

消费级显卡可用!李开复零一万物发布并开源90亿参数Yi模型,代码数学能力史上最强
source link: https://www.qbitai.com/2024/03/126184.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

消费级显卡可用!李开复零一万物发布并开源90亿参数Yi模型,代码数学能力史上最强

仅次于“干翻GPT-4”的DeepSeek
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
李开复旗下AI公司零一万物,又一位大模型选手登场:
90亿参数Yi-9B。
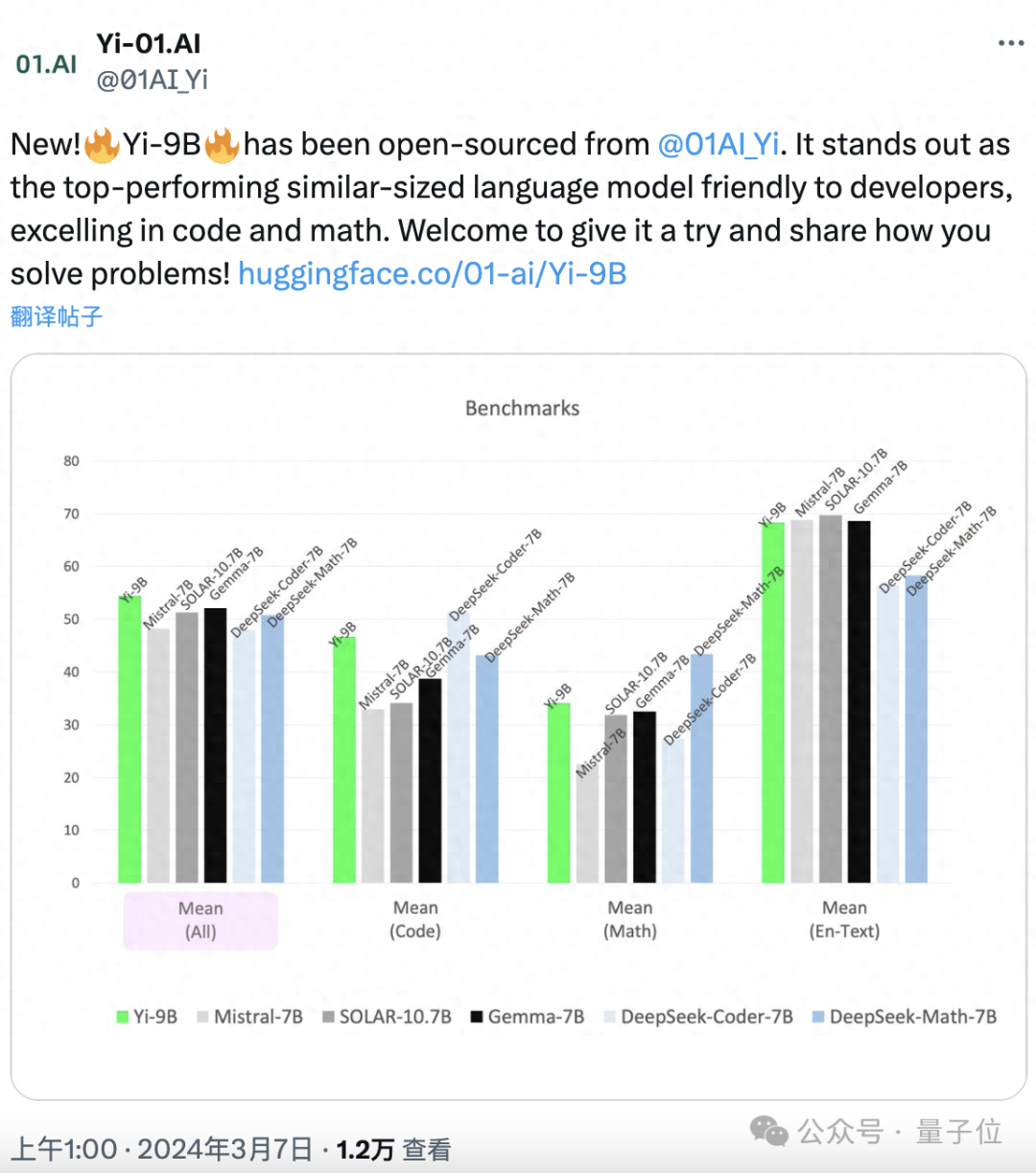
它号称Yi系列中的“理科状元”,“恶补”了代码数学,同时综合能力也没落下。
在一系列类似规模的开源模型(包括Mistral-7B、SOLAR-10.7B、Gemma-7B、DeepSeek-Coder-7B-Base-v1.5等)中,表现最佳。
老规矩,发布即开源,尤其对开发者友好:
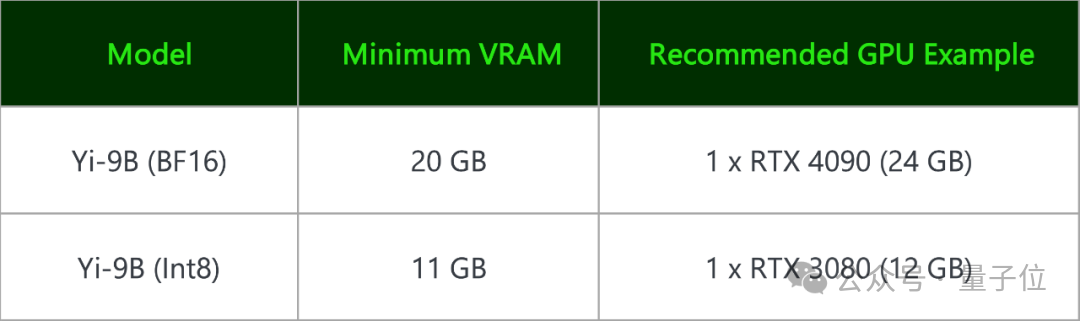
Yi-9B(BF 16) 和其量化版 Yi-9B(Int8)都能在消费级显卡上部署。
一块RTX 4090、一块RTX 3090就可以。
深度扩增+多阶段增量训练而成
零一万物的Yi家族此前已经发布了Yi-6B和Yi-34B系列。
这两者都是在3.1T token中英文数据上进行的预训练,Yi-9B则在此基础上,增加了0.8T token继续训练而成。
数据的截止日期是2023年6月。
开头提到,Yi-9B最大的进步在于数学和代码,那么这俩能力究竟如何提升呢?
零一万物介绍:
单靠增加数据量并没法达到预期。
靠的是先增加模型大小,在Yi-6B的基础上增至9B,再进行多阶段数据增量训练。
首先,怎么个模型大小增加法?
一个前提是,团队通过分析发现:
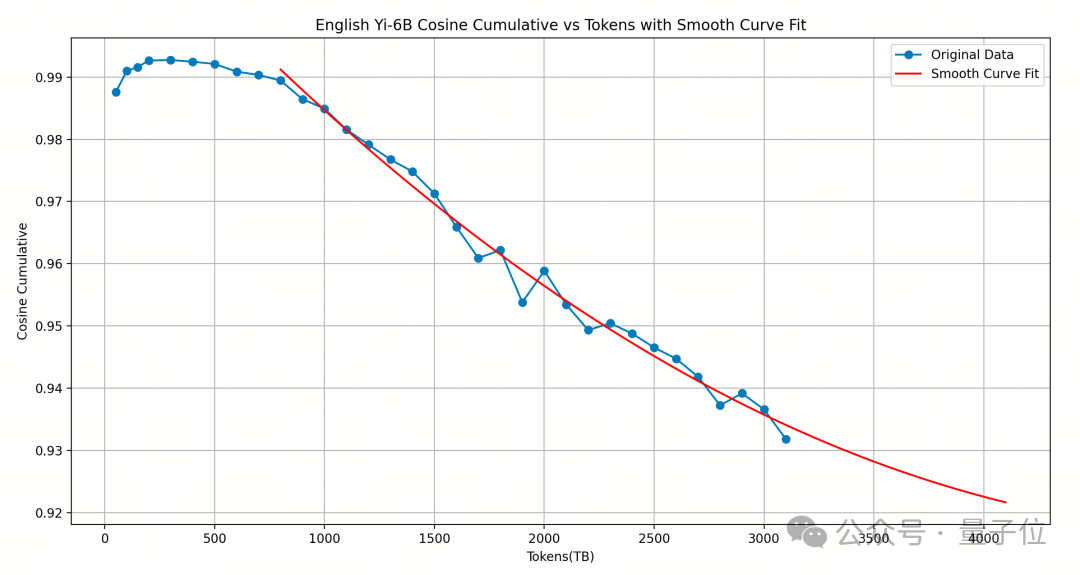
Yi-6B训练得已经很充分,再怎么新增更多token练效果可能也不会往上了,所以考虑扩增它的大小。(下图单位不是TB而是B)
怎么增?答案是深度扩增。
零一万物介绍:
对原模型进行宽度扩增会带来更多的性能损失,通过选择合适的layer对模型进行深度扩增后,新增layer的input/output cosine 越接近1.0,即扩增后的模型性能越能保持原有模型的性能,模型性能损失微弱。
依照此思路,零一万物选择复制Yi-6B相对靠后的16层(12-28 层),组成了48层的Yi-9B。
实验显示,这种方法比用Solar-10.7B模型复制中间的16层(8-24层)性能更优。
其次,怎么个多阶段训练法?
答案是先增加0.4T包含文本和代码的数据,但数据配比与Yi-6B一样。
然后增加另外的0.4T数据,同样包括文本和代码,但重点增加代码和数学数据的比例。
(悟了,就和我们在大模型提问里的诀窍“think step by step”思路一样)
这两步操作完成后,还没完,团队还参考两篇论文(An Empirical Model of Large-Batch Training和Don’t Decay the Learning Rate, Increase the Batch Size)的思路,优化了调参方法。
即从固定的学习率开始,每当模型loss停止下降时就增加batch size,使其下降不中断,让模型学习得更加充分。
最终,Yi-9B实际共包含88亿参数,达成4k上下文长度。
Yi系列中代码和数学能力最强
实测中,零一万物使用greedy decoding的生成方式(即每次选择概率值最大的单词)来进行测试。
参评模型为DeepSeek-Coder、DeepSeek-Math、Mistral-7B、SOLAR-10.7B和Gemma-7B:
(1)DeepSeek-Coder,来自国内的深度求索公司,其33B的指令调优版本人类评估超越GPT-3.5-turbo,7B版本性能则能达到CodeLlama-34B的性能。
DeepSeek-Math则靠7B参数干翻GPT-4,震撼整个开源社区。
(2)SOLAR-10.7B来自韩国的Upstage AI,2023年12月诞生,性能超越Mixtral-8x7B-Instruct。
(3)Mistral-7B则是首个开源MoE大模型,达到甚至超越了Llama 2 70B和GPT-3.5的水平。
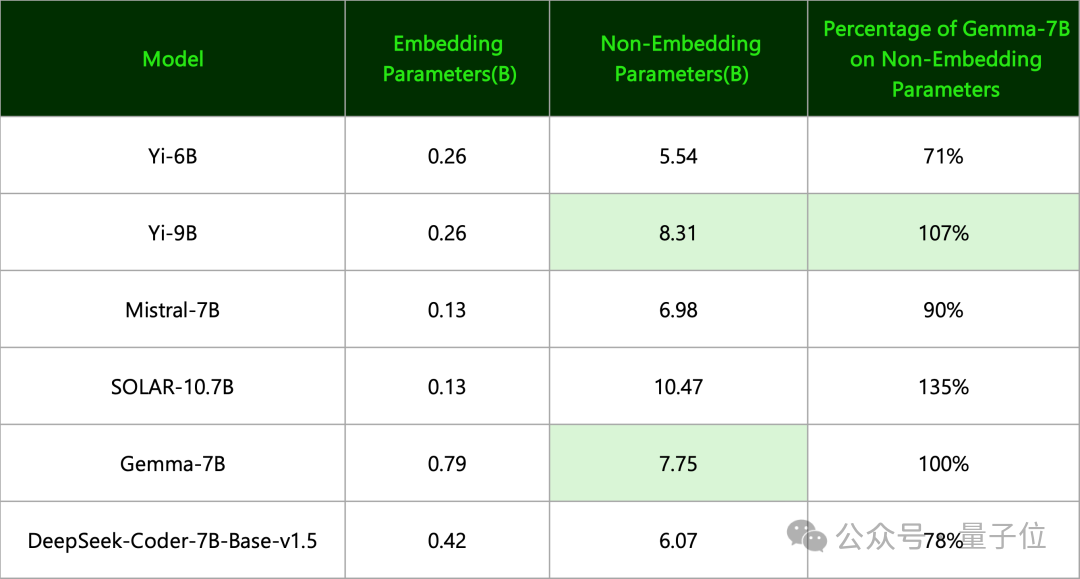
(4)Gemma-7B来自谷歌,零一万物指出:
其有效参数量其实和Yi-9B一个等级。
(两者命名准则不一样,前者只用了Non-Embedding参数,后者用的是全部参数量并向上取整)
结果如下。
首先在代码任务上,Yi-9B性能仅次于DeepSeek-Coder-7B,其余四位全部被KO。
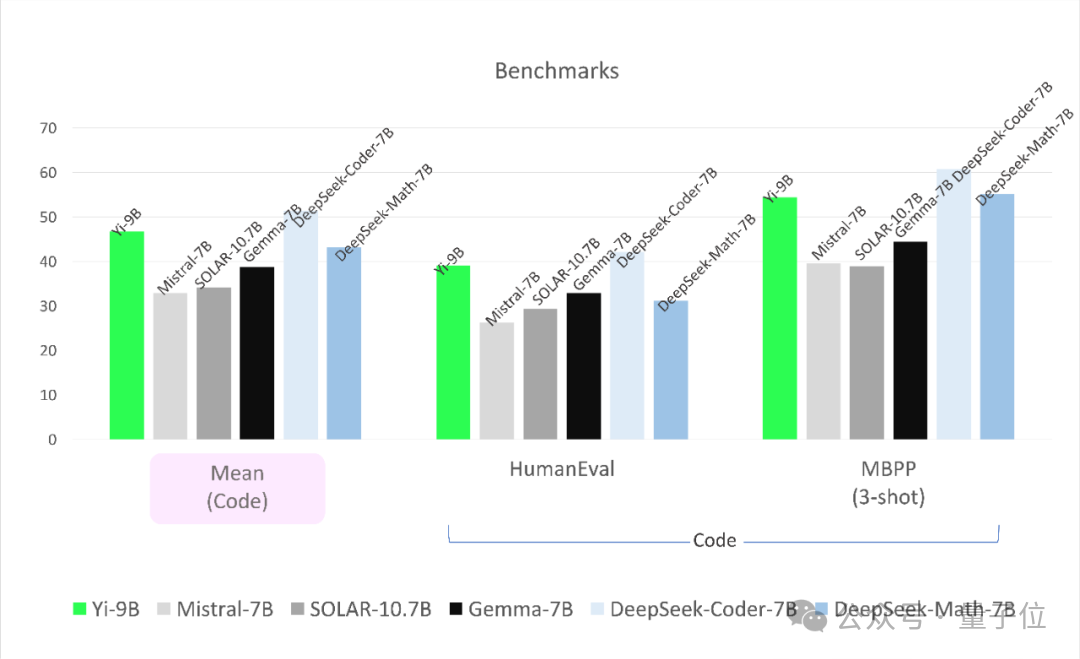
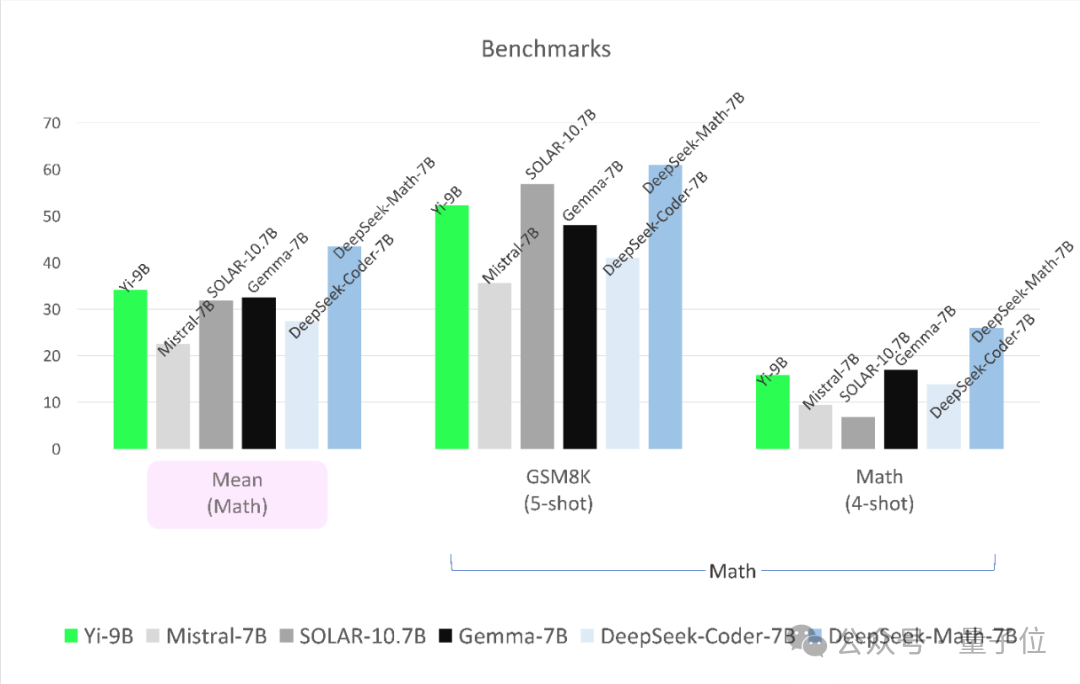
在数学能力上,Yi-9B性能仅次于DeepSeek-Math-7B,超越其余四位。
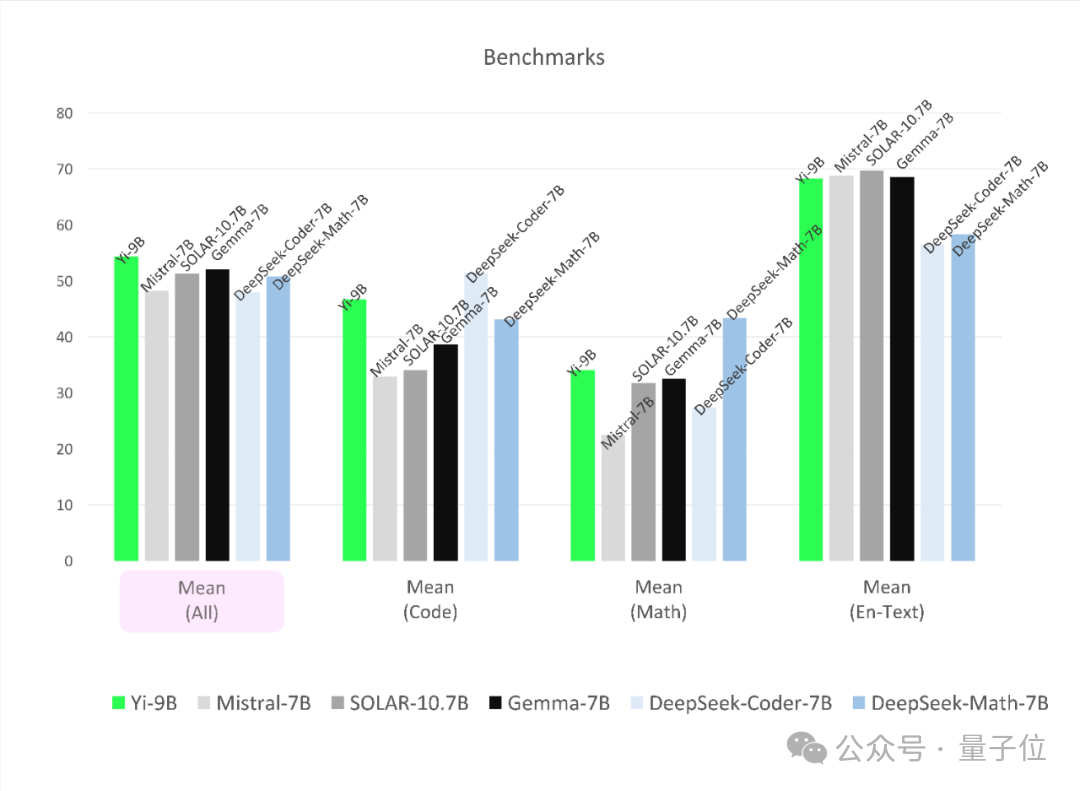
综合能力也不赖。
其性能在尺寸相近的开源模型中最好,超越了其余全部五位选手。
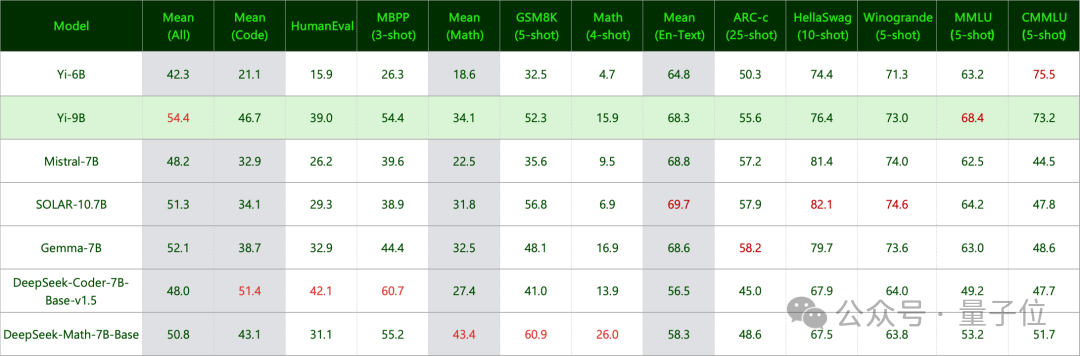
最后,还测了常识和推理能力:
结果是Yi-9B与Mistral-7B、SOLAR-10.7B和Gemma-7B不相上下。
以及语言能力,不仅英文不错,中文也是广受好评:
最最后,看完这些,有网友表示:已经迫不及待想试试了。

还有人则替DeepSeek捏了一把汗:
赶紧加强你们的“比赛”吧。全面主导地位已经没有了==

传送门在此:
https://huggingface.co/01-ai/Yi-9B
参考链接:
https://mp.weixin.qq.com/s/0CXIBlCZ7DJ2XjYT6Rm8tw
https://twitter.com/01AI_Yi/status/1765422092663849368
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK