

用 Python 优雅地玩转 Elasticsearch:实用技巧与最佳实践
source link: https://www.51cto.com/article/783662.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Elasticsearch,这个开源的分布式搜索与数据分析引擎,因其强大的全文搜索功能而广受欢迎。
尽管Elasticsearch的核心是用Java编写的,它提供了REST API,让各种编程语言的开发者都能轻松与之交互,Python当然也不例外。
今天,我们将深入探讨如何将 Elasticsearch 与 Python 结合使用,提升我们的项目到新的高度。

1、入门准备
首先,确保我们有一个运行中的 Elasticsearch 8.X 实例、Kibana实例。

图片
2、Elasticsearch Python 客户端介绍
在Python项目中,我们可以选择以下几个库与Elasticsearch交互:
elasticsearch-py:官方提供的低级客户端(Official low-level client for Elasticsearch),直接且灵活。
https://elasticsearch-py.readthedocs.io/en/v8.12.1/
elasticsearch-dsl:基于 elasticsearch-py 的高级封装,简化了很多操作,更适合日常使用。
https://elasticsearch-dsl.readthedocs.io/en/latest/
django-elasticsearch-dsl:为 Django 用户设计,基于elasticsearch-dsl,实现了与Django的深度集成。
https://django-elasticsearch-dsl.readthedocs.io/en/latest/
3、Elasticsearch Python 客户端适用场景及优缺点
elasticsearch-py | 直接与Elasticsearch交互的底层操作 | - 完整访问Elasticsearch API | - 代码复杂,易出错 |
elasticsearch-dsl | 构建复杂搜索查询 | - 简化查询构建 | - 学习成本相对较高 |
django-elasticsearch-dsl | 在Django项目中使用Elasticsearch | - 与Django无缝集成 | - 限定于Django项目 |
4、使用 elasticsearch-py 进行增删改查基础操作
elasticsearch-py 是Elasticsearch的官方低级Python客户端。
它允许我们执行所有基本和高级的Elasticsearch操作,包括直接与集群交互、管理索引、执行CRUD(创建、读取、更新、删除)操作以及搜索。
以下是使用elasticsearch-py的一些基础操作示例:
4.1 导入依赖
导入必要的Python库,包括datetime、Elasticsearch、configparser,并配置警告过滤以忽略警告信息。
from elasticsearch import Elasticsearch
import configparser
import warnings
warnings.filterwarnings("ignore")4.2 初始化Elasticsearch客户端
init_es_client函数从配置文件config.ini读取Elasticsearch的配置(如主机地址、用户名和密码),并初始化Elasticsearch客户端。这允许与Elasticsearch集群建立连接。
def init_es_client(config_path='./conf/config.ini'):
"""初始化并返回Elasticsearch客户端"""
# 初始化配置解析器
config = configparser.ConfigParser()
# 读取配置文件
config.read(config_path)
# 从配置文件中获取Elasticsearch配置
es_host = config.get('elasticsearch', 'ES_HOST')
es_user = config.get('elasticsearch', 'ES_USER')
es_password = config.get('elasticsearch', 'ES_PASSWORD')
es = Elasticsearch(
hosts=[es_host],
basic_auth=(es_user, es_password),
verify_certs=False,
ca_certs='conf/http_ca.crt'
)
return es
basic_auth=(es_user, es_password)Elasticsearch 8.X要求客户端连接时进行身份验证。这里使用基本认证(HTTP Basic Authentication)提供用户名和密码。这两个值应该对应于有效的Elasticsearch用户凭证,该用户需要有足够的权限执行客户端请求的操作。
verify_certs=False
这个选项告诉客户端是否验证Elasticsearch服务器的TLS证书。在生产环境中,我们应该将其设置为True以确保安全的通信。将此设置为False可能会导致中间人攻击等安全风险。在开发或测试环境中,如果使用的是自签名证书,可能需要暂时设置为False来避免验证错误。
ca_certs='conf/http_ca.crt'
当verify_certs=True时,这里指定了CA证书的路径,客户端将使用它来验证服务器证书的签名。这是实现TLS加密通信的关键部分。在Elasticsearch 8.X中,如果启用了安全特性(默认情况下启用),那么客户端需要信任连接到的Elasticsearch服务器使用的CA。如果Elasticsearch使用的是自签名证书或私有CA签发的证书,那么我们需要在客户端提供CA证书的路径。
对于Elasticsearch 8.X版本,正确配置客户端以安全地连接到Elasticsearch服务是非常重要的。这包括使用HTTPS协议、提供正确的用户认证凭证,以及在启用了TLS加密通信时验证服务器证书。为了最大化安全性和兼容性,强烈推荐在生产环境中使用由受信任CA签发的证书,并且始终验证服务器证书。
4.3 创建索引
create_index函数尝试创建一个新索引。如果指定的索引名已存在,则忽略创建操作。索引是数据存储和搜索的基本单位。
def create_index(es, index_name="test-index"):
"""创建索引,如果索引已存在则忽略"""
if not es.indices.exists(index=index_name):
es.indices.create(index=index_name)4.4 定义映射
define_mapping函数为索引设置映射。映射定义了索引中文档的字段类型,如文本、整数和关键词等。这有助于Elasticsearch理解字段内容并优化搜索和聚合操作。
def define_mapping(es, index_name="test-index"):
"""为索引定义映射"""
mapping = {
"mappings": {
"properties": {
"name": {"type": "text"},
"age": {"type": "integer"},
"email": {"type": "keyword"}
}
}
}
es.indices.create(index=index_name, body=mapping, ignore=400) # ignore=400忽略索引已存在错误4.5 插入文档
insert_document函数向指定索引插入(或更新)一个文档。文档由一个Python字典表示,可以包含多个字段和值。如果提供了doc_id,该ID将用于文档;否则,Elasticsearch会自动生成一个ID。
def insert_document(es, index_name="test-index", doc_id=None, document=None):
"""插入文档到指定索引"""
es.index(index=index_name, id=doc_id, document=document)4.6 更新文档
update_document函数更新指定索引中的特定文档。需要文档的ID和要更新的字段。
def update_document(es, index_name="test-index", doc_id=None, updated_doc=None):
"""更新指定ID的文档"""
es.update(index=index_name, id=doc_id, body={"doc": updated_doc})4.7 删除文档
delete_document函数从指定索引中删除特定ID的文档。
def delete_document(es, index_name="test-index", doc_id=None):
"""删除指定ID的文档"""
es.delete(index=index_name, id=doc_id)4.8 搜索文档
search_documents 函数在指定索引中执行搜索查询,并返回匹配的文档。查询通过一个查询DSL(Domain-Specific Language)构建,可以非常灵活地定义搜索条件。
def search_documents(es, index_name="test-index", query=None):
"""在指定索引中搜索文档"""
return es.search(index=index_name, body=query)4.9 main函数
main函数是程序的入口点,按顺序执行了创建索引、定义映射、插入文档、更新文档、搜索文档和删除文档的操作,演示了与Elasticsearch交互的完整流程。
def main():
# 初始化Elasticsearch客户端
es = init_es_client()
# 创建索引
create_index(es)
# 定义映射
define_mapping(es)
# 插入文档
doc = {
"name": "John Doe",
"age": 30,
"email": "[email protected]"
}
insert_document(es, doc_id="1", document=doc)
# 更新文档
# 注意:这里假设我们知道文档的ID。实际使用时可能需要通过搜索等方式来确定ID
update_document(es, doc_id="1", updated_doc={"age": 31})
# 搜索文档
query = {
"query": {
"match": {
"name": "John Doe"
}
}
}
search_result = search_documents( es, query=query )
print( search_result )
# 删除文档
delete_document(es, doc_id="1")以上示例展示了使用elasticsearch-py进行基本的Elasticsearch操作。
这些操作涵盖了创建和删除索引、定义映射、插入、更新和删除文档以及基本的搜索功能。
elasticsearch-py提供了访问Elasticsearch强大功能的直接途径,但正如之前讨论的,使用它需要对Elasticsearch的工作原理有深入理解。
5、使用 elasticsearch-dsl 进行基础操作
如下代码演示了如何使用elasticsearch-dsl,一个Python库,以便与Elasticsearch进行高效交互。
我们将涵盖初始化客户端、创建索引、文档的CRUD操作以及执行搜索查询。
5.1 初始化 Elasticsearch 客户端
为了与Elasticsearch集群交互,首先需要建立连接。我们通过读取配置文件来获取连接信息,并创建一个默认连接。
def init_es_client_dsl(config_path='./conf/config.ini'):
config = configparser.ConfigParser()
config.read(config_path)
es_host = config.get('elasticsearch', 'ES_HOST')
es_user = config.get('elasticsearch', 'ES_USER')
es_password = config.get('elasticsearch', 'ES_PASSWORD')
connections.create_connection(
hosts=[es_host],
http_auth=(es_user, es_password),
verify_certs=False
)5.2 创建索引
在Elasticsearch中,索引是存储文档的容器。我们定义了一个文档类 MyDocument,指定了索引名称和映射,并删除已存在的同名索引后重新创建。
class MyDocument(Document):
name = Text()
age = Integer()
email = Text()
class Index:
name = 'test-index'
settings = { "number_of_shards": 1, }
def create_index_dsl():
es = connections.get_connection()
es.indices.delete(index='test-index', ignore=[400, 404])
MyDocument.init()5.3 插入文档
将一个新文档插入到Elasticsearch。如果提供了id,将使用它作为文档ID;否则,Elasticsearch会自动生成一个。
def insert_document_dsl(document):
doc = MyDocument(meta={'id': document.get('id', None)}, **document)
doc.save()5.4 更新文档
根据文档ID更新已存在的文档。这里我们更新了文档的某些字段。
def update_document_dsl(doc_id, updated_doc):
doc = MyDocument.get(id=doc_id)
for key, value in updated_doc.items():
setattr(doc, key, value)
doc.save()5.5 删除文档
根据ID删除指定的文档。
def delete_document_dsl(doc_id):
doc = MyDocument.get(id=doc_id)
doc.delete()5.6 搜索文档
执行一个搜索查询,返回匹配指定查询条件的文档。在此例中,我们使用match查询匹配名字字段。
def search_documents_dsl(query):
es = connections.get_connection()
es.indices.refresh(index="test-index")
s = Search(index="test-index").query("match", name=query)
response = s.execute()
return response5.7 主函数
main_ds l函数串联了上述所有步骤,展示了如何在实际应用中使用这些功能。
def main_dsl():
init_es_client_dsl()
create_index_dsl()
insert_document_dsl({ ... })
results = search_documents_dsl('John Doe')
update_document_dsl('1', { ... })
delete_document_dsl('1')5.8 运行
将上述代码保存为Python文件并执行,可以看到从插入到搜索、更新和删除文档的完整流程。
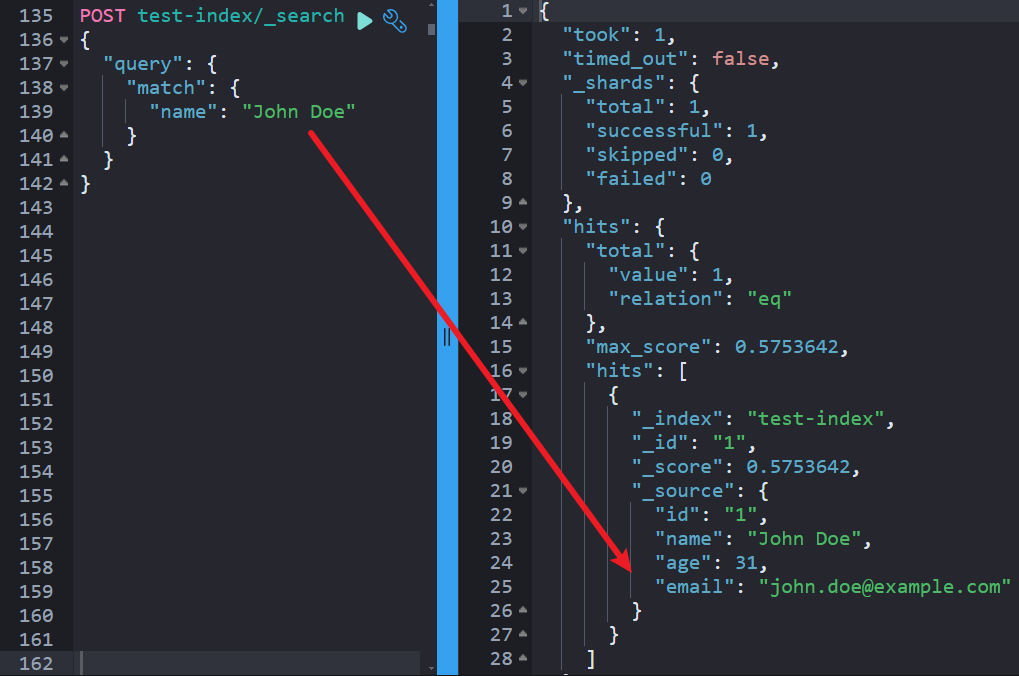
图片
5.9 特别强调——默认连接池管理
在elasticsearch-dsl中,当我们创建查询或者执行任何需要与Elasticsearch服务器通信的操作时,并不需要每次都显式地指定Elasticsearch连接实例。
这是因为elasticsearch-dsl内部维护了一个默认的连接池。当我们首次使用connections.create_connection函数创建连接时,如果不指定别名,这个连接就被设置为默认连接。
官方alias 示例:
from elasticsearch_dsl import connections
connections.create_connection(alias='my_new_connection', hosts=['localhost'], timeout=60)后续的所有操作,如搜索查询,都会自动使用这个默认连接,除非咱们通过using参数显式指定了另一个连接。
这种设计使得在大多数情况下,我们只需在应用启动时建立一次连接,而不需要在每个查询中重复指定连接信息,从而简化了代码并提高了代码的可读性和维护性。
https://elasticsearch-dsl.readthedocs.io/en/latest/configuration.html#default-connection
篇幅原因,django-elasticsearch-dsl API 没有展开。如果需要,欢迎留言讨论。
在本文中,我们探讨了如何将Elasticsearch与Python结合使用,通过两种主要的Python客户端——elasticsearch-py和elasticsearch-dsl。
elasticsearch-py提供了直接且灵活的底层API访问,适用于需要完整控制Elasticsearch交互细节的场景。
相比之下,elasticsearch-dsl提供了更高级的抽象,通过更为Pythonic的接口简化了复杂搜索查询的构建,使得代码更加简洁易读,尤其适合日常使用和复杂查询构建。
此外,我们还介绍了如何通过elasticsearch-dsl内部管理的默认连接池来简化连接管理,避免了在每次查询时重复指定连接信息,从而提高了开发效率和代码的可维护性。通过这种方式,开发者只需在应用启动时配置一次连接,之后便可以在整个应用中复用这个默认连接。
无论是直接使用elasticsearch-py进行底层操作,还是利用elasticsearch-dsl进行更加高效的数据处理和搜索,Elasticsearch都能为Python开发者提供强大的搜索和数据分析能力,帮助他们轻松应对各种数据处理和搜索需求,将项目提升到新的高度。在选择合适的客户端和API时,重要的是根据项目的具体需求和团队的熟悉程度来做出决策,以确保既能充分发挥Elasticsearch的强大功能,又能保持代码的可读性和可维护性。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK