

带你认识本地大模型框架Ollama(可直接上手)
source link: https://wiki.eryajf.net/pages/97047e/#%E6%9C%80%E5%90%8E
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

# 前言
自 OpenAI 公司于2022 年 11 月 30 日发布 ChatGPT 以来,经过 23 年一整年的发展之后,大模型的概念已逐渐普及,各种基于大模型的周边产品,以及集成层出不穷,可以说已经玩出花来了。
在这个过程中,也有不少本地化的模型应用方案冒了出来,针对一些企业知识库问答的场景中,模型本地化是第一优先考虑的问题,因此如何在本地把模型调教的更加智能,就是一个非常重要的技能了。
在 23 年的时候,我也接触过一些本地模型的开源项目(比如 LocalAI (opens new window)),当时在本地部署跑起来之后,发现交互的体验,回答的速度,以及智能程度,都远低于预期。
最近又一次了解本地模型的玩法,从微信群里了解到了 ollama (opens new window),经过几天业余时间的研究及了解,发现现在模型本地化的玩法,以及能力都早已不可同日而语,本文,将记录我这几天来对于 ollama 的粗浅认识以及快速入门玩起来。
# 什么是 ollama
先来记录一些 ollama 相关的快链:

一句话来说, Ollama 是一个基于 Go 语言开发的简单易用的本地大模型运行框架。可以将其类比为 docker(同基于 cobra (opens new window) 包实现命令行交互中的 list,pull,push,run 等命令),事实上它也的确制定了类 docker 的一种模型应用标准,在后边的内容中,你能更加真切体会到这一点。
在管理模型的同时,它还基于 Go 语言中的 Web 框架 gin (opens new window) 提供了一些 Api 接口,让你能够像跟 OpenAI 提供的接口那样进行交互。
虽然一开始官方开发的接口没有兼容 OpenAI 的接口交互标准,后来也有社区开发者提交此类兼容的 pr,比较优秀的 pr 可见:1331 (opens new window)。

在 issue 最后是该项目的发起者给到的回复,在社区 pr 没有被合并的情况下,其所表现出的礼貌与风度,令人钦佩,那么这个项目将会是什么样,也大概可据此管窥。
项目官方在 2376 (opens new window) 这次 pr 中集成了 OpenAI 接口的兼容,此次 pr 被合并在 v0.1.24 (opens new window) 中,因此,只要是在这之后的版本,你可以利用此前与 OpenAI 的集成任何包来与 Ollama 进行交互。
官方还为此专门发布了一篇官方博客: https://ollama.com/blog/openai-compatibility (opens new window),并配了如下一个可爱的图。

同时:官方还提供了类似 GitHub,DockerHub 一般的,可类比理解为 ModelHub,用于存放大模型的仓库(有 llama 2,mistral,qwen 等模型,同时你也可以自定义模型上传到仓库里来给别人使用)。目前我体验下来,通过官方地址拉取模型的速度都基本上可以跑满带宽,应该是官方目前比较大的一笔支出。
我想,以上应该就是 Ollama 这个项目几个比较核心的概念了。一些地方你看了介绍之后还不熟悉,没关系,接下来的内容会帮你认识并映照上边提到的这些内容。
# Ollama 怎么玩
# Mac 安装 ollama
要想玩起来,首先要把它安装起来,Ollama 支持多平台部署,你可以在官网,选择适合的平台,下载对应的安装包。
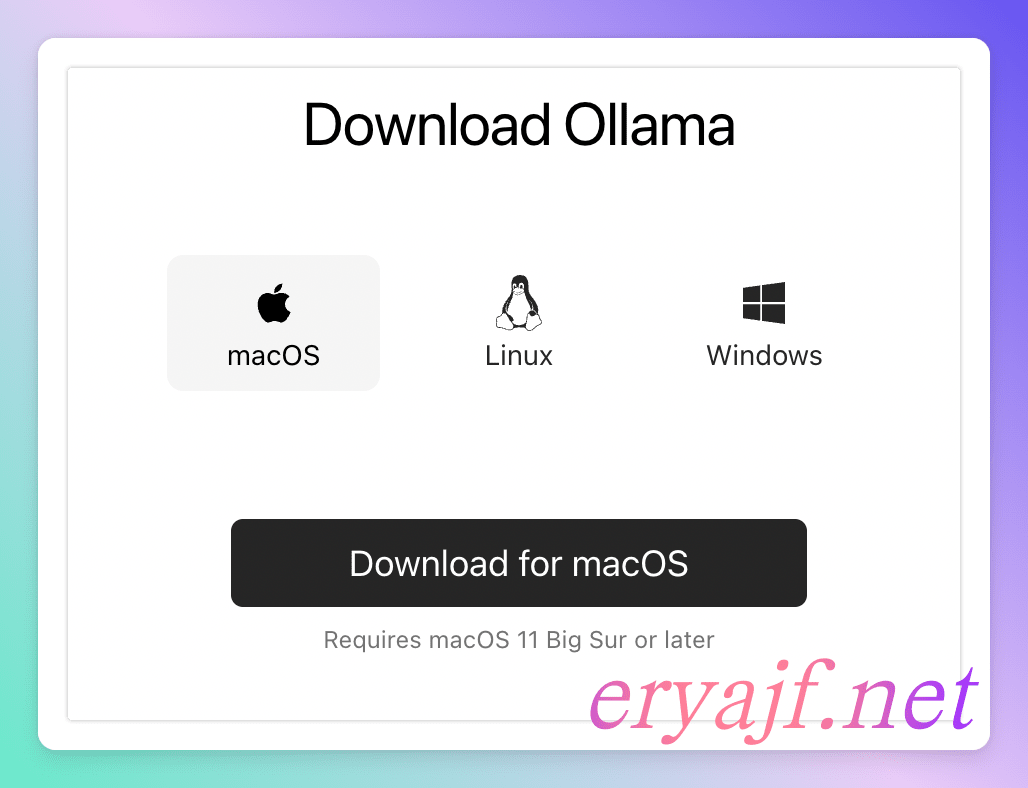
当然也可以选择在项目的 GitHub 的 Releases (opens new window) 页面进行下载。
同时,该项目还支持 docker 一键部署,可以说在部署方面,只需要有比较简单的运维基础就可以在你当下的平台中部署起来。
我这里个人使用的是 Mac M2(32G 内存版),直接下载安装包,安装即可,安装之后,运行软件。
运行之后,项目默认监听 11434 端口,在终端执行如下命令可验证是否正常运行:
$ curl localhost:11434
Ollama is running
此时只是相当于把一个架子,一个舞台搭好了,想要在本地玩转模型,还需要接下来的主角,模型登场。
# 模型管理
ollama 安装之后,其同时还是一个命令,与模型交互就是通过命令来进行的。
ollama list:显示模型列表。ollama show:显示模型的信息ollama pull:拉取模型ollama push:推送模型ollama cp:拷贝一个模型ollama rm:删除一个模型ollama run:运行一个模型
前边提到过,官方提供了一个模型仓库,https://ollama.com/library (opens new window),在这里你可以找到你想要运行的模型。
官方建议:应该至少有 8 GB 可用 RAM 来运行 7 B 型号,16 GB 来运行 13 B 型号,32 GB 来运行 33 B 型号。
在这里我选择下载阿里开源的 Qwen1.5 (opens new window) 模型来做演示。模型地址为:qwen (opens new window),因我的电脑有 32G,所以选择了 14b 的模型来调试。
$ ollama run qwen:14b
如果本地没有该模型,则会先下载模型再运行。首次运行启动可能略慢,考验电脑性能的时刻到了。
自己调试制定模型,官方也提供了一种类似 Dockerfile 的 Modelfile,这里用一个简单的例子来讲解一下用法。
FROM qwen:14b
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# set the system message
SYSTEM """
请你每句话都以“真是我的小可爱,”开头
"""
2
3
4
5
6
7
8
9
然后执行如下命令制作模型并运行:
$ ollama create qwen:eryajf -f Modelfile
$ ollama run qwen:eryajf

更多模型调试的参数及用法请看官方文档: https://github.com/ollama/ollama/blob/main/docs/modelfile.md (opens new window)
# 简单交互
模型运行之后,会默认进入到交互状态,你可以按下 Ctrl + D 退出交互,但此时模型并不会退出,仍旧可以正常通过 Api 接口交互。
终端交互示例:

接口请求参考官方文档的介绍 api (opens new window),下边是简单的示例:

接口请求支持 stream 模式,上边这个请求响应 10s 左右,如果使用 stream 模式,体验会提升不少。
# 两个 web 客户端
围绕 ollama 生态,也有一大批优秀的开源项目,这里介绍两个在本地可直接与模型进行交互的项目。
项目一:ollama-webui-lite (opens new window)
项目自述中,他说是 open-webui 的简化版,而复杂版也许的确复杂,我始终没能够部署起来,因此推荐使用这个简化的。
注意需要 node >= 16。
$ git clone https://github.com/ollama-webui/ollama-webui-lite.git
$ cd ollama-webui-lite
$ yarn
$ yarn dev
运行之后,你可以点击设置,对连接信息进行设置,默认是连接本机的 http://localhost:11434/api,如果你跟我一样在本机部署,那就不用更改。然后就是选择已经 run 过了的模型,接着就可以进行对话了。
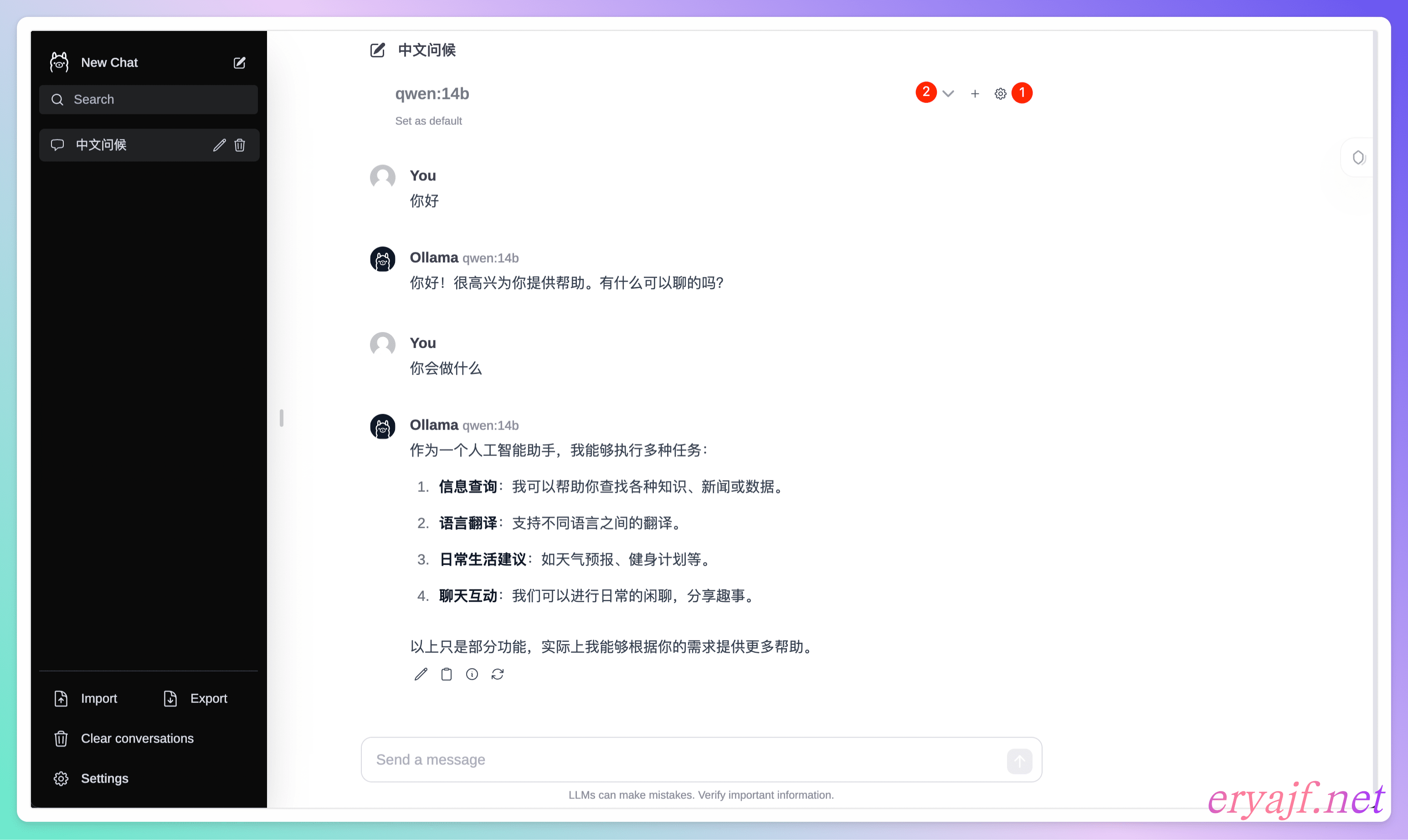
项目二:ChatGPT-Next-Web (opens new window)
这个项目支持桌面端,可直接下载 Mac 版本,然后在本地进行交互。
下载安装之后,点击设置,进行如下几项设置,此处正说明当下 ollama 已兼容 OpenAI 的接口标准。
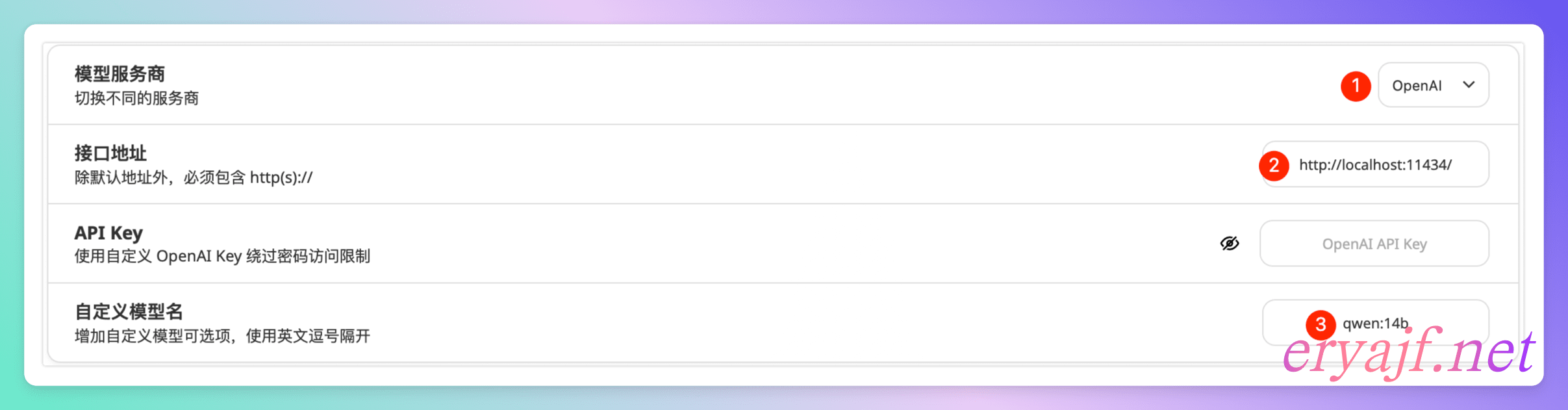
保存之后,交互请求的时候发现有报错,这个是因为默认启动之后,有一些请求跨域的问题。
{
"error": true,
"message": "Load failed"
}
详见此问题相关的 issue:4119 (opens new window)
把 ollama 退出,然后重新使用如下命令运行:
$ export OLLAMA_ORIGINS="*";export OLLAMA_HOST="0.0.0.0";ollama serve
然后运行模型:
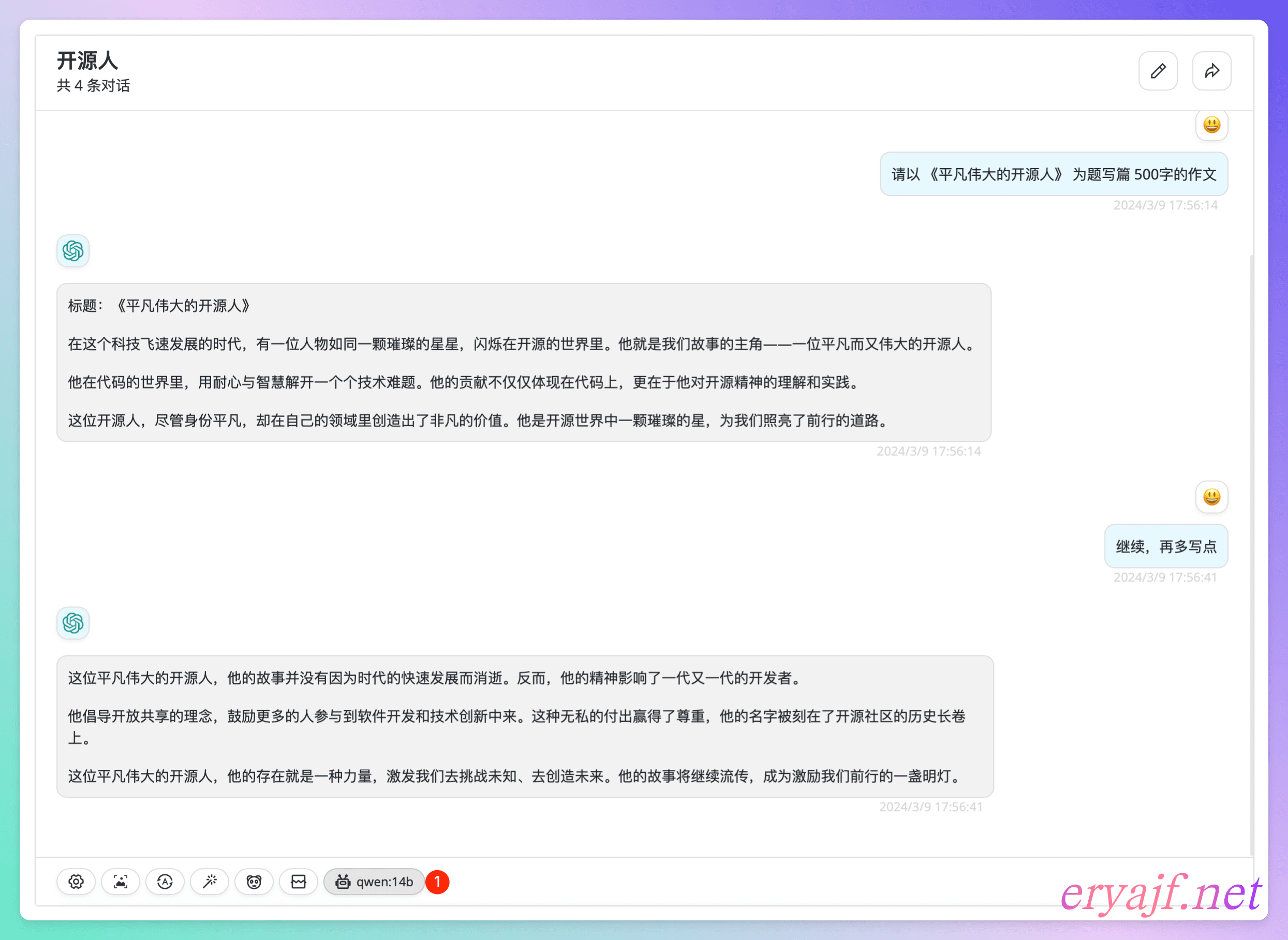
$ ollama run qwen:14b
之后再次交互,发现就能正常进行了:
以上,粗浅地介绍了 ollama 的入门玩法,希望通过如上内容,你可以快速了解这个优秀的项目,从而开启属于你的大模型折腾之路。
# 补充:Linux 部署方式两种
# 通过 systemd 方式部署。
事实上基于 systemd 的部署官方文档介绍的也非常仔细,这里就快速记录一下,主要有一些注意点,踩过一些坑,在这里一并记录一下。
安装步骤参考: https://github.com/ollama/ollama/blob/main/docs/linux.md (opens new window)
这里着重介绍一下,配置 system 启动配置的时候,应该注意的一些点:
$ cat /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
Environment="OLLAMA_MODELS=/data/ollama/.ollama/models"
ExecStart=/usr/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
我这里把用户改成了 root,以免出现权限问题。
另外增加了三个环境变量的声明:
OLLAMA_HOST:指定监听地址,默认为127.0.0.1。OLLAMA_ORIGINS:指定允许跨域请求的源,这里因为都在内网,因此设置为*。OLLAMA_MODELS:声明模型存放的路径,默认模型存放于~/.ollama/models,一般用户家目录的磁盘分区不会很大,而模型文件通常都比较大,因此不适合放在用户家目录中。
# 通过 docker 部署

官方介绍了 docker 的运行方式,我这里做了一些调整,可直接通过 docker-compose 拉起:
version: '3'
services:
ollama:
container_name: ollama
image: ollama/ollama:latest
restart: always
ports:
- "11434:11434"
volumes:
- /data/ollama:/root/.ollama
environment:
OLLAMA_ORIGINS: "*"
OLLAMA_HOST: "0.0.0.0"
2
3
4
5
6
7
8
9
10
11
12
13
docker 拉起之后,你可以 exec 到容器里边,然后执行与模型的交互。
# 最后
以上是我个人最近几天在 ollama 领域的一些心得体会,分享给大家。
️接下来还有很多值得琢磨的方向可以走,这里也先简单记录一下自己所了解知道的,以备后续继续研究发力。
最后,愿你在本地大模型中摸索出自己的一片天地。如果你在部署配置过程中遇到问题,或者有新的好玩的思路,欢迎在评论区一块儿交流。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK