

用大视觉模型开车,理想和清华叉院联手了
source link: https://www.qbitai.com/2024/03/126833.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

用大视觉模型开车,理想和清华叉院联手了

解决长尾难题,0.3s响应
曹原 发自 副驾寺
智能车参考|公众号AI4Auto
在大语言模型让语音助手开始“说学逗唱”的时候,另一边的大视觉模型已经发力自动驾驶了。
而且一出手,目标就是解决自动驾驶老大难的长尾问题。
新自动驾驶系统DirveVLM,融合视觉语言模型VLM的视觉理解、推理能力,让自动驾驶系统能认出来道路上倒着的自行车、横穿马路的牛、甚至是打手势的交警,并作出正确驾驶决策。
更重要的是,这还是个端到端系统,在英伟达Orin上就能跑,处理时间只需0.3s。
清华叉院联合理想汽车出品。
DriveVLM:长尾场景也会开
先看看论文中展示DriveVLM处理的几个场景。
场景一,一处城市开放道路,没有明显车道线,左边是对向车辆,比较拥挤;前方有一辆三轮车,路中央还有一位交警在指挥交通。

DriveVLM识别出这位交警在指挥左边道路的交通情况,并且由于前面的三轮车正在缓慢行驶,系统作出“缓慢直线行驶”的决策。
并且解释道,这么做是因为需要和前方及两侧车辆保持安全距离,所以需要缓慢直行。

场景二,阴雨天的城市道路,车辆准备向右前方道路行驶,但这条路上有一行人骑着电动车迎面而来。

DriveVLM识别出电动自行车位于车辆前方道路右侧,结合车辆的前进方向,作出“车辆先减速,右转,并缓慢直行”的决策。
并给出说明,减速是为了等骑车的人通过,待其通过后车辆再右转。

场景三,前方道路可能发生事故,车道前方有一辆自行车倒在路上,还有交警和一位行人站在道路上。
DriveVLM判断,由于自行车阻挡了前方道路,车辆又要前行,因此要“先减速,再向右变道,并缓慢直行”的决策。

同时系统还特别解释,减速并且确保右后方没有车辆驶来时,再向右变道。
不仅如此,高速公路上偶遇过路的牛群、路的另一侧即将倒下的树木、通过只够单车通过的桥、只有两条车辙的雪路等非常规场景,DriveVLM也都能一一识别并应对。
并且,DriveVLM除了能处理这些corner case,还能提供直观的语言界面,提供与用户的交互功能。

系统能够分析道路情况、天气条件、会影响本车前进的因素,并作出对应的驾驶决策,还能给出轨迹预测。
而这一切,除了基础的自动驾驶系统外,还离不开大模型的参与。
DriveVLM:大模型应用于行车域
实际上,DriveVLM是在传统的自动驾驶系统上,增加了大视觉语言模型(VLM)的能力。
由于VLM在视觉理解和推理方面的能力突出,所以结合该大模型能力后,DriveVLM不仅具备基本的自动驾驶能力,而且还能够理解输入的图像信息,并作出对应驾驶决策。
摄像头输入的图像序列先由视觉编码器进行处理,生成图像tokens,并通过自注意力机制捕捉其中的重要特征,与VLM的组成部分大语言模型进行对齐。
随后,大语言模型通过思维链(chain-of-thought,CoT)进行推理,主要包含三个模块,场景描述,场景分析和分层规划。
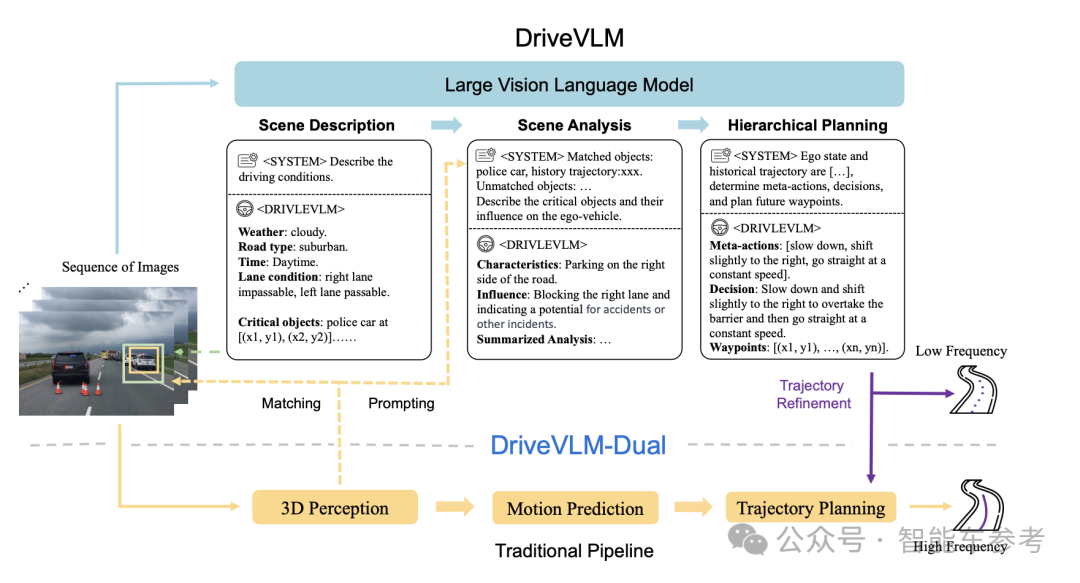
场景描述即输出驾驶环境的语言描述,包括天气状况、时间、道路类型和车道状况,方便系统判断是否选择更谨慎的驾驶方式(比如在夜间或者能见度较低的时候),以及选择是否需要变道。
描述完场景后,系统则开始场景分析,主要对关键对象进行分析,即会影响车辆驾驶决策的。
关键对象的判断要素包括三个,静态属性、运动状态和特定行为,比如正在做手势的交警就要列为关键对象,因为这时首先要参考交警的手势而不是交规。
在分析完这三个要素后,DriveVLM将预测每个关键对象对本车的潜在影响,比如路边醉酒的行人可能走上马路,挡住前方道路。
而这就增强了传统自动驾驶系统对交通环境的判断和理解,能够更加适应不常见,特别是训练时未见过的长尾场景。
这一模块的最后,系统还会生成场景摘要,分析总结当前场景下所有关键对象和环境描述,并与驾驶路线、车辆位置和速度信息结合,给出规划提示。
最后就是分层规划模块,DriveVLM主要分三部分进行:基础行为(meta-actions)、决策描述和轨迹航点。
基础行为包括17类,包括加速、减速、左转、变道、轻微位置调整、等待等等。
而决策描述则是在基础行为之上,结合场景里的关键主体(行人、红绿灯、车道等)和持续时间,给出更详细、简洁和可操作的驾驶决策。
比如在面对道路一侧有即将倒下的树木时,DriveVLM给出的决策是:立刻减速停车,在倒下的树木被清除后再继续行驶。

并且在给出决策描述后,系统还可以生成相应的轨迹航路点,实现语言处理模块和空间导航的无缝集成。
不过,VLM大模型虽然能帮助系统复杂场景理解,但模型巨大、反应速度慢,这就让DriveVLM无法直接应用于自动驾驶系统这种必需实时响应和决策能力。
所以,研究团队还推出DriveVLM-Dual,可集成3D物体感知进行关键对象分析,还能把轨迹航路点连点成线,输出线性的轨迹结果,并且降低延迟。
并且,团队还特意从大型数据库中挖掘出各种具有挑战性的长尾场景,并选取关键帧进行注释,给出了规划场景理解数据集SUP-AD。

最后,团队在常用的自动驾驶数据nuScenes和SUP-AD上都验证了效果。
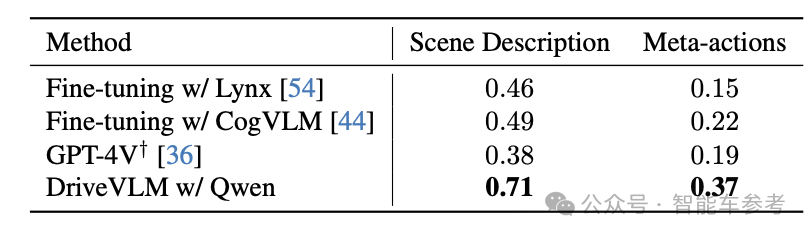
结果显示,DriveVLM在SUP-AD上,对于场景的理解以及给出的基础行为都实现SOTA,还超过GPT-4V。
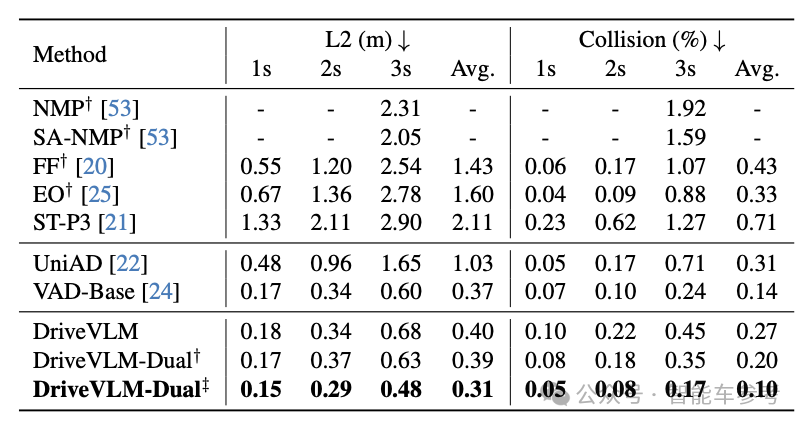
另一边在nuScenes上,DriveVLM-Dual在规划任务方面取得SOTA。
并且,团队还在英伟达Orin芯片上运行了DriveVLM-Dual,DriveVLM-Dual只需0.3s就能完成单一场景的推理,在保证推理结果的情况下,还能兼顾推理时间。
这意味着DriveVLM-Dual不仅是一个能快速响应、解决corner case的自动驾驶系统,而且还能在端侧部署,属于大模型加持下的新一代端到端自动驾驶系统。
研究团队简介
已经进入智能驾驶第一梯队的理想汽车和大佬云集的清华叉院,联合推出了DriveVLM。

来自叉院的Xiaoyu Tian和Junru Gu,以及来自理想汽车的Bailin Li,对本文有同等贡献。
其中,Xiaoyu Tian是目前就读于清华叉院的博士生,硕士毕业于清华大学软件学院,研究方向包括计算机视觉、自动驾驶、多模态学习等等。
而Bailin Li则是理想汽车静态感知部软件架构师。

他本科毕业于哈尔滨工业大学机械工程专业,还拥有密歇根大学机器人技术工程硕士学位,在2021年入职理想汽车。
本文的其他作者中,Yicheng Liu和胡晨旭也来自叉院,都是博士在读,胡晨旭还是清华MARS实验室的研究助理。

而Yang Wang、Kun Zhan和Peng Jia则来自理想汽车,其中Kun Zhan是理想汽车高级研发工程师,Peng Jia是AI基础设施高级总监。
作者还包括理想汽车自动驾驶副总裁郎咸朋,拥有中科大博士学位。

他曾在中国自动驾驶黄埔军校百度Apollo工作过,2018年入职理想汽车,2020年升任理想汽车副总裁,一直负责理想汽车自动驾驶业务。
本文的通讯作者是赵行,目前是清华叉院的助理教授,以及MARS实验室首席研究员。

赵行拥有麻省理工博士学位,师从计算机视觉大牛Antonio Torralba。来清华大学之前曾就职于美国自动驾驶巨头之一的Waymo,担任研究科学家,在谷歌学术上被引次数达到16804次。
在他们的共同努力之下,端到端、能理解城市道路中复杂的长尾场景的自动驾驶系统DriveVLM就此诞生。
随着AIGC产业的浪潮,大模型在车圈智能化下半场的竞争中,参与度越来越高。
从端侧来划分,应用于自动驾驶的大模型可以分为云端大模型和车端大模型两类。
比如毫末智行的雪湖·海若DriveGPT、华为盘古大模型、百度文心大模型,就是部署在云端,可以在场景生成、数据标注等方面,训练和优化自动驾驶系统的感知和决策能力。
在车端,现在已经成为行业标配的“BEV+Transformer”,则是主要用于优化车端系统的感知能力。
还有可以应用在车端的感知决策一体化的端到端大模型,比如特斯拉FSD V12、商汤等联合推出的UniAD,以及本文的DriveVLM。
大模型在AI行业带来的变革有目共睹,对于细分自动驾驶赛道来说,在大模型的帮助下,相信距离落地完全自动驾驶的那一天,也不远了。
项目主页:
https://tsinghua-mars-lab.github.io/DriveVLM/
论文传送门:
https://arxiv.org/pdf/2402.12289.pdf
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK