

PostgreSQL Index Types
source link: https://vladmihalcea.com/postgresql-index-types/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Imagine having a tool that can automatically detect JPA and Hibernate performance issues. Wouldn’t that be just awesome?
Well, Hypersistence Optimizer is that tool! And it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, or Play Framework.
So, enjoy spending your time on the things you love rather than fixing performance issues in your production system on a Saturday night!
Introduction
In this article, we are going to analyze the PostgreSQL Index Types so that we can understand when to choose one index type over the other.
When using a relational database system, indexing is a very important topic because it can help you speed up your SQL queries by reducing the number of pages that have to be scanned or even avoid some operations altogether, such as sorting.
If you want to receive automatic index and SQL rewrite recommendations based on your database workloads, check out EverSQL by Aiven.
PostgreSQL Index Types
What’s great about PostgreSQL is that it offers a large variety of index options, such as B+Tree, Hash, GIN, GiST, or BRIN.
In this article, we are going to cover the B+Tree, Hash, and GIN Index because they are the most common options for the vast majority of web or enterprise applications.
We are going to use Aiven for our tests since it allows us to deploy a PostgreSQL database in a couple of minutes.
You can create a PostgreSQL database by navigating to Aiven Console and follow these steps:
- First, you need to create an account and log in.
- Afterwards, you need to select the “Create new service” option and select PostgreSQL.
- Choose your preferred cloud provider, region, and plan size to use for your PostgreSQL database instance, and that’s it!
Domain Model
Let’s consider we have the following book table:

The book table has plenty of columns that we can use to exercise various PostgreSQL Index Types.
For example, the published_on column could benefit from a B+tree index since it has a very high selectivity, and the column is used for both equality checks and range scans.
The title column could use a Hash Index since our SQL queries only need to filter it using equality checks.
The properties column stores JSON content, and we can use a GIN index to optimize the performance of various SQL queries that need to be filtered based on information found inside the JSON column value.
B+Tree Index Type
The B+Tree index type is the default option in PostgreSQL and many other relational database systems.
In PostgreSQL and Oracle, records are stored in Heap Tables, each row having a row identifier that uniquely identifies the record in question. A Primary Key B+Tree index in PostgreSQL or Oracle will contain the row identifier in the leaf nodes, as illustrated by the following diagram:
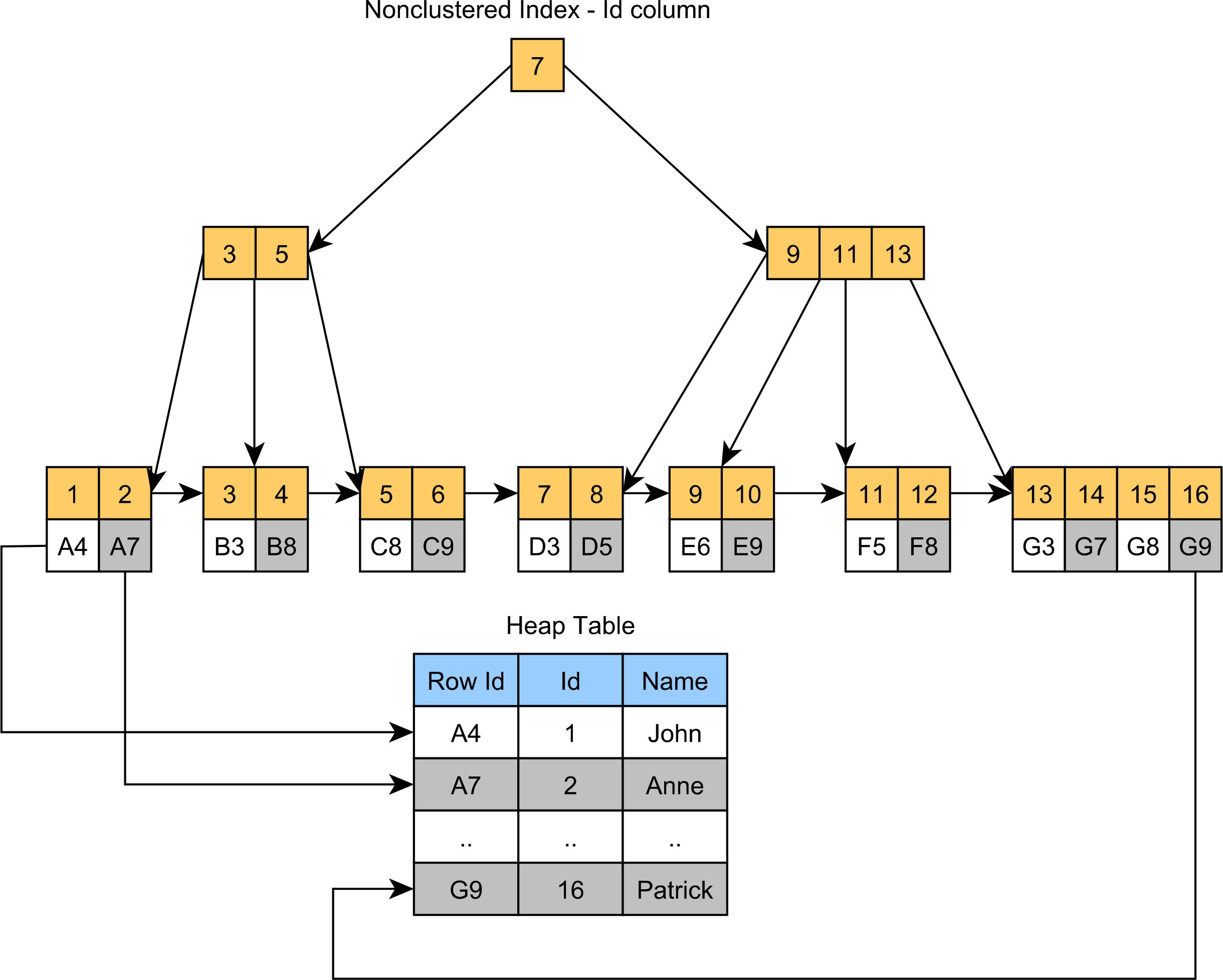
Without a B+Tree index, finding a table record by its Primary Key would require a table scan, checking each record to see whether its Primary Key column value matches the value we are looking for. So, the complexity of a table scan is O(n).
On the other hand, finding a table record by its Primary Key with the help of a B+Tree index has the complexity of O(logn) because that’s basically the height of the tree structure.
A very important aspect of B+Tree indexes is that they are sorted by the index key. For this reason, auto-incremented column values or monotonically increasing timestamp values make very good candidates for a B+Tree since the index will grow in the same direction, therefore providing a very good page fill factor.
On the other hand, random column values are not very suitable for a B+Tree index because the newer elements will not necessarily fill the existing index nodes as they may require their own nodes due to the randomness of the key values. For this reason, the B+Tree index would have a low fill factor and a very large size on the disk that would put pressure on the in-memory Buffer Pool.
For more details about why random UUIDs are not suitable for B+Tree indexes, check out this article as well.
Let’s create a B+Tree index on the published_on column of our book table and also include the title column value in the index node entries as well.
CREATE INDEX IF NOT EXISTS idx_book_published_onON book (published_on)INCLUDE (title) |
B+Tree Index Equality Search
If each table record has a distinct published_on value or if only a few rows share the same published_on value, it means that the published_on column has good selectivity.
When we have a B+Tree index for a highly selective column, then the database will consider using this index when trying to filter the table records by the indexed column value.
So, if we are executing the following SQL query on a PostgreSQL database running on Aiven:
Query:["EXPLAIN (ANALYZE, BUFFERS)SELECT titleFROM bookWHERE published_on = ?"], Params:[(2024-03-04 12:00:00.0)] |
The PostgreSQL query optimizer will choose the following execution plan:
Index Only Scan using idx_book_published_on on book(cost=0.28..23.72 rows=25 width=218) (actual time=0.053..0.054 rows=1 loops=1)Index Cond: (published_on = '2024-03-04 12:00:00'::timestamp without time zone)Heap Fetches: 1Buffers: shared hit=1 read=2 |
Our SQL query does an index-only scan since it doesn’t have to go to the post table to locate the title column value since we included it in the idx_book_published_on index.
The Buffers part tells us that the index loaded one page from the in-memory Shared Buffers and two pages from the OS cache. So, only 3 pages were required to be scanned in order to find the record we were interested in.
B+Tree Index Range Scans
Another use case where B+Tree indexes are very suitable is for range scans since the indexed values are sorted so the index can figure out the starting and the ending nodes for the range that has to be scanned.
So, if we are running the following SQL query on an Aiven-powered PostgreSQL database:
Query:["EXPLAIN (ANALYZE, BUFFERS)SELECT titleFROM bookWHEREpublished_on >= ? ANDpublished_on < ?"], Params:[(2024-03-01 12:00:00.0, 2024-03-29 18:00:00.0)] |
We can see that the PostgreSQL query optimizer has chosen the following execution plan:
Index Only Scan using idx_book_published_on on book(cost=0.28..4.54 rows=113 width=66)(actual time=0.015..0.050 rows=113 loops=1)Index Cond: ((published_on >= '2024-03-01 12:00:00'::timestamp without time zone) AND(published_on < '2024-03-29 18:00:00'::timestamp without time zone))Heap Fetches: 0Buffers: shared hit=3 read=1 |
The rows attribute has the value of 113, meaning that the filtering criteria matched 113 records, and these records were retrieved by loading to 3 pages from the Shared Buffers and 1 page from the OS cache.
Loading just 4 pages in order to retrieve the 113 records for this Range Scan query clearly shows us the benefit of using a B+Tree index.
B+Tree Index Sorting
While it’s common practice to use an index for filtering records, B+Tree indexes are also useful when having to sort the query result set.
Since the B+Tree index is already sorted, as long as we are interested in displaying the result set on the ascending or descending order of an index, then the PostgreSQL query optimizer may choose to scan the indexed records in that particular order.
So, when executing the following SQL query:
EXPLAIN (ANALYZE, BUFFERS)SELECT titleFROM bookORDER BY published_on DESCFETCH FIRST 10 ROWS ONLY |
The PostgreSQL database running on Aiven chooses the following execution plan:
Limit(cost=0.28..0.72 rows=10 width=226)(actual time=0.054..0.078 rows=10 loops=1)Buffers: shared hit=1 read=3-> Index Only Scan Backward using idx_book_published_on on book(cost=0.28..220.28 rows=5000 width=226)(actual time=0.052..0.075 rows=10 loops=1)Heap Fetches: 10Buffers: shared hit=1 read=3 |
Because we are limiting the query result set to, at most, 10 records, we can see that the index will scan only 10 records. The Backward part of the index scan tells you that the index was scanned in descending order because that’s how we constructed our ORDER BY clause.
The Buffers part of the Index Scan shows us that only 1 page was loaded from the Shared Buffers and 3 pages from the OS cache.
B+Tree Index Selectivity
The PostgreSQL optimizer will consider using a B+Tree index only if the number of records that have to be scanned is relatively small compared to the total number of records that are stored in the table.
For instance, the author column has a very low selectivity since, in this case, there are just two values shared by all book table records:
| author | duplicate_count || ------------- | --------------- || Vlad Mihalcea | 1969 || Alex Mihalcea | 3031 | |
So, if we execute the following SQL query that filters the post table records by the author column:
Query:["EXPLAIN (ANALYZE, BUFFERS)SELECT id, title, author, published_onFROM bookWHEREauthor = ?ORDER BYpublished_on"], Params:[(Vlad Mihalcea)] |
We can see that PostgreSQL is going to skip the index and resort to a Table Scan instead:
Sort(cost=143.08..143.14 rows=25 width=352)(actual time=3.603..3.860 rows=1969 loops=1)Sort Key: published_onSort Method: quicksort Memory: 319kBBuffers: shared hit=83-> Seq Scan on book(cost=0.00..142.50 rows=25 width=352)(actual time=0.022..2.205 rows=1969 loops=1)Filter: ((author)::text = 'Vlad Mihalcea'::text)Rows Removed by Filter: 3031Buffers: shared hit=80 |
The execution plan tells us that the post table was scanned sequentially, and 80 pages were loaded from the Shared Buffers, filtering out 3031 records that didn’t match the provided author value.
Because there was no index used for scanning the records, PostgreSQL needs to run a separate Sort operation in order to provide the records sorted by the published_on column value.
So, if an SQL query uses a filtering criteria that has a very low selectivity, then the database might avoid using an index and resort to a sequential scan instead.
For more details about index selectivity, check out this article.
Hash Index Type
While many relational database systems support B+Tree indexes, PostgreSQL provides many other indexing options, such as the Hash Index.
The Hash Index stores a 32-bit hash value that was computed from the column value that gets indexed, and for this reason, it can be used only for equality operations.
The title column can take up to 50 characters, and since we want to filter books by their title, we want to create an index for this column.
A B+Tree index on the title column would require each index node to allocate up to 50 bytes to store the title column value.
On the other hand, if we create a Hash Index, then each index node would require only 4 bytes. The more compact the indexes, the better chance they would fit into the PostgreSQL Shared Buffers or the OS cache. So, it’s beneficial to use column types and index options that are as compact as possible.
The Hash Index can be created like this:
CREATE INDEX IF NOT EXISTS idx_book_title_hashON book USING HASH (title) |
With the idx_book_title_hash Hash Index in place, when running the following SQL query that filters the book records by a given title:
Query:["EXPLAIN (ANALYZE, BUFFERS)SELECT title, author, published_onFROM bookWHERE title = ?"], Params:[(Vivamus penatibus augue vitae nascetur libero ridiculus sodales vitae arcu.)] |
The PostgreSQL engine running on Aiven generates the following execution plan:
Bitmap Heap Scan on book(cost=4.19..57.90 rows=25 width=344)(actual time=0.046..0.047 rows=1 loops=1)Recheck Cond: ((title)::text = 'Vivamus penatibus augue vitae nascetur libero ridiculus sodales vitae arcu.'::text)Heap Blocks: exact=1Buffers: shared hit=3-> Bitmap Index Scan on idx_book_title_hash(cost=0.00..4.19 rows=25 width=0)(actual time=0.040..0.040 rows=1 loops=1)Index Cond: ((title)::text = 'Vivamus penatibus augue vitae nascetur libero ridiculus sodales vitae arcu.'::text)Buffers: shared hit=2 |
The idx_book_title_hash Hash Index was used, and PostgreSQL managed to provide the result set by scanning just 2 pages from the Shared Buffers.
To see the advantage of the Hash Index over the B+Tree one, let’s also add the following B+Tree index:
CREATE INDEX IF NOT EXISTS idx_book_title_btreeON book (title) |
And let’s check the size of both indexes using the following SQL query:
SELECTpg_size_pretty(pg_table_size('idx_book_title_btree')) as b_tree_index_size,pg_size_pretty(pg_table_size('idx_book_title_hash')) as hash_index_size |
The b_tree_index_size B+Tree Index takes 472 kB while the hash_index_size Hash Index takes only 272 kB:
| b_tree_index_size | hash_index_size || ----------------- | --------------- || 472 kB | 272 kB | |
If the table is very large, a Hash Index would make it easier for the index to be stored in the in-memory Shared Buffers as opposed to a much larger index. However, the Hash Index would only be useful for equality checks.
GIN Index Type
The book table has a properties column that can store JSON objects. However, since the column type is jsonb, we can create a GIN (Generalized Inverted Index) Index on this column and, therefore, speed up various JSON-specific operations.
For a detailed list of JSON-related functions that you can run in PostgreSQL, check out this handy cheatsheet shared by Aiven.
The GIN Index is very useful for indexing composite structures, such as arrays, text documents, or JSON objects, because we can speed up queries that need to filter by an interval property value of our indexed array, text document, or JSON object.
So, let’s first create a GIN index on the properties column of our book table:
CREATE INDEX idx_book_properties_ginON book USING GIN (properties) |
GIN Index JSON attribute existence
If an SQL query needs to check whether a given JSON column value contains a given attribute, then the GIN index can help us speed up that SQL query.
For instance, having the idx_book_properties_gin in place, when executing the following SQL query:
EXPLAIN (ANALYZE, BUFFERS)SELECT title, author, published_onFROM bookWHEREproperties ? 'publisher' |
The PostgreSQL query optimizer will generate the following execution plan:
Bitmap Heap Scan on book(cost=3.39..48.01 rows=50 width=344)(actual time=0.037..0.038 rows=1 loops=1)Recheck Cond: (properties ? 'publisher'::text)Heap Blocks: exact=1Buffers: shared hit=4-> Bitmap Index Scan on idx_book_properties_gin(cost=0.00..3.38 rows=50 width=0)(actual time=0.025..0.025 rows=1 loops=1)Index Cond: (properties ? 'publisher'::text)Buffers: shared hit=3 |
There is no sequential scan on the book table as the idx_book_properties_gin index is used instead, and only 3 pages are scanned from the PostgreSQL Shared Buffers.
GIN Index JSON attribute value existing
Another type of SQL query that we can speed up with the GIN index is the one that has to filter by a given attribute name and value combination.
However, to achieve this goal, we need to provide the jsonb_path_ops operation when creating the GIN Index, as illustrated by the following example:
CREATE INDEX idx_book_properties_ginON book USING GIN (properties jsonb_path_ops) |
With the idx_book_properties_gin index supporting the jsonb_path_ops operator, when running the following SQL query that searches if there is an existing title attribute with the value of High-Performance Java Persistence inside the properties JSON column value:
EXPLAIN (ANALYZE, BUFFERS)SELECT title, author, published_onFROM bookWHEREproperties @> '{"title": "High-Performance Java Persistence"}' |
PostgreSQL generates the following SQL execution plan:
Bitmap Heap Scan on book(cost=3.39..48.01 rows=50 width=344)(actual time=0.033..0.033 rows=0 loops=1)Recheck Cond: (properties @> '{"title": "High-Performance Java Persistence"}'::jsonb)Buffers: shared hit=3-> Bitmap Index Scan on idx_book_properties_gin(cost=0.00..3.38 rows=50 width=0)(actual time=0.026..0.026 rows=0 loops=1)Index Cond: (properties @> '{"title": "High-Performance Java Persistence"}'::jsonb)Buffers: shared hit=3 |
The SQL query can filter the book records using the idx_book_properties_gin GIN Index, and only 3 pages are scanned from the PostgreSQL Shared Buffers.
GIN Index JSON path expression
If you want to index the values of a given JSON attribute, then you can provide the following GIN Index:
CREATE INDEX idx_book_properties_ginON book USING GIN ((properties -> 'reviews')) |
With this idx_book_properties_gin in place, when executing the following SQL query:
EXPLAIN (ANALYZE, BUFFERS)SELECT title, author, published_onFROM bookWHEREproperties -> 'reviews' @> '[{"rating":5}]' |
PostgreSQL generates the following execution plan:
Bitmap Heap Scan on book(cost=5.39..50.14 rows=50 width=344)(actual time=23.160..23.169 rows=1 loops=1)Recheck Cond: ((properties -> 'reviews'::text) @> '[{"rating": 5}]'::jsonb)Heap Blocks: exact=1Buffers: shared hit=7-> Bitmap Index Scan on idx_book_properties_gin(cost=0.00..5.38 rows=50 width=0)(actual time=0.099..0.100 rows=1 loops=1)Index Cond: ((properties -> 'reviews'::text) @> '[{"rating": 5}]'::jsonb)Buffers: shared hit=6 |
The SQL query filters the book table rows using the idx_book_properties_gin GIN Index, and only 6 pages are scanned from the PostgreSQL Shared Buffers.
Awesome, right?
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
PostgreSQL provides a large variety of index types from which you can choose. While the B+Tree is the most-used index, there are other indexing options, such as Hash or GIN indexes.
Besides the ones we have covered in this article, PostgreSQL offers a GiST index that’s suitable for spatial searches and a BRIN Index that can allow you to index very large tables.
If you are using
pgvectorfor developing Natural Language Processing applications, and you want to speed up your vector similarity search queries, then check out this article.
Knowing which index to choose to speed up your SQL queries is very important since some options are suitable for a limited number of operations.
This research was funded by Aiven and conducted in accordance with the blog ethics policy.
While the article was written independently and reflects entirely my opinions and conclusions, the amount of work involved in making this article happen was compensated by Aiven.




Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK