

Sora 证明马斯克的是对的,但特斯拉和人类可能都输了
source link: https://finance.sina.com.cn/chanjing/gsnews/2024-02-19/doc-inaipzvh8092866.shtml
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Sora 证明马斯克的是对的,但特斯拉和人类可能都输了_新浪财经_新浪网

Sora 证明特斯拉的思路是对的,而特斯拉证明 Sora 的价值不止是生成视频。
来源:极客公园
作者 | 曹思颀
Sora 推出,马斯克可能是心情最复杂的一个。不仅因为其本人与 OpenAI 早年的纠葛,更因为 Sora 实现的其实是特斯拉早几年间一直在探索的方向。
2 月 18 日,马斯克在科技主播 @Dr.KnowItAll 一条主题为‘OpenAI 的重磅炸弹证实了特斯拉的理论’的视频下留言,称‘特斯拉已经能够用精确物理原理制作真实世界视频大约一年了’。
随后他在 X 上转发了一条 2023 年的视频,内容是特斯拉自动驾驶总监 Ashok Elluswamy 向外界介绍特斯拉如何用 AI 模拟真实世界驾驶。视频中,AI 同时生成了七个不同角度的驾驶视频,同时只需要输入‘直行’或者‘变道’这样的指令,就能让这七路视频同步变化。

当然,这不意味着特斯拉早在一年前就掌握了 Sora 的技术,毕竟特斯拉的生成技术只用于模拟车辆行驶,而 Sora 能够处理的环境、场景、Prompt、物理规律等信息更加复杂,二者在难度上不可同日而语。
但特斯拉 AI 和 Sora 训练的思路是一致的:并不是训练 AI 如何生成视频,而是训练 AI 理解和生成一个真实的场景或者世界,视频只是从某一个视角观察这个场景的一段时空。这是两家在现有业务上完全不同的公司,以彼此不同的方法来感知真实世界,而他们共同希望通向的,都是 AGI(通用人工智能),甚至更具体一些,就是具身智能和智能体。
理解这个观点的核心,是理解 OpenAI 为 Sora 赋予的使命,并不只是替代视频生成的创作者,而是将视频生成作为帮助 AI 理解真实世界的‘模拟器’。如果说特斯拉数以百万计的车辆仍然需要用‘肉身’感受这个世界,那么 Sora 则是单纯依靠数据的输入,建立起对世界的认知。

OpenAI 官网上,关于 Sora 的这篇研究论文名为《把视频生成模型作为世界模拟器》。请注意‘世界模拟器’(world simulators)这个关键词,它是比生成视频更关键的核心所在。
其实,早在特斯拉发布 FSD V12 的时候,这家以汽车为主要消费产品的人工智能公司,就已经展示了类似的能力。
如何理解呢?首先,在 FSD V12 上,工程师删除了超过 30 万行定义驾驶规则的代码,系统将从被‘投喂’的驾驶视频中,学习如何应对真实的驾驶场景,而不是向过往那样,按照写好的规则,在某个特定场景下执行某一个具体的命令。
当然,和作为‘生成式模型’的 Sora 不同,FSD 的目标是实现自动驾驶,所以它并不需要真正生成一个具体的视频。你可以想象成一个人(或者智能体)正在进行‘防御性驾驶’,基于过往经验,可以对周围环境中交通参与者的下一步移动趋势做出判断。这个判断存在在头脑里就行了,不需要真正把它画在纸上。因此,特斯拉的 FSD 也不需要把对未来的想象,生成为一个真实视频,并呈现在车辆的某一个屏幕上。
所以,现在有 OpenAI 和特斯拉两家完全不同的公司,用截然不同的方式和路径,实现‘通过视频生成,让 AI 理解物理世界’这个相同的目标。
简单了解一下 Sora 的运行逻辑:OpenAI 表示,Sora 结合了 Transformer 和 Diffusion 两个过去几年最重要的模型。ChatGPT、Gemini、LLaMA 等语言模式都是基于 Transformer 模型,它对词语进行标记,并生成下一个单词;Diffusion 模型则是‘文生图’的代表。
如果从‘理解世界’的角度来审视 Sora,那么某一帧图像的画质、画面关系绝不是模型质量高低的评判标准,甚至官网释出的 60 秒一镜到底视频也不是最核心的部分。重要的是这个生成的视频可以被剪辑——在不同的机位下,无论是广角、中景、近景、特写,视频中人物和背景的关系都保持着高度的‘一致性’。这才是 Sora 遥遥领先并接近真实的地方。

这一点和特斯拉在 FSD 上采取‘纯视觉’方案可以结合理解。简单来说,99% 的车企或者智驾团队都会在车辆上保留激光雷达,通过激光束的发射和接收,辅助计算周围物体和车辆间的距离关系。但马斯克不仅删除了 30 万行代码,还移除了雷达,只依靠高清摄像头采集和神经网络学习来判断距离关系。
无论是对特斯拉,还是对 OpenAI,这都是巨大的挑战。毕竟输入的画面是 2D 的,但输出的结果(无论是驾驶指令还是视频)都需要基于对 3D 世界的深刻理解。
规模和质量是训练模型的核心。特斯拉的数据来源于真实道路上,搭载了传感器的车辆;而 OpenAI 的大量数据,从目前的公开信息来看,来源于网络。在质量的维度,在《马斯克传》里,作者艾萨克森写道特斯拉通过和 Uber 合作,获取‘五星司机’的素材训练 FSD;而从规模出发,奥特曼最近希望筹集万亿规模的资金,就是重注算力和规模的具体体现。
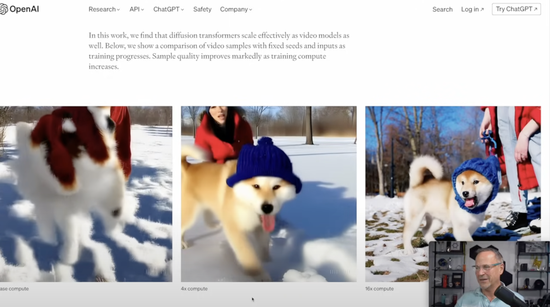
最后,回到一开始的那个问题,为什么我们会认为 Sora 和 FSD v12 是相似的?Sora 和 OpenAI 未来的想象空间又是什么呢?它们和 AGI 又有什么关系?
在马斯克看来,当人工智能可以真正解决一个问题(物理、数学、化学等等)的时候,AGI 就到来了。不过还有另外一个理解维度,那就是具身智能。毕竟现实世界里,并不是只有数学公式和文字规则,拥有一定的智商的小猫小狗也可以依靠运动真实地和物理世界进行互动。
这点对于过去只能输入二维信息的 AI 来说很难做到。这也是为什么马斯克看到 Sora 后在 X 上评价是‘GG Humans’,在他看来 Sora 今天做到的,已经打破了过去的次元壁,而能理解真实世界并继续学习,AI 也就有了更进一步影响真实世界的能力。
而就像特斯拉把这种生成能力用于训练车辆,Sora 的价值也不仅仅是生成一个难以让人区分真假的视频,用作影视创作者的生产力工具(尽管这是一个非常困难且刚需的场景)。就像周鸿祎所说,‘Sora 只是小试牛刀,它展现的不仅仅是一个视频制作的能力,而是大模型对真实世界有了理解和模拟之后,会带来新的成果和突破。’
*头图来源:《埃隆·马斯克传》

责任编辑:刘万里 SF014
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK