

给系统加上眼睛:服务端监控要怎么做?
source link: https://www.51cto.com/article/783698.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

给系统加上眼睛:服务端监控要怎么做?
在项目的整个生命周期中,运行维护的份量相当重要,几乎与项目研发同等重要。在系统运维阶段,及时发现并解决问题是团队的首要任务。因此,在垂直电商系统的构建初期,运维团队已完成了对机器CPU、内存、磁盘、网络等基础监控的设置,期望在出现问题时能够及时发现并解决。
然而,实际运行中却频繁收到用户投诉。主要问题包括数据库主从延迟增加导致业务功能问题、接口响应时间延长导致用户反馈商品页面出现空白页、以及系统出现大量错误影响用户正常使用。这些问题本应及时被发现和解决,但现实却是只能被动接收用户反馈后匆忙修复。
团队意识到,要快速发现和定位业务系统中的问题,必须建立完善的服务端监控体系。因为“道路千万条,监控第一条,监控不到位,领导两行泪”。然而,在搭建过程中困难重重:监控指标的选择、采集方法与途径、以及指标采集后的处理与展示等问题环环相扣,关系着系统的稳定性和可用性。
监控指标如何选择
在搭建监控系统时,首要问题是选择适当的监控指标,也就是确定监控的对象。有时候,针对新系统的监控指标的设定可能会令人感到迷茫,不知从何着手。然而,有一些成熟的理论和方法可供直接借鉴。例如,谷歌对分布式系统监控的经验总结提出了“四个黄金信号”(Four Golden Signals)。
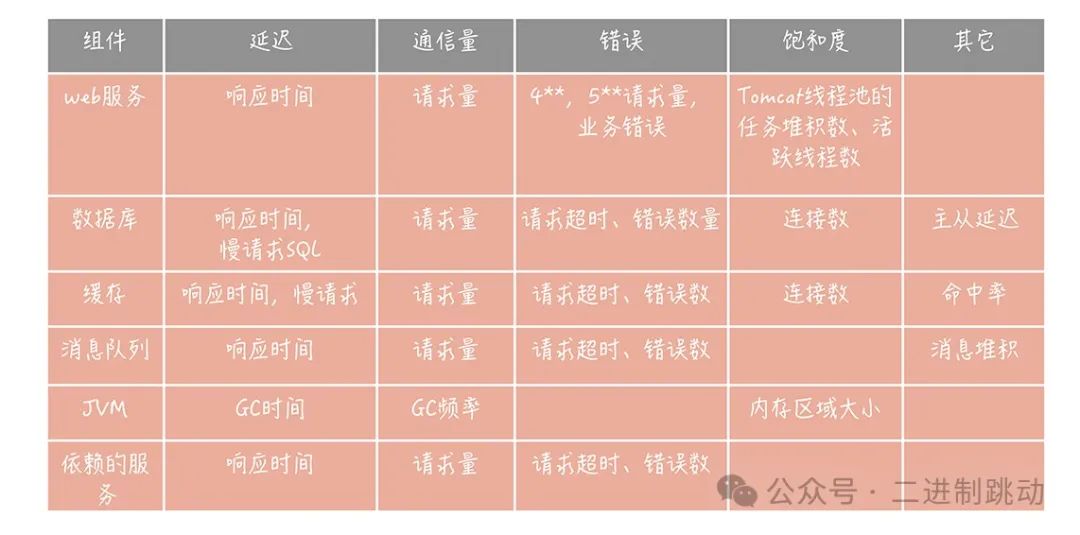
这四个黄金信号主要包括延迟、通信量、错误和饱和度。
具体而言,延迟指的是请求的响应时间,比如接口响应时间、数据库和缓存响应时间等;
通信量则表示单位时间内的请求量大小,如访问第三方服务的请求量、消息队列的请求量等;
错误包括显式和隐式的错误,显式错误指的是出现的特定响应码(例如4xx和5xx),隐式错误则是指返回正常响应码但实际上发生了与业务相关的错误;
饱和度则表示服务或资源达到上限的程度,包括 CPU、内存、磁盘使用率以及数据库连接数等。
除了四个黄金信号,还可以借鉴RED指标体系,它是从四个黄金信号中衍生出来的,其中R代表请求量(Request rate)、E代表错误(Error)、D代表响应时间(Duration),不包含饱和度指标。可以将RED指标体系视为一种简化版的通用监控指标体系。
如何采集数据指标
首先,Agent 是一种比较常见的采集数据指标的方式
对于从Memcached服务器获取性能数据,可以通过Agent连接到该服务器,并发送stats命令以获取服务器的统计信息。然后,从返回的信息中选择重要的监控指标,发送给监控服务器,形成Memcached服务的监控报表。以下是一些推荐的重要状态项,可供参考使用:
- curr_connections:当前打开的连接数。
- cmd_get:获取数据的请求数。
- cmd_set:设置数据的请求数。
- get_hits:成功获取数据的次数。
- get_misses:未找到数据的次数。
- evictions:因内存空间不足而清除数据的次数。
- bytes:当前存储的字节数。
- bytes_read:从Memcached读取的字节数。
- bytes_written:向Memcached写入的字节数。
- uptime:Memcached服务的运行时间。
另一种很重要的数据获取方式是在代码中埋点。
埋点和Agent的不同之处在于,Agent主要收集组件服务端的信息,而埋点则从客户端的角度描述所使用的组件、服务的性能和可用性。在选择埋点方式时,可以考虑以下两种方法:
面向切面编程:这是一种常见的埋点方式,通过在代码中插入切面逻辑,实现对关键方法或代码块的监控。例如,在方法执行前后记录方法调用时间、参数、返回值等信息,以便后续分析性能和定位问题。
客户端计算:另一种方式是在资源客户端直接计算调用资源或服务的耗时、调用量等指标,并将这些信息发送给监控服务器。例如,可以在客户端代码中添加逻辑,记录资源调用开始和结束时间,并计算调用耗时,然后将这些数据发送给监控服务器。
最后,日志也是你监控数据的重要来源之一。
在监控系统中,Tomcat和Nginx的访问日志是非常重要的监控数据源之一。通过开源的日志采集工具,可以将这些日志中的数据发送给监控服务器,以便进行实时监控和分析。目前,常用的日志采集工具包括Apache Flume、Fluentd和Filebeat等,你可以根据自己的熟悉程度和项目需求选择合适的工具。
在项目中,倾向于使用Filebeat来收集监控日志数据。Filebeat是一个轻量级的日志数据收集工具,具有简单易用、低资源消耗等特点,适用于实时收集和传输日志数据。通过配置Filebeat,你可以轻松地将Tomcat和Nginx的访问日志发送到监控服务器,实现对这些日志数据的收集和分析,从而更好地监控系统的运行状态和性能表现。
监控数据的处理和存储
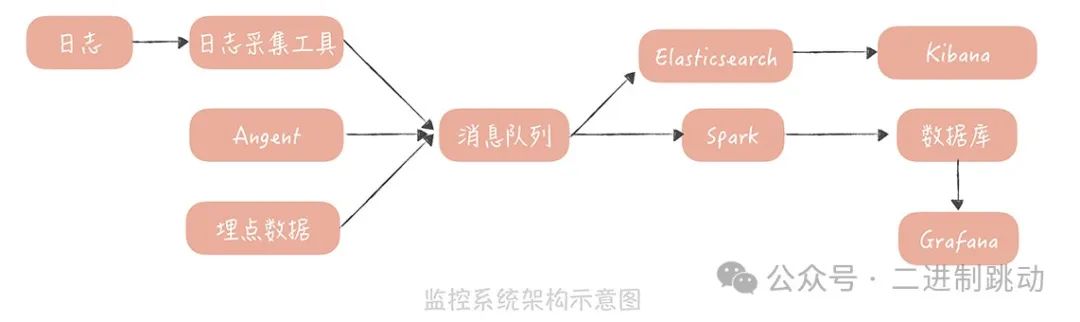
在采集监控数据后,一般会先通过消息队列来缓冲数据,以平滑数据流,防止监控服务因写入过多数据而受到影响。同时,通常会部署两个队列处理程序来处理消息队列中的数据。
一个处理程序负责将数据写入Elasticsearch,并通过Kibana展示,用于原始数据的查询。另一个处理程序则用于流式处理,通常使用Spark、Storm等中间件。它们会从消息队列接收数据并进行如下处理:
解析数据格式,特别是日志格式,提取诸如请求量、响应时间、请求URL等数据。
对数据进行聚合运算,例如针对Tomcat访问日志,计算同一URL在一段时间内的请求量、响应时间分位值、非200状态码请求量等。
将数据存储在时间序列数据库中。时序数据库特点是可以更有效地存储带有时间标签的数据,而监控数据恰好带有时间标签,适合存储在此类数据库中。常用的时序数据库包括InfluxDB、OpenTSDB、Graphite等,选择根据实际需求和团队熟悉程度而定。
最后,通过Grafana连接时序数据库,将监控数据可视化成报表,供开发和运维人员使用。
至此,你和你的团队也就完成了垂直电商系统服务端监控系统搭建的全过程。这里我想再多说一点,我们从不同的数据源中采集了很多的指标,最终在监控系统中一般会形成以下几个报表,你在实际的工作中可以参考借鉴。
访问趋势报表:此类报表基于Web服务器和应用服务器的访问日志,展示了服务整体的访问量、响应时间、错误数量、带宽等信息。它主要反映了服务的整体运行情况,有助于发现问题。
性能报表:这类报表对接的是资源和依赖服务的埋点数据,展示了被埋点资源的访问量和响应时间情况。它反映了资源的整体运行情况。当从访问趋势报表发现问题时,可以先从性能报表中找到出现问题的具体资源或服务。
资源报表:此类报表主要对接使用Agent采集的资源的运行情况数据。当从性能报表中发现某一资源出现问题时,可以进一步从资源报表中查找资源的具体问题,如连接数异常增加或缓存命中率下降。这有助于进一步分析问题的根源并找到解决方案。
Recommend
-
235
在靠 WF-1000X「降噪豆」引起了颇高的关注度后,这次索尼在 CES 上带来的真 · 无线耳机新品 WF-SP700N 选择加入了一点运动的风格。如之前在发布时介绍的那样,其 IPX4 级别的防水防汗能力可以更好地适应健身时的使用场景。而且按照 Sony 的说法,这也是...
-
82
国外一个老爸为了让宝宝学会的第一句话就是爸爸,在给宝宝读书的每句话前都加上一句“爸爸”,最后宝宝开口的时候,我好像听到什么东西碎了
-
84
奇思妙想 - @EchoChan - 只需要增加通话和短信,当功能手机用。不需要更多的第三方应用。系统不需要是智能系统。只要能依然保持续航很长就行了。有没有人也有这种奇葩需求。手机+墨水屏阅读器二合一。YOTA 虽然是一种
-
67
由于所有跨系统的接口服务都通过ESB服务总线进行封装代理后接入,因此理论上说从实际业务服务调用实例数据和日志中是可以反推出来端到端的业务流程的,也就是可以通过服务实例和服务链的监控来间接的监控跨系统的业务流转是否正常。简单来说,比如...
-
78
自提出互联网转型以来,苏宁创新科技零售:以云技术为基础,云服务为产品,为生产商、代理商、零售商提供开放的金融服务、供应链服务和产品品牌推广服务,为个人、家庭、企事业客户提供产品、内容、应用智能解决方案。
-
21
┅┅来更新┅┅大家都关心的卧蚕/眼影显脏问题卧蚕问题1,卧蚕我推荐在上完底妆后,先用眉刷开始画卧蚕(…
-
50
其实很多人对脸上的小颗粒,傻傻分不清楚,所以有的人干脆叫它脂肪粒。如果单纯从字眼来看,脂肪粒就是脂…
-
3
V2EX › 问与答 一只眼睛弱视怎么能通过深圳驾校体检
-
2
让智能产品加上眼睛,亚马逊云科技“智能产品流媒体”行业论坛即将开幕 ...
-
4
gRPC 服务要加 HTTP 接口? go-zero 给大家带来极简的 RESTful 和 gRPC 服务开发体验的同时,社区又给我们提出了新的期望: 我想只写一次代码 既要 gRPC 接口 也要 HTTP 接口 既要。...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK