

作为开发需要了解 SSD 的一切
source link: https://www.luozhiyun.com/archives/833
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

这篇文章主要来探讨一下SSD相关的问题,以及我们在写代码的时候如何更高效的利用好 SSD 的特性。
SSD 基本介绍
其实现在 SSD 已经很普及了,SSD 被称之为固态硬盘是相对于普通的机械硬盘 HDD 而言,因为它没有机械结构。普通的机械硬盘 HDD 一般都需要将执行器臂将读写头定位在驱动器的正确区域上以读取或写入信息。
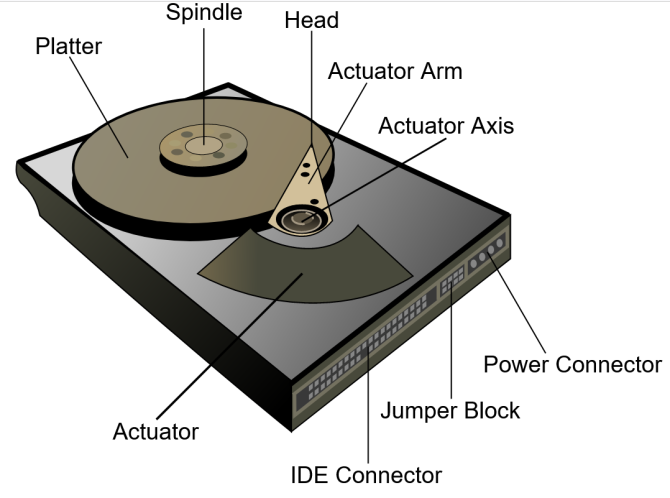
因为驱动器磁头必须在磁盘的某个区域对齐才能读取或写入数据,并且磁盘不断旋转,所以在访问数据之前会有延迟。HDD 的延迟通常以毫秒为单位,硬盘驱动器通常需要10-15ms才能在驱动器上找到数据并开始读取,即使是现在 15000 转的 HDD 延迟最低也要 4ms,IOPS(每秒的输入输出量) 在 200 左右,顺序读写速度在300MB/s 左右 。
反观我们看现在 SSD,以三星的 990 PRO为例,读写速度最高达到了 7000+ MB/s ,IOPS 高达 1,400K,延迟在 41us 左右,这么一对比,大家可以知道其实 SSD 比 HDD 快了好几个数量级。
SSD 内部结构
SSD 的内部结构一般是由三部分构成:1. Controller 控制器 ;2.DRAM缓存;3.NAND闪存;

控制器是用来控制 SSD 的所有操作的,从实际读取和写入数据到执行垃圾回收和耗损均衡算法等,以保证SSD 的速度及整洁度;
DRAM缓存不是所有的硬盘都有,对于我们上面提到的 990 PRO 来说会有 2GB 左右的缓存,主要是用来存放的是逻辑物理映射表,控制器会通过缓存的映射表来查找数据使用。还承载了一部分待写入的数据,等够一页的时候一次性写入到NAND颗粒里面,用来缓解写入放大;
顺带提一下无缓的固态硬盘也不用过于担心性能问题,一般来说会使用 HMB 技术通过PCIe通道找内存借用一部分内存空间来存储映射表,在每次开机的时候往内存写入部分常用的FTL表,这个空间大小通常是64MB。像我们国产的致钛TiPlus7100就是采用的无缓+HMB机制,其速度也不差。
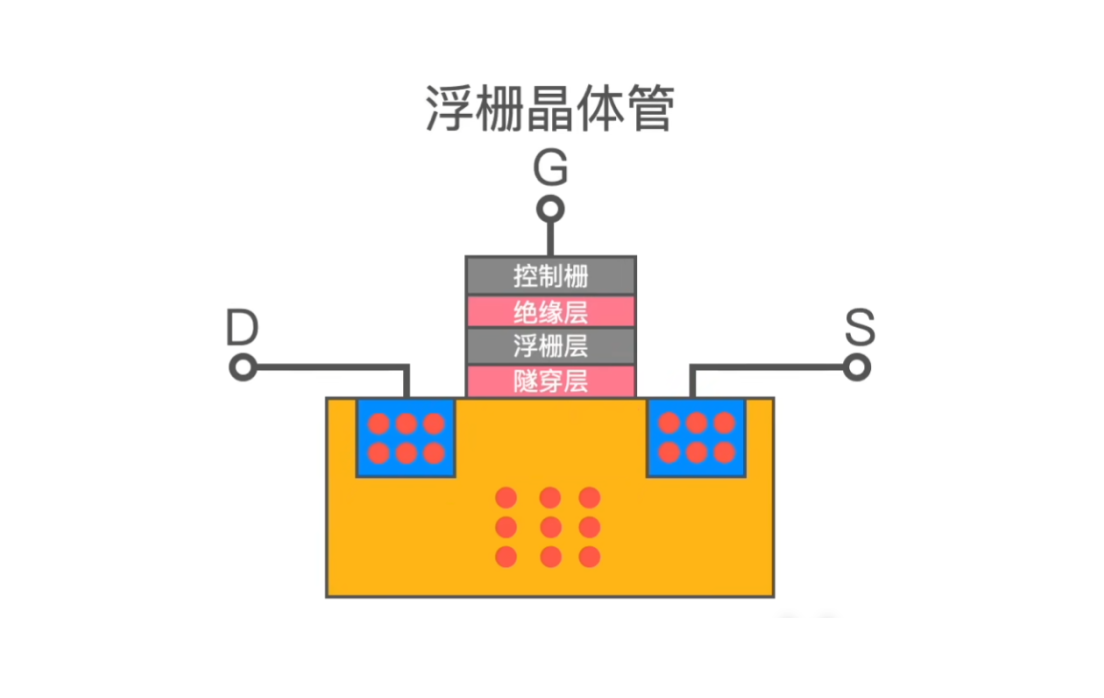
NAND 闪存是最终用来存放数据的地方,它不仅决定了SSD的使用寿命,而且对SSD的性能影响也非常大。比如大家所熟知的 SLC, MLC, TLC 闪存。NAND本身由所谓的浮栅晶体管组成,它是一种非易失性存储器,即使不通电也能保持状态,NAND 由一个个浮栅晶体管堆叠而成。根据每个浮栅晶体管可以保存1bit, 2bit, 3bit数据量可以分为SLC, MLC, TLC。
1个Page 一般是4KB 或者 8 KB ,上面我们提到的 990 PRO 是 16KB, 不同 SSD 大小也不同。因为浮栅晶体管被分组并以非常特定的属性访问,所以我们只能按页来进行数据的读写,如下简化图中红色的每一行都代表一个 Page ,写数据的时候会给行列两端加上不同的电压,加电压只能加到行和列上,所以没法控制到单个浮栅晶体管;
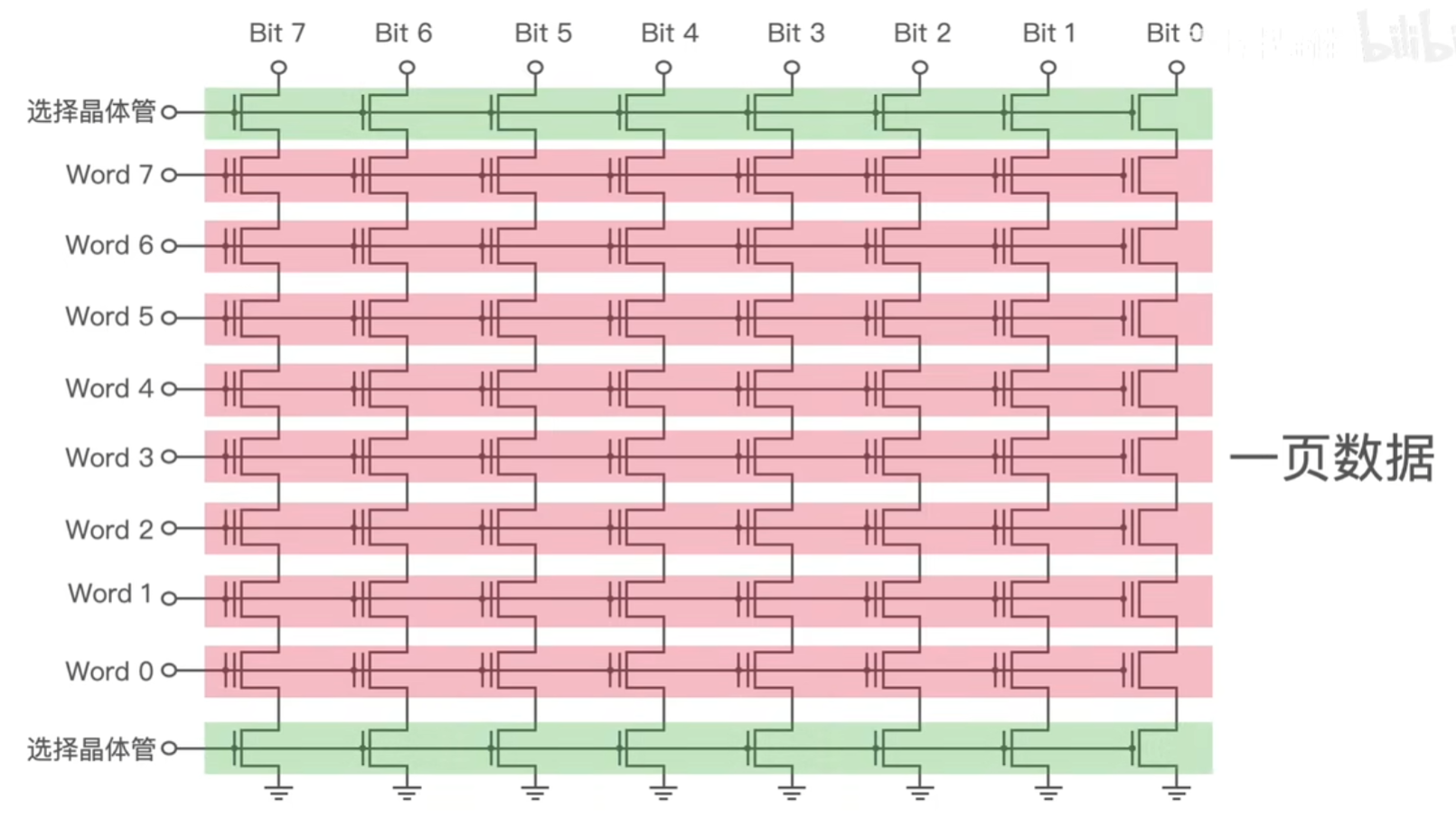
Block 是擦除的基本单位,每个 Block 会包含 128 到 256 个上面这样的 Page。如下图由于一块 Block 上面的所有浮栅晶体管其实是共用一个衬底,只要给这个衬底施加高压,浮栅晶体管里面存储的数据就会被清空,所以 Block 是擦除数据的基本单位。

为啥 SSD寿命是有限的?
其实这取决于浮栅晶体管的结构,它的结构下图所示,我不打算概述它的原理,但是我们可以知道在浮栅晶体管中电子是存储在浮栅层的,读写数据的时候电子需要穿过隧穿层,由隧穿层来锁住电子,隧穿层穿越次数是有限制的,进出次数多了,就锁不住电子了,那么该 Block 就没法擦写数据了。
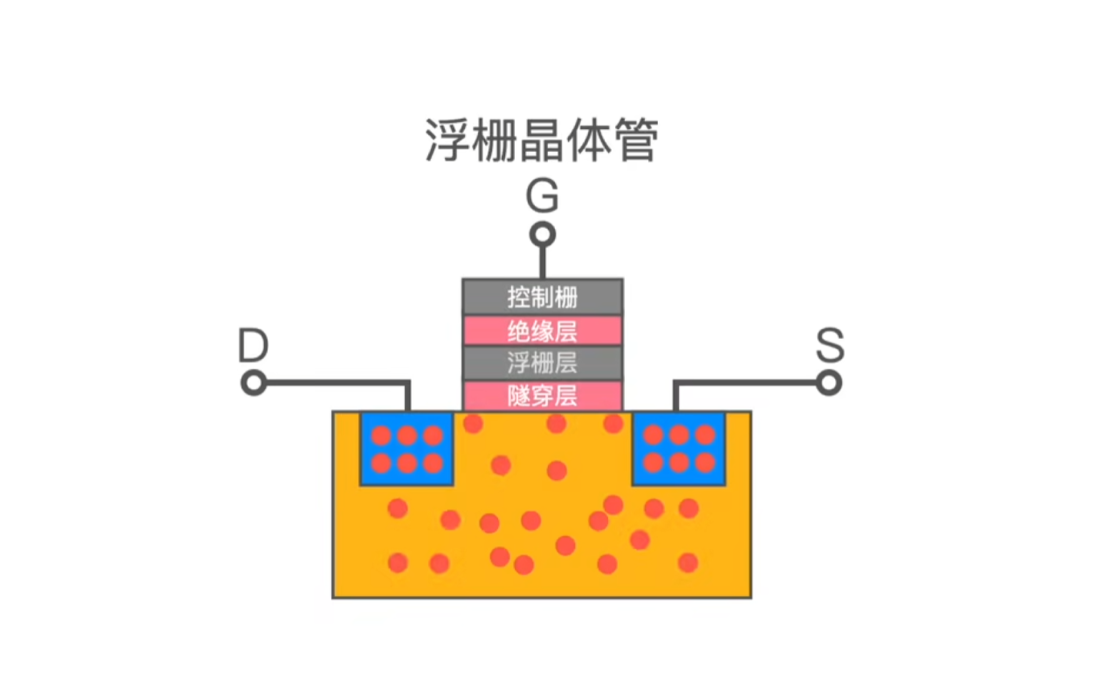
所以如果一直在同一个 Block 擦写数据,这个 Block 的寿命很快就会消耗完,为了有效的延迟 SSD 的使用寿命就很考验 Block 的管理技术了,后面我们可以看看现在的 SSD 有哪些管理抓手。
读、写、擦除
当首次向SSD写入数据时,因为数据都处于已擦除的状态,所以数据可以直接写入,至少一次性写入一个 Page。因为在写入的时候会按照 Page 为单位进行写入,所以如果要写入的数据小于一个 Page,那么其余写入超过必要的数据称为写入放大。
只有空闲的Page才能被写入,并且是不能覆盖的,所以在修改数据的时候数据会被写入到一个空闲页面中,一旦被持久化到页面上,原来的旧页面会被标记成 stale 状态,表示它可以被擦除。
所以一个 Page 变成 stale 状态之后唯一能让它们再次使用的方式就是擦除它们,但是擦除的维度我们上面也讲过了,是以 Block 为维度进行擦除的,并且擦除命令不由用户控制,擦除命令是由SSD控制器中的垃圾回收机制进程在需要回收陈旧页面以腾出空闲空间时自动触发的。
除了上面提到的写入放大以外,如果在写入数据的时候不是以 Page 为单位进行写入,会导致Page 被修改并写回驱动器之前被读入缓存,这种操作被称为读-修改-写,比直接操作页面要慢。
所以我们写入数据的时候应该要对齐写入,也就是按 Page 整倍大小写入。并且为了最大限度地提高吞吐量,尽可能将小写入保留到 RAM 中的缓冲区中,当缓冲区已满时,执行一次大写入以批处理所有小写入。
数据以 Page 为单位写入到存储中。然而,存储器只能以较大的单位 Block 擦除。如果不再需要一个Block 中某些Page内的数据,仅会读取该块中含有有效数据的Page,并重新写入到另一个先前擦除的空 Block 中,然后将原来的 Block 进行擦除,擦除之后的 Block 又可以重新使用,这个过程叫做垃圾回收。
所有的SSD都包含不同程度的垃圾回收机制,但在执行的频率和速度上有所不同,垃圾回收占了SSD上写入放大的很大一部分。

比如上面这个例子中,在 Block 1000 中写入 x,y,z 三个数据,然后想要修改 PPN 为 0 的这块数据时由于不能覆盖,所以只能在 PPN 为 3 的 Page 上面写入 x` 。当后台的垃圾回收进程启动的时候会将有效的数据拷入到另一个空闲的 BLock 中,然后将原来的 Block 1000 中的数据擦除。
SSD 擦除写入的次数也叫做 P/E 周期( program/erase cycle),由于 P/E 周期是有限的,所以假设SSD其中数据总是从同一个精确的块中读取和写入,那么这块 Block 很快就达到了使用寿命的上限,SSD控制器会将其标记为不可用。然后磁盘的整体容量会下降。
所以实现磨损均衡(wear leveling)是控制器的主要目标之一,即在块之间尽可能均匀地分配P/E周期,理想情况下,所有块都将达到其P/E周期限制并同时磨损。
我这里用长江存储致钛的图来解释一下,上面三张是没有磨损均衡的,那么反复写就会出现坏页,下面三张是有磨损均衡,那么控制器会根据不同的算法挑选出擦写次数较低的 Page 进行写入。
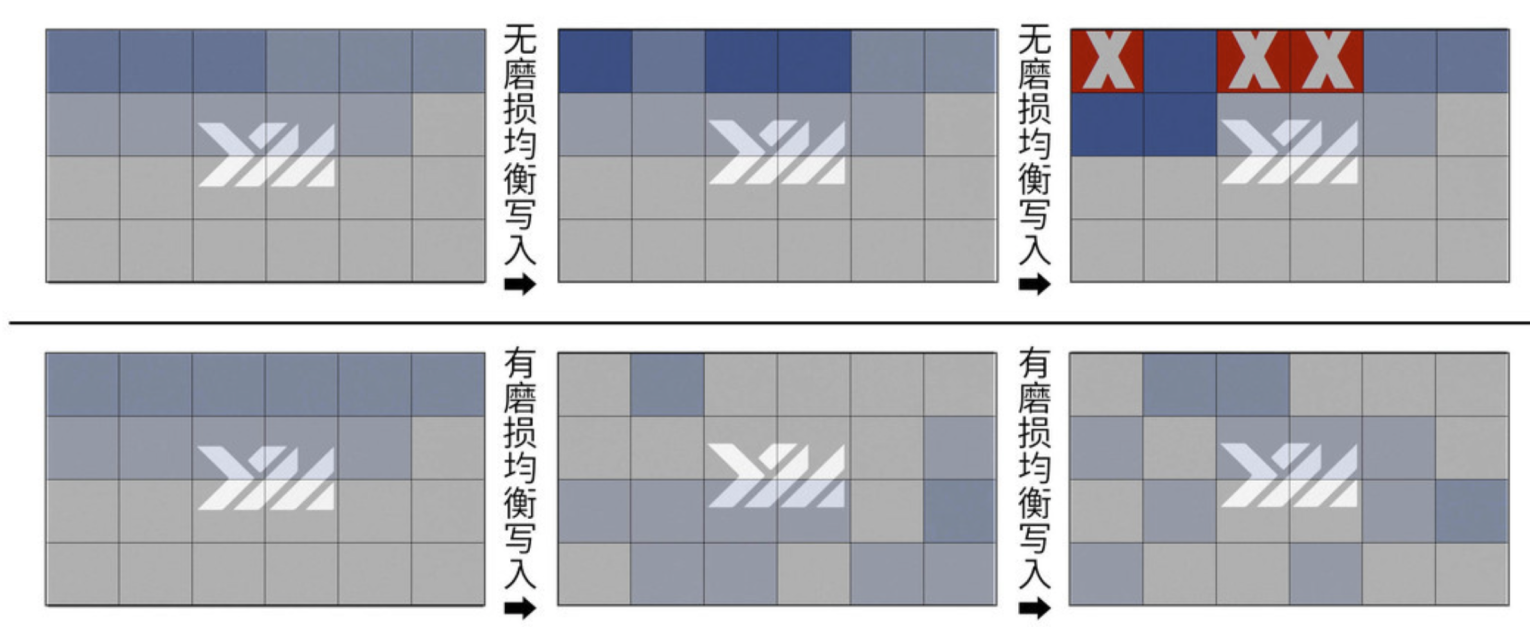
当然我们也知道,理论和现实总是有区别的,具体实现起来还是很难的。因为想要磨损均衡,那必须要写入的时候将一些Block的数据进行移动,这一过程本身会导致写入放大的增加。因此,块管理是最大化磨损均衡和最小化写入放大之间的权衡,也就是它是一个 trade-off 的艺术。

磨损均衡分为静态磨损均衡与动态磨损均衡。动态磨损平衡是指当需要更改某个Page中的数据时,将新的数据写入擦除次数较少的物理页上,同时将原页标为无效页,动态磨损平衡算法的缺点在于,如果刚刚写入的数据很快又被更新,那么,刚刚更新过的数据块很快又变成无效页,如果频繁更新,无疑会让保存冷数据的Block极少得到擦除,对闪存整体寿命产生不利影响。早期的SSD主控多用动态磨损平衡算法。
静态磨损均衡是在每次写入时从空白Page中挑选擦写次数最少的进行写入,并且为了防止冷数据的Block极少得到擦除,静态磨损均衡会在条件具备的情况下搬走长期占用Block的不变数据,将其释放出来用于新数据写入,从而避免过度消耗其他闪存单元的寿命。
预留空间 Over-provisioning,也叫OP,指的是 SSD 一般会保留一部分的空间对用户不可见,大多数的厂商都会预留7%到25%左右的空间,额外的预留空间有助于降低控制器写入闪存时的写入放大。用户可以通过将磁盘分区为低于其最大物理容量的逻辑容量来创建更多的过度配置。例如,可以在100 GB驱动器中创建一个90 GB分区,并将剩余的10 GB预留不使用。
比如下面的这种图中, 是我找到金士顿官网的预留空间图:
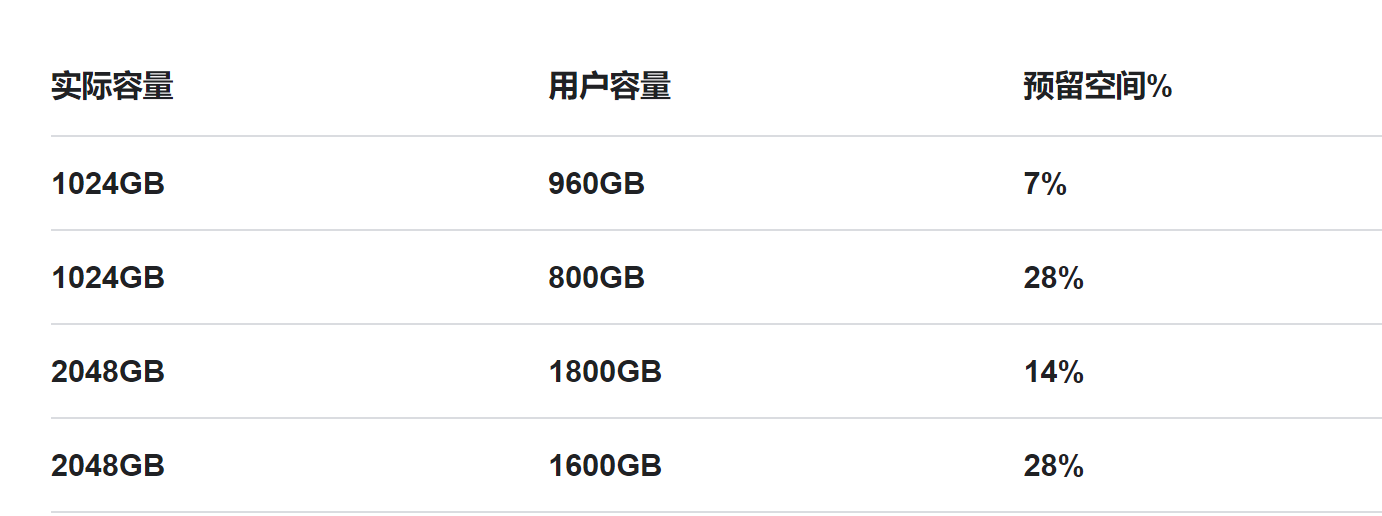
预留空间主要是给 SSD 控制器使用,一方面是用来做是用来做磨损平衡,替换可见空间中被磨损的 Block,另一方面是用来提升性能使用;
因为上面也提到了,SSD 的写入是无法覆盖的,只能在空白页面上写入,所以在这个过程中预留空间足够大则从空白的页中进行写入,可以减少擦除次数也能够减少有效数据的再次写入,降低 Block 的磨损,从而提升硬盘的耐用性。
预留空间在读写工作负载很重的时候可以充当NAND闪存块的缓冲区,帮助垃圾回收机制处理吸收写入高峰。因为垃圾回收擦除数据比写入要花费更多的时间,垃圾回收一般在空闲的时候做,如果在负载很重的时候垃圾回收来不及擦除,那么可能会和写入操作同时进行,而预留空间可以作为缓冲区给垃圾回收机制留出足够的时间来赶上并再次擦除块。
另一方面预留空间也可以减少垃圾回收次数,空白页面多了自然就不用频繁的做垃圾回收了,这同时也减少了写入放大。
简单来说,TRIM主要是优化固态硬盘,解决SSD使用后的降速与寿命的问题。
原本在机械硬盘上,写入数据时,Windows会通知硬盘先将以前的擦除,再将新的数据写入到磁盘中。而在删除数据时,Windows只会在此处做个标记,说明这里应该是没有东西了,等到真正要写入数据时再来真正删除,由于这个标记只是在操作系统层面,SSD 并不知道哪些数据被删了,所以我们日常的文件删除,都只是一个操作系统层面的逻辑删除。这也是为什么,很多时候我们不小心删除了对应的文件,我们可以通过各种恢复软件,把数据找回来。
SSD 只有当操作系统在同一个被删了的 Block 里面写入数据的时候才知道这个数据已经被删了,那么才会把它标记成废弃,等待垃圾回收。。这就导致,我们为了磨损均衡,很多时候在都在搬运很多已经删除了的数据。这就会产生很多不必要的数据读写和擦除,既消耗了 SSD 的性能,也缩短了 SSD 的使用寿命。
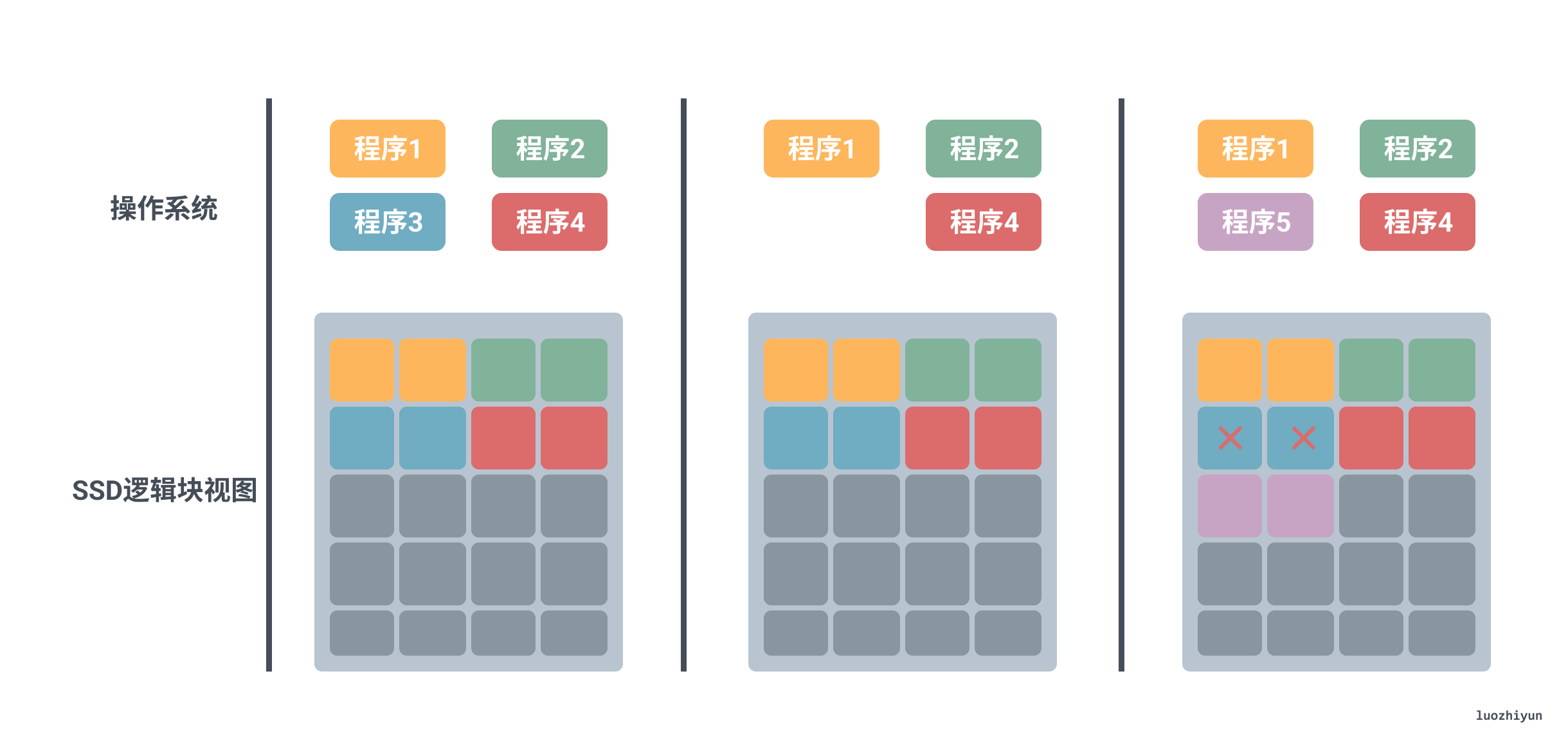
比如上面这个图中,我们在系统层面删除了程序3,但是在SSD 的逻辑块层面,其实并不知道这个事情。这个时候,如果我们需要对 SSD 进行垃圾回收操作,程序3占用的物理页仍然要在这个过程中,被搬运到其他的 Block 里面去。只有当操作系统在里面重新写入数据的时候SSD才会把它标记成废弃掉。
TRIM指令让操作系统可以告诉固态驱动器哪些数据块是不会再使用的;否则SSD控制器不知道可以回收这些闲置数据块。TRIM的简约性将极大减少写入负担,同时允许SSD更好地在后台预删除闲置的数据块,以便让这些数据块可以更快地预备新的写入。
TRIM命令只有在SSD控制器、操作系统和文件系统支持它的情况下才有效。
来看并发性之前,先来看看 SSD 具体的层级结构,SSD 使用层级的方式管理NAND Flash。Controller会使用多Channel的方式与NAND Flash Chip连接。每个Channel可以被视为一条数据传输路线,多个通道可以让控制器同时读写更多的数据,提高数据传输的速度和效率。每个NAND Flash Chip内部封装(Packaging)了多个Die,每个Die上排列了多个Plane,每个Plane中包含多个Block,每个Block中有多个Page。
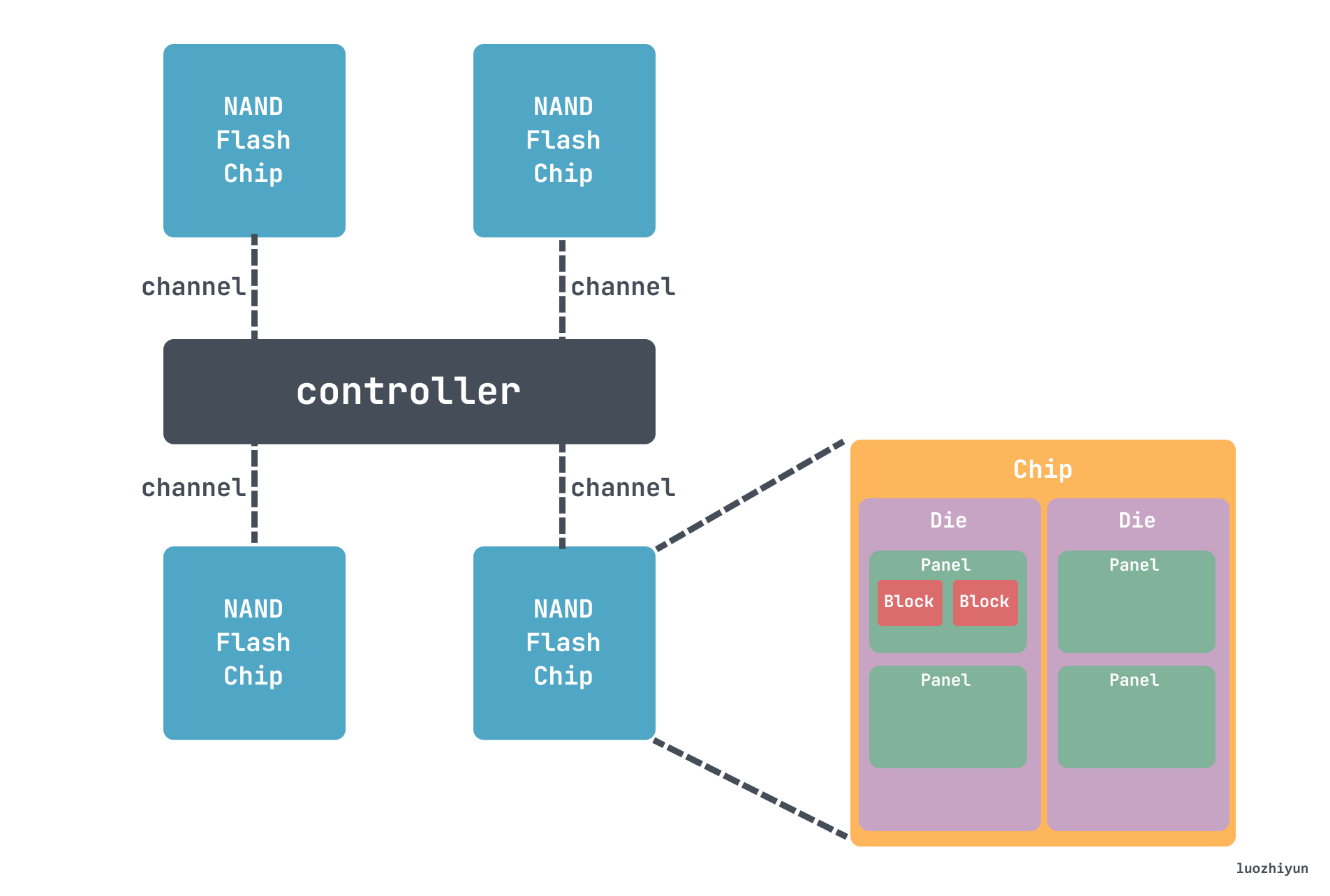
- Channel级别:Controller可以同时使用多个Channel在不同的NAND Flash Chip上执行不同的操作
- Chip级别:连接在相同Channel上的不同的不同Chip,也可以使用流水线(Interleaving)的方式同时执行不同的命令
- Die级别:一个Chip封装多个Die,Chip可以把不同的命令发送到多个Die上并行执行
- Plane级别:一个Die包含多个Plane,相同的命令(读、写、擦除)可以在一个Die的多个Plane上同时执行
像我们上面提到的 990 Pro 这款 SSD,有 8条 Channel,每条Channel可以传输2,000 MT/s,MT/s代表每秒百万次传输(MegaTransfers per second)。每个 Chip 里面有 16 个 Die,每个 Die 有 4 个 Plane。
写的并发性
所以通过上面信息可以知道,SSD 是可以并行写入多个 Block 的,所以利用 SSD 多级并行机制,可以被并行访问的最大数量的 Block 集合称为一组 Cluster Blocks,它的可以从几十MB到几百MB,具体取决于控制器策略、SSD 容量、NAND 闪存类型等,不过我查过了,一般厂商没有给出这个具体的大小。
利用Cluster Blocks的并行性能,SSD可以把一次大块写打散到多个Cluster Blocks上并行执行,有效降低时延,提高吞吐量。
如果写操作每次写入的数据量小于 Cluster Blocks 大小时则顺序写的吞吐量显著高于随机写,所以如果随机写入既是Cluster Blocks 的倍数,那么它们的性能与顺序写入一样好。两者的区别主要体现在以下两个方面:
- 小块写入会导致更多的映射表更新,而顺序写可以合并映射表的更新;
- 小块随机写更容易造成某个Block中少量的Page被设置为无效,需要进行擦除,加剧垃圾回收过程的写放大;
最后,关于并发,其实用一个线程写入一大块数据和用许多并发线程写入许多较小块数据一样快。事实上,一个大写入保证了SSD的所有内部并行性都被使用。因此,尝试并行执行多个写入不会提高吞吐量。然而,与单线程访问相比,许多并行写入会导致延迟增加。所以一次大写入比多次小并发写入要好。
再来就是当写入很小并且无法合并的时候,多线程是有益的,许多并发的小写请求将提供比单个小写请求更好的吞吐量。所以如果I/O很小并且无法批处理,最好使用多个线程。
总结就是这样:
| 大块写 | 小块写 | |
|---|---|---|
| 单线程 | 最快 | 最慢 |
| 多线程并发 | 无助于吞吐量,提高时延 | 有助于提高多级并发机制的利用,提高吞吐量 |
读的并发性
同样的为了提高读取性能,最好将相关数据一起写入。因为读取性能是写入模式的结果。当一次写入一大块数据时,它会分布在单独的NAND闪存芯片上。因此,您应该在同一页、块或集群块中写入相关数据,这样以后就可以利用内部并行性,通过单个I/O请求更快地读取这些数据。
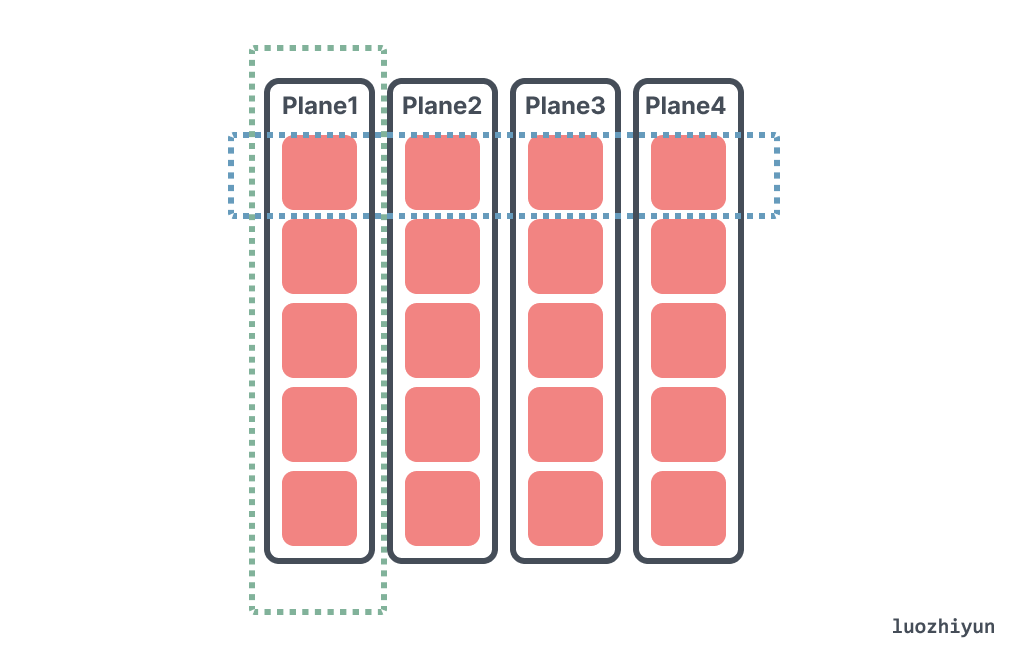
因为写入的时候SSD会尽量的把所写的Page打散到多个Clustered Block上进行并行,那么读操作如果同时读取这些Page将会获得最多的并行。相反如果读操作总是读取不同写操作写入的Page,那么这些Page很可能处于相同的Plane上,必须串行读取。如上图所示。
对于多线程并发小块数据读取来说,性能是不如单线程大块数据读取的,因为这不能用到预读机制,这种机制通过预先读取可能接下来会被请求的数据到缓存中,减少了数据访问的等待时间,从而提升了读取性能。
在编程时如何更好的利用SSD
更好的利用SSD可以获得一些免费的好处,如:提升应用程序性能、延长SSD的寿命、提高SSD的 IO 效率等等。
区分冷热数据
假设我们将冷热数据混合排布在同一个区块,对于 SSD 来说,如果要修改其中的一小块内容(小于 1 页),SSD 仍然会读取整页的数据,这样会导致写入放大。所以对于一些改动非常频繁的热数据应该尽可能的 cache 住在内存里,然后批量的进行更新,这样不仅更快,而且还能提升SSD寿命。
采用紧凑的数据结构
这其实也和 SSD 的结构相关,更紧凑的数据结构可以尽量让数据都聚拢在同一个 Block 中,减少 SSD 的读取操作,同时也能更好的利用缓存。同样的,由于SSD 写入方式的特殊性,紧凑数据结构将关联数据放置到相邻区域,减少可能的垃圾回收的同时,还能够降低写入放大带来的问题。
写的数据最好是页大小的倍数
避免写入小于NAND闪存页面大小的数据块,以最大限度地减少写入放大并防止读取-修改-写入操作。目前页面的最大大小为16 KB,因此默认情况下应使用该值,此大小取决于SSD型号。
当数据不足一页时为了最大限度地提高吞吐量,尽可能将小写入保留到RAM中的缓冲区中,当缓冲区已满时,执行一次大写入以批处理所有小写入。
将相关数据一起写入
读取性能是写入模式的结果。当一次写入一大块数据时,它会分布在单独的NAND闪存芯片上。因此,您应该在同一 Page、Block或 clustered block 中写入相关数据,这样以后就可以利用内部并行性,通过单个I/O请求更快地读取这些数据。
尽量避免读写混合
由小交错读写混合组成的工作负载将阻止内部缓存和预读机制正常工作,并将导致吞吐量下降。最好避免同时读取和写入,并在大块中一个接一个地执行它们,最好是clustered block的大小。例如,如果必须更新1000个文件,您可以迭代文件,对文件进行读写,然后移动到下一个文件,但那会很慢。最好一次读取所有1000个文件,然后一次写回这1000个文件。
不要总以为随机写入比顺序写入慢
如果写入很小(即低于clustered block的大小),则随机写入比顺序写入慢。如果写入既是clustered block的倍数,又与clustered block的大小对齐,随机写入将使用所有可用的内部并行级别,并且执行与顺序写入一样好。对于大多数驱动器,集群块的大小为16 MB或32 MB,因此使用32 MB是安全的。
大型单线程读取优于许多小型并发读取
上面我们也提到了,并发随机读取不能充分利用预读机制。此外,多个逻辑块地址可能最终在同一芯片上,没有利用或内部并行性。大型读取操作将访问顺序地址,因此能够使用预读缓冲区(如果存在)并使用内部并行性。因此,如果用例允许,最好发出大型读取请求。
大型单线程写入优于许多小型并发写入
大型单线程写入请求提供与许多小型并发写入相同的吞吐量,但是就延迟而言,大型单线程写入比并发写入具有更好的响应时间。因此,只要有可能,最好执行单线程大型写入。
当写入量很小并且无法分组或缓冲时,才使用多线程写
许多并发的小写请求将提供比单个小写请求更好的吞吐量。所以如果I/O很小并且无法批处理,最好使用多个线程。
对于读写负载很高的工作,应该配置更大的预留空间
预留空间有助于磨损均衡机制应对NAND闪存单元固有的有限生命周期。对于写入不那么重的工作负载,10%到15%的过度配置就足够了。对于持续随机写入的工作负载,保持高达25%的过度配置将提高性能。过度配置将充当NAND闪存块的缓冲区,帮助垃圾回收机制处理吸收写入高峰。
Reference
https://codecapsule.com/2014/02/12/coding-for-ssds-part-1-introduction-and-table-of-contents/
https://www.bilibili.com/video/BV1aF411u7Ct/?vd_source=f482469b15d60c5c26eb4833c6698cd5
https://www.extremetech.com/gaming/210492-extremetech-explains-how-do-ssds-work
https://www.bilibili.com/video/BV1644y157mB/?vd_source=f482469b15d60c5c26eb4833c6698cd5
https://zh.wikipedia.org/wiki/%E5%86%99%E5%85%A5%E6%94%BE%E5%A4%A7
https://time.geekbang.org/column/article/118191
https://www.techpowerup.com/ssd-specs/samsung-990-pro-2-tb.d862

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK