we will follow his lead.
For the simplest case consider sequences of 


then we must discard it since there is no

there is no chance for a hot hand since the “game is over.” Hence it seems natural to use the following sampling procedure:
-
Generate a sequence
at random.
-
If it has no head in the first
places, discard it.
-
Else pick a head at random from those places. That is, pick
such that
.
-
Score a “hit” if
, else “miss.”
Let HHS be the number of hits after 




To see why, consider 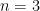



This gives HHS 
A Statistical Heads-Up
What happened is that the heads are not truly chosen uniformly at random. Look again at the six rows. There are 8 heads total in the first two characters. Choose one of them at random over the whole data set. Then you see 4 heads are followed by 
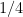
You might think the bias would quickly lessen as the sequence length grows but that too is wrong. Try 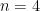


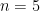










The bias persists if we condition on 
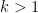
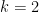


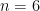

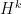
Did GTV really follow this sampling strategy? It seems yes. It comes about if you follow the letter of conditioning on the event that the previous
If you did your hot-hand study as above and got 50%, then chances are the process from which you drew the data really was “hot.”
And since the way of conditioning on misses has a bias toward 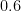
Subtler Bias Still
MS give some other explanations of the bias, one roughly as follows: If a sequence starts with
This suggests a fix, but the fix doesn’t work: Let us only condition on sequences of

This gives 


A Grid Idea
This train of thought led me (Ken) to an ironclad fix, different from a test combining conditionals by MS which they refer to their 2014 working paper. It simply allows only one selection from each non-discarded sequence, namely, testing the bit after the first 

That this is unbiased is easy to prove: Given 
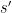

Break up the data into subsequences
of any desired lengths
. The
consecutive “hits” in the first
places, choose the first such sequence and test whether the next bit is “hit” or “miss.”
The downsides to putting this kind of grid on the data are sacrificing some samples—that is, discarding cases of 
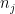
A larger lesson is that hidden bias might be rooted out by clarifying the algorithms by which data is collated. Researchers count as part of the public addressed in articles on how not to go astray such as this and this, both of which highlight pitfalls of conditional probability.
Open Problems
Has our grid idea been tried? Does it show a “hot hand”?
Update (10/18): The idea is apparently new, though as we admit in the post it is “lossy.” Meanwhile this has been covered in the Review section of the Sunday 10/18 New York Times, which in turn references and gives a chart from this post by Steven Landsburg on his “Big Questions” blog.
Like this:
Related
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK