

让Sora和ChatGPT更可靠!只需这个知识价值定量评估新框架
source link: https://www.qbitai.com/2024/03/127799.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

让Sora和ChatGPT更可靠!只需这个知识价值定量评估新框架

将物理机理等领域知识引入AI
西风 发自 凹非寺
量子位 | 公众号 QbitAI
为了让AI更像科学家,他们将人类知识注入大模型…
正如教孩子解难题,你可以让他们自己反复试错找到正确方法,也可以教他们一些基础规则和技巧提高解题效率。
类似地,将规则和技巧等人类知识融入到ChatGPT、Sora等基于数据驱动的AI模型训练中,有可能提高模型的效率和推理能力。

△该图由AI模型StableDiffusionXL生成
但关键问题是如何平衡数据和知识对模型的影响。
为了解决这一问题,美国国家工程院院士张东晓、宁波东方理工大学(暂名)助理教授陈云天领衔,提出了一个新框架——
它首次对知识的价值进行定量评估,从而增强深度学习模型的预测能力。

实验证明,该框架可在物理、化学、工程学等不同领域有广泛的实际应用,比如使用该方法优化机器学习模型来解决多变量方程、预测薄层色谱实验的结果优化未来的实验化学条件等。
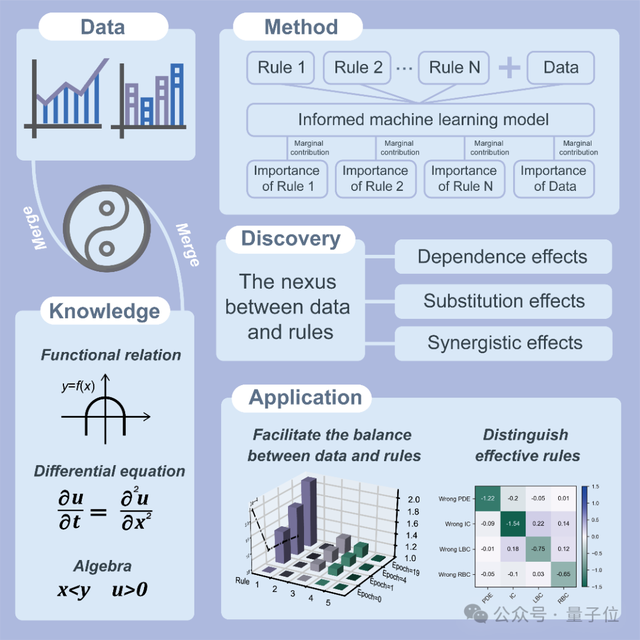
目前,该研究已刊于Cell Press交叉学科领域期刊Nexus。
此外值得一提的是,虽然Sora发布后被认为可以理解“事物在现实世界中的存在方式”,但本文研究人员认为它不能准确模拟许多基本交互的物理特性:
如果没有对世界的基本理解,模型本质上就是动画,而不是一个模拟。
新框架长啥样?
在数据科学中,知识可被视为是数据在时间和空间维度中复杂关系的体现。深度学习领域,先验知识对于弥补数据驱动模型的缺陷至关重要。
然而,要想将物理机理等知识融入大模型仍然存在挑战——
如何评估先验知识的价值?数据和知识之间的关系是什么?如何使先验知识更好地发挥作用?
为解决这几点问题,本文研究框架的核心提出了两个新的概念:
- 规则重要性(Rule Importance, RI)
- 完全重要性(Full Importance, FI)
其中,规则重要性(RI)用于量化每条规则对模型预测精度的边际贡献,研究特定规则或组合如何影响模型的预测准确性。
本文提到的“规则”指的是在知情机器学习(informed machine learning)框架中,用于指导模型学习和预测的先验知识。
计算过程如下图:
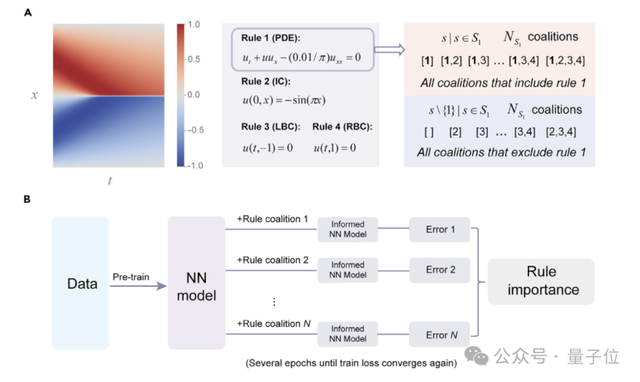
对于模型中纳入的第i条规则,定义它的边际贡献为:
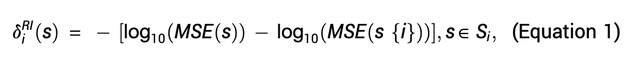
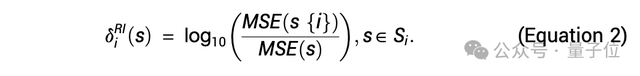
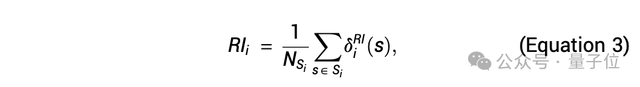
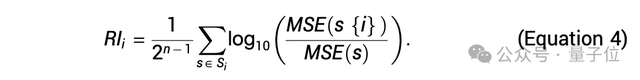
为了进行比较,完全重要性(FI)表示在所有其他规则存在的情况下,某条规则的重要性,计算公式可以表示为:
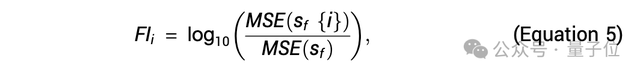
值得一提的是,研究人员还建立了一种基于扰动的高效计算RI的方法,避免了每次都从头训练模型。
(更多细节,感兴趣的家人们可以查看原论文)
数据和规则的基本原理
接下来,研究人员通过一系列系统实验,揭示了数据和规则之间的一些内在原理和关系。
具体来说,他们选择了四个典型的物理过程作为实验案例,涉及的规则包括控制偏微分方程(PDEs)、边界条件(BCs)和初始条件(ICs)。
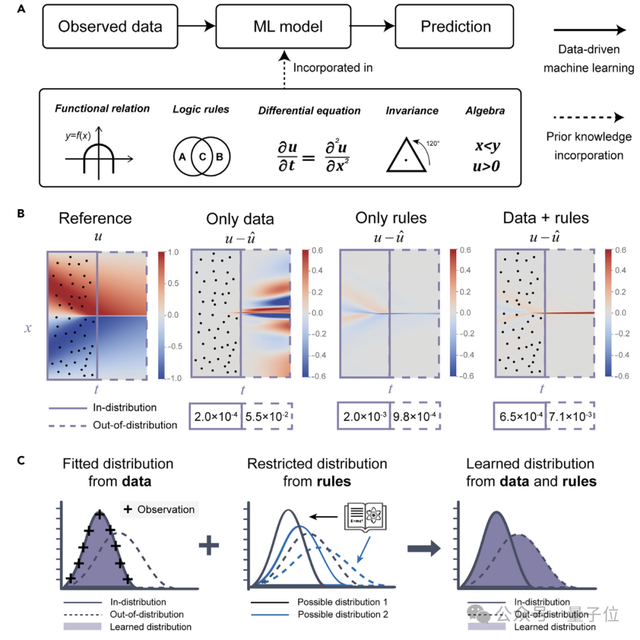
研究人员发现,在分布内(in-distribution)预测场景中,随着训练数据量增加,RI会逐渐降低。尤其是局部规则(local rules)如初始条件,RI下降得更快。
这表明在数据量较大时,模型可以通过学习数据本身来提高预测精度,而不需要依赖于规则来限制可能的分布范围。
分布外(out-of-distribution)预测场景中,不同类型规则的RI会随数据量变化呈现出不同趋势。全局规则(global rules)如PDE,RI会随数据量的增加而升高,而局部规则如初始条件的RI会随着数据量的增加而降低。
全局规则在指导模型全局分布方面发挥更关键的作用,而局部规则与观测数据紧密相关,过多的数据可能导致过拟合。
研究人员总结,规则之间存在着依赖(Dependence)、协同(Synergism)和替代(Substitution)等复杂交互作用。
- 依赖性体现为规则内部之间的依赖(inner dependence)和规则与依赖变量之间的外部依赖(outer dependence)。内部依赖指的是规则之间相互依赖以发挥作用,而外部依赖则是指规则对模型预测的依赖程度。
- 协同作用体现为:在某些情况下,多条规则共同作用产生的效应大于它们各自效应的总和。
- 替代作用体现为:在某些情况下,一个规则的功能可以被数据或其他规则替代。
值得一提的是,研究人员表示该框架在实际应用中具有实际效用,不仅能够提高知情机器学习(informed machine learning)的性能,还能够通过改善模型的规则选择来提高模型的安全性和可靠性。
论文通讯作者
张东晓,美国工程院院士,美国地质学会会士,国际石油工程师协会SPE最高荣誉会员。
现任宁波东方理工大学(暂名)常务副校长兼教务长,主要从事智慧能源与碳中和领域研究。
陈云天,东方理工助理教授,博导。清华大学能源与动力工程系学士,北京大学力学(能源与资源工程)博士,鹏城实验室博士后。
研究方向为科学机器学习,主要专注于:物理驱动与数据驱动的融合、AI辅助的科学知识发现。
论文一作
徐浩,北京大学工学院博士研究生。
擅长运用人工智能技术辅助科学探索,相关研究曾发表在Nature Communications、Chem和Advanced Science等期刊。
参考链接:
[1]https://www.eurekalert.org/news-releases/1036117
[2]https://www.cell.com/nexus/fulltext/S2950-1601(24)00001-9
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK