
3

Understanding, Using, and Finetuning Gemma
source link: https://lightning.ai/lightning-ai/studios/understanding-using-and-finetuning-gemma
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Understanding, Using, and Finetuning Gemma
Gemma is Google’s latest open-weight LLM. This Studio shows you how to use Gemma through LitGPT and explains some of the unique design choices of Gemma compared to other LLMs.
Gemma Performance
The most notable aspect of Gemma is its impressive performance compared to other popular and widely used open-source models, such as Llama 2 7B and Mistral, as shown in the figure below.

Annotated performance comparison from the Gemma technical report (https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf).
What contributes to Gemma's outstanding performance? The reasons are not explicitly stated in the paper, but I assume it's due to:
- The large vocabulary size of 256,000 words (in contrast, Llama has a vocabulary of 32,000 words);
- The extensive 6 trillion token training dataset (Llama was trained on only one-third of that amount).
Moreover, upon integrating Gemma into our open-source LitGPT repository, my colleagues and I noticed that its overall architecture bears a strong resemblance to that of Llama 2. Let's examine this aspect more closely in the next section.
Gemma Architecture Insights
What are some of the interesting design choices behind Gemma? As mentioned above, its vocabulary size (and consequently the embedding matrix size) is very large. The table below shows an architecture overview comparing Gemma to LLama 2 7B and OLMo 7B.
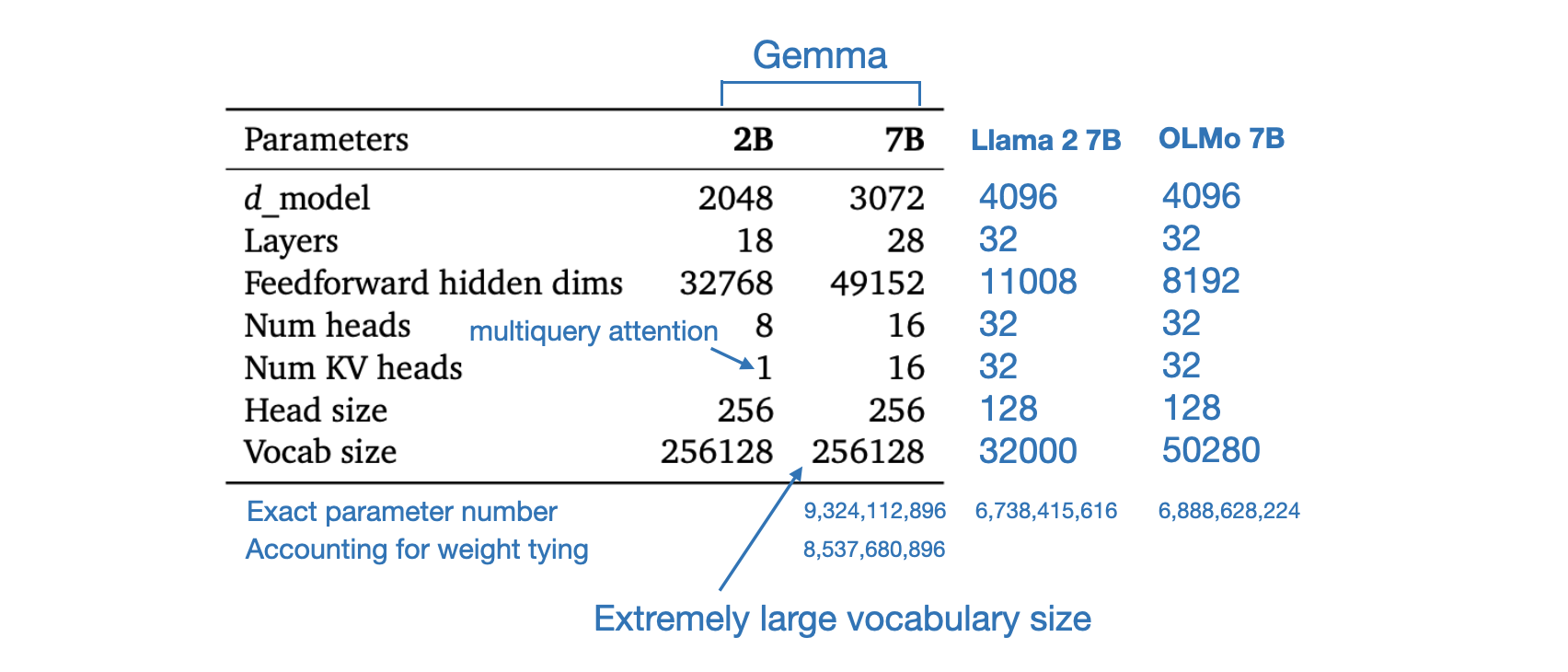
Model Sizes
Something else worth noting is that Gemma 2B utilized multi-query attention, whereas Gemma 7B did not. Additionally, Gemma 7B features a relatively large feedforward layer compared to Llama 2, despite having fewer layers in total (28 versus 32). However, despite having fewer layers, the number of parameters in Gemma is quite large.
Although it is called Gemma 7B, it actually has 9.3 billion parameters in total, and 8.5 billion parameters if you account for weight tying. Weight tying means that it shares the same weights in the input embedding and output projection layer, similar to GPT-2 and OLMo 1B (OLMO 7B was trained without weight tying).
Normalization layers
Another detail that stands out is the following quote from the paper:
> Normalizer Location. We normalize both the input and the output of each transformer sub-layer, a deviation from the standard practice of solely normalizing one or the other. We use RMSNorm (Zhang and Sennrich, 2019) as our normalization layer.
At first glance, it sounds like Gemma has an additional RMSNorm layer after each transformer block. However, looking at the official code implementation, it turns out that Gemma just uses the regular pre-normalization scheme that is used by other LLMs like GPT-2, Llama 2, and so on, as illustrated below.
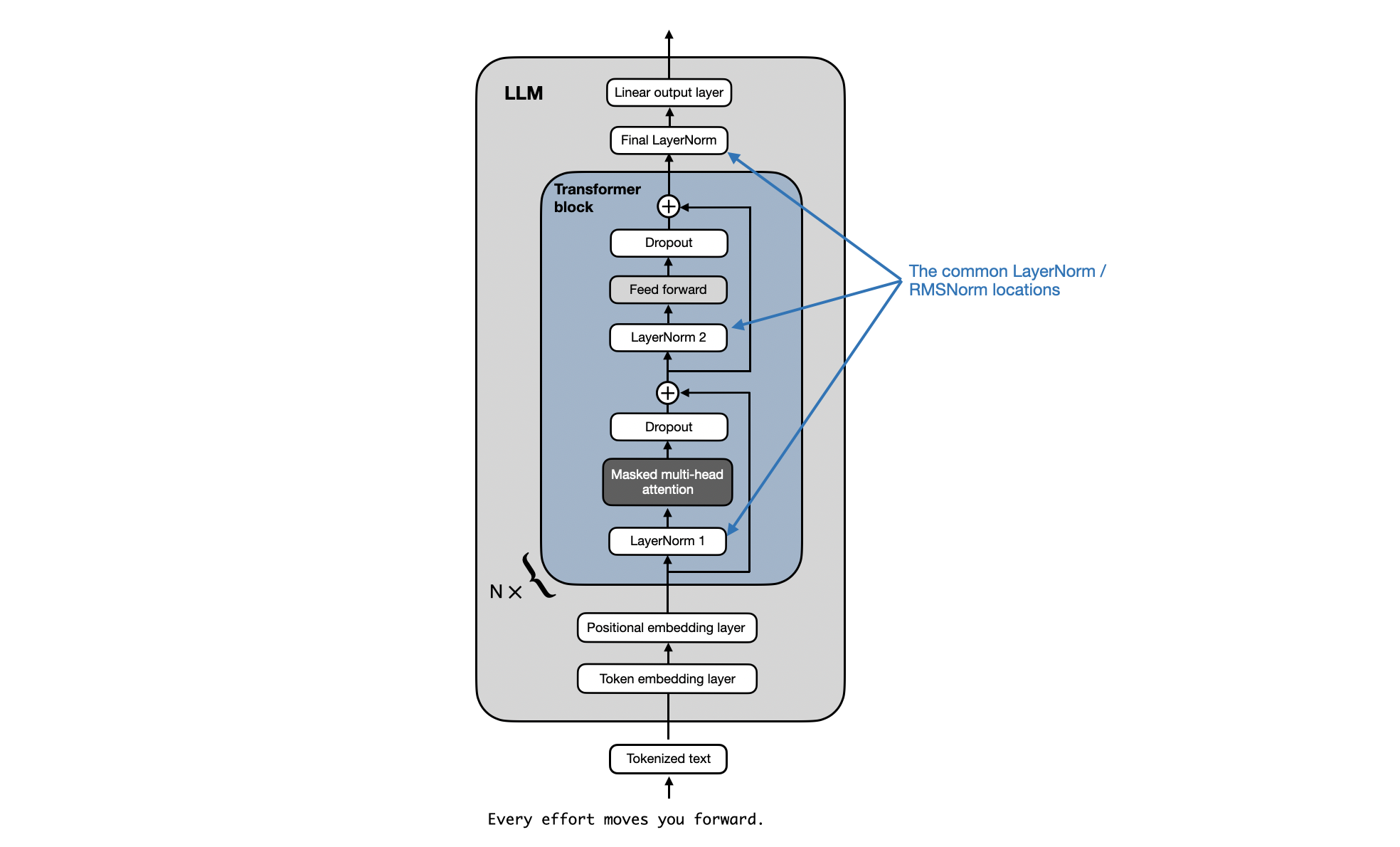
The typical layer normalization locations in GPT, Llama 2, and other LLMs: there's nothing new in Gemma. Annotated figure from "Build a Large Language Model From Scratch" (https://github.com/rasbt/LLMs-from-scratch).
GeGLU Activations
One notable deviation from other architectures is that Gemma uses GeGLU activations, which was proposed in the 2020 paper GLU Variants Improve Transformer.
GeLU, or Gaussian Error Linear Unit, is an activation function that has become increasingly popular as an alternative to the traditional ReLU. The popularity of GeLU stems from its ability to introduce nonlinearity while also allowing for the propagation of gradients for negative input values, addressing one of the limitations of ReLU, which blocks negative values completely.
Now, GeGLU is a gated linear unit variant of GeGLU, where the activation is split into two parts, a sigmoidal part and a linear projection that is element-wise multiplied with the output of the first part, as illustrated below.

GELU and ReLU side by side Annotated figure from "Build a Large Language Model From Scratch" (https://github.com/rasbt/LLMs-from-scratch).
As illustrated above, GeGLU is analogous to SwiGLU activations used by other LLMs (for example, Llama 2 and Mistral), except that it uses GELU as the base activation rather than Swish.

This is perhaps easier to see when looking at the pseudo-code of these activations:
Note that feedforward modules with SwiGLU and GeGLU effectively have one more linear layer (
linear_1 and linear_2) compared to the regular feedforward module with GeLU (only linear). However, in GeGLU and SwiGLU feedforward modules, the linear_1 and linear_2 are typically obtained by splitting a single linear layer into two parts so that it doesn't necessarily increase the parameter size.Is GeGLU better than SwiGLU? There are no ablation studies to say for sure. I suspect the choice could have also been just to make Gemma slightly more different from Llama 2.
Moreover, when adding Gemma support for LitGPT, led by the efforts of Andrei Aksionov and Carlos Mocholi, we found some other interesting design choices.
For instance, Gemma adds an offset of +1 to the RMSNorm layers and normalizes the embeddings by the square root of the hidden layer dimension. These details are not mentioned or discussed in the paper, and the significance of this is not clear.
Conclusion
Gemma is a nice contribution to the openly-available LLM collection. It appears that the 7B model is a very strong model that could potentially replace Llama 2 and Mistral in real-world use cases.
In addition, since we already have a large collection of ~7B models openly available, the Gemma 2B is almost more interesting as it comfortably runs on a single GPU. It'll be interesting to see how it compares to phi-2, which is 2.7B in size as well.
Using Gemma
Click on the “Run Template” button above to get started with Gemma in this Studio. For instance, you can run Gemma in chat mode via:
Alternatively, you can change
gemma-7b-it to gemma-2b-it if you want to use the instruction-finetuned version of 2B version Gemma: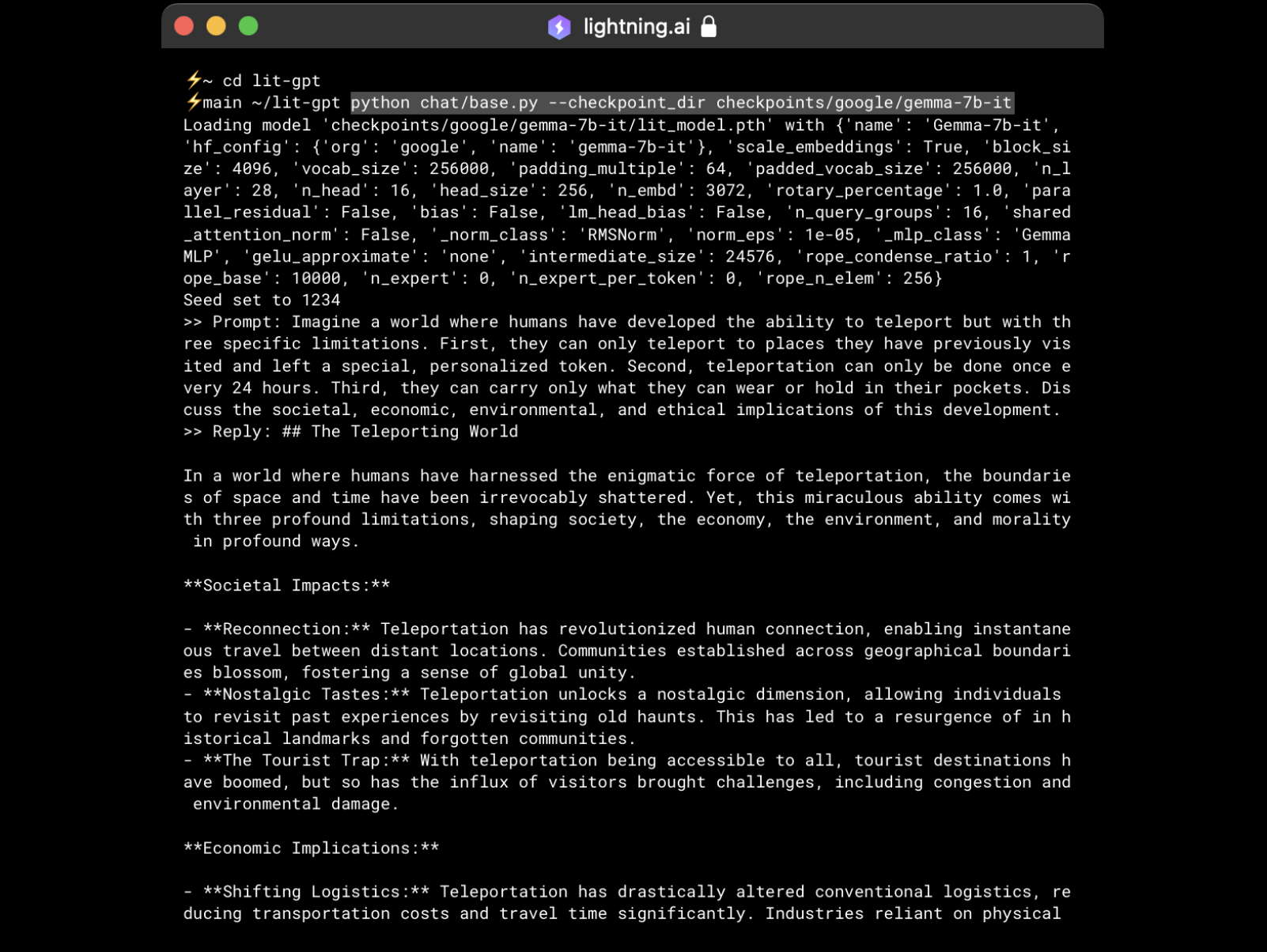
you are interested in instruction finetuning Gemma yourself, for example, using LoRA, follow these steps:
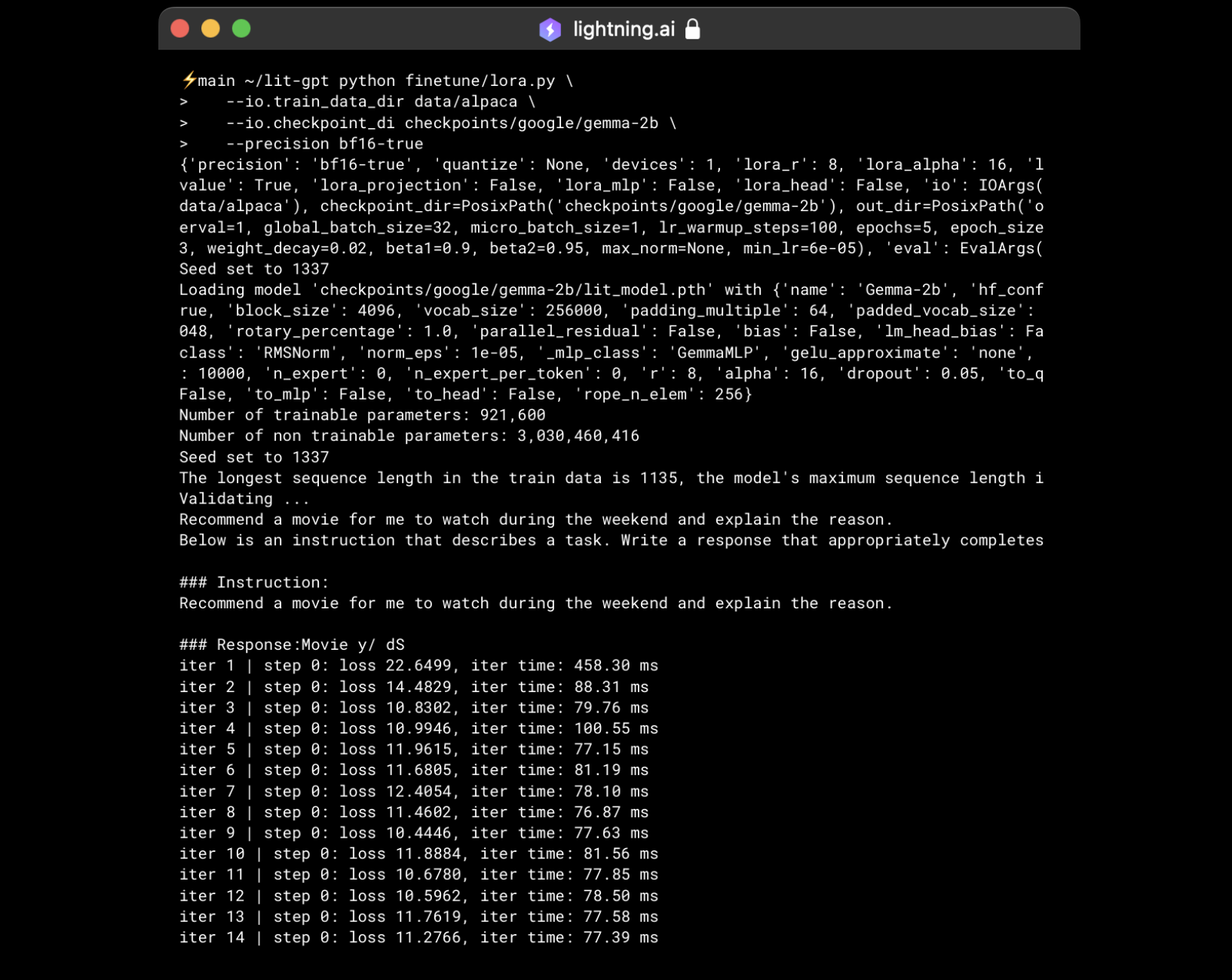
For more information, duplicate the Studio and see the
tutorials/ documents.To get started using Gemma, click the Run Template button at the top of this page.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK