

Stable Diffusion 3技术报告出炉:揭露Sora同款架构细节
source link: https://www.qbitai.com/2024/03/125822.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Stable Diffusion 3技术报告出炉:揭露Sora同款架构细节

文字渲染能力成功关键在此
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
很快啊,“文生图新王”Stable Diffusion 3的技术报告,这就来了。
全文一共28页,诚意满满。

“老规矩”,宣传海报(⬇️)直接用模型生成,再秀一把文字渲染能力:
所以,SD3这比DALL·E 3和Midjourney v6都要强的文字以及指令跟随技能,究竟怎么点亮的?
技术报告揭露:
全靠多模态扩散Transformer架构MMDiT。
成功关键是对图像和文本表示使用单独两组权重的方式,由此实现了比SD3之前的版本都要强的性能飞升。
具体几何,我们翻开报告来看。
微调DiT,提升文本渲染能力
在发布SD3之初,官方就已经透露它的架构和Sora同源,属于扩散型Transformer——DiT。
现在答案揭晓:
由于文生图模型需要考虑文本和图像两种模式,Stability AI比DiT更近一步,提出了新架构MMDiT。
这里的“MM”就是指“multimodal”。
和Stable Diffusion此前的版本一样,官方用两个预训练模型来获得合适和文本和图像表示。
其中文本表示的编码用三种不同的文本嵌入器(embedders)来搞定,包括两个CLIP模型和一个T5模型。
图像token的编码则用一个改进的自动编码器模型来完成。
由于文本和图像的embedding在概念上完全不是一个东西,因此,SD3对这两种模式使用了两组独立的权重。
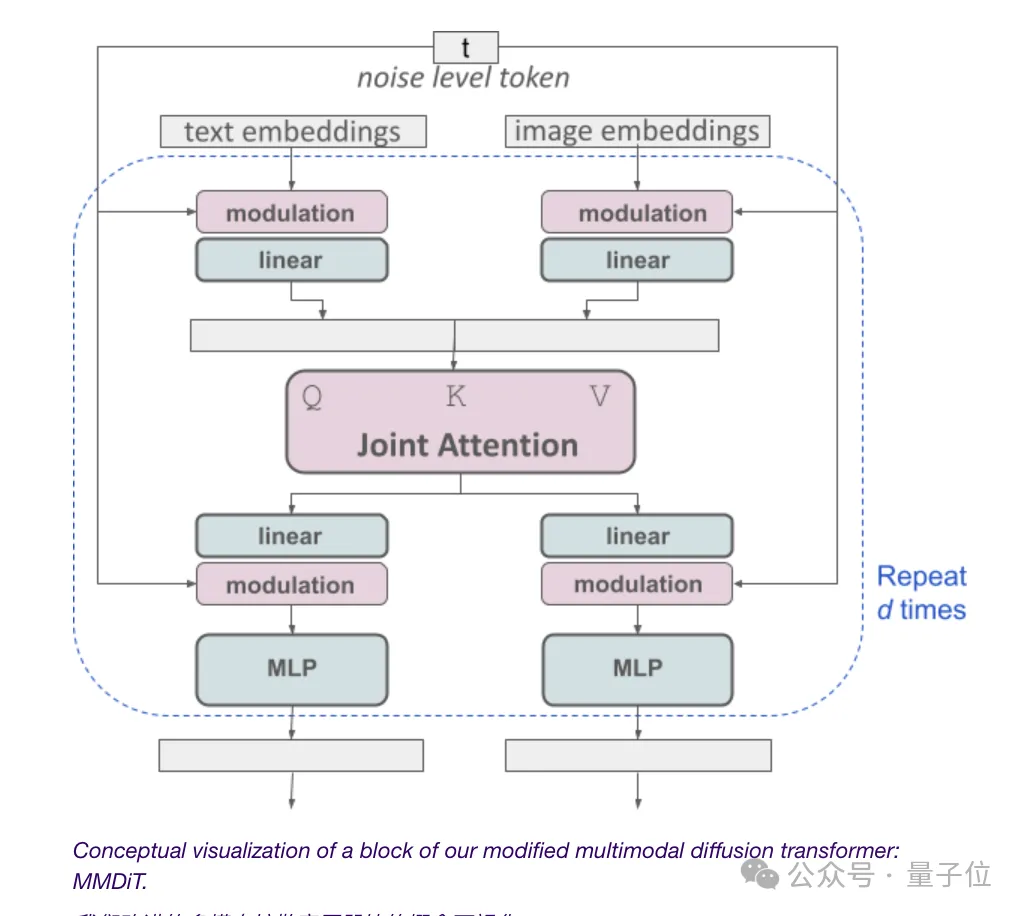
如上图所示,这相当于每种模态都有两个独立的transformer,但是会将它们的序列连接起来进行注意力操作。
这样,两种表示都可以在自己的空间中工作,同时还能考虑到另一种。
最终,通过这种方法,信息就可以在图像和文本token之间“流动”,在输出时提高模型的整体理解能力和文字渲染能力。
并且正如之前的效果展示,这种架构还可以轻松扩展到视频等多种模式。

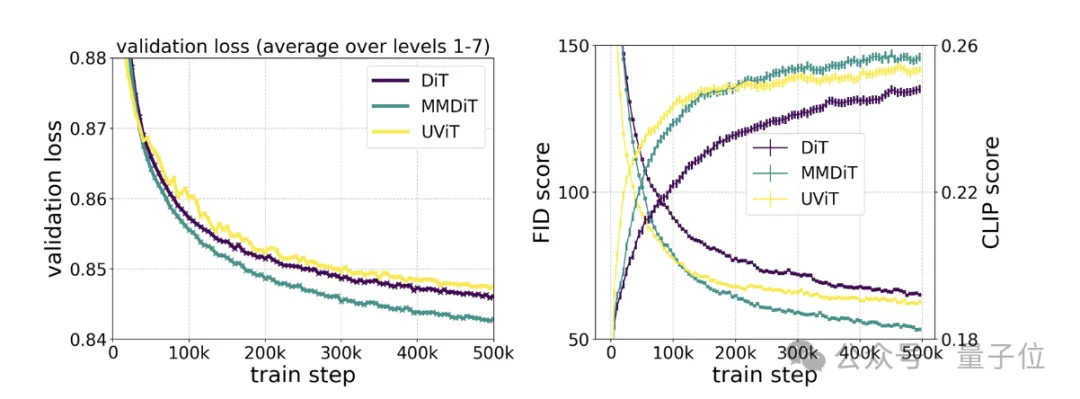
具体测试则显示,MMDiT出于DiT却胜于DiT:
它在训练过程中的视觉保真度和文本对齐度都优于现有的文本到图像backbone,比如UViT、DiT。
重新加权流技术,不断提升性能
在发布之初,除了扩散型Transformer架构,官方还透露SD3结合了flow matching。
什么“流”?
如今天发布的论文标题所揭露,SD3采用的正是“Rectified Flow”(RF)。

这是一个“极度简化、一步生成”的扩散模型生成新方法,入选了ICLR2023。
它可以使模型的数据和噪声在训练期间以线性轨迹进行连接,产生更“直”的推理路径,从而可以使用更少的步骤进行采样。
基于RF,SD3在训练过程中引入了一张全新的轨迹采样。
它主打给轨迹的中间部分更多权重,因为作者假设这些部分会完成更具挑战性的预测任务。
通过多个数据集、指标和采样器配置,与其他60个扩散轨迹方法(比如LDM、EDM和ADM)测试这一生成方法发现:
虽然以前的RF方法在少步采样方案中表现出不错的性能,但它们的相对性能随着步数的增加而下降。
相比之下,SD3重新加权的RF变体可以不断提高性能。
模型能力还可进一步提高
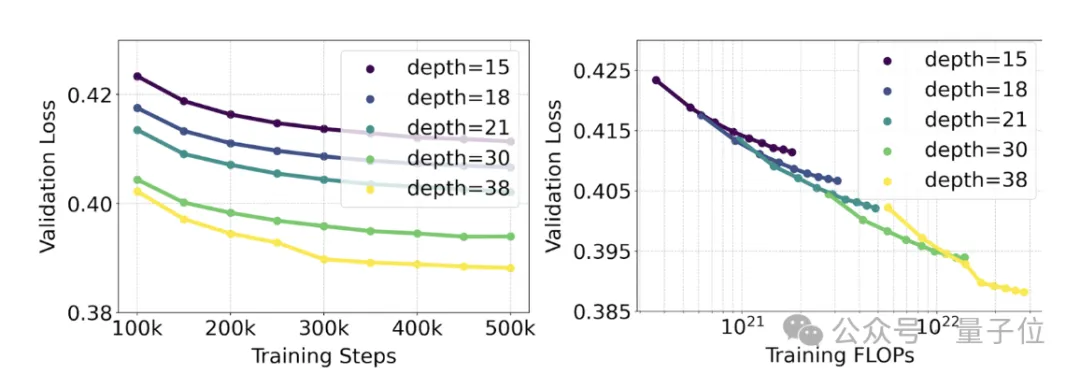
官方使用重新加权的RF方法和MMDiT架构对文本到图像的生成进行了规模化研究(scaling study)。
训练的模型范围从15个具有4.5亿参数的模块到38个具有80亿参数的模块。
从中他们观察到:随着模型大小和训练步骤的增加,验证损失呈现出平滑的下降趋势,即模型通过不断学习适应了更为复杂的数据。
为了测试这是否在模型输出上转化为更有意义的改进,官方还评估了自动图像对齐指标(GenEval)以及人类偏好评分(ELO)。
两者有很强的相关性。即验证损失可以作为一个很有力的指标,预测整体模型表现。
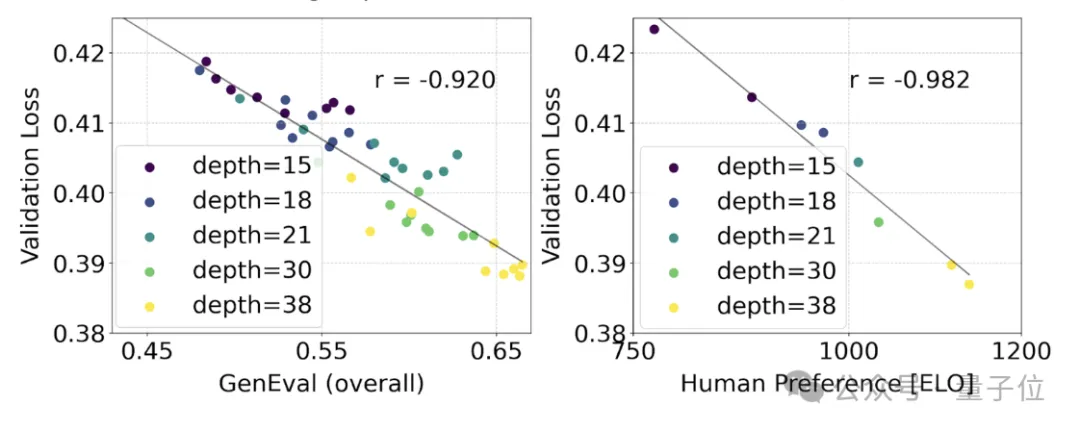
此外,由于这里的扩展趋势没有出现饱和迹象(即即随着模型规模的增加,性能仍在提升,没有达到极限),官方很乐观地表示:
未来的SD3性能还能继续提高。
最后,技术报告还提到了文本编码器的问题:
通过移除用于推理的47亿参数、内存密集型T5文本编码器,SD3的内存需求可以显著降低,但同时,性能损失很小(win rate从50%降到46%)。
不过,为了文字渲染能力,官方还是建议不要去掉T5,因为没有它,文本表示的win rate将跌至38%。

那么总结一下就是说:SD3的3个文本编码器中,T5在生成带文本图像(以及高度详细的场景描述图)时贡献是最大的。
网友:开源承诺如期兑现,感恩
SD3报告一出,不少网友就表示:
Stability AI对开源的承诺如期而至很是欣慰,希望他们能够继续保持并长久运营下去。

还有人就差报OpenAI大名了:

更加值得欣慰的是,有人在评论区提到:
SD3模型的权重全部都可以下载,目前规划的是8亿参数、20亿参数和80亿参数。


速度怎么样?
咳咳,技术报告有提:
80亿的SD3在24GB的RTX 4090上需要34s才能生成1024*1024的图像(采样步骤50个)——不过这只是早期未经优化的初步推理测试结果。
报告全文:
https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
参考链接:
[1]https://stability.ai/news/stable-diffusion-3-research-paper
[2]https://news.ycombinator.com/it
Recommend
-
6
美国大学发布重磅报告,揭露政府持续监视民众的阴谋-51CTO.COM 美国大学发布重磅报告,揭露政府持续监视民众的阴谋 作者:苏苏 2022-07-27 13:44:51
-
9
Stable Diffusion launch announcement 10 Aug Written By Emad Mostaque
-
7
Ranked #17 for todayStable Diffusion - DreamStudioUnlock our creative potentialFree OptionsStable Diff...
-
13
Getting Stable Diffusion Running on NixOS A 11 minute read.
-
7
Stable Diffusion Is the Most Important AI Art Model EverA state-of-the-art AI model available for everyone through a safety-centric open-source license is unheard of.
-
7
Stable Diffusion is a really big deal If you haven’t been paying attention to what’s going on with Stable Diffusion, you really should be. Stable Diffusion is a new “text-to-image diffusion model” that was
-
7
Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion’s Image Generator One of the biggest frustrations of text-to-image generation AI models is that they feel like a black box. We know th...
-
6
Run Stable Diffusion on your M1 Mac’s GPU Posted yesterday by @bfirsh Stable Diffusion is open source, so anyone can run and mo...
-
6
Stable Diffusion火到被艺术家集体举报,网友科普背后机制被LeCun点赞
-
4
揭露「跳票」真相:Cybertruck 生产报告泄漏,马斯克头疼多年的原因找到了 特斯拉的江山,双雄苦撑久矣。
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK