

CS144:一个轻量级 TCP 重组器的实现与分析
source link: https://pandaychen.github.io/2024/02/10/A-CS144-COURSE-STUDY/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

0x00 前言
CS144 课程提供了一个用户态 TCP 协议的简单实践,先回顾下 TCP 的若干特点,为了最大限度的保证传输可靠:
1、可靠性保证
- 校验和,TCP 每个报文都有校验和字段,防止数据丢失或出错
- 序列化和确认号,保证每个序号的字节都交付,解决丢失、重复等问题
- 超时重传,对于超时未能确认的报文,TCP 会重传这些包,确保数据达到对端
- 拥塞控制等等
2、全双工
TCP 协议通信的双方既可以发送数据,又可以接受数据,双方拥有独立的序号、窗口等信息。一个 TCP 连接既可以是 sender 也可以是 receiver,同时连接拥有两个字节流,一个输出流,被 sender 控制,另一个是输入流,由 receiver 管理
3、字节流
TCP 数据传输是基于流的,意味着 TCP 传输数据是没有边界和大小限制的,可以传输无限量的字节。但是 TCP 报文大小是有限制的,这主要取决于滑动窗口大小、路径最大传输单元 MTU 等因素。TCP 数据写、读、传入都是基于字节流,因此常常会有字节流乱序发生,因此 TCP 需要重组
sponge 协议
CS144 给出了一个简化 TCP 版本(sponge),它的特点如下
- Sponge 协议建立在 UDP/IP(基于 TUN/TAP 技术) 之上
- Sponge 协议是一种简易版 TCP 协议,和 TCP 协议一样有滑动窗口、重传、校验和等功能,但是一些复杂的特性(如:紧急指针、拥塞控制、Options)暂不支持
cs144-Lab
LAB0-LAB4 是循序渐进的,最终实现如下架构图的 sponge 协议流
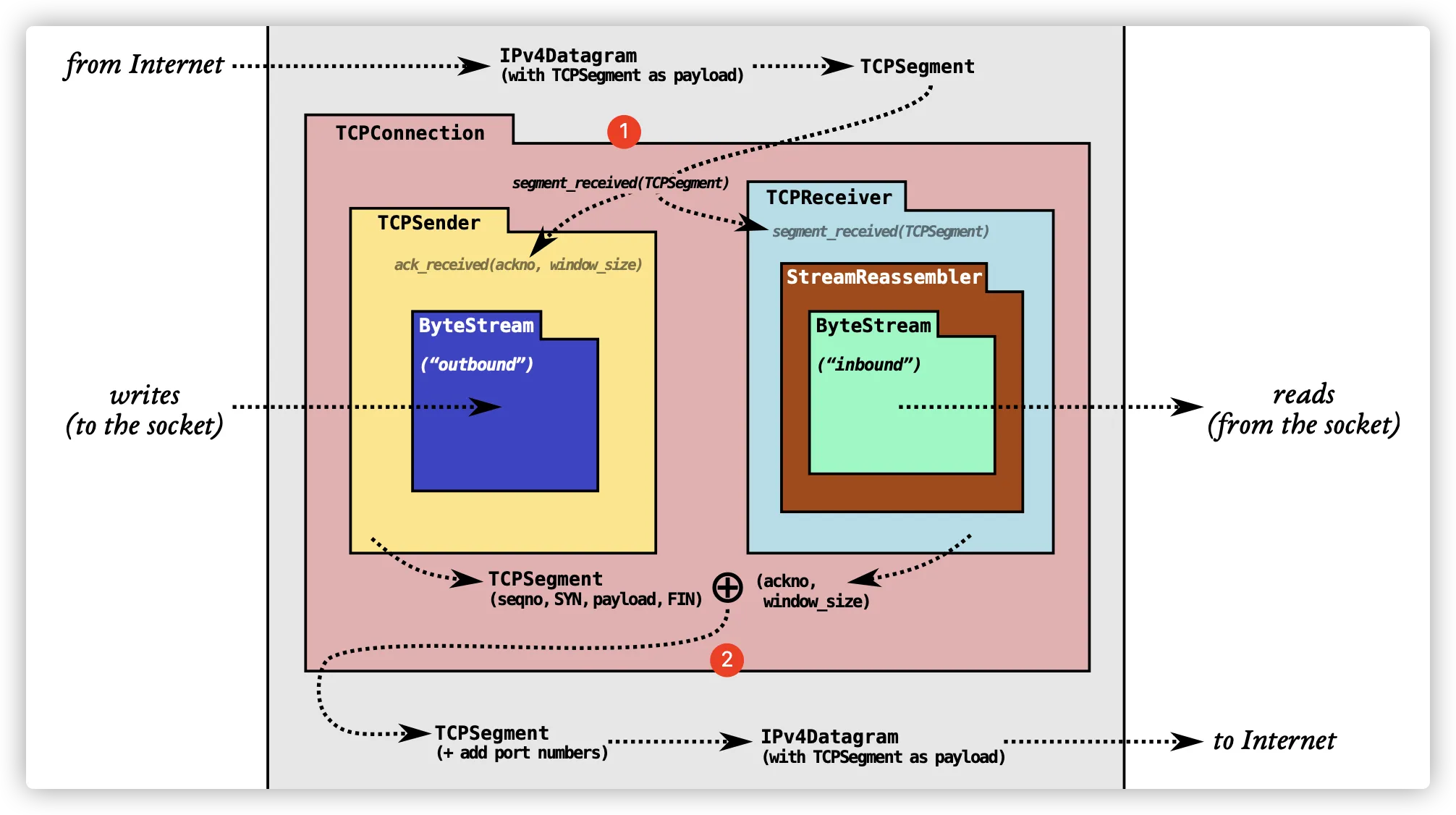
上图中梳理下 Sponge 协议数据流过程(假设走 TUN-UDP 隧道方式通信):
- 内核态下 UDP 数据包中的 payload 被解析为 TCPSegment 后,交给用户态下的
TCPConnection(调用segment_received方法) TCPConnection收到报文后,将报文交给TCPReceiver,即调用TCPReceiver.segment_received方法,并将报文中的ackno与window_size交给TCPSender(调用ack_received方法),这里是回复 ACK 报文TCPReceiver处理 TCP 报文,并将报文中的 payload 推入StreamReassembler中,并重组后交给应用程序,随后尝试发送 response 报文TCPConnection调用TCPSender.fill_window方法尝试得到待发送报文(可能得不到,视具体情况而定),若有报文,则设置报文 payload 以及其它字段,如SYN/ackno(从receiver获取)/window_size等,设置完毕后包装为 TCP 报文,将报文交给 UDP- UDP 将其打包为数据报,并发送给另外一端
0x02 核定代码分析
libsponge/
├── byte_stream.cc // ByteStream(数据流) 实现文件
├── byte_stream.hh // ByteStream 头文件
├── stream_reassembler.cc // StreamReassembler(数据流重组器) 实现文件
├── stream_reassembler.hh // StreamReassembler 头文件
├── tcp_connection.cc // TCPConnection(TCP 连接) 实现文件
├── tcp_connection.hh // TCPConnection 头文件
├── tcp_receiver.cc // TCPReceiver(TCP 接收者) 实现文件
├── tcp_receiver.hh // TCPReceiver 头文件
├── tcp_sender.cc // TCPSender(TCP 发送者) 实现文件
├── tcp_sender.hh // TCPSender 头文件
├── wrapping_integers.cc // WrappingIntegers(包装 32 位 seqno、ackno) 实现文件
└── wrapping_integers.hh // WrappingIntegers 头文件
sponge-TCP 框架类图如下:
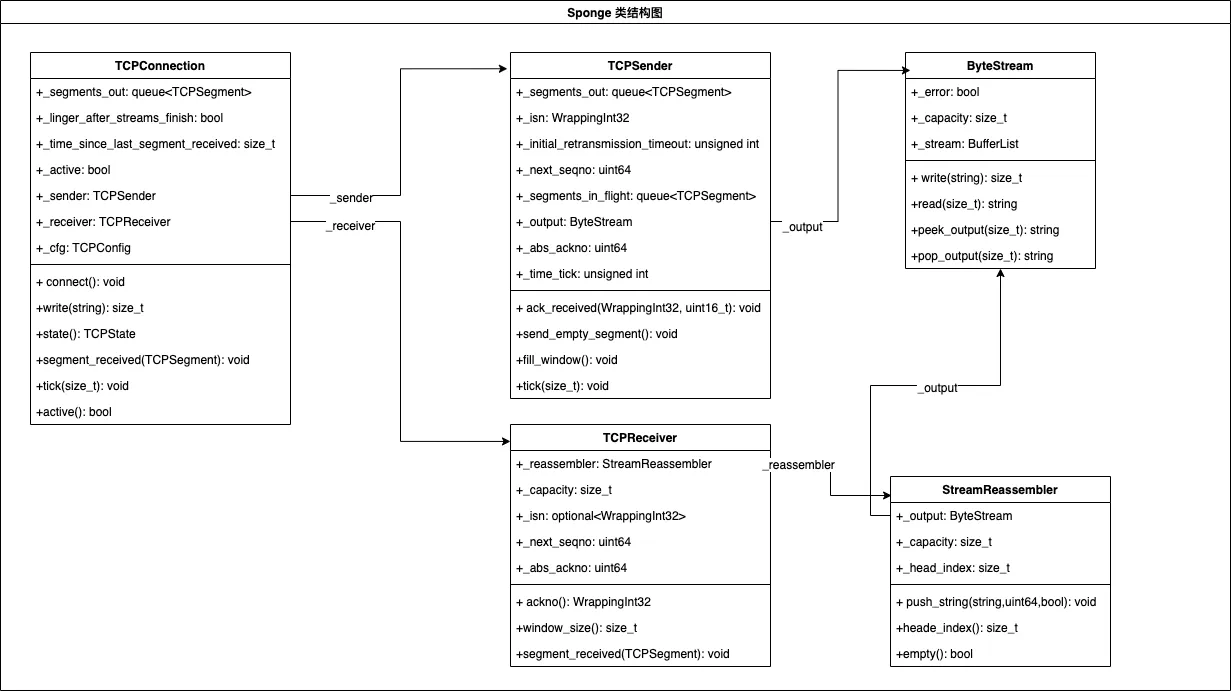
主体类为 TCPConnection,该类主要维护 TCP 连接、TCP 状态机等信息数据,并将接收到的报文交给 TCPReceiver 处理,从 TCPSender 获取报文并发送:
TCPConnection负责维护连接,报文发送、接收分别由TCPSender和TCPReceiver来负责TCPSender负责发送报文,接收确认号(ackno)确认报文,记录发送但未确认的报文,对超时未确认的报文进行重发TCPReceiver负责接收报文,对报文数据进行重组(报文可能乱序 / 重传等,由StreamReassembler负责重组)StreamReassembler负责对报文数据进行重组,每个报文中的每个字节都有唯一的序号,将字节按照序号进行重组得到正确的字节流,并将字节流写入到ByteStream中ByteStream是 Sponge 协议中的字节流类,一个TCPConnection拥有两个字节流,一个输出流,一个输入流。** 输出流 ** 为TCPSender中的_output字段,该流负责接收程序写入的数据,并将其包装成报文并发送,** 输入流 ** 为StreamReassembler中的_output字段,该流由StreamReassembler重组报文数据而来,并将流数据交付给应用程序
0x03 LAB0:有序字节流 ByteSteam
实现一个读写字节流 ByteSteam,用来作为存放给用户调用获取数据的有限长度缓冲区 buffer,这里采用 std::deque<char> 实现,一端读另一端写入,ByteSteam 的位置如下图:
class ByteStream {
private:
// Your code here -- add private members as necessary.
// Hint: This doesn't need to be a sophisticated data structure at
// all, but if any of your tests are taking longer than a second,
// that's a sign that you probably want to keep exploring
// different approaches.
std::deque<char> buffer;
size_t capacity;
bool end_write; // 用来标识本 stream 写入结束
bool end_read; // 用来标识本 stream 读取结束
size_t written_bytes;
size_t read_bytes; // 累计读取字节数
bool _error{}; //!< Flag indicating that the stream suffered an error.
};
需要实现如下方法:
std::string ByteStream::read(const size_t len)
size_t write(const std::string &data);
bool eof() const;
write:向字节流中写入数据,注意写入数据的大小和当前缓冲区的大小加起来不能超过容量大小,然后将数据加入到bufferdeque 中,并且更新buffer_size及bytes_writtenread:读取字节流中的前len个字节,注意read会消费流数据,读取后会移除前len个字节peek_output:查看字节流的前len个字节,peek_out方法不会消费字节流,只会查看前len个字节,并且查询字节数量不能超过当前缓冲区字节的数量pop_out:移除字节流中的前len个字节,然后更新bytes_read和buffer_sizebuffer_size:获取当前buffer的实际数据大小
核心实现如下:
size_t ByteStream::buffer_size() const { return buffer.size(); }
void ByteStream::end_input() { end_write = true;}
bool ByteStream::eof() const { return buffer.empty() && end_write; }
size_t ByteStream::write(const string &data) {
// 缓冲区的剩余字节
size_t canWrite = capacity - buffer.size();
// 取实际可写大小
size_t realWrite = min(canWrite, data.length());
for (size_t i = 0; i < realWrite; i++) {
buffer.push_back(data[i]);
}
written_bytes += realWrite;
return realWrite;
}
std::string ByteStream::read(const size_t len) {
string out = "";
// 过长,非法
if (len> buffer.size()) {
set_error();
return out;
}
for (size_t i = 0; i < len; i++) {
out += buffer.front();
buffer.pop_front();
}
read_bytes += len;
return out;
}
//param[in] len bytes will be copied from the output side of the buffer
string ByteStream::peek_output(const size_t len) const {
size_t canPeek = min(len, buffer.size());
string out = "";
for (size_t i = 0; i < canPeek; i++) {
out += buffer[i];
}
return out;
}
//param[in] len bytes will be removed from the output side of the buffer
void ByteStream::pop_output(const size_t len) {
if (len> buffer.size()) {
set_error();
return;
}
for (size_t i = 0; i < len; i++) {
buffer.pop_front();
}
read_bytes += len;
}
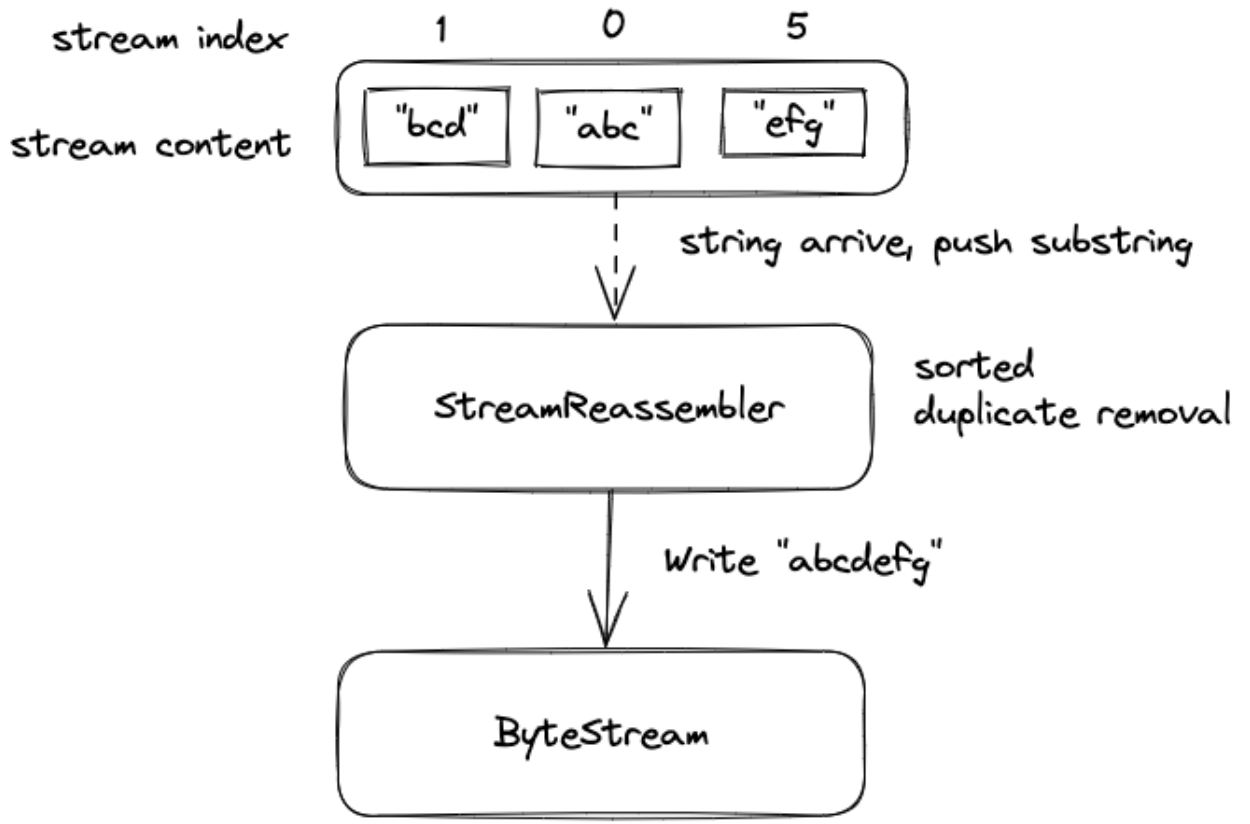
0x04 LAB1:重组器 StreamReassembler
StreamReassembler 实现,作为 ByteSteam 的上游,实现 sponge-TCP 协议流重组的功能,本 LAB 仍然不涉及到 TCP 的相关属性,是一个通用实现;StreamReassembler 的核心接口就是 push_substring,其参数如下:
data:报文应用数据(不含 TCP header)index:报文数据第一个字节的序号(注意这个是字节流的序号,跟seqno有区别)eof:是否收到了fin包数据,即是否要关闭输入数据流
在 StreamReassembler 类中,定义 buffer 为临时缓冲队列,使用 bitmap 来标识每个位置(char)的占用情况(当前也有更优雅的实现方式)
class StreamReassembler {
private:
// Your code here -- add private members as necessary.
size_t unass_base; //!< The index of the first unassembled byte
size_t unass_size; //!< The number of bytes in the substrings stored but not yet reassembled
bool _eof; //!< The last byte has arrived
std::deque<char> buffer; //!< The unassembled strings
std::deque<bool> bitmap; //!< buffer bitmap
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
void check_contiguous();
size_t real_size(const std::string &data, const size_t index);
// ....
}
上述成员的初始化值如下:
StreamReassembler::StreamReassembler(const size_t capacity)
: unass_base(0)
, unass_size(0)
, _eof(0)
, buffer(capacity, '\0')
, bitmap(capacity, false)
, _output(capacity)
, _capacity(capacity) {}
由于从 sponge-tcp 获取到的字节流可能为乱序报文,所以 StreamReassembler 主要完成这几件事情:
- 接收乱序字节流,按照重组序列规则缓存到
buffer,丢弃非预期的字节流,尝试检查缓存buffer中的字节流是否能与当前流进行合并 - 定期将已重组完成的数据写入到 LAB0 中的
ByteStream(调用ByteStream的write接口) - 判断流重组完整,设置
eof
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
if (eof) {
_eof = true;
}
size_t len = data.length();
if (len == 0 && _eof && unass_size == 0) {
_output.end_input();
return;
}
// ignore invalid index
if (index>= unass_base + _capacity) return;
if (index>= unass_base) {
int offset = index - unass_base;
size_t real_len = min(len, _capacity - _output.buffer_size() - offset);
if (real_len < len) {
// 注意:此说明 buffer 的剩余空间装不下当前的 data,需要标记流状态结束标记为 false
_eof = false;
}
for (size_t i = 0; i < real_len; i++) {
if (bitmap[i + offset])
continue;
buffer[i + offset] = data[i];
bitmap[i + offset] = true;
unass_size++;
}
} else if (index + len> unass_base) {
int offset = unass_base - index;
size_t real_len = min(len - offset, _capacity - _output.buffer_size());
if (real_len < len - offset) {
// 注意:此说明 buffer 的剩余空间装不下当前的 data,需要标记流状态结束标记为 false
_eof = false;
}
for (size_t i = 0; i < real_len; i++) {
if (bitmap[i])
continue;
buffer[i] = data[i + offset];
bitmap[i] = true;
unass_size++;
}
}
// 尝试检查把已经重组完成的流写入 ByteStream
check_contiguous();
if (_eof && unass_size == 0) {
_output.end_input();
}
}
StreamReassembler.capacity 的意义
这里再回顾下 StreamReassembler._capacity 的含义:
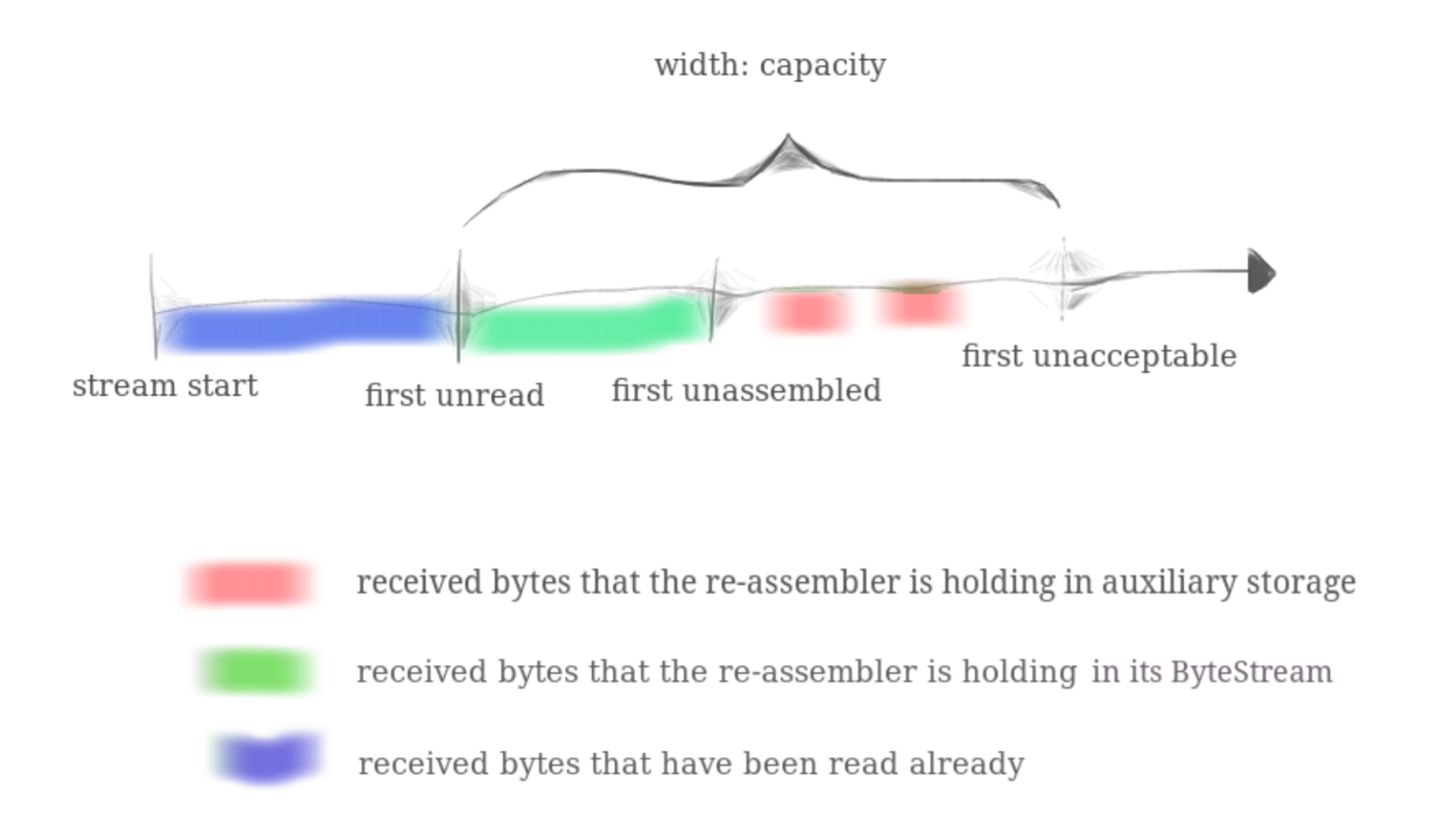
ByteStream的空间上限是capacityStreamReassembler用于暂存未重组字符串片段的缓冲区空间StreamReassembler.buffer上限也是capacity- 蓝色部分代表了已经被上层应用读取的已重组数据
- 绿色部分代表了
ByteStream中已经重组并写入但还未被读取的字节流所占据的空间大小 - 红色部分代表了
StreamReassembler中已经缓存但未经重组的若干字符串片段所占据的空间大小 - 同时绿色和红色两部分加起来的空间总占用大小不会超过
capacity(事实上会一直小于它)
从代码层面来看:
- first unread 的索引等于
ByteStream的bytes_read()函数的返回值 - first unassembled 的索引等于
ByteStream的bytes_write()函数的返回值 - first unacceptable 的索引等于
ByteStream的bytes_read()加上capacity的和(已超过ByteStream的 buffer 限制) - first unread 和 first unacceptable 这两个边界是动态变化的,每次重组结束都需要更新
0x05 LAB2:TCP 接收器 TCPReceiver
原实验稿在 此,lab0 实现了读 / 写字节流 ByteStream,lab1 实现了可靠有序不重复的字节流重组 StreamReassembler,本 LAB 开始就涉及到 TCP 协议属性了,即 TCPReceiver 的实现,TCPReceiver 包含了一个 StreamReassembler 实现,它主要解决如下问题:
可靠的接收数据
- 从哪里接收 TCP 分段数据
- 重组数据(调用
StreamReassembler),缓存数据 - 重组后的数据放在哪里(写入
ByteSteam),等待上层读取
与 TCPSender 交互
- 第一个未被 assembly(first unassembled)字节的索引 index,称为确认号(
ackno),告知对端当前本端已经成功接收了多少字节 - 提供 window size:第一个未被 assembly 字节的索引和 “第一个不可接收”(first unacceptable) 索引之间的距离(the distance between the “first unassembled” index and the “first unacceptable” index)
新版课程把上述 window size 重新描述为 “the available capacity in the output ByteStream”。ackno 和窗口大小一起描述了接收方的窗口:允许 TCPSender 发送的一系列索引。使用该窗口,接收方可以控制传入数据的流量,使发送方限制其发送量,直到接收方准备好接收更多数据。有时将 ackno 称为窗口的左边缘(TCPReceiver 感兴趣的最小索引),将 ackno + 窗口大小称为右边缘(刚好超出 TCPReceiver 所感兴趣的最大索引)
seqno/absolute sequence number/stream index
正常情况下在 sponge 协议中,TCPReceiver 会收到 3 种报文:
- SYN 报文,有初始
ISN(用来标记字节流的起始位置) - FIN 报文,表明通信结束
- 普通的数据报文,只需要写入 payload 到
ByteStream即可
TCP 流的逻辑开始数据包和逻辑结束数据包各占用一个 seqno。除了确保接收到所有字节的数据以外,TCP 还需要确保接收到流的开头和结尾。在 TCP 中,SYN(流开始)和 FIN(流结束)控制标志将会被分别分配一个序列号,流中的每个数据字节也占用一个序列号。但需要注意的是,SYN 和 FIN 不是流本身的一部分,也不是传输的字节数据。它们只是代表字节流本身的开始和结束
为了实现 TCP 流重组,sponge 协议提供了三种 index:
1、序列号 seqno:从 ISN 起步,包含 SYN 和 FIN,32 位循环计数
TCP 报文头部的 seqno 标识了 payload 字节流在完整字节流中的起始位置,然而该字段只有 32 位,最多只能支持 4gb 的字节流,这显然不够的,因此引入 absolute sequence number 定义为 uin64_t,最高可以支持 2^64 - 1 长度的字节流
2、绝对序列号 absolute seqno:从 0 起步,包含 SYN/FIN,64 位非循环计数
absolute seqno 的起始位置(针对单个 stream)永远是 0,它对于 seqno 会有 ISN 长度的偏移,每次写入时都不断对其递增,由于 seqno 可能会溢出,abs_seqno 保证了正常记录正确的长度;此外,在 sponge 协议中需要有 seqno 和 absolute seqno 转换
3、流索引 stream index:从 0 起步,排除 SYN/FIN,64 位非循环计数
stream index 本质上是 ByteStream 的字节流索引,只是少了 FIN 和 SYN 各自在字节流中的 1 个字节占用,也是 uint64_t 类型
这里,以数据流 cat 为例,上述 index 的对比图如下:

注意,在程序中计算的概念均使用 uint64_t 的偏移,如 absolute seqno,seqno 的 32 位类型是由于 TCP 协议的设计遗留问题导致的
seqno 和 absolute seqno 的转换
对于 TCPReceiver 而言,数据包中的 seqno 不是真正的字节流起始位置,因此接收报文时(拿到的是 seqno),需要对其转换成 absolute seqno,才可以进行后续操作,如流重组、 TCPReceiver 中计算窗口大小;由于 seqno 类型与其他不同,所以这里需要有一个相互转换算法,描述如下:
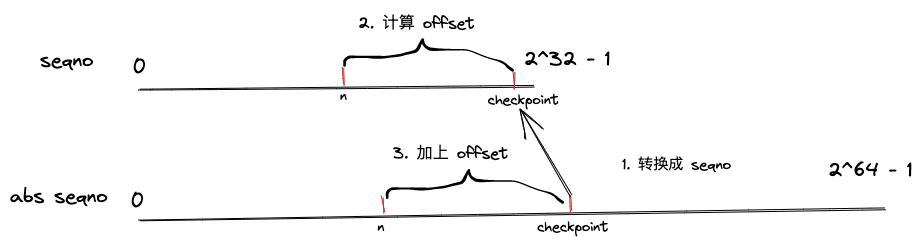
由于 absolute seqno 表示的范围是 seqno 的 2^32 倍,所以映射转换需要一定的技巧(因为 seqno=17 可以表示多个 absolute seqno,如 2^32 + 17/2^33 + 17/2^34 + 17 等),通过引入 checkpoint 变量来解决转换的问题,在 TCPReceiver 实现中 checkpoint 表示 ** 当前写入的总字节数 **,期望通过此值来寻找到离 absolute seqno 最近的那个 index,因为单个 TCP packet 长度必然不可超过 2^32,就是说,一旦 seqno 的区间映射到 [2^32 + 17,2^33 + 17] 这个区间,那就要计算到底 seqno 是 2^32 + 17、还是 2^33 + 17?
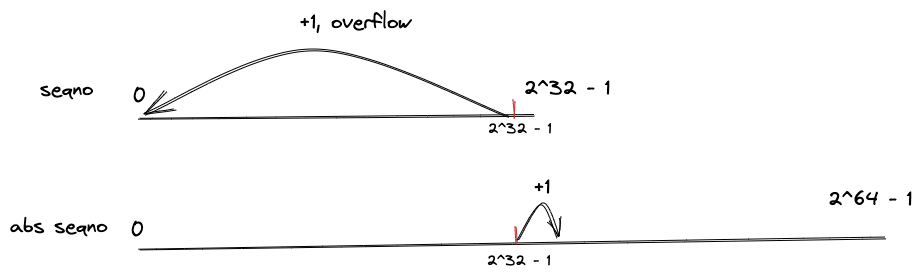
unwrap接口用于将absolute seqno转换成seqno,只需把absolute seqno加上isn初始偏移量,然后取absolute seqno的低32位值即可unwrap接口用于反向转换,假设要将n从seqno转换成absolute seqno,先将当前的chekpoint从absolute seqno转换成seqno,然后计算n(seqno版本) 和checkpoint(seqno版本) 的偏移量,最后加到checkpoint(absolute seqno版本)上面即可得出n(absolute seqno版本),参考下图:
实现代码如下:
// absolute seqno 转 seqno
WrappingInt32 wrap(uint64_t n, WrappingInt32 isn) {
return isn + uint32_t(n);
}
// version2
WrappingInt32 wrap(uint64_t n, WrappingInt32 isn) {
uint64_t m = (1ll << 32);
uint32_t num = (n + isn.raw_value()) % m;
return WrappingInt32{num};
}
uint64_t unwrap(WrappingInt32 n, WrappingInt32 isn, uint64_t checkpoint) {
uint64_t tmp = 0;
uint64_t tmp1 = 0;
if (n - isn < 0) {
tmp = uint64_t(n - isn + (1l << 32));
} else {
tmp = uint64_t(n - isn);
}
if (tmp>= checkpoint)
return tmp;
tmp |= ((checkpoint>> 32) << 32);
while (tmp <= checkpoint)
tmp += (1ll << 32);
tmp1 = tmp - (1ll << 32);
return (checkpoint - tmp1 < tmp - checkpoint) ? tmp1 : tmp;
}
如何理解 unwrap 的这种转换方法呢?TODO
接收(并重组)报文实现 segment_received
基于前文基础,看看处理 sponge-TCP 报文的流程,主要关注前面 SYN/FIN 报文即可,及时更新最新的 absolute seqno,这个也是TCPReceiver最核心的实现:
void TCPReceiver::segment_received(const TCPSegment &seg) {
const TCPHeader head = seg.header();
if (!head.syn && !_synReceived) {
return;
}
// extract data from the payload
string data = seg.payload().copy();
bool eof = false;
// first SYN received
if (head.syn && !_synReceived) {
_synReceived = true;
_isn = head.seqno;
if (head.fin) {
// 如果同时设置了 fin
_finReceived = eof = true;
}
// 重组开始(SYN)/ 重组结束(FIN)
_reassembler.push_substring(data, 0, eof);
return;
}
// FIN received
if (_synReceived && head.fin) {
_finReceived = eof = true;
}
// convert the seqno into absolute seqno
// 计算 absolute seqno 以及 stream_index
uint64_t checkpoint = _reassembler.ack_index();
uint64_t abs_seqno = unwrap(head.seqno, _isn, checkpoint);
uint64_t stream_idx = abs_seqno - _synReceived;
// push the data into stream reassembler
// 重组当前 data
_reassembler.push_substring(data, stream_idx, eof);
}
窗口大小和 ackno
窗口大小用于通知对端当前可以接收的字节流大小,ackno 用于通知对端当前接收的字节流进度。这两个也是由 TCPReceiver 提供,实现如下:
optional<WrappingInt32> TCPReceiver::ackno() const {
// next_write + 1 ,because syn flag will not push in stream
size_t next_write = _reassembler.stream_out().bytes_written() + 1;
next_write = _reassembler.stream_out().input_ended() ? next_write + 1 : next_write;
return !_received_syn ? optional<WrappingInt32>() : wrap(next_write, _isn);
}
size_t TCPReceiver::window_size() const {
return _reassembler.stream_out().remaining_capacity();
}
size_t ByteStream::remaining_capacity() const { return capacity - buffer.size(); }
TCPReceiver 定义
前面已经描述了 TCPReceiver 的核心功能了,这里列举下其定义:
class TCPReceiver {
//! Our data structure for re-assembling bytes.
StreamReassembler _reassembler;
//! The maximum number of bytes we'll store.
size_t _capacity;
//! Flag to indicate whether the first SYN message has received
bool _synReceived;
//! Flag to indicate whether FIN mesaage has received
bool _finReceived;
//! Inital Squence Number
WrappingInt32 _isn;
}
TCPReceiver 只负责:
- SYN/FIN 的标记,SYN - 流开始;FIN - 流结束
整个接收端的空间由窗口空间(StreamReassmbler)和缓冲区空间(ByteStream)两部分共享。需要注意窗口长度等于接收端容量减去还留在缓冲区的字节数,只有当字节从缓冲区读出后窗口长度才能缩减,CS144对整个TCPReceiver的执行流程期望如下:
0x06 LAB3:TCP 发送器 TCPSender
TCPSender 实现,仅包含 outbound 的 ByteSteam,但实际相对于 TCPReceiver 要复杂,需要支持:
- 根据
TCPSender当前的状态对可发送窗口进行填充,发包 TCPSender需要根据对方通知的窗口大小和ackno来确认对方当前收到的字节流进度- 需支持超时重传机制,根据时间变化(RTO),定时重传那些还没有
ack的报文
0x07 LAB4:完整 sponge-TCP 连接:TCPConnection
TCPConnection 的实现,包含如下步骤:
- 写入数据,发送数据包
- 接收数据包
- 丰富超时重传机制
0x01 参考
Related Issues not found
Please contact @pandaychen to initialize the comment
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK