

神经网络优化篇:详解TensorFlow - Oten
source link: https://www.cnblogs.com/oten/p/18026749
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

TensorFlow
先提一个启发性的问题,假设有一个损失函数JJ需要最小化,在本例中,将使用这个高度简化的损失函数,Jw=w2−10w+25Jw=w2−10w+25,这就是损失函数,也许已经注意到该函数其实就是(w−5)2(w−5)2,如果把这个二次方式子展开就得到了上面的表达式,所以使它最小的ww值是5,但假设不知道这点,只有这个函数,来看一下怎样用TensorFlow将其最小化,因为一个非常类似的程序结构可以用来训练神经网络。其中可以有一些复杂的损失函数J(w,b)J(w,b)取决于的神经网络的所有参数,然后类似的,就能用TensorFlow自动找到使损失函数最小的ww和bb的值。但让先从左边这个更简单的例子入手。
在的Jupyter notebook中运行Python,
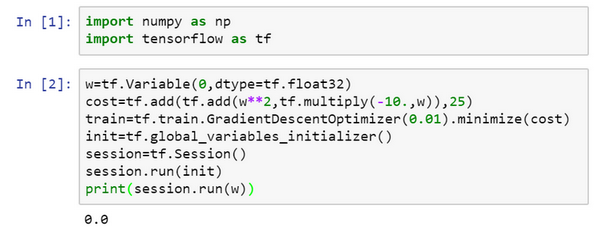
import numpy as np
import tensorflow as tf
#导入TensorFlow
w = tf.Variable(0,dtype = tf.float32)
#接下来,让定义参数w,在TensorFlow中,要用tf.Variable()来定义参数
#然后定义损失函数:
cost = tf.add(tf.add(w**2,tf.multiply(- 10.,w)),25)
#然后定义损失函数J
然后再写:
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
#(让用0.01的学习率,目标是最小化损失)。
#最后下面的几行是惯用表达式:
init = tf.global_variables_initializer()
session = tf.Session()#这样就开启了一个TensorFlow session。
session.run(init)#来初始化全局变量。
#然后让TensorFlow评估一个变量,要用到:
session.run(w)
#上面的这一行将w初始化为0,并定义损失函数,定义train为学习算法,它用梯度下降法优化器使损失函数最小化,但实际上还没有运行学习算法,所以#上面的这一行将w初始化为0,并定义损失函数,定义train为学习算法,它用梯度下降法优化器使损失函数最小化,但实际上还没有运行学习算法,所以session.run(w)评估了w,让::
print(session.run(w))
所以如果运行这个,它评估ww等于0,因为什么都还没运行。
#现在让输入:
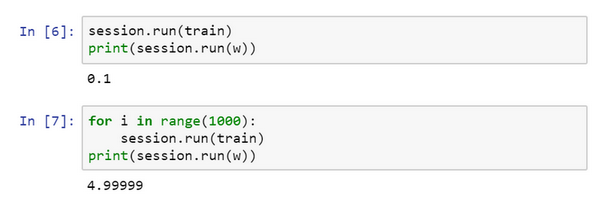
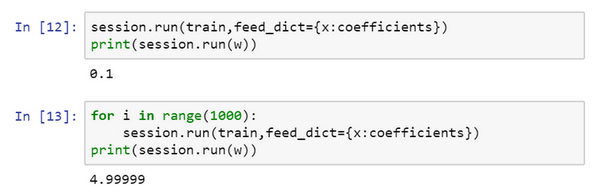
$session.run(train),它所做的就是运行一步梯度下降法。
#接下来在运行了一步梯度下降法后,让评估一下w的值,再print:
print(session.run(w))
#在一步梯度下降法之后,w现在是0.1。

现在运行梯度下降1000次迭代:

这是运行了梯度下降的1000次迭代,最后ww变成了4.99999,记不记得说(w−5)2(w−5)2最小化,因此ww的最优值是5,这个结果已经很接近了。
希望这个让对TensorFlow程序的大致结构有了了解,当做编程练习,使用更多TensorFlow代码时,这里用到的一些函数会熟悉起来,这里有个地方要注意,ww是想要优化的参数,因此将它称为变量,注意需要做的就是定义一个损失函数,使用这些add和multiply之类的函数。TensorFlow知道如何对add和mutiply,还有其它函数求导,这就是为什么只需基本实现前向传播,它能弄明白如何做反向传播和梯度计算,因为它已经内置在add,multiply和平方函数中。
对了,要是觉得这种写法不好看的话,TensorFlow其实还重载了一般的加减运算等等,因此也可以把costcost写成更好看的形式,把之前的cost标成注释,重新运行,得到了同样的结果。
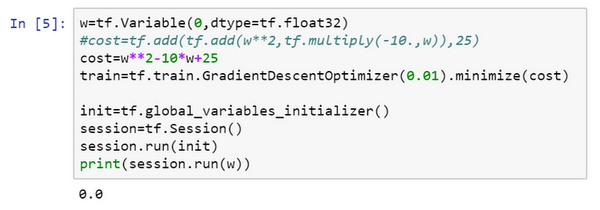
一旦ww被称为TensorFlow变量,平方,乘法和加减运算都重载了,因此不必使用上面这种不好看的句法。
TensorFlow还有一个特点,想告诉,那就是这个例子将ww的一个固定函数最小化了。如果想要最小化的函数是训练集函数又如何呢?不管有什么训练数据xx,当训练神经网络时,训练数据xx会改变,那么如何把训练数据加入TensorFlow程序呢?
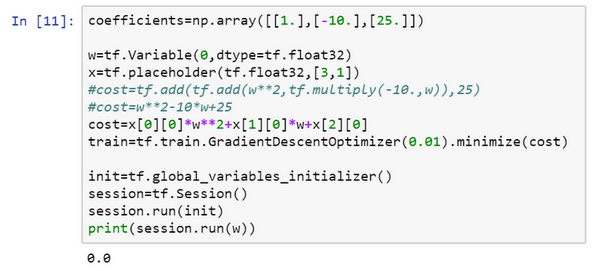
会定义xx,把它想做扮演训练数据的角色,事实上训练数据有xx和yy,但这个例子中只有xx,把xx定义为:
x = tf.placeholder(tf.float32,[3,1]),让它成为[3,1][3,1]数组,要做的就是,因为costcost这个二次方程的三项前有固定的系数,它是w2+10w+25w2+10w+25,可以把这些数字1,-10和25变成数据,要做的就是把costcost替换成:
cost = x[0][0]*w**2 +x[1][0]*w + x[2][0],现在xx变成了控制这个二次函数系数的数据,这个placeholder函数告诉TensorFlow,稍后会为xx提供数值。
让再定义一个数组,coefficient = np.array([[1.],[-10.],[25.]]),这就是要接入xx的数据。最后需要用某种方式把这个系数数组接入变量xx,做到这一点的句法是,在训练这一步中,要提供给xx的数值,在这里设置:
feed_dict = {x:coefficients}
好了,希望没有语法错误,重新运行它,希望得到和之前一样的结果。
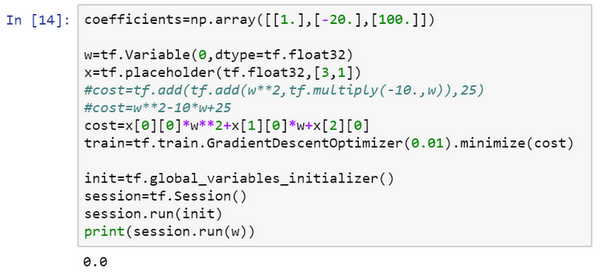
现在如果想改变这个二次函数的系数,假设把:
coefficient = np.array([[1.],[-10.],[25.]])
改为:coefficient = np.array([[1.],[-20.],[100.]])
现在这个函数就变成了(w−10)2(w−10)2,如果重新运行,希望得到的使(w−10)2(w−10)2最小化的ww值为10,让看一下,很好,在梯度下降1000次迭代之后,得到接近10的ww。
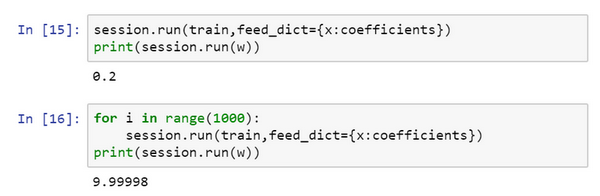
在做编程练习时,见到更多的是,TensorFlow中的placeholder是一个之后会赋值的变量,这种方式便于把训练数据加入损失方程,把数据加入损失方程用的是这个句法,当运行训练迭代,用feed_dict来让x=coefficients。如果在做mini-batch梯度下降,在每次迭代时,需要插入不同的mini-batch,那么每次迭代,就用feed_dict来喂入训练集的不同子集,把不同的mini-batch喂入损失函数需要数据的地方。
希望这让了解了TensorFlow能做什么,让它如此强大的是,只需说明如何计算损失函数,它就能求导,而且用一两行代码就能运用梯度优化器,Adam优化器或者其他优化器。

这还是刚才的代码,稍微整理了一下,尽管这些函数或变量看上去有点神秘,但在做编程练习时多练习几次就会熟悉起来了。

还有最后一点想提一下,这三行(蓝色大括号部分)在TensorFlow里是符合表达习惯的,有些程序员会用这种形式来替代,作用基本上是一样的。
但这个with结构也会在很多TensorFlow程序中用到,它的意思基本上和左边的相同,但是Python中的with命令更方便清理,以防在执行这个内循环时出现错误或例外。所以也会在编程练习中看到这种写法。那么这个代码到底做了什么呢?让看这个等式:
cost =x[0][0]*w**2 +x[1][0]*w + x[2][0]#(w-5)**2
TensorFlow程序的核心是计算损失函数,然后TensorFlow自动计算出导数,以及如何最小化损失,因此这个等式或者这行代码所做的就是让TensorFlow建立计算图,计算图所做的就是取x[0][0]x[0][0],取ww,然后将它平方,然后x[0][0]x[0][0]和w2w2相乘,就得到了x[0][0]∗w2x[0][0]∗w2,以此类推,最终整个建立起来计算cost=[0][0]∗w∗∗2+x[1][0]∗w+x[2][0]cost=[0][0]∗w∗∗2+x[1][0]∗w+x[2][0],最后得到了损失函数。

TensorFlow的优点在于,通过用这个计算损失,计算图基本实现前向传播,TensorFlow已经内置了所有必要的反向函数,回忆一下训练深度神经网络时的一组前向函数和一组反向函数,而像TensorFlow之类的编程框架已经内置了必要的反向函数,这也是为什么通过内置函数来计算前向函数,它也能自动用反向函数来实现反向传播,即便函数非常复杂,再帮计算导数,这就是为什么不需要明确实现反向传播,这是编程框架能帮变得高效的原因之一。

如果看TensorFlow的使用说明,只是指出TensorFlow的说明用了一套和不太一样的符号来画计算图,它用了x[0][0]x[0][0],ww,然后它不是写出值,想这里的w2w2,TensorFlow使用说明倾向于只写运算符,所以这里就是平方运算,而这两者一起指向乘法运算,以此类推,然后在最后的节点,猜应该是一个将x[2][0]x[2][0]加上去得到最终值的加法运算。
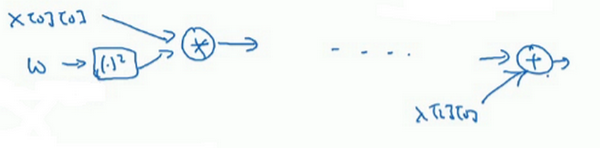
认为计算图用第一种方式会更容易理解,但是如果去看TensorFlow的使用说明,如果看到说明里的计算图,会看到另一种表示方式,节点都用运算来标记而不是值,但这两种呈现方式表达的是同样的计算图。
在编程框架中可以用一行代码做很多事情,例如,不想用梯度下降法,而是想用Adam优化器,只要改变这行代码,就能很快换掉它,换成更好的优化算法。所有现代深度学习编程框架都支持这样的功能,让很容易就能编写复杂的神经网络。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK