

聊聊 Go 的边界检查消除技木
source link: https://colobu.com/2024/02/19/bce/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在翻译的从慢速到SIMD一文中, SourceGraph工程师其中的一个优化就是边界检查消除(BCE,bounds check elimination)技术,同时他也抛给了读者一个问题:
为啥在使用
a[i:i+4:i+4]而不是a[i:i+4]?
本文第一部分先回答这个问题。 第二部分介绍更好的边界检查消除方法。 第三部分再全面梳理Go的边界检查消除技术。
为啥在使用 a[i:i+4:i+4] 而不是 a[i:i+4]?
这篇文章发布到几个平台之后,很多Gopher都在问这个问题的答案,包括《100个Go语言典型错误》的作者也在twitter上询问,再比如Hacker News上的讨论,reddit。
当然,还每看过这篇文章的同学还不明白前因后果,这里我再简单介绍一下。SourceGraph工程师使用BCE做优化,他的代码如下,
func DotBCE(a, b []float32) float32 { if len(a) != len(b) { panic("slices must have equal lengths") if len(a)%4 != 0 { panic("slice length must be multiple of 4") sum := float32(0) for i := 0; i < len(a); i += 4 { aTmp := a[i : i+4 : i+4] // <--- 这里会做边界检查 bTmp := b[i : i+4 : i+4] // <--- 这里会做边界检查 s0 := aTmp[0] * bTmp[0] // <--- 这里不会做边界检查 s1 := aTmp[1] * bTmp[1] // <--- 这里不会做边界检查 s2 := aTmp[2] * bTmp[2] // <--- 这里不会做边界检查 s3 := aTmp[3] * bTmp[3] // <--- 这里不会做边界检查 sum += s0 + s1 + s2 + s3 return sum注意做边界检查的那两行,它们做了边界检查,新的slice的len和cap都是4,可以确保aTemp[0]、aTemp[3]、bTemp[0]、bTemp[3]不会越界,所以下面四行不用做边界检查了。不过边界检查少了很多的指令,可以提高性能。
我们怎么知道哪一行做了边界检查呢?可以使用下面的命令编译,会把做边界检查的行数打印出来。

可以看到结果和我们注释中的一样,只在第14、15行做了边界检查。
但是话锋一转,SourceGraph工程师突然问了一个问题:为啥这两行使用 a[i:i+4:i+4] 而不是 a[i:i+4]?
难道a[i:i+4]会导致下面四行做边界检查吗?这个问题让很多人都很好奇,几个论坛上没有答案。我翻译的文章评论中也有小伙伴问这个问题。
首先,我们修改为a[i:i+4],然后编译,看看结果:
没什么区别,还是在第14、15行做了边界检查,接下来四行做了边界检查消除,不一样么?
这个问题 Go101 老貘 在Twitter上提了一下,没有展开讲,购买了他的书的同学可以看看那一章:
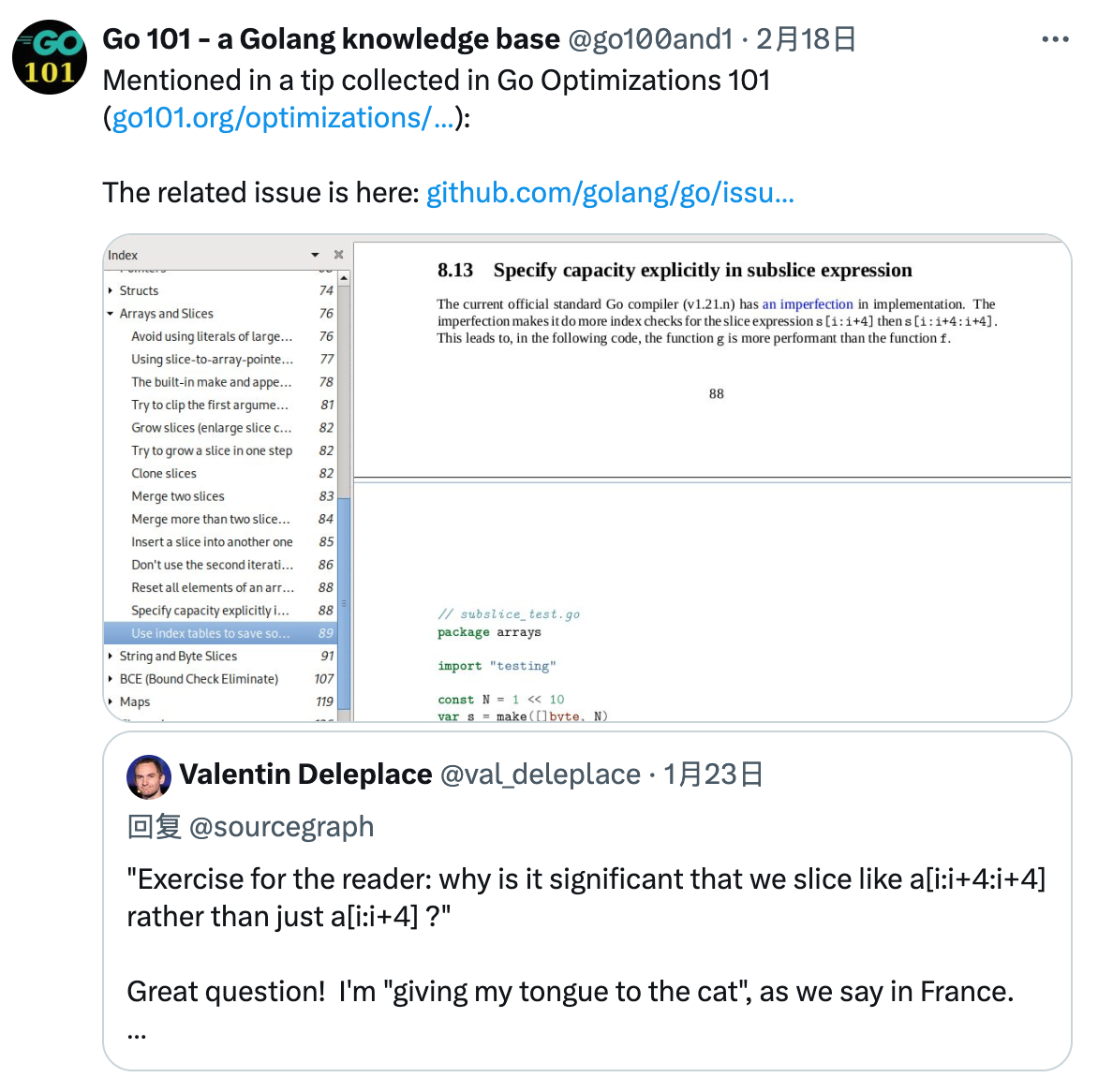
接下来我从最开始的讨论讲起,那还得从2018年的秋天的一个提交讲起。
不想看历史的同学可以直接跳过去,结论就是:这样写不是为了边界检查消除,而是为了性能。
这是一次对image/draw: optimize bounds checks in loops做边界检查的优化:
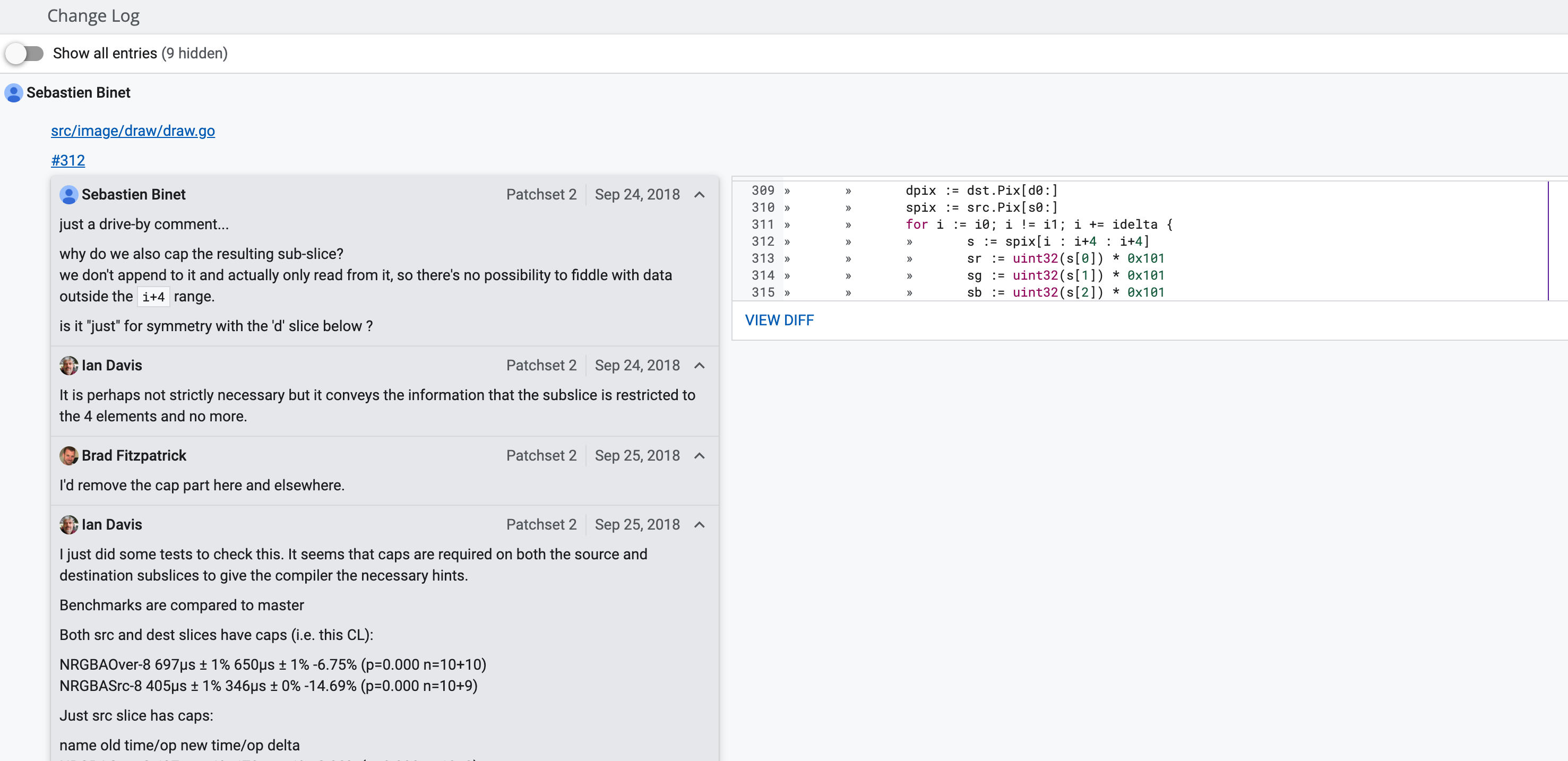
其中有一行s := spix[i : i+4 : i+4],Sebastien Binet提出一个疑问,为啥这里要设置cap? Brad Fitzpatrick就说那我移除好了,作者Ian Davis说我做了测试,感觉设置cap会给编译器提示,性能更好。大家就对这个奇怪的点展开了有趣的讨论,Ian Davis说如果改成s := spix[i : i+4]虽然对边界检查没有影响,但是性能会下降。Giovanni Bajo给出了正解:
If you don't specify the cap, the compiler needs to calculate it computing newcap = oldcap - offset. If you specify it with the same value of len, it does less work.
翻译:如果你不指定cap,编译器需要计算新的
newcap = oldcap - offset。如果你指定cap的值和len一样,编译器就可以少做点工作。
Nigel Tao也指出,这行代码也可以使用_ = spix[i+3]代替。
最终这个讨论记录在#27857。
回答SourceGraph工程师的问题:为啥在使用 a[i:i+4:i+4] 而不是 a[i:i+4]?
答案是为了更好的性能,而不是为了边界检查消除。
更好的边界检查消除方法
SourceGraph工程师的代码使用BCE做了优化,但是你还是看到,有两行代码还是做了边界检查,这是因为Go的BCE并不完美,有时候还是会做边界检查。
但是有没有办法全部消除代码的边界检查呢?老貘还是给出了一个解决方案。
我们先看看老貘的给出的例子(f8z我略有改动):
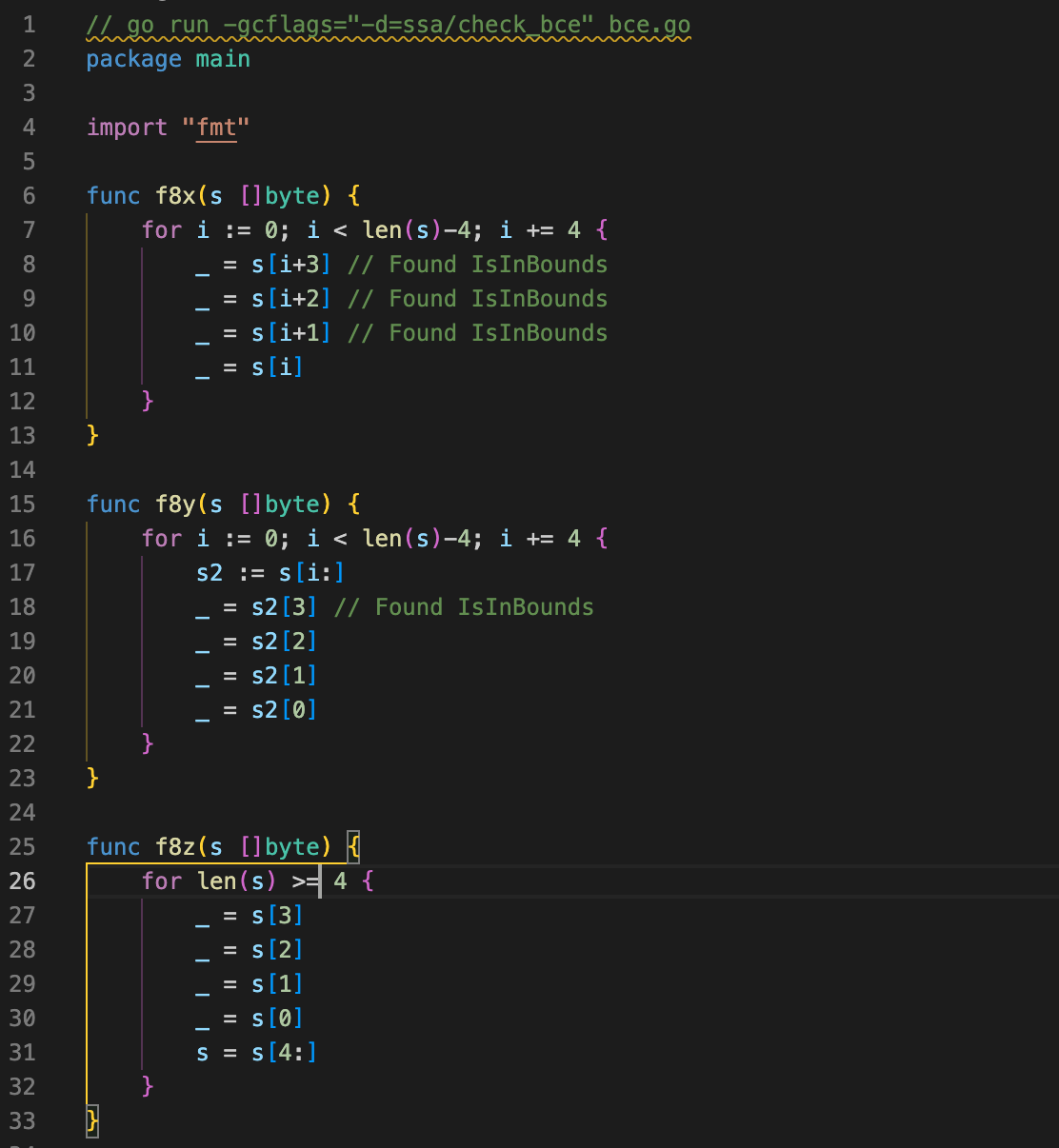
可以看到,Go的BCE还不是那么智能,f8x例子中s[i+3]、s[i+2]、s[i+1]不会越界,但是这三行还是做了边界检查。
f8y例子中s[3]做了边界检查后,可以保证s[2]、s[1]、s[0]不会越界,所以这三行不用做边界检查。
f8z例子中,每次循环我们都会检查s的长度是否大于4,如果大于4,s[3]、s[2]、s[1]、s[0]肯定不会越界,所以这四行不做边界检查,而且s = s[4:]也不会越界。这样这个实现就整体都不需要做边界检查了
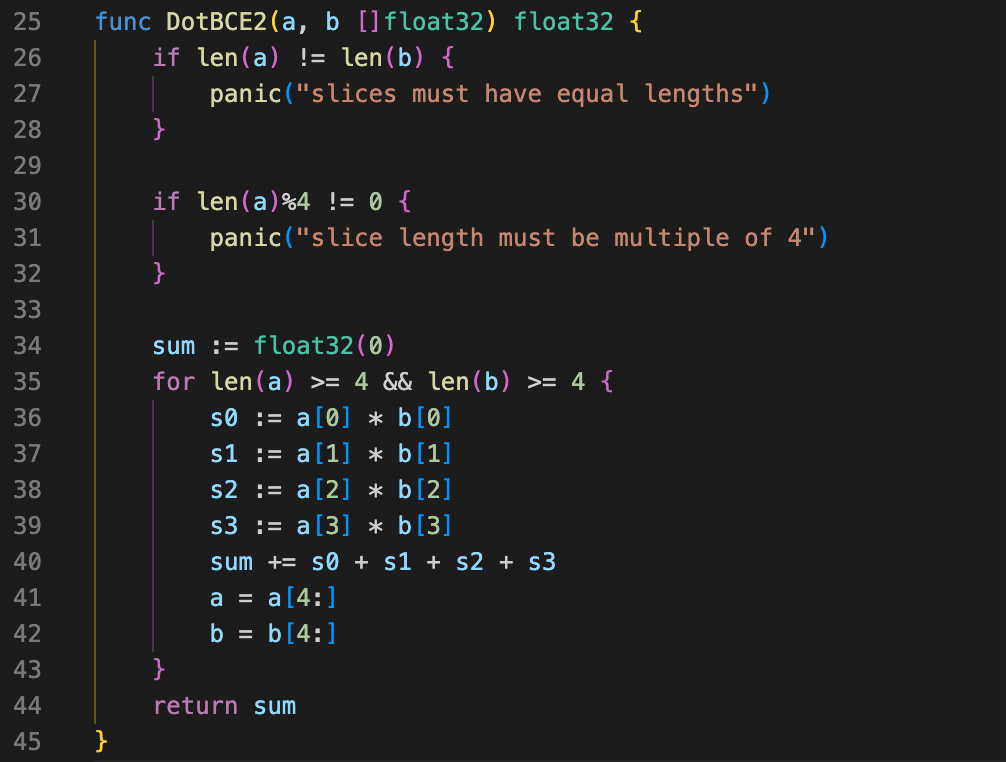
所以SourceGraph工程师的代码可以改成下面这样:
Go的边界检查消除技术
老貘在Go101中有一章专门讲了这个问题,感兴趣的同学可以直接阅读,或者购买他的电子书。
我想从Go实现边界检查消除的提议说起,这个提议是cmd/compile: unnecessary bounds checks are not removed #14808。
当然BCE在Go的编译器中也一直做优化,原始的文档整理也不能全面反映现状,但是还是很有意义的,整理的BCE技术进行分类便于学习。我就整理翻译一下。
Go的边界检查有两个:索引a[i]和slicea[i,j]。Go编译器在访问这两种方式的时候会插入一些边界检查代码,但是大部分情况下是不需要的,冗余的,我们的目标就是在编译的时候去掉这些冗余的检查,这样能提供性能,检查二进制文件大小。通过-gcflags=-B可以禁止边界检查。
你可以通过go build -gcflags="-d=ssa/check_bce" xxx.go查看哪些行进行了边界检查。
下面是一些进行边界检查消除的场景。
比如下面的代码中,重复的索引和切片访问就不做边界检查了。
var a []int_ = a[i] // 边界检查_ = a[i] // 重复访问,消除边界检查_ = a[2*i+7] // 边界检查_ = a[2*i+7] // 重复访问,消除边界检查var a []int_ = a[:i]_ = a[:i] // 重复访问,消除边界检查var a []int_ = a[i:]_ = a[i:] // 重复访问,消除边界检查带掩码索引的恒定切片大小
var a[17]int_ = a[i&5] // 0 <= i&5 and i&5 <= 5 < 17 == len(a), 移除边界检查_ = a[i%5] // 不能移除, 因为i可能是负数, 负数就越界了var a[]intif 5 < len(a) { _ = a[5] } // 0 <= 5 and 5 < len(a), 移除边界检查这也是上一节我们完全消除边界检查的方式。
常数索引和常数size
var a[10]int_ = a[5] // 0 <= 5 and 5 < len(a) == 10, 移除边界检查琐碎的边界检查
a[i:j] 会产生两个边界检查: 0 <= i <= j 和 0 <= j <= cap(a)。有时候我们可以移除它们中的一个。
var a[]inta[i:len(a)] // 第二个边界检查 0 <= len(a) <= cap(a) 移除了var a[]inta[:len(a)>>1] // 第一个边界检查移除了 0 <= 0 <= len(a)>>1, 因为 len(a)>>1 >= 0var a[]inta[:len(b)] // 第一个边界检查 0 <= 0 <= len(a) 移除了基于循环变量的边界检查
var a[]int for i := range a { // 不适用于string use a[i] // 移除, i 循环变量 use a[i:] // 移除 use a[:i] // 移除var a []int for i := 0; i < len(a); i++ { // 也适用于string use a[i] // 移除, i 循环变量 use a[i:] // 移除 use a[:i] // 移除var a[]int for i := range a { // 不适用于string use a[:i+1] // 移除, i 循环变量 use a[i+1:] // 移除递减常量索引
var a[]int_ = a[3] // 一次边界检查use a[1], a[2], a[3] // 不需要边界检查a = a[:3:len(a)] // 一次边界检查use a[0], a[1], a[2] // 不需要边界检查use a[3], a[2], a[1] // 一次边界检查if len(a) >= 3 { use a[0], a[1], a[2] // 一次边界检查不能移除的边界检查
下面这个k8x中第一个a[i]中i可能为负数,所以不能移除,接下来的两个可以确保不越界,所以可以移除。
func k8x(a []int, i int, j uint) { if i < len(a) { _ = a[i] // 不能移除,因为i可能为负数 if j < uint(len(a)) { _ = a[j] // 移除,因为 0 <= j < len(a) if 0 <= i && i < len(a) { _ = a[i] // 移除,因为 0 <= i < len(a)下面这个k8y中i+2可能溢出,比如i = math.MaxInt, 所以不能移除。
func k8y(a []int, i int) { if 0 <= i && i+2 < len(a) { _ = a[i+2] // i+2 might overflow int这个文档中有几处场景已经BCE已经完善了,我更正过来了,如上。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK