

MySQL分库分表也拉垮,日扛百万数据查询还得ClickHouse - 更多 - dbaplus社群:围绕Da...
source link: https://dbaplus.cn/news-160-5895-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

MySQL分库分表也拉垮,日扛百万数据查询还得ClickHouse
作者介绍
杨博,哔哩哔哩高级开发工程师。
王智博,哔哩哔哩资深开发工程师。
一、业务背景
1.什么是直播公会
直播公会是指从事网络直播表演的组织、制作、营销等经营活动和主播的签约、推广、代理等经纪活动的机构。
B站为外部公会提供了主播全生命周期的管理系统,包含主播的入退会管理、主播营收数据分析、主播开播看播数据分析、直播监控、营收账单结算等功能子模块。
同时为了鼓励、引导外部公会有针对性对潜力主播进行孵化扶持,公会系统协同B站内部多业务方,提供一系列业务激励、流量策略,满足公会日常运营需求。
2.公会业务对于数据查询场景分析
1)数据场景
公会系统主要的服务对象是外部公会运营人员,在日常公会运营工作中,通常关注以下数据:
-
主播日维度准实时营收数据
-
主播日维度准实时看播数据
-
主播日维度准实时垂直业务数据
-
公会日维度准实时营收数据
-
主播T+1任务进度
-
主播T+1月、年维度营收数据
-
主播T+1月、年维度看播数据
-
主播T+1月、年维度垂直业务数据
-
公会月、年维度准实时营收数据
且对数据更新频率敏感,通常需要准实时的数据进行观测。
3.查询数据量预估
截至2023年12月,B站公会主播量级为百万级,为满足各项业务数据查询需求,公会侧存储日粒度的主播业务数据,日均数据在百万级。
-
主播维度年度数据聚合:
预估数据量:1*365 = 365
-
公会维度日、周、月、年度数据聚合(以最大公会主播数据量级20万记):
预估数据量:
日- 200000
周-200000 * 7 = 1,400,000
月-200000 * 30 = 6,000,000
年-200000 * 365 = 73,000,000
二、技术方案选型/演进
1.数据方案选型:从MySQL到ClickHouse
1)MySQL数据查询压力
基于上述“查询数据量预估”,在索引设计合理的情况下,公会维度数据按月聚合已需要扫描至少6,000,000行数据。
按照数据库配置4核8G,此时查询平均时间已达到20s+水平,无法满足业务要求。
2)MySQL数据存储压力
在公会主播百万级数据压力下,存储一年必要的热数据为:
1000000 * 365 = 365,000,000
虽然可通过分库分表等方式缓解数据存储压力,但是在实际的查询场景中,分库分表存在着天然的数据查询硬伤,无法灵活满足OLAP需求。
3)数据查询QPS分析
对公会数据查询接口进行流量分析,需要查询准实时全量公会数据的QPS最高不超过20,通过梳理业务场景,针对大公会进行数据分流,即使未来公会业务大力发展,任然可以将接口整体QPS控制在50以下。
4)难点
按照公会实际情况,主播与经纪人1:N关系,经纪人与其所属管理员1:N关系,并且经纪人、管理员进行数据查询时需要进行数据隔离,因此无法对汇总数据进行缓存或提前计算等操作。
基于上述特性,数据量大、单次查询扫描行数多、查询QPS可控、数据频繁更新,选择ClickHouse作为数据处理工具支撑公会业务。
2.技术方案演进:业务场景流量隔离,OLAP业务重构数据链路
1)流量隔离
通过梳理业务场景,将数据查询分为以下三类:
-
外部公会后台准实时查询长时间跨度公会维度数据概览:此场景下,需要实时汇总登录用户权限范围内的数据概览,无法进行数据预热的同时需要进行大量数据计算。
-
外部公会后台查询主播详细数据:仅需查询单主播数据,需要扫描的数据行数可控。
-
T+1脚本查询数据计算任务进度:通过定时任务,T+1计算主播维度、公会维度任务进度,查询姿势可控、筛选条件较少,但QPS较高。
公会服务通过查询特性,将主播维度、短时间跨度、查询简单但QPS高的业务通过MySQL业务宽表进行支撑;将经纪人、管理员、公会维度等需要扫描大量数据的业务通过ClickHouse支持。
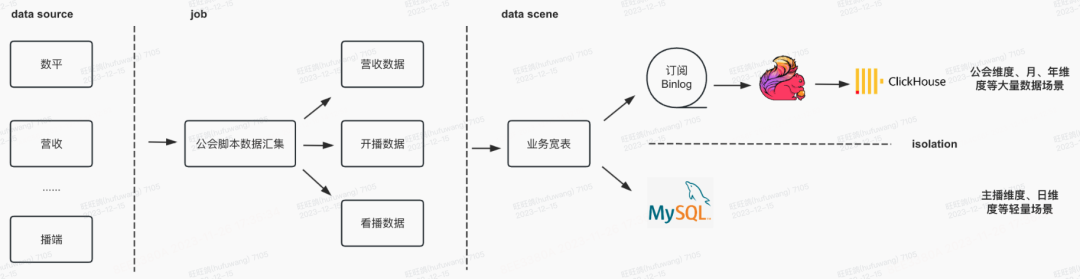
2)针对ClickHouse特性进行全局流量管控
-
公会数据异步导出中心
针对ClickHouse支持QPS较低的问题,公会服务针对数据导出场景进行全局限流,限制同时数据导出任务数量,控制导出任务查询频率等方式,支持公会大数据量场景下的数据导出功能。
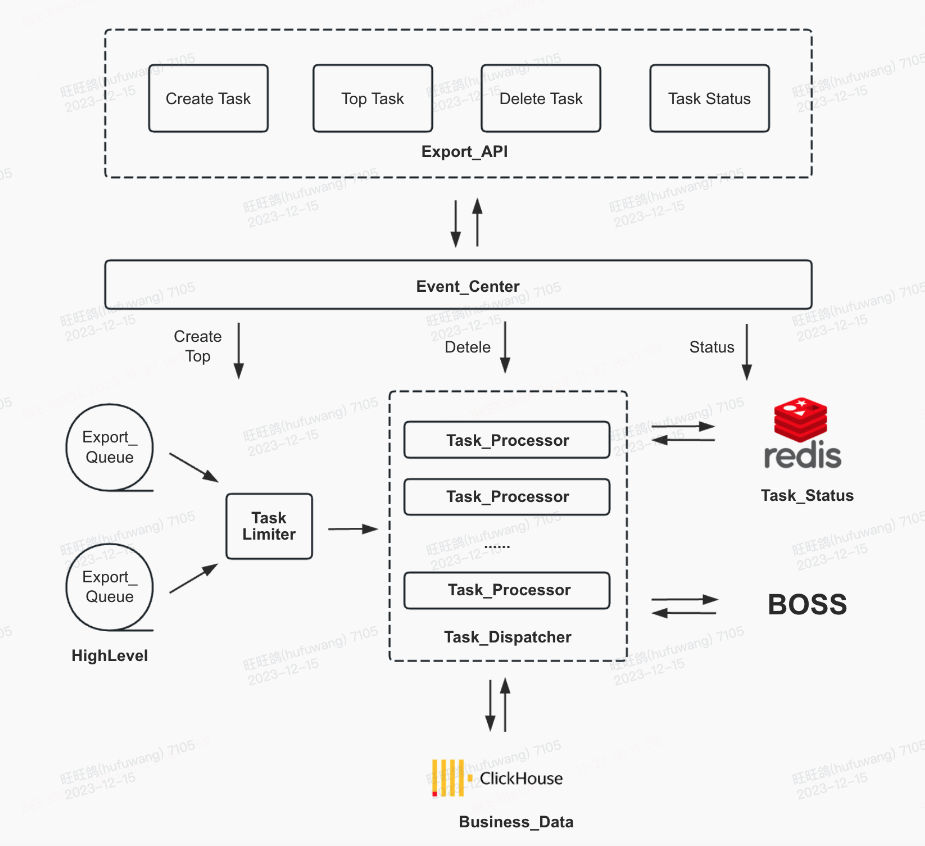
三、ClickHouse表设计与优化
如上文所述,我们运用ClickHouse支持直播公会场景的大数据量分析查询,同时需要ClickHouse支持数据更新写入(UPSERT)的功能。最初,我们采用ClickHouse的ReplacingMergeTree表引擎,借助其继承的MergeTree表引擎能力和去重特性,来支持数据的查询和更新。
针对直播公会场景的更新需求、数据查询模式、数据过滤方式以及数据量规模等场景特征,我们的ClickHouse表采用了以下技术设计:
-
设置去重键(record_date, uid)为主键索引和sharding key,设置mtime为版本,利用ReplacingMergeTree的合并机制和final修饰词,来完成实时更新。
-
按月分区(substring(record_date, 1, 6)),减少文件的数量,降低查询的IO寻址消耗。
-
使用复制表,增强数据可靠性。
-
使用冷热存储策略,冷热数据使用不同存储介质,提升热数据的读写性能。
ReplacingMergeTree引擎的建表语句示例:
CREATE TABLE bili_live.ads_guild(`id` Int64,`uid` Int64,`guild_id` Int64,`record_date` String,`mtime` DateTime,...)ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/{layer}-{shard}/bili_live/ads_guild', '{replica}', mtime)PARTITION BY substring(record_date, 1, 6)ORDER BY (record_date, uid)TTL ...SETTINGS index_granularity = 8192, storage_policy = 'hot_and_cold'
ReplacingMergeTree会使用primary key(默认为order by键)做排序,并根据指定的version字段(上面SQL中的mtime字段)做去重,每个key只保留最新的那条数据。
1.ReplacingMergeTree的问题
ReplacingMergeTree表引擎虽然支持了数据更新,但由于受限于其实现原理,ReplacingMergeTree存在以下问题:
-
基于Merge-On-Read机制实现数据更新,使用单线程做数据合并,效率低。
-
主键索引设置不够灵活,去重键必须和索引键保持一致,去重键不一定是业务常用的过滤字段,限制了主键索引的作用。
-
final修饰词导致无法使用跳数索引做数据过滤。
-
final修饰词导致无法使用prewhere的优化。
以上问题的存在使得ReplacingMergeTree表在查询时数据过滤效果不佳,并发度不够,最终导致查询性能受限,查询延迟不能很好地满足业务需求。
2.Unique Engine
为了解决ReplacingMergeTree的上述问题,我们新增了一款Unique Engine表引擎,主要思路是在写入过程中通过标记删除(Delete-On-Insert)完成更新操作。下面我们比较一下ReplacingMergeTree引擎和Unique Engine引擎的查询执行模式,看看为什么Unique Engine引擎在查询性能方面更优。
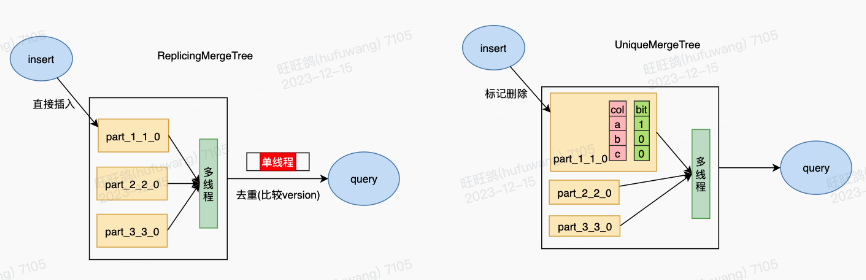
从上图可以看到,ReplacingMergeTree虽然也是多线程读取数据,但由于要实现相同key数据的去重(仅保留最新version的数据),最终需要在单线程中完成数据合并,这样就会影响查询性能,增加了查询延迟。而Unique Engine的数据读取和去重都是多线程并发完成的,不存在单线程合并的环节。
UniqueEngine引擎的建表语句示例:
CREATE TABLE bili_live.ads_guild(`id` Int64,`uid` Int64,`guild_id` Int64,`record_date` String,`mtime` DateTime,...INDEX id_idx id TYPE bloom_filter(0.025) GRANULARITY 1,INDEX uid_idx uid TYPE bloom_filter(0.025) GRANULARITY 1)ENGINE = ReplicatedUniqueMergeTree('/clickhouse/tables/{layer}-{shard}/bili_live/ads_guild', '{replica}', mtime)PARTITION BY substring(record_date, 1, 6)ORDER BY (record_date, guild_id)UNIQUE KEY (record_date, uid)TTL ...SETTINGS index_granularity = 8192, storage_policy = 'hot_and_cold', enable_unique_key_bucket = 1, unique_key_deduplicate_level = 1, unique_key_index_type = 1
从建表SQL可以看到,我们增加了一个unique key,数据会基于unique key做去重,每个key仅保留version(上面SQL中的mtime字段)最新的那条数据。
除了查询执行模式上的优势,Unique Engine同时解决了上文提到的ReplacingMergeTree的几个问题:
-
拆分去重键和主键索引:设置(record_date, guild_id)为主键索引,以便使用主键索引做过滤。
-
添加跳数索引:由于查询不再需要添加final修饰词,所以能够利用跳数索引跳过不需要扫描的数据。
-
prewhere优化:由于查询不再需要添加final修饰词,所以能够利用prewhere优化减少需要读取的数据量。
四、Unique Engine设计原理与实现
上一节我们阐述了如何通过引入Unique Engine引擎解决ReplacingMergeTree引擎的问题,下面我们将详细介绍Unique Engine的原理与实现。
针对分析型场景支持数据更新这一问题,行业内常见的设计思路有两种:Merge-On-Read和Delete-On-Insert。例如,HBase和ClickHouse的ReplacingMergeTree就是在查询过程中通过Merge-On-Read做数据更新;而StarRocks和ByConity则都是通过Delete-On-Insert在写入过程中做标记删除。
由于在我们大部分有更新需求的场景下,数据量都相对较小,对数据写入的延迟要求较低),而对数据查询延迟的要求比较高,所以经过详细评估后,我们采用了Delete-On-Insert的设计思路。
1.方案设计
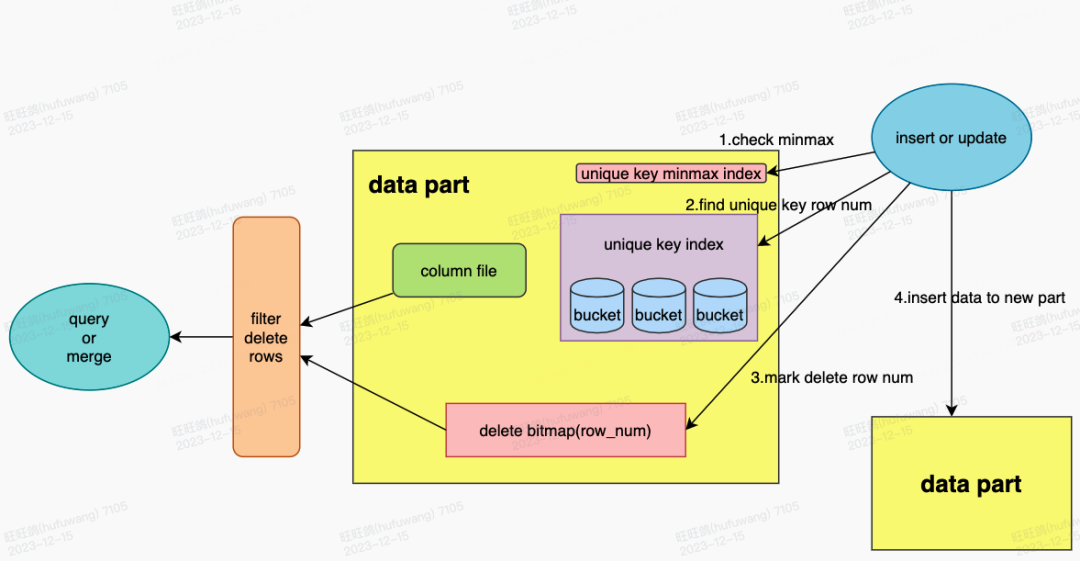
为了支持Delete-On-Insert机制,我们在ClickHouse data part内部新增了三种数据结构:
-
unique key minmax index:用于存储unique key的最大值和最小值,通过极值判断快速跳过不需要扫描的data part。
-
unique key index:用于存储所有unique key的唯一值,并进行了hash分桶,以加快其加载的速度。
-
delete bitmap:用于标记data part内部删除的数据,记录其对应的行号。
在写入过程中,扫描历史数据,并依次检查unique key minmax index和unique key index,如果发现历史数据的data part中有相同的unique key,且未被删除,则在delete bitmap中记录其行号,标记删除。在查询和合并的过程中,依赖delete bitmap过滤删除数据,避免了merge on read单线程做合并的问题。
对于unique key index,我们支持了map、unordered_map、StringHashMap三种类型,其中unordered_map占用内存相对较小,但在常驻内存的模式下,如果unique key的数量非常多的话,还是会占用很大的内存,影响业务的正常查询,所以我们场景中使用的是非常驻内存模式。
由于data part内部的行号是递增数值类型,所以非常适合使用bitmap类型来存储删除的行号,这样不仅占用空间小,检索速度还非常快。
2.写入合并冲突
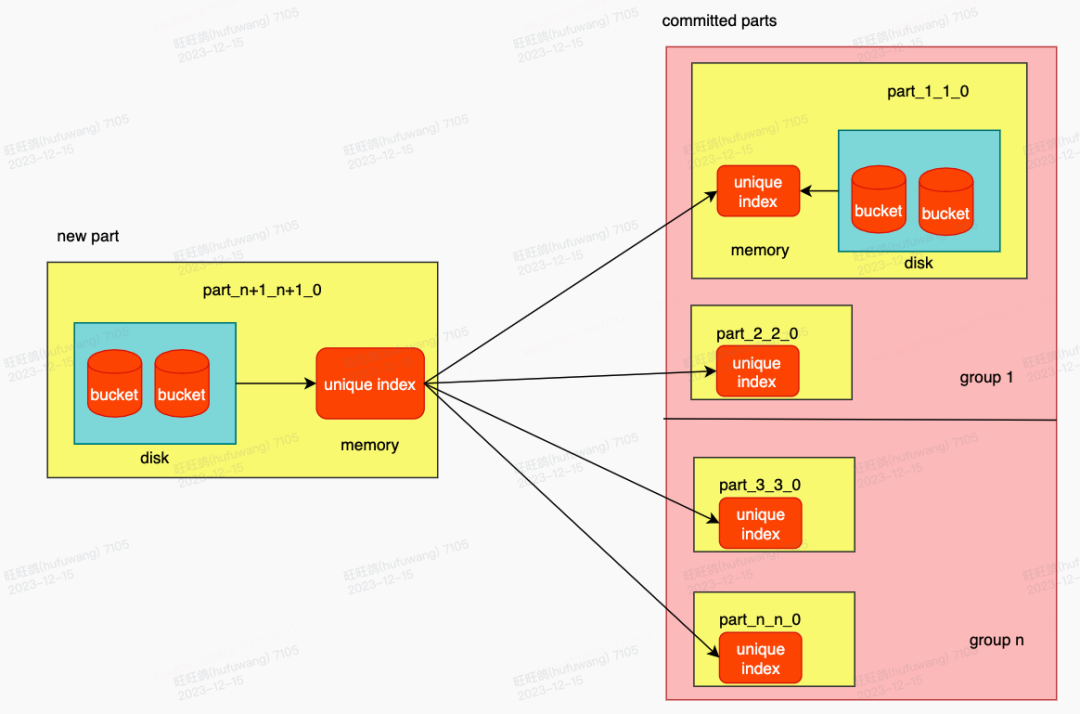
写入和合并是两条独立的链路,它们是很有可能同时发生的。在合并期间进行写入操作,如果合并未感知到写入的标记删除,就会引发冲突,造成数据重复的问题。
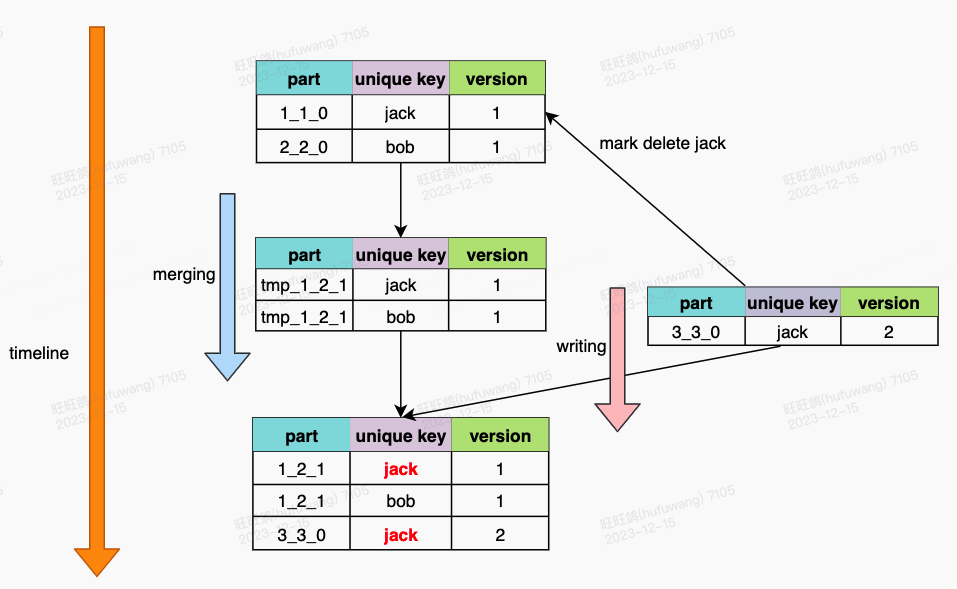
如图所示,在part_1_1_0和part_2_2_0合并的过程中,写入了part_3_3_0,虽然part_3_3_0已经标记了part_1_1_0中的unique key 'jack'需要删除,但由于merge任务在标记删除之前,已经完成了对part_1_1_0的读取,所以导致最后的结果中,出现了重复的数据。
为了解决这个冲突,我们采用了cas原子性变更part状态+commit lock的方案,以保证幂等性更新。在写入过程中,如果发现历史part正处于合并中,会对历史part做两份标记,一份是part级别,另一份是table级别,part级别是为了实时读取的准确性,table级别是为了最终的数据去重。
再回到刚才的问题,part_3_3_0在写入的过程中,发现part_1_1_0正在合并,则会对part_1_1_0做两份标记,part级别和table级别都会记录unique key 'jack'的删除信息。当part_1_1_0和part_2_2_0合并到临时文件后,在提交的时候,会发现table级别有关于part_1_1_0的标记信息,则会对unique key 'jack'做最后的删除,保证了数据去重。
3.去重加速
1)并行比较
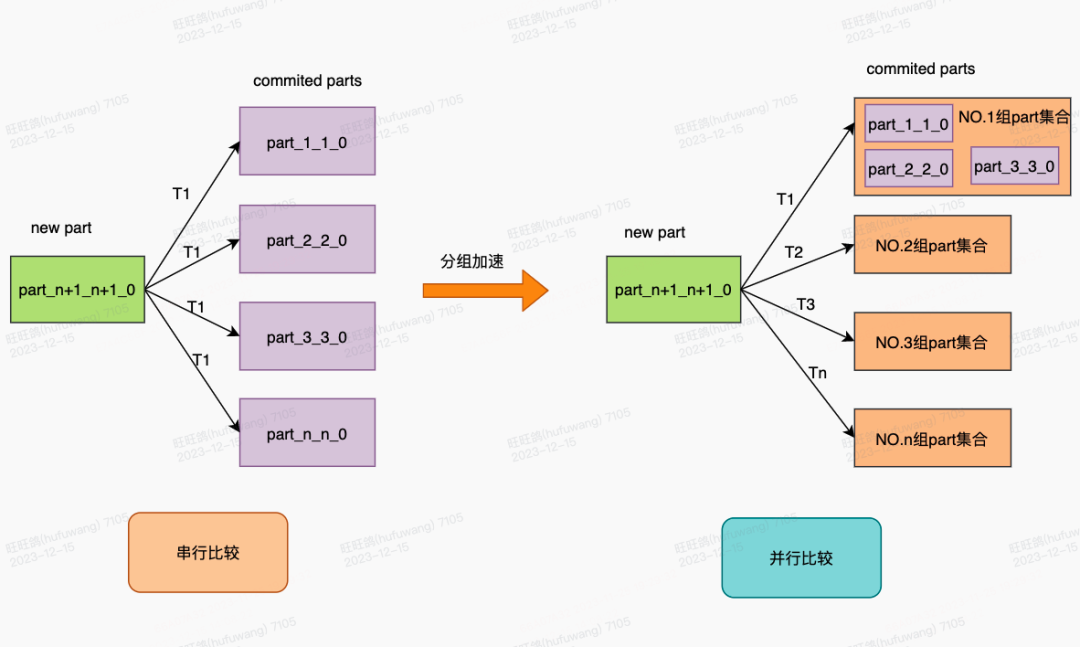
在写入过程中,新写入的data part需要与历史data part进行比较,以筛选出并标记需删除的数据。传统的串行比较方法效率低,影响了写入性能。为了提高写入效率,我们将历史数据部分进行分组,并采用多线程并行比较的方式,以此来提升数据写入的速度。
2)Hash分桶
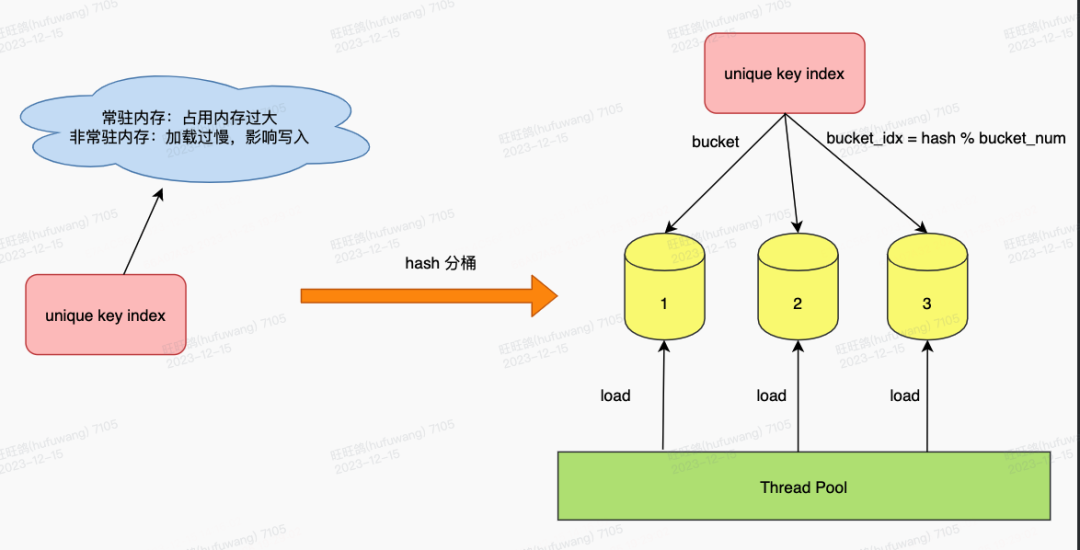
unique key index是行级索引,占用存储空间较大。如果unique key index常驻内存,则内存消耗过大,在我们的实际场景中不可行;而如果unique key index非常驻内存,则每次写入在做去重前都需要将unique key index加载进内存。为了减少每次写入需要加载的unique key index数据量,我们对Unique index进行了hash分桶,每次写入时仅加载可能与写入数据重复的分桶,从而提升整体写入性能。
综上所述,我们通过并行比较和unique key index分桶加载的方式实现unique key的去重,从而在内存占用和写入速度之间达到一个平衡,以保障幂等性写入。
4.复制表副本去重
为使用ClickHouse副本特性(比如备份数据,同时提供读写能力等),我们支持了Unique Engine的副本功能。Unique Engine会对历史的data part进行实时更新,所以副本之间是需要同步更新的信息,为降低对zookeeper的影响,目前采用的是副本二次去重,即拉取的data part会与历史的data part重新进行比较,以保证幂等性写入。同为shard的两个副本节点,为保证两个副本的数据一致性,只能由一个节点完成合并,另一个节点只能去拉取合并后的data part。
5.重复数据的过滤
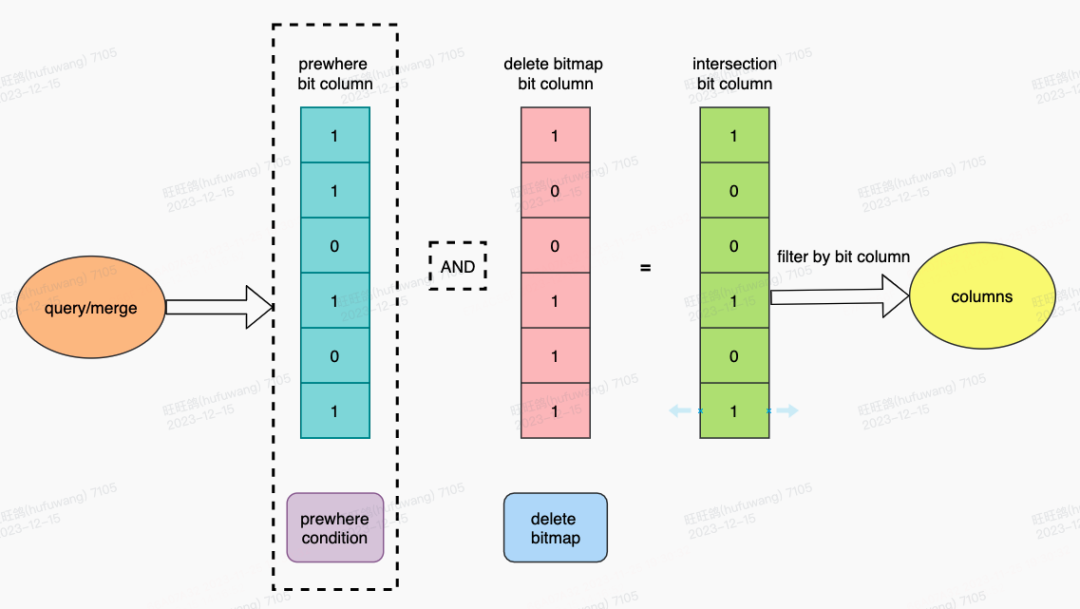
ClickHouse内部的过滤筛选是通过bit column实现的,1代表满足筛选条件,0代表不满足。ClickHouse的prewhere过滤结果就是通过bit column表示的。delete bitmap的作用是过滤掉已删除的数据,因此在进行数据过滤时,我们将delete bitmap转换成为bit column进行过滤。
对于存在prewhere的查询,我们将delete bitmap bit列与prewhere bit列进行交集操作,这样不仅能够过滤无效的数据,还可以结合prewhere的能力,提升整体的查询性能。对于不存在prewhere的查询和合并,则直接依赖于delete bitmap的bit column进行过滤,获取有效的数据集。
五、Unique Engine在直播公会场景的落地效果
1.查询性能对比
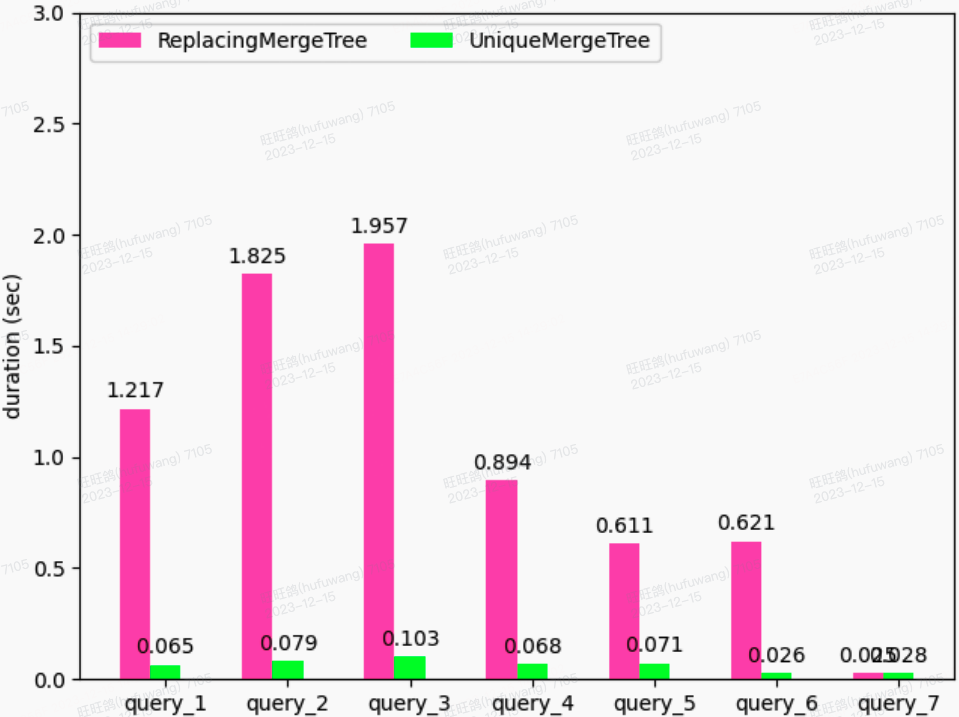
上图是七种业务查询在不同表引擎下的耗时对比图,如图所示,受益于Unique Engine的特性(灵活的主键索引、不受final限制的跳数索引等),查询性能均得到大幅提升,整体提升了大约10x~20x。

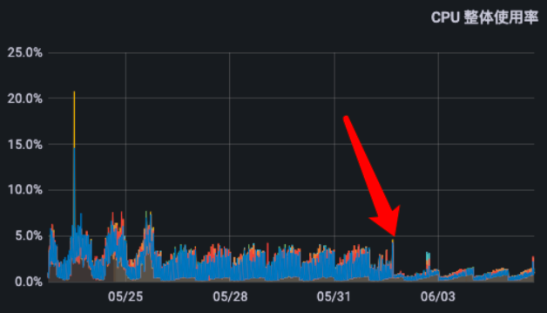
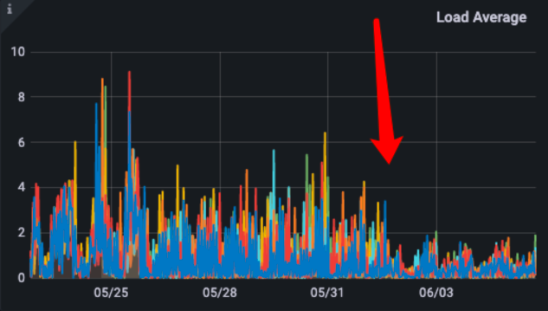
使用ReplacingMergeTree表引擎,部分查询延迟无法保证在亚秒内,而且日均扫描数据量达60TB+。
使用UniqueMergeTree表引擎,最大耗时可以保证在亚秒内,p90查询性能提升了5x,日均扫描数据量减少了6x,集群资源节省了50%。
2.写入性能对比

在写入方面,使用UniqueMergeTree表引擎后,相较于ReplacingMergeTree表引擎有10x的性能损耗,而且去重比较的历史数据量越大,去重性能越差。
针对MySQL2ClickHouse的数据写入场景,由于整体数据量相对较小,大多数都在千万级别以内。在我们的场景中,写入带来资源消耗比较小,平均写入延迟依然在亚秒级别。
六、Unique Engine写入性能优化方案
如上文所述,虽然我们做了各种优化(如并发比较,hash分桶),但Unique Engine相较ReplacingMergeTree仍然有10+倍的写入性能下降。因此,在Unique Engine落地直播公会场景后,我们对unique engine写入性能优化做了进一步的探索。通过做写入性能分析,我们发现性能瓶颈主要在两个地方:一个是unique key index的加载;另一个是unique key的比较。
unique key index的加载:就是将unique key index从磁盘反序列化到内存中。虽然使用了hash分桶,但在某些写入场景下,hash后的key比较离散,导致几乎每次都需要把data part中的所有unique key加载到内存中。
unique key的比较:就是比较新写入的data part和历史的data part的unique key。新写入的所有keys都需要和历史存在的所有keys比较。比如有4个历史data part,新写入的data part有10个unique key,那么意味着至少需要比较4 * 10 = 40次。当写入数据或历史数据较多时,key的比较次数巨大,从而影响整体写入性能。
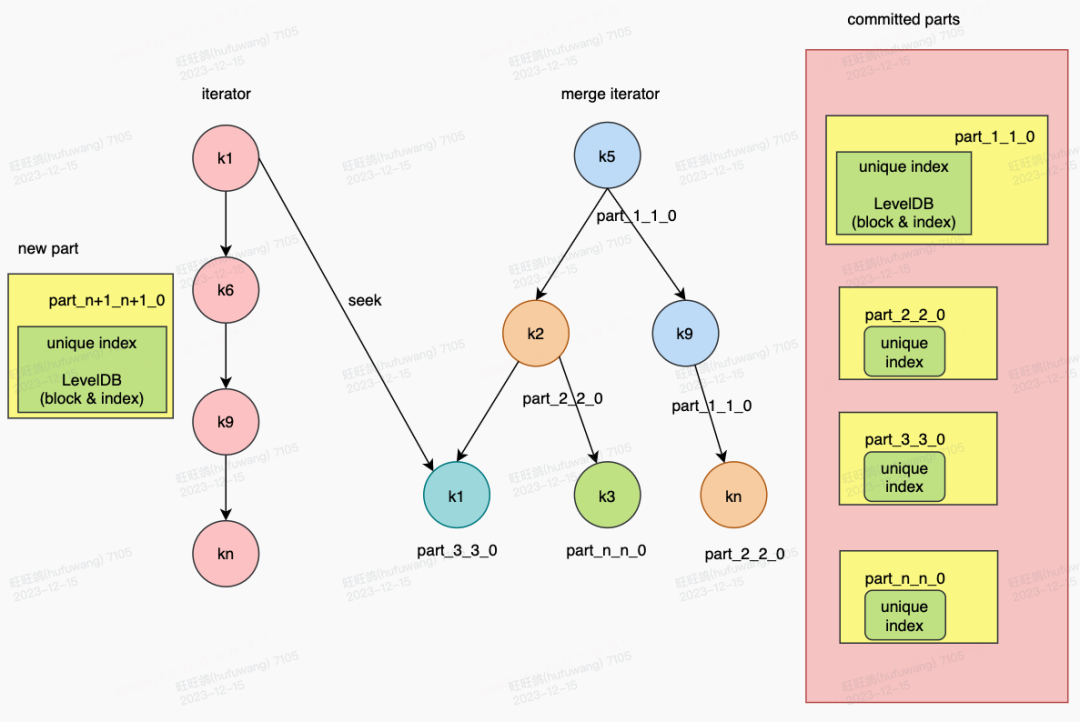
围绕上述写入性能瓶颈,我们对Unique Engine的写入做了进一步优化。主要思路是将unique key存储到LevelDB,在数据写入时,对新写入的数据做排序后构建有序key iterator,同时对LevelDB中的历史数据也构建有序key iterator,然后对两个有序key iterators做顺序比较,利用LevelDB索引跳过不需比较的数据。这样不仅可以借助LevelDB的特性(如有序性,索引、block)缩小unique key的加载范围,减少无效的加载,还可以减少unique key的比较次数,从而大幅提升写入性能。
我们实现了上述写入优化,经测试验证,上述优化可将写入延迟降低数倍,性能提升效果如下:

另外,优化前Unique Engine写入耗时与历史数据成正比,而优化后的版本由于利用LevelDB的索引跳过无需比较的数据,所以写入性能大体上是和新写入的数据量成正比的,所以在线上数据量较大的场景下,性能提升效果会更为明显。
七、下一步的工作
1.LevelDB Unique Key Index全覆盖
目前线上运行的大部分Unique Engine场景使用的还是Map类型的Unique Key Index,我们将推进LevelDB Unique Key Index的全覆盖,从而大幅提升ClickHouse更新场景的写入性能。
2.接入链路优化
目前MySQL到ClickHouse的写入链路较长,需要经过Canal,Kafka,Flink等组件才能最终写入到ClickHouse,不仅增加了数据链路的复杂性和运维成本,同时也使得用户的业务接入门槛较高,阻碍了业务场景的拓展。我们计划采用Flink CDC,配合上层接入服务支持,实现MySQL到ClickHouse数据同步链路的一站式构建配置,降低业务接入门槛,进而拓展更多业务场景。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK