

进一步加速落地:压缩自动驾驶端到端运动规划模型
source link: https://www.51cto.com/article/783794.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

进一步加速落地:压缩自动驾驶端到端运动规划模型
本文经自动驾驶之心公众号授权转载,转载请联系出处。
原标题:On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
论文链接:https://arxiv.org/pdf/2403.01238.pdf
代码链接:https://github.com/tulerfeng/PlanKD
作者单位:北京理工大学 ALLRIDE.AI 河北省大数据科学与智能技术重点实验室

端到端的运动规划模型配备了深度神经网络,在实现全自动驾驶方面展现出了巨大潜力。然而,过大的神经网络使得它们不适合部署在资源受限的系统上,这无疑需要更多的计算时间和资源。为了解决这个问题,知识蒸馏提供了一种有前景的方法,它通过使一个较小的学生模型从较大的教师模型学习来压缩模型。尽管如此,如何应用知识蒸馏来压缩运动规划器到目前为止还未被探索。本文提出了 PlanKD,这是第一个为压缩端到端运动规划器量身定制的知识蒸馏框架。首先,考虑到驾驶场景本质上是复杂的,常常包含与规划无关或甚至是噪声信息,迁移这种信息对学生规划器并无益处。因此,本文设计了一种基于信息瓶颈(information bottleneck)的策略,只蒸馏与规划相关的信息,而不是无差别地迁移所有信息。其次,输出规划轨迹中的不同 waypoints 可能对运动规划的重要性各不相同,某些关键 waypoints 的轻微偏差可能会导致碰撞。因此,本文设计了一个 safety-aware waypoint-attentive 的蒸馏模块,根据重要性为不同 waypoints 分配自适应权重,以鼓励学生模型更准确地模仿更关键的 waypoints ,从而提高整体安全性。实验表明,本文的 PlanKD 可以大幅提升小型规划器的性能,并显著减少它们的参考时间。
主要贡献:
- 本文构建了第一个旨在探索专用知识蒸馏方法以压缩自动驾驶中端到端运动规划器的尝试。
- 本文提出了一个通用且创新的框架 PlanKD,它使学生规划器能够继承中间层中与规划相关的知识,并促进关键 waypoints 的准确匹配以提高安全性。
- 实验表明,本文的 PlanKD 可以大幅提升小型规划器的性能,从而为资源有限的部署提供了一个更便携、更高效的解决方案。
网络设计:
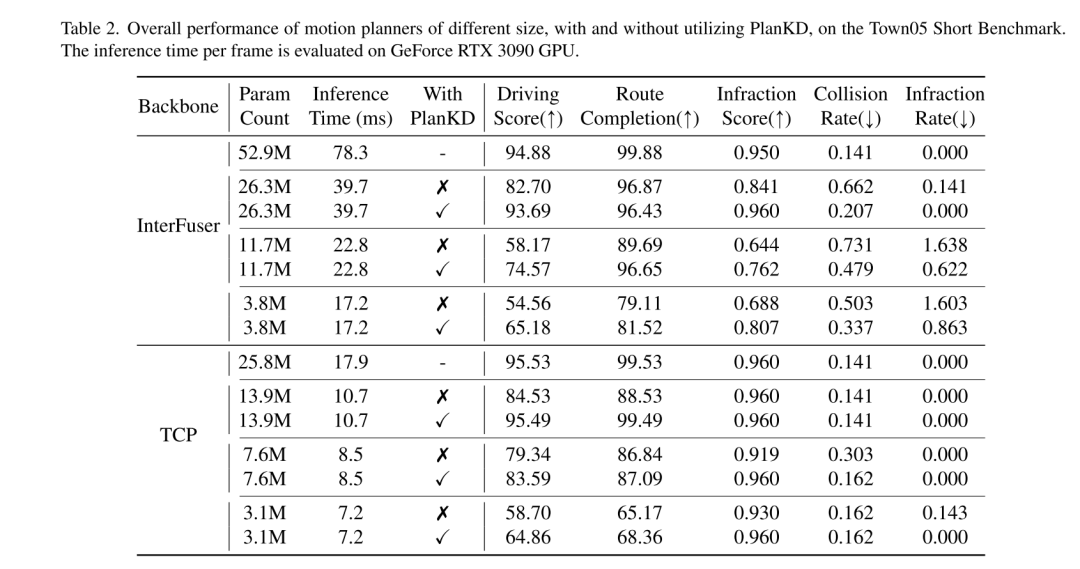
端到端运动规划最近作为自动驾驶中的一个有前景的方向出现[3, 10, 30, 31, 40, 47, 48],它直接将原始传感器数据映射到规划的动作上。这种基于学习的范式展现出减少对手工制定规则的严重依赖和减轻在复杂级联模块(通常是检测-跟踪-预测-规划)[40, 48]内错误累积的优点。尽管取得了成功,但运动规划器中深度神经网络庞大的架构为在资源受限环境中的部署带来了挑战,例如依赖边缘设备计算能力的自动配送机器人。此外,即便是在常规车辆中,车载设备上的计算资源也经常是有限的[34]。因此,直接部署深层且庞大的规划器不可避免地需要更多的计算时间和资源,这使得快速响应潜在危险变得具有挑战性。为了缓解这个问题,一个直接的方法是通过使用较小的主干网络来减少网络参数的数量,但本文观察到,端到端规划模型的性能会急剧下降,如图1所示。例如,尽管当 InterFuser [33](一个典型的端到端运动规划器)的参数数量从52.9M减少到26.3M时,推理时间降低了,但其驾驶得分也从53.44下降到了36.55。因此,有必要开发一种适用于端到端运动规划的模型压缩方法。
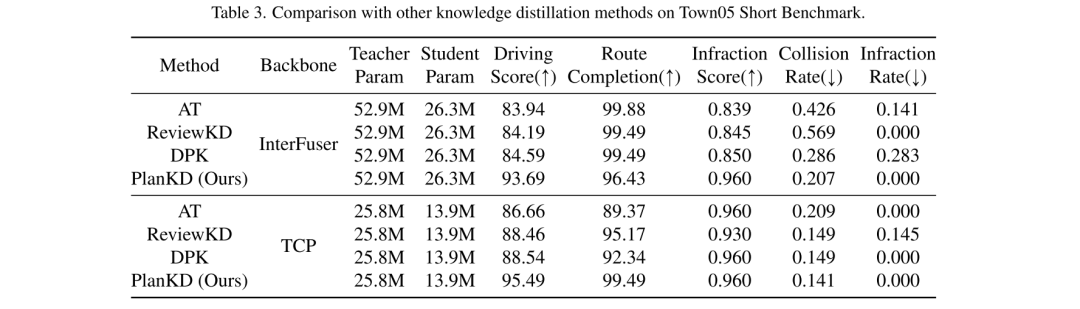
为了得到一个便携的运动规划器,本文采用知识蒸馏[19]来压缩端到端运动规划模型。知识蒸馏(KD)已经在各种任务中被广泛研究用于模型压缩,例如目标检测[6, 24]、语义分割[18, 28]等。这些工作的基本思想是通过从更大的教师模型继承知识来训练一个简化的学生模型,并在部署期间使用学生模型来替代教师模型。虽然这些研究取得了显著的成功,但直接将它们应用于端到端运动规划会导致次优结果。这源于运动规划任务中固有的两个新出现的挑战:(i) 驾驶场景本质上是复杂的[46],涉及包括多个动态和静态物体、复杂的背景场景以及多方面的道路和交通信息在内的多样化信息。然而,并不是所有这些信息都对规划有益。例如,背景建筑物和远处的车辆对规划来说是无关的甚至是噪音[41],而附近的车辆和交通灯则有确定性的影响。因此,自动地只从教师模型中提取与规划相关的信息至关重要,而以往的KD方法无法做到这一点。(ii) 输出规划轨迹中的不同 waypoints 通常对运动规划的重要性各不相同。例如,在导航一个交叉口时,轨迹中靠近其他车辆的 waypoints 可能比其他 waypoints 具有更高的重要性。这是因为在这些点,自车需要主动与其他车辆互动,即使是微小的偏差也可能导致碰撞。然而,如何自适应地确定关键 waypoints 并准确地模仿它们是以往KD方法的另一个重大挑战。
为了解决上述两个挑战,本文提出了第一个为压缩自动驾驶中端到端运动规划器量身定制的知识蒸馏方法,称为 PlanKD 。首先,本文提出了一个基于信息瓶颈原理[2]的策略,其目标是提取包含最少且足够规划信息的与规划相关的特征。具体来说,本文最大化提取的与规划相关特征和本文定义的规划状态的真值之间的互信息,同时最小化提取特征和中间特征映射之间的互信息。这一策略使本文能够只在中间层提取关键的与规划相关的信息,从而增强学生模型的有效性。其次,为了动态识别关键 waypoints 并如实地模仿它们,本文采用注意力机制[38]计算每个 waypoints 及其在鸟瞰图(BEV)中与关联上下文之间的注意力权重。为了在蒸馏过程中促进对安全关键 waypoints 的准确模仿,本文设计了一个 safety-aware ranking loss ,鼓励对于靠近移动障碍物的 waypoints 给予更高的注意力权重。相应地,学生规划器的安全性可以显著增强。如图1所示的证据显示,通过本文的 PlanKD,学生规划器的驾驶得分可以显著提高。此外,本文的方法可以将参考时间降低约50%,同时保持与教师规划器在 Town05 Long Benchmark 上相当的性能。
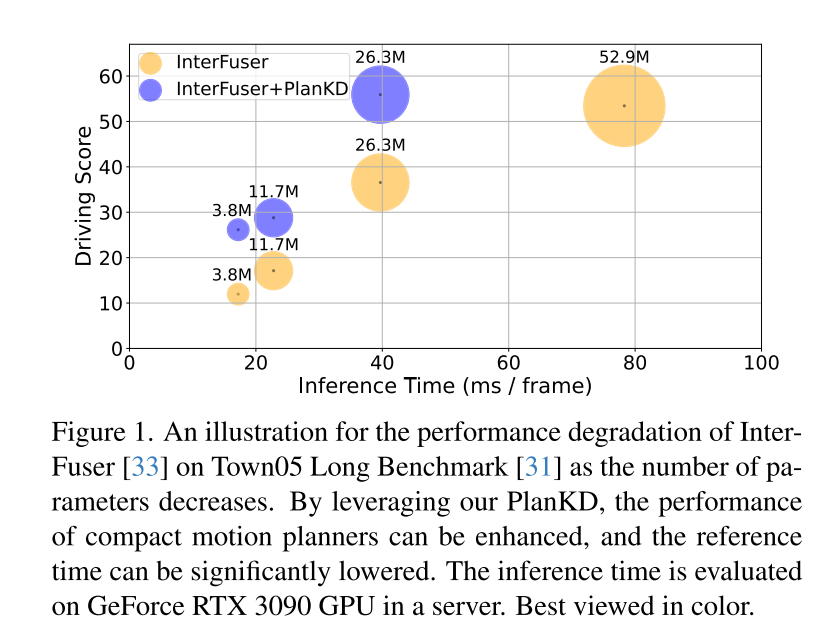
图1. 在 Town05 Long Benchmark [31]上,随着参数数量的减少,InterFuser[33] 性能下降的示意图。通过利用本文的 PlanKD ,可以提升紧凑型运动规划器的性能,并且显著降低参考时间。推理时间在服务器上的 GeForce RTX 3090 GPU 上进行评估。
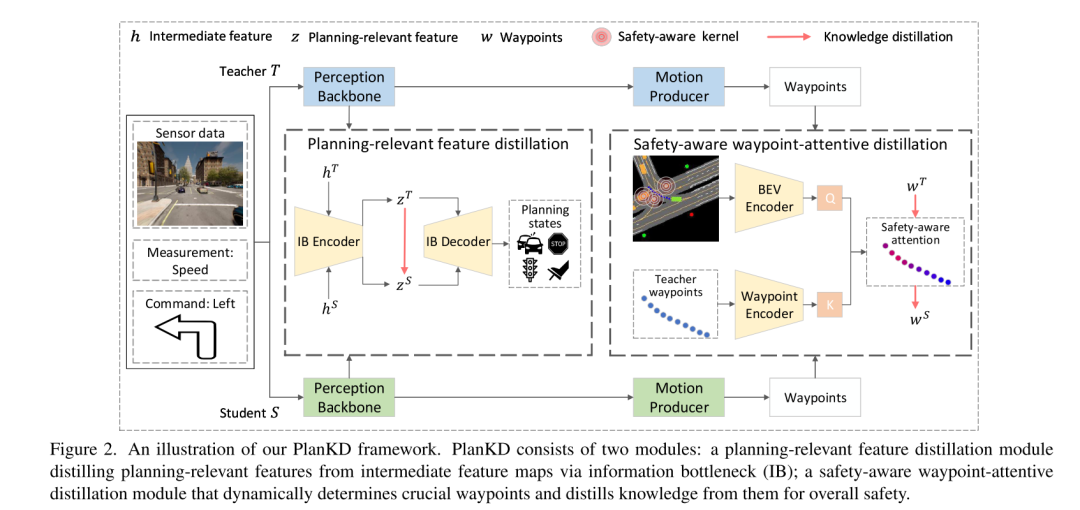
图2. 本文的 PlanKD 框架示意图。PlanKD 由两个模块组成:一个与规划相关的特征蒸馏模块,通过信息瓶颈(IB)从中间特征映射中提取与规划相关的特征;一个 safety-aware waypoint-attentive 蒸馏模块,动态确定关键 waypoints ,并从中提取知识以增强整体安全性。
实验结果:
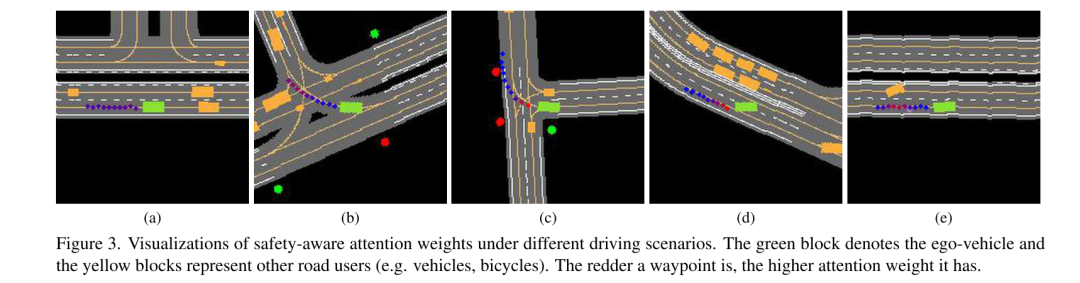
图3. 在不同驾驶场景下,safety-aware 注意力权重的可视化。绿色块代表自车(ego-vehicle),黄色块代表其他道路使用者(例如汽车、自行车)。一个 waypoint 的颜色越红,它的注意力权重就越高。
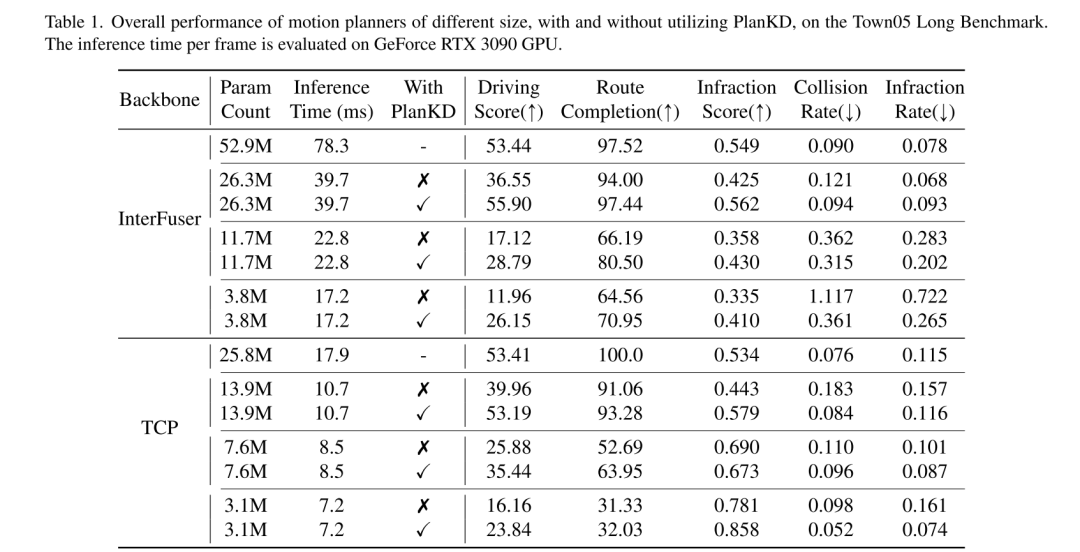
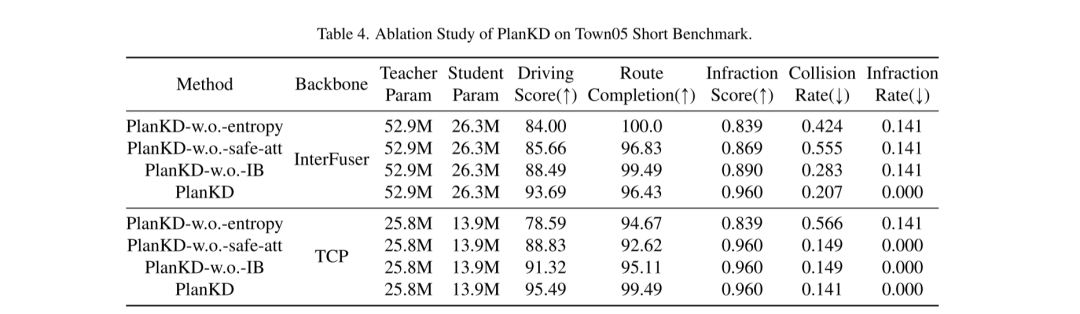
本文提出了 PlanKD,这是一种为压缩端到端运动规划器量身定制的知识蒸馏方法。所提出的方法可以通过信息瓶颈学习与规划相关的特征,以实现有效的特征蒸馏。此外,本文设计了一个 safety-aware waypoint-attentive 蒸馏机制,以适应性地决定每个 waypoint 对 waypoint 蒸馏的重要性。广泛的实验验证了本文方法的有效性,证明了 PlanKD 可以作为资源有限部署的便携式和安全的解决方案。
Feng K, Li C, Ren D, et al. On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving[J]. arXiv preprint arXiv:2403.01238, 2024.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK