

Go 中如何高效遍历目录?探索几种方法
source link: https://www.51cto.com/article/781624.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

目录遍历是一个很常见的操作,它的使用场景有如文件目录查看(最典型的应用如 ls 命令)、文件系统清理、日志分析、项目构建等。
本文将尝试逐步介绍在 Go 中几种遍历目录文件的方法,从传统的 ioutil.ReadDir 函数开始,逐渐深入。
图片
文中也会提供示例代码、提供一些性能剖析,以便于大家更好地理解。
ioutil.ReadDir
首先,Go 中目录文件遍历的第一种方式是 ioutil.ReadDir 函数。
在 Go 1.16 版本前,ioutil.ReadDir 就是遍历目录的标准方法,它的返回结构是目录中文件的 FileInfo 列表,简单直接。
示例代码:
func main() {
files, err := ioutil.ReadDir(".")
if err != nil {
log.Fatal(err)
}
for _, f := range files {
fmt.Println(f.Name())
}
}但它的缺点也非常明显,性能不高。导致它的主要原因有如下几点:
这就导致了 ioutil.ReadDir 在返回结果前,会将目录下所有文件的信息完全加载到内存中。对于包含大量文件的目录,它就需要在内存中存储大量的 FileInfo 对象,毫无疑问,这会增加内存使用。
FileInfo 开销
由于是完全加载,每个 FileInfo 对象都包含了文件的详细信息,如文件名、大小、修改时间等都会在返回之前都已经加载完成。但获取这些信息需进行系统调用。而每个文件都要做这样的调用,当文件数量很多时,这些系统调用的累积开销可以变得不容忽视了。
无法分批处理
由于 ioutil.ReadDir 是一次性返回所有文件信息,没有提供分批处理的能力。无论目录中有多少文件,都要等待所有文件信息读取完成,这在处理目录中包含大量文件的场景中,也就无法提前并行处理,效率是可想而知的。
这一点其实和我们前面的一篇文章,介绍的 GO 中按行(或者说按块)读取文件的逻辑是类似的,一次加载全部内容,有潜在的性能问题。
由于 ioutil.ReadDir 有这么多的缺点,所以它在 Go 1.16 及更高版本已经被弃用了。
那现在我们该用什么方法呢?
os.ReadDir
从 Go 1.16 版本起,标准库针对目录遍历查看提供了新的函数 os.ReadDir,以用来简化和提高遍历目录文件的效率。
函数签名如下:
func ReadDir(name string) ([]DirEntry, error)os.ReadDir 函数返回一个按文件名排序的 DirEntry 类型切片。如果在读取目录项时遇到错误,它也会尽量返回已读取内容。这种设计同时兼顾了效率和错误处理的需要。
示例代码:
func main() {
files, err := os.ReadDir(".")
if err != nil {
log.Fatal(err)
}
for _, file := range files {
fmt.Println(file.Name())
}
}os.ReadDir 相比于旧方法 ioutil.ReadDir 的有什么优势?为什么丢弃 ioutil.ReadDir 而引入这个新的 os.ReadDir。
如果对比两者源码,会发现差异主要在返回的类型上。os.ReadDir 返回的 []DirEntry 而非 []FileInfo。它还具有性能优势。
因为 DirEntry 允许按需获取文件详情,即懒加载,而非是遍历目录时立即加载所有文件属性。很多场景下,我们并不需要
我在 MacOS 系统下测试的 DirEntry 接口的实际变量类型为 os.unixDirent。
它的源码如下:
func (d *unixDirent) Name() string { return d.name }
func (d *unixDirent) IsDir() bool { return d.typ.IsDir() }
func (d *unixDirent) Type() FileMode { return d.typ }
func (d *unixDirent) Info() (FileInfo, error) {
if d.info != nil {
return d.info, nil
}
return lstat(d.parent + "/" + d.name)
}我们只有在调用 Info 方法时,才会真正通过 lstat 发起系统调用。
如果你有将旧代码迁移到 DirEntry 的需求, Go 1.17 还引入了 fs.FileInfoToDirEntry 函数,允许我们将 FileInfo 对象转换为 DirEntry 对象。
info, _ := os.Stat("somefile")dirEntry := fs.FileInfoToDirEntry(info)
看到这,对于认真思考的朋友,或许已经发现我们还有一个问题没解决,即 os.ReadDir 不是也不支持分批处理的能力吗?
继续往下看吧,我将介绍一个更底层的方法。
os.File 的 ReadDir 方法
我们知道 os.Open 是用于打开文件的,但其实它也可用于打开目录。如果 os.Open 打开的是目录,我们在它返回的 os.File 上调用 ReadDir 以查看目录内容。
示例代码:
func main() {
dir, err := os.Open(".")
if err != nil {
log.Fatal(err)
}
defer dir.Close()
files, err := dir.ReadDir(-1)
if err != nil {
log.Fatal(err)
}
for _, file := range files {
fmt.Println(file.Name())
}
}如上的代码其实类似于 os.ReadDir 内容的实现代码。
os.ReadDir 源码如下:
func ReadDir(name string) ([]DirEntry, error) {
f, err := Open(name)
if err != nil {
return nil, err
}
defer f.Close()
dirs, err := f.ReadDir(-1)
sort.Slice(dirs, func(i, j int) bool { return dirs[i].Name() < dirs[j].Name() })
return dirs, err
}这种方法更底层,提供了更多的灵活性。我们就可以用它分批读取目标。
如何实现呢?
核心就是那句的 dir.ReadDir(-1),它的入参指定了每次读取文件的数量,而 -1 表示读取目录的所有内容。我们只要将 -1 改为分批读取的数量即可,多次循环即可。
示例代码:
func main() {
dir, err := os.Open(".")
if err != nil {
log.Fatal(err)
}
defer dir.Close()
for {
files, err := dir.ReadDir(10) // 每批读取10个条目
if err == io.EOF {
break // 遍历完成
}
if err != nil {
log.Fatal(err) // 处理其他错误
}
for _, file := range files {
fmt.Println(file.Name())
}
}
}这段代码演示了如何使用 File.ReadDir 分批处理目录中的文件。通过这种方式,可以更有效地管理内存使用。
在写这篇文章时,我发现 os.File 有两个查看目录的方法,分别是 Readdir 和 ReadDir。功能上的区别是新的 ReadDir 返回的是 []DirEntry,而 Readdir 返回的是 []FileInfo。
换句话说,ReadDir 本质上是 Readdir 的升级版。
它们的函数签名,如下所示:
func (f *File) Readdir(n int) ([]FileInfo, error)
func (f *File) ReadDir(n int) ([]DirEntry, error)这算是不支持可选参数和重载,但要解决兼容问题采取的措施吗?真的是蚌埠住了。
目录的递归遍历
现在,还差最后一个内容没有介绍,那就是递归目录遍历。
针对目录的递归遍历,Go 中提供了一个专门的函数,filepath.Walk。它可以遍历指定目录下的所有子目录。
示例代码:
func main() {
err := filepath.Walk(".", func(path string, info os.FileInfo, err error) error {
if err != nil {
return err
}
fmt.Println(path)
return nil
})
if err != nil {
fmt.Printf("error walking the path %v: %v\n", ".", err)
}
}我们通过遍历的回调函数中在处理每个文件。它简化了目录的递归遍历,但对于大型或深层次的目录结构,同样存在着提前加载 FileInfo 的问题。
针对这个问题,在 Go1.16 版本也引入了基于 DirEntry 版的 filepath.WalkDir 函数。
filepath.WalkDir 的函数签名如下:
func WalkDir(root string, fn fs.WalkDirFunc) errorfs.WalkDirFunc 的定义如下:
type WalkDirFunc func(path string, d DirEntry, err error) error新函数的遍历回调参数是 DirEntry,而非 FileInfo。现在,filepath.WalkDir 也有了延迟加载 FileInfo 的能力了。
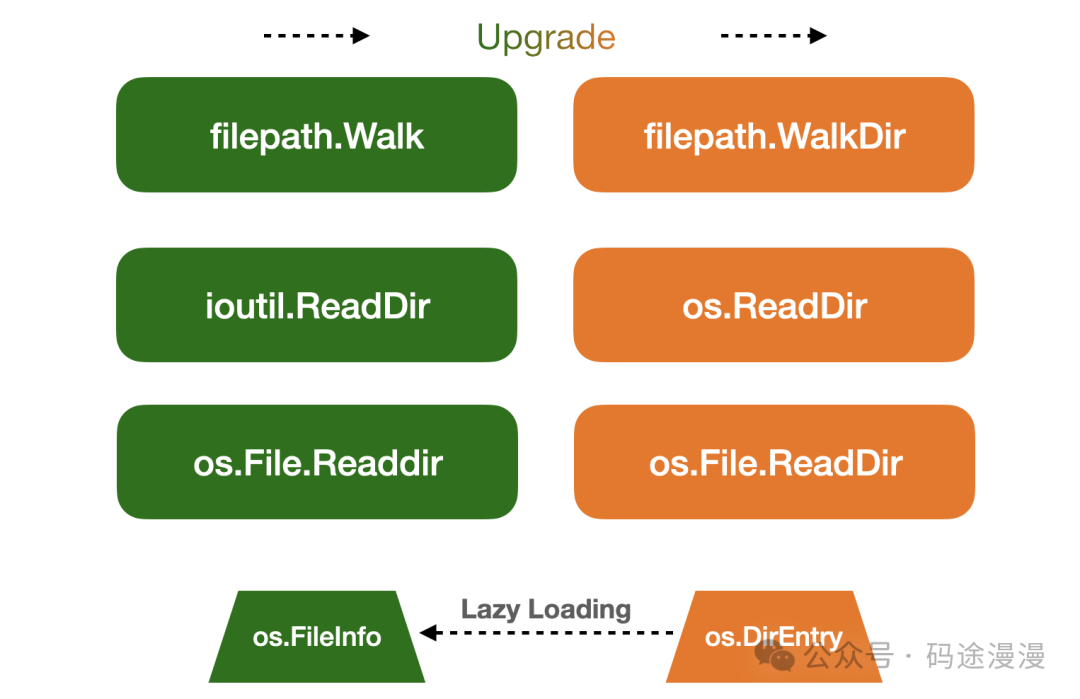
现在,我们再来看下这张图。
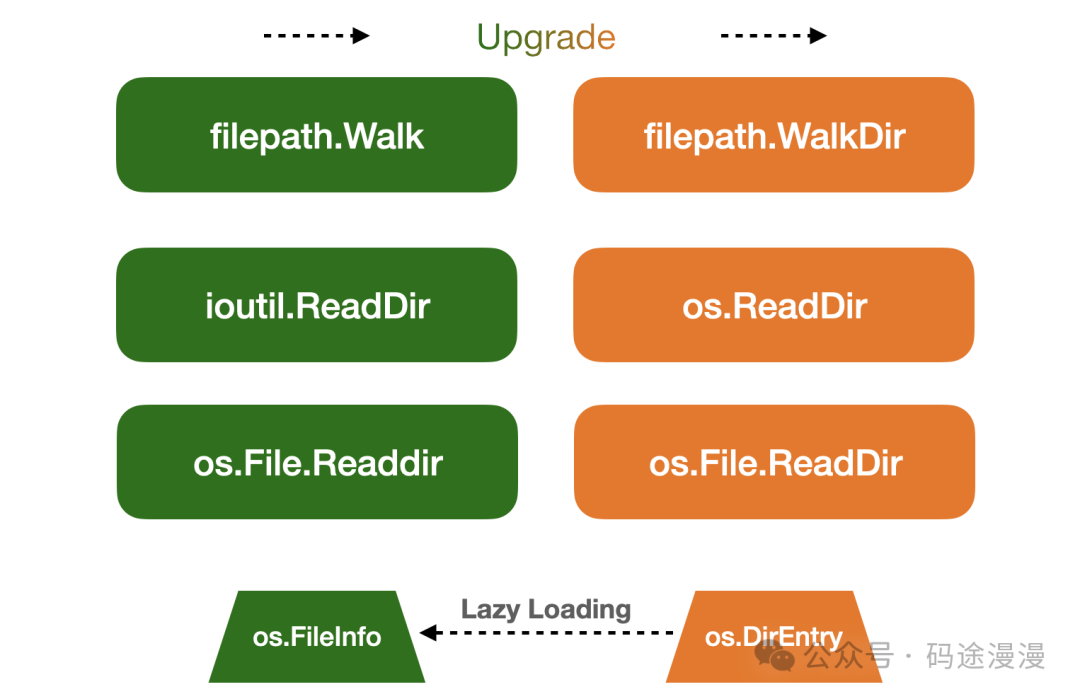
图片
在本文中,我们系统介绍了 Go 中多种遍历目录文件的方法。从传统的 ioutil.ReadDir,到 Go 1.16 引入的 os.ReadDir,os.File 的 ReadDir 方法。每种方法适用于不同的场景,如何选择要取决于你的需求、Go 版本、性能。如果你需要递归遍历,也可以使用基于 DirEntry 的 filepath.WalkDir 实现,提高遍历的性能。
[1] Go 中如何遍历目录?探索几种方法: https://www.poloxue.com/2024-02-22-list-directory-in-golang/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK