

Sora爆火,马斯克急了!"特斯拉才拥有最好的视频生成技术" | 量子位
source link: https://www.qbitai.com/2024/02/122045.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Sora爆火,马斯克急了!“特斯拉才拥有最好的视频生成技术”

FSD一年前就用上了
曹原 发自 副驾寺
智能车参考|公众号AI4Auto
这两天有没有被OpenAI的新成果Sora刷屏?
熙熙攘攘的龙年春节,人物众多,同时各有各的行为:

雨后的东京街头,光影和反射都处理得很到位:

甚至是超近景的蜥蜴,细节拉满:

以上均来自OpenAI首个视频生成模型Sora。
只要输入提示词,就能生成1分钟的高清视频,已经被看作是改写整个视频生成领域的新王炸技术。
这不仅轰动了学术圈,还让同为科技圈的老马坐不住了。
在推特上直言:特斯拉拥有世界上最好的现实世界模拟和视频生成能力!
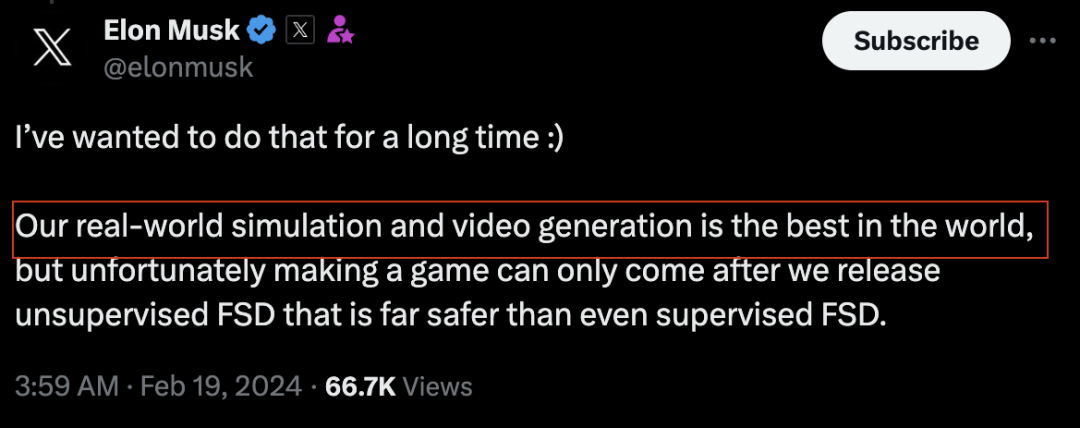
哎呦,打起来,打起来(doge)。
马斯克回应Sora
Sora发布后,效果立刻震惊全网。
不过并不像ChatGPT,现在只有少数人拥有Sora的访问权限。
但不少人还是想自己玩玩看的,所以OpenAI CEOSam Altman立刻抓住这次展示能力的机会,发布Sora后在推特上开始在线接单。
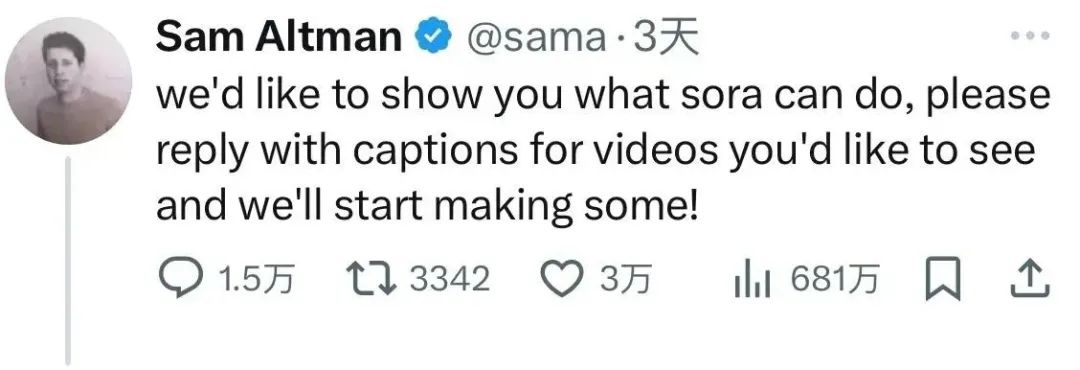
只要发布提示词并艾特Sam,或者在Sam的推特下回复,就有可能收到Sora生成好的视频。
这其中认真回复的有之,趁机捣乱的也有之。
狗狗币图形设计师DogeDesigner就回复了Sam的推特,他给的提示词是:
一个人把一家开源的非盈利公司变成闭源的盈利公司。
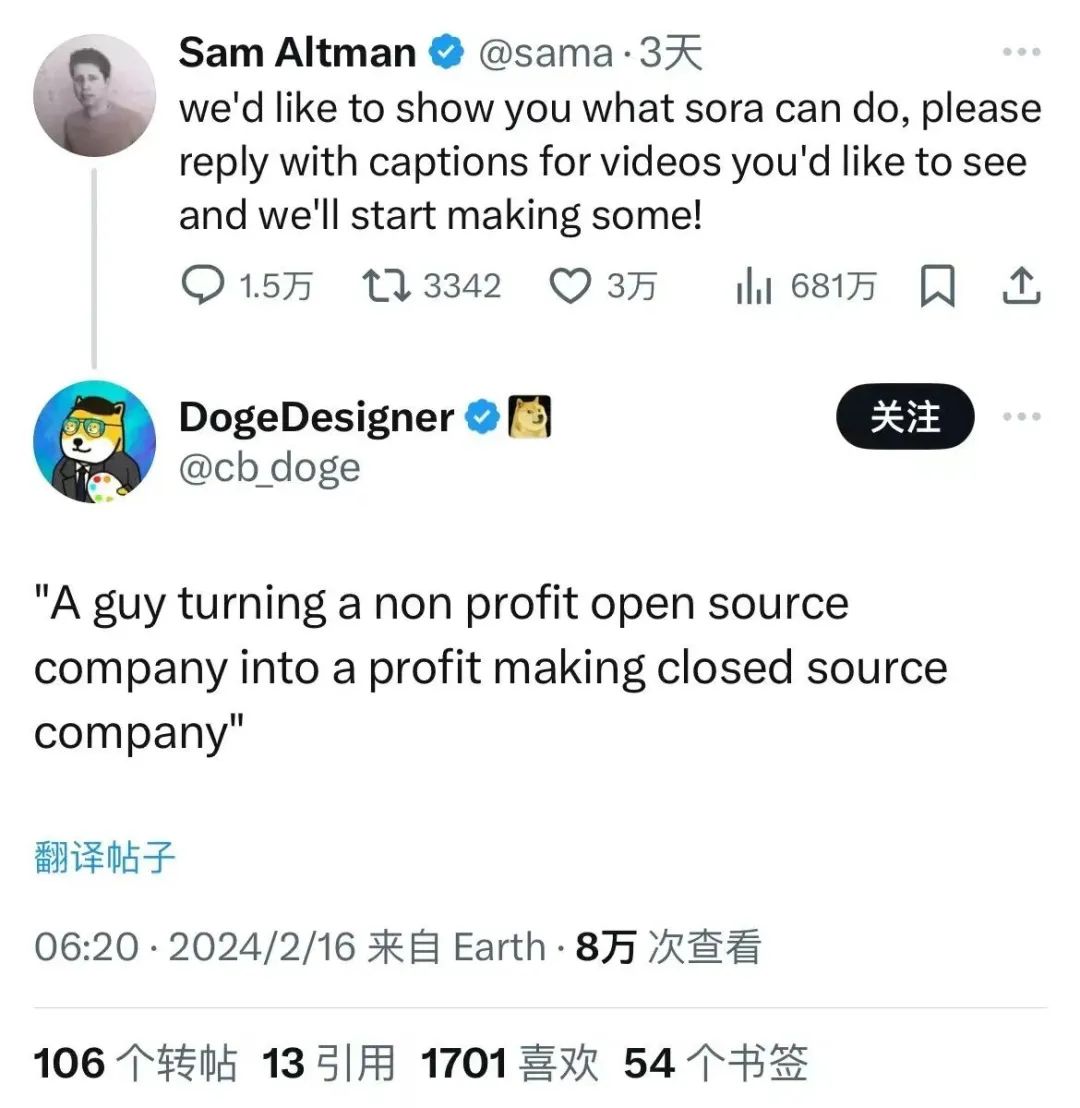
这描述,你要不直接报Sam身份证号得了(doge)。
而马斯克直接把这条回复po了出来。
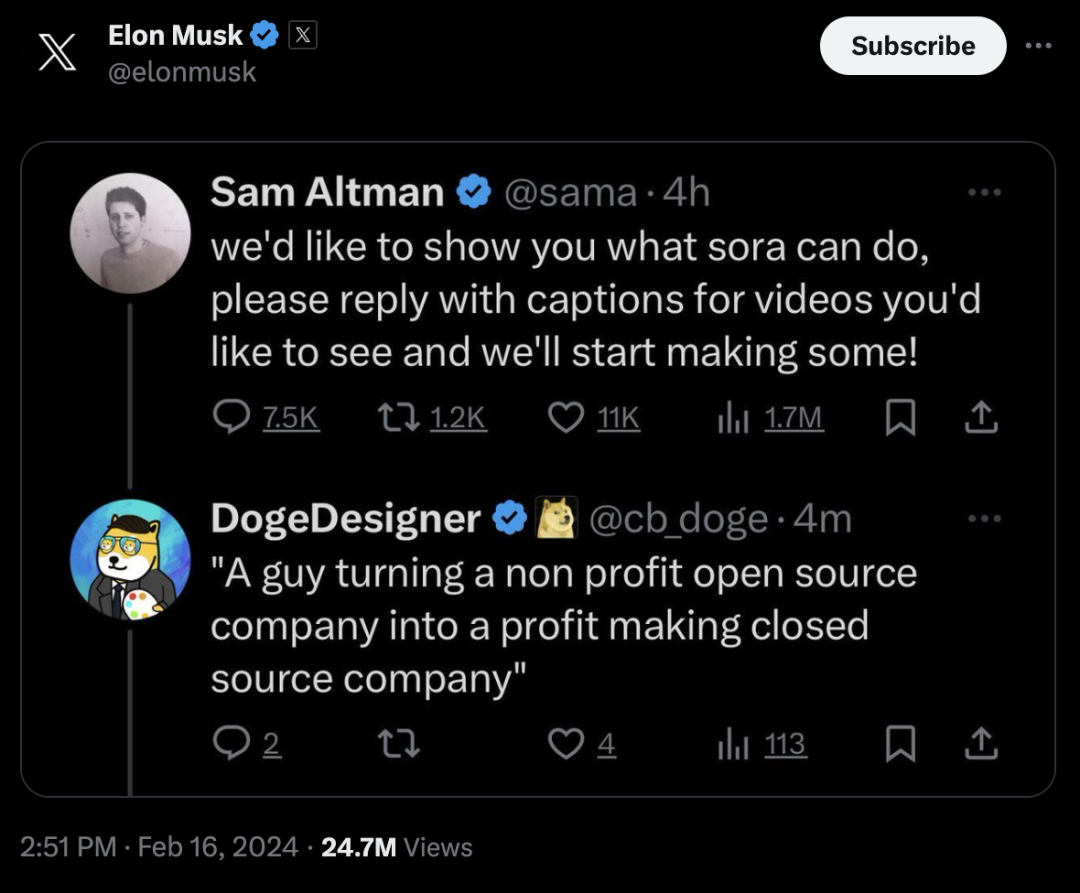
一方面他最爱的数字货币就是狗狗币,在推特上和这位用户也经常互动;而更重要的另一方面,马斯克和OpenAI有不少过节。
虽然马斯克是联合创始人,但后来被踢出了董事会,并且在OpenAI转变为盈利公司后,多次在公开场合批评和指责OpenAI失去初心,开始逐利。
随后,马斯克又转发了一条和OpenAI有关的内容,并配了个带单片眼镜的emoji表情,像是在疑惑。
这条内容是在说Sam拥有一家OpenAI的风险投资基金,这家基金截至去年已承诺投资1.75亿美元。
并且这家基金并没有由OpenAI来管理,只是“暂时”放在Sam的名下。
众所周知,Sam并不直接拥有OpenAI的股权,并且把自己通过YC基金对OpenAI投资的间接持有称为“不重要”,表示自己成立OpenAI就是因为喜欢AI。
而这则Sam拥有OpenAI风投基金的新闻曝出,马斯克又表示疑惑,可能想暗指Sam还是想要用OpenAI获利,并不是之前表现出“淡泊名利”的样子。
本以为马斯克嘲讽两条就结束了,谁知在有用户发布对比Sora和特斯拉FSD V12的推特后,马斯克又上线回复:
特斯拉大概在一年前就能生成真实世界的视频了,并且精准符合物理学。
但这并不是很有趣,因为所有的训练数据都来自汽车,所以视频也看起来像来自特斯拉车辆上的摄像头,尽管这是动态生成而不是记录下的世界。
那接下来就看看,Sora和特斯拉的能力对比到底如何?
Sora是什么
Sora,OpenAI的首个视频生成大模型,或者说是文生视频大模型。
本质上是一个扩散模型(Diffusion models),基于不同时长、分辨率和宽高比的视频和图像训练得来。
官方只浅浅介绍了一些技术细节,其中比较关键的有patch、潜(latent),以及训练路线上的选择。
对应语言大模型中的token,OpenAI创造了patch这一概念,模型可以将视频压缩进低维潜空间中,并分解为Spacetime latent patches,统一不同的视觉数据表现形式。
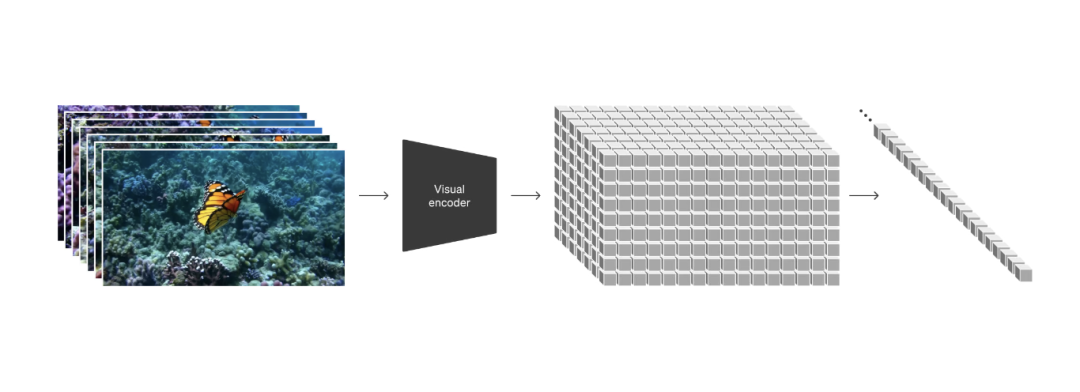
也就是说,正如token可以简化、统一不同的自然语言,patch可以统一不同分辨率、时长和宽高比的视频和图像。
而这个视频压缩网络也是OpenAI特意训练的,用来降低视觉数据维度,并且训练也是基于该网络进行,可以减少计算量的压力。
并且,由于Sora的训练直接在视频数据的原始尺寸上进行,和其他模型不同,所以在输出结果上,Sora也能hold住各种分辨率、时长、宽高比、视角等等的视频。

同时还优化了构图和布局。比如业内同类型模型都会盲目裁剪输出视频为正方形,造成主题元素只能部分展示,但Sora可以捕捉完整的场景。

另外,Sora的技术还包含OpenAI之前在DALL·E 3、扩散型Transformer方面的技术积累和突破。
最终展示出的Sora,就不仅能够理解提示词中的要求,还了解这些物体在物理世界中的存在方式。
能理解纸飞机在林中穿过时会发生碰撞,同时光影也会发生变化。
一群纸飞机在茂密的丛林中翩翩起舞,在树林中穿梭,就像候鸟一样。

同时在单个视频中创建多个镜头,并靠对语言的深入理解准确地解释提示词,保留角色和视觉风格。
美丽、白雪皑皑的东京熙熙攘攘。镜头穿过熙熙攘攘的城市街道,跟随几个人享受美丽的雪天并在附近的摊位购物。绚丽的樱花花瓣随着雪花随风飘扬。

不过,Sora现在并不完美。OpenAI指出它可能难以准确模拟复杂场景的物理原理,并且可能无法理解因果关系。
例如“五只灰狼幼崽在一条偏僻的碎石路上互相嬉戏、追逐”,狼的数量会变化,一些凭空出现或消失。
还可能混淆提示的空间细节,例如混淆左右,并且可能难以精确描述随着时间推移发生的事件,例如遵循特定的相机轨迹。
如提示词“篮球穿过篮筐然后爆炸”中,篮球没有正确被篮筐阻挡。
但这些缺点也没让各路大佬吝啬他们的赞美,比如纽约大学助理教授、ResNeXt一作谢赛宁直言,Sora将改写整个视频生成领域。
以上就是Sora当前展示出的能力,还有背后的技术,那么特斯拉的能力又如何?
特斯拉的视频生成能力
去年7月,特斯拉自动驾驶软件总监Ashok Elluswamy在CVPR2023的演讲中提到,特斯拉正在为其人工智能技术构建一个基础的世界模型(General World Model)。
根据他的介绍,该模型基于神经网络,使用过去的视频和其他事物为条件来预测未来。
该模型不仅能预测一个摄像头的视角,而是可以预测八个摄像头的视角(展示的是七个)。
比如对于同一段视频,该模型可以预测本车在“继续直行”和“向右变道”两种情况下,未来周围环境的演变。
这其实也就是一种基于文本生成不同视频的能力。
同时在不同摄像头视角之间,周围车辆的颜色可以保持一致,也就是符合3D物体移动的运动规律。
特斯拉这里还强调,我们并没有特意训练它在3D层面的能力,或者要求它表现出3D层面的能力,这意味着神经网络已经理解了深度、运动等物理概念。
并且,特斯拉的这个模型不局限于RGB数据维度,也可以是语义或者几何维度。
一句话总结就是,基于过去的视频,给出车辆行动提示,甚至不给提示,该模型可以预测不同的未来情况,以及生成视频。
那么既然特斯拉有了如此强大的模型,为什么之前并没有很多曝光度?
因为当时介绍时,Ashok直言这还是个“半成品”,关键是它可以提供一个神经网络模拟器,推演出不同的未来结果,跟踪道路中所有移动的物体。
并且,在马斯克这次展示自家视频生成能力时也坦言称,目前对于FSD训练的算力还不够,所以并没有用模型生成的视频进行训练。
不过马斯克也表示,特斯拉是可以训练的,在今年晚些时候,当公司有空余算力了就会开始。
到这里其实能看出特斯拉的世界模型和Sora之间的相似点,都是通过视觉让AI能够理解甚至模拟真实的物理世界。
只不过OpenAI在探索过程中,先放出Sora给世界带来一点AI震撼;而特斯拉把这个能力运用在了探索自动驾驶,通过纯视觉方案,以及视频数据训练出的端到端神经网络,FSD V12已经能比肩老司机。
所以FSD和Sora,不过是AI通过视觉认知世界理解世界上的两个开花结果,FSD最终用来行动,Sora则是用来生成视频。
殊途同归。
马斯克的认知,确实了不得。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK