

提高Java开发生产力,我选Stream API,真香啊 - 码农Academy
source link: https://www.cnblogs.com/coderacademy/p/18020463
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Java 8 引入的Stream API提供了一种新的数据处理方式,它以声明式、函数式的编程模型,极大地简化了对集合、数组或其他支持数据源的操作。Stream可以被看作是一系列元素的流水线。允许你高效地对大量数据执行复杂的过滤、映射、排序、聚合等操作,而无需显式地使用循环或者临时变量。Stream API的设计理念主要包括两个方面:链式调用和惰性求值。链式调用允许我们将多个操作连接在一起,形成一个流水线,而惰性求值意味着只有在真正需要结果的时候才执行计算,从而避免了不必要的计算开销。
接下来我们就来盘点一下日常开发中常用的一些Stream API。
创建Stream
- 集合创建
List<String> list = new ArrayList<>();
// 串行流
Stream<String> stream = list.stream();
// 并行流
Stream<String> parallelStream = list.parallelStream();
- 数组创建
String[] strs = new String[3];
Stream<String> stream = Arrays.stream(strs);
- 使用
Stream.of(T...values)创建
Stream<String> stream = Stream.of("Apple", "Orange", "Banana");
- 使用Stream.generate()创建流
// 生成一个无限流,通过limit()限制元素个数
Stream<Double> randomStream = Stream.generate(Math::random).limit(5);
- 使用Stream.iterate()创建流
// 生成一个等差数列,通过limit()限制元素个数
Stream<Integer> integerStream = Stream.iterate(0, n -> n + 2).limit(5);
- 使用IntStream、LongStream、DoubleStream创建原始类型流
// 使用IntStream创建
IntStream intStream = IntStream.range(1, 5); // [1, 2, 3, 4]
// 使用LongStream创建
LongStream longStream = LongStream.rangeClosed(1, 5); // [1, 2, 3, 4, 5]
IntStream我们使用的地方还是比较多的,比如我们按照下标遍历一个集合时,同常的做法是:for(int i = 0; i < list.size(); i++){},我们可以使用IntStream去改造一下,IntStream.rangeClosed(0, list.size()).forEach();
中间操作是构建流水线的一部分,用于对流进行转换和处理,但它们并不会触发实际的计算。
- 过滤操作(filter)
过滤操作用于筛选流中的元素,保留满足指定条件的元素。Stream<T> filter(Predicate<? super T> predicate),filter接受一个谓词Predicate,我们可以通过这个谓词定义筛选条件,Predicate是一个函数式接口,其包含一个test(T t)方法,该方法返回boolean。
private static void filterTest(){
List<String> fruits = Arrays.asList("apple", "banana", "orange", "grape");
// 过滤长度大于5的水果
List<String> filteredFruits = fruits.stream().filter(fruit -> fruit.length() > 5).collect(Collectors.toList());
System.out.println("长度大于5的水果: "+ filteredFruits);
}
private static void filterTest(List<Student> students){
List<Student> filterStudents = students.stream()
.filter(student -> Objects.equals("武汉大学", student.getSchool()))
.collect(Collectors.toList());
filterStudents.forEach(System.out::println);
}
打印结果:
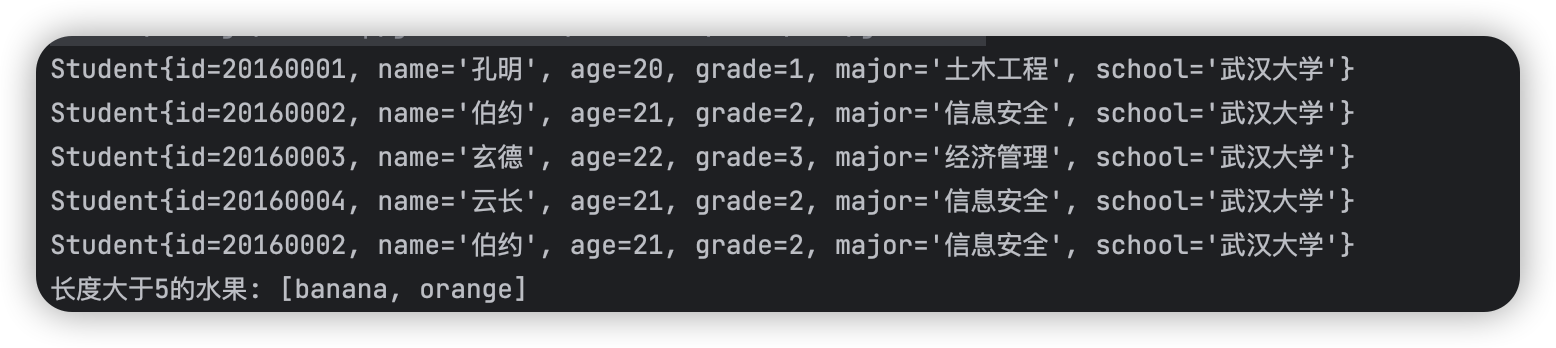
- 映射操作(map/flatMap)
映射操作用于对流中的每个元素进行转换。他有map以及flatMap两种操作。map就是基本的映射操作,对每个元素进行提取转换。
// 将实体层映射成学生姓名字符串
List<String> names = students.stream()
.map(Student::getName)
.collect(Collectors.toList());
// 将字符串转大写。
List<String> upperList = Lists.newArrayList("hello", "world", "stream", "api").stream().map(String::toUpperCase).collect(Collectors.toList());
日常开发中map操作我们用的非常多,比如数据库中查询出来的DO实体,我们需要转换为VO返回给前端页面展示,这时候我们可以使用map进行转换操作:
List<StudentDO> studentDOList = studentMapper.listStudents();
List<StudentVO> studentVOList = studentDOList.stream().map(studentDO -> {
StudentVO studentVO = StudentVO.builder().studentNo(studentDO.getId())
.studentName(studentDO.getName()).build();
return studentVO;
}).collect(Collectors.toList());
而flatMap的作用略微特殊,它用于将一个元素映射为一个流,然后将所有流连接成一个流。这在处理嵌套结构或集合中的元素是另一个集合的情况下非常有用。
List<List<String>> nestedWords = Arrays.asList(
Arrays.asList("Java", "Kotlin"),
Arrays.asList("Python", "Ruby"),
Arrays.asList("JavaScript", "TypeScript")
);
// 使用 flatMap 将嵌套的 List<String> 转换为一个扁平的 List<String>, 结果将是包含所有单词的扁平流
List<String> wordList = nestedWords.stream()
.flatMap(List::stream).collect(Collectors.toList());
System.out.println(wordList);
// 打印结果: [Java, Kotlin, Python, Ruby, JavaScript, TypeScript]
flatMap在使用时,通常会涉及到处理复杂的数据结构,比如处理嵌套的对象集合或者进行数据的扁平化。
@Data
@Builder
class Student {
private String name;
private List<Integer> grades;
}
@Data
@Builder
class ClassRoom {
private List<Student> studentList;
}
@Data
@Builder
class School {
private List<ClassRoom> classRoomList;
}
School school = School.builder()
.classRoomList(Lists.newArrayList(
ClassRoom.builder().studentList(Lists.newArrayList(
Student.builder().name("Alice").gradeList(Lists.newArrayList(90, 85, 88)).build(),
Student.builder().name("Bob").gradeList(Lists.newArrayList(78, 92, 80)).build()
)).build(),
ClassRoom.builder().studentList(Lists.newArrayList(
Student.builder().name("Charlie").gradeList(Lists.newArrayList(95, 89, 91)).build(),
Student.builder().name("David").gradeList(Lists.newArrayList(82, 87, 79)).build()
)).build()
))
.build();
// 使用 flatMap 扁平化处理获取所有学生的所有课程成绩
List<Integer> allGrades = school.getClassRoomList().stream()
.flatMap(classroom -> classroom.getStudentList().stream())
.flatMap(student -> student.getGradeList().stream())
.collect(Collectors.toList());
System.out.println(allGrades);
// 打印结果:[90, 85, 88, 78, 92, 80, 95, 89, 91, 82, 87, 79]
- mapToInt操作
mapToInt是 Stream API 中的一种映射操作,专门用于将元素映射为IntStream。通过mapToInt,你可以将流中的元素映射为int类型,从而进行更专门化的操作,例如数值计算。
int totalAge2 = students.stream().mapToInt(Student::getAge).sum();
类似的还有mapToLong和mapToDouble 操作,这两个操作类似于 mapToInt,分别用于将流中的元素映射为 LongStream 和 DoubleStream。
- 排序操作(sorted)
排序操作用于对流中的元素进行排序。
List<String> cities = Lists.newArrayList("New York", "Tokyo", "London", "Paris");
// 对城市按字母顺序排序
List<String> sortedStream = cities.stream().sorted().collect(Collectors.toList());
对于集合中对象的排序,sorted要求待比较的元素必须实现Comparable接口。
@Data
@Builder
static class Student implements Comparable<Student>{
private String name;
private Integer age;
@Override
public int compareTo(Student other) {
return other.getAge()-this.getAge();
}
}
List<String> sortedList = students.stream()
.sorted()
.map(Student::getName())
.collect(Collectors.toList());
如果没有实现,就需要将比较器作为参数传递给sorted(Comparator<? super T> comparator)。
@Data
@Builder
static class Student {
private String name;
private Integer age;
}
List<String> sortedList = students.stream()
.sorted((student1,student2) -> student2.getAge() - student1.getAge())
.map(Student::getName())
.collect(Collectors.toList());
- 去重操作(distinct)
去重操作用于去除流中的重复元素。distinct基于Object.equals(Object)实现。
List<Integer> numbers = Lists.newArrayList(1, 2, 3, 2, 4, 5, 3, 6);
// 去除重复的数字
List<Integer> distinctList = numbers.stream().distinct().collect(Collectors.toList());
// 或者去除学生中姓名相同的
List<String> studentNameList = students.stream()
.map(Student::getName())
.distinct()
.collect(Collectors.toList());
- 截断操作(limit)
截断操作用于限制流中元素的数量。limit返回包含前n个元素的流,当集合大小小于n时,则返回实际长度。
List<Integer> numbers = Lists.newArrayList(1, 2, 3, 2, 4, 5, 3, 6);
// 只取前三个数字
List<Integer> limitedList = numbers.stream().limit(3).collect(Collectors.toList());
// 取土工工程专业的年龄最小的前两名学生
List<Student> limitStu = students.stream()
.filter(student -> Objects.equals("土木工程", student.getMajor()))
.sorted((student1,student2) -> student2.getAge() - student1.getAge())
.limit(2)
.collect(Collectors.toList());
- 跳过操作(skip)
跳过操作用于跳过流中的前几个元素,返回由后面所有元素构造的流,如果n大于满足条件的集合的长度,则会返回一个空的集合。作用上跟limit相反。
List<Integer> numbers = Lists.newArrayList(1, 2, 3, 2, 4, 5, 3, 6);
// 跳过前三个数字,返回后面的数字
List<Integer> limitedList = numbers.stream().skip(3).collect(Collectors.toList());
// 跳过土工工程专业的年龄最小的前两名学生,取后面的学生
List<Student> limitStu = students.stream()
.filter(student -> Objects.equals("土木工程", student.getMajor()))
.sorted((student1,student2) -> student2.getAge() - student1.getAge())
.skip(2)
.collect(Collectors.toList());
- peek操作
peek方法对每个元素执行操作并返回一个新的 Stream。peek的主要目的是用于调试和观察流中的元素,通常用于打印调试信息、记录日志或其他类似的目的,而不会改变流中元素的结构。
List<String> words = Arrays.asList("apple", "banana", "orange", "grape");
List<String> modifiedWords = words.stream()
.filter(word -> word.length() > 5)
.peek(word -> System.out.println("Filtered Word: " + word))
.map(String::toUpperCase)
.peek(word -> System.out.println("Uppercase Word: " + word))
.collect(Collectors.toList());
Stream的终端操作
终端操作是对流进行最终计算的操作,执行终端操作后,流将被消耗,不能再被使用。
- 迭代forEach操作
forEach迭代操作,用于对流中的每个元素执行指定的操作。
List<String> fruits = Arrays.asList("apple", "banana", "orange", "grape");
// 使用 forEach 输出每个水果
fruits.stream().forEach(fruit -> System.out.println(fruit));
// 执行forEach时可省略 stream(),即
fruits.forEach(fruit -> System.out.println(fruit));
// 或
fruits.stream().forEach(System.out::println);
- 收集操作(collect)
通过collect()方法结合java.util.stream.Collectors工具类将Stream转换为另一种形式,例如列表、集合(toList, toSet, toMap)、映射或归约结果。如上述示例中的:
- 收集到List
使用Collectors.toList()。
// 跳过土工工程专业的年龄最小的前两名学生,取后面的学生
List<Student> limitStu = students.stream()
.filter(student -> Objects.equals("土木工程", student.getMajor()))
.sorted((student1,student2) -> student2.getAge() - student1.getAge())
.skip(2)
.collect(Collectors.toList());
- 收集到Set
使用Collectors.toSet()。
// 将学生姓名收集到Set
Set<String> studentNameSet = students.stream().map(Student::getName)
.collect(Collectors.toSet());
- List转Map
使用Collectors.toMap。日常开发中使用很多。
// 转换为年龄对应的学生信息
Map<Integer, Student> studentMap = students.stream().collect(Collectors.toMap(
Student::getAge,
Function.identity(),
(e1,e2) -> e1));
这段代码代表,我们使用年龄作为Map的key,对应学生信息作为value。Function.identity():这是一个提取元素自身的映射函数。(e1, e2) -> e1:这是一个合并冲突的操作。如果在流中存在相同的年龄(相同的键),这个函数定义了当出现重复键时应该如何处理。在这里,我们选择保留第一个出现的元素,即保留先出现的 Student 对象。当然我们还可以这样(e1, e2) -> {...}自定义合并冲突策略,例如:
// 转换为年龄对应的学生信息,如果年龄相同,则取名字较长的
Map<Integer, Student> studentMap = students.stream().collect(Collectors.toMap(Student::getAge, Function.identity(), (e1,e2) -> {
return e1.getName().length() > e2.getName().length() ? e1 : e2;
}));
如果value的值是一些number,我们也可以做一些加减乘除之类的合并。
日常开发中,这个用法很频繁。
- 字符串拼接:
使用Collectors.joining(拼接符)。
List<Student> students = Lists.newArrayList(
Student.builder().name("Alice").gradeList(Lists.newArrayList(90, 85, 88)).build(),
Student.builder().name("Bob").gradeList(Lists.newArrayList(78, 92, 80)).build()
);
String studentName = students.stream().map(Student::getName).collect(Collectors.joining(","));
// 打印出来:Alice,Bob
- 分组
即按照集合中的元素的某个属性进行分组,转换为Map<Object, List<Object>>:
List<String> fruits = Arrays.asList("apple", "banana", "orange", "grape");
Map<Integer, List<String>> lengthToNamesMap = fruits.stream()
.collect(Collectors.groupingBy(String::length));
// 按照年龄分组
Map<Integer, List<Student>> studentMap = students.stream().collect(Collectors.groupingBy(Student::getAge));
// 连续进行分组
Map<String,Map<String,List<Student>>> groupsStudent = students.stream()
// 先按照学校分组
.collect(Collectors.groupingBy(Student::getSchool
// 再按照专业分组
,Collectors.groupingBy(Student::getMajor)));
- counting()
counting()收集器用于计算流中元素的数量。等同于Stream的count()操作。
long studentCount = students.stream().collect(Collectors.counting());
// 效果同等于
long studentCount = students.stream().count();
- maxBy()
maxBy()基于指定的比较器,用于找到流中的最大的元素。等同于Stream的max操作
// 年龄最大的学生
Student olderStudent = students.stream()
.collect(Collectors.maxBy((s1,s2) -> s1.getAge()- s2.getAge())).orElse(null);
Student olderStudent2 = students.stream()
.collect(Collectors.maxBy(Comparator.comparing(Student::getAge))).orElse(null);
// 等价于stram的max
Student olderStudent = students.stream()
.max(Comparator.comparing(Student::getAge)).orElse(null);
- minBy()
minBy()基于指定的比较器,用于找到流中的最小的元素。等同于Stream的min操作。
// 年龄最小的学生
Student youngStudent = students.stream()
.collect(Collectors.minBy(Comparator.comparing(Student::getAge))).orElse(null);
Student youngStudent = students.stream()
.min(Comparator.comparing(Student::getAge)).orElse(null);
- averagingInt
averagingInt()收集器用于计算流中元素的平均值。
// 求学生平均年龄
double avgAge = students.stream()
.collect(Collectors.averagingInt(Student::getAge));
- summarizingInt()
summarizingInt()收集器用于计算流中元素的汇总统计信息,包括总数、平均值、最大值和最小值。
// 一次性得到元素个数、总和、均值、最大值、最小值
IntSummaryStatistics summaryStatistics = students.stream().collect(Collectors.summarizingInt(Student::getAge));
System.out.println("总数:" + summaryStatistics.getCount());
System.out.println("平均值:" + summaryStatistics.getAverage());
System.out.println("最大值:" + summaryStatistics.getMax());
System.out.println("最小值:" + summaryStatistics.getMin());
- partitioningBy()
将流中的元素按照指定的条件分成两个部分。在分区中key只有两种情况:true或false,目的是将待分区集合按照条件一分为二,分区相对分组的优势在于,我们可以同时得到两类结果,在一些应用场景下可以一步得到我们需要的所有结果,比如将数组分为奇数和偶数。
// 分为武汉大学学生,非武汉大学学生
Map<Boolean,List<Student>> partStudent = students.stream()
.collect(Collectors.partitioningBy(student -> Objects.equals("武汉大学",student.getSchool())));
- count操作
count用于计算流中的元素个数。效果等同于Collectors.counting()。
long studentCount = students.stream().count();
// 效果同等于
long studentCount = students.stream().collect(Collectors.counting());
- max操作
基于指定比较器,max用于找到流中最大的元素。效果等同于Collectors.maxBy()。
Student olderStudent = students.stream()
.max(Comparator.comparing(Student::getAge)).orElse(null);
Student olderStudent2 = students.stream()
.collect(Collectors.maxBy(Comparator.comparing(Student::getAge))).orElse(null);
- min操作
基于指定比较器,min用于找到流中最小的元素。效果等同于Collectors.minBy()。
Student youngStudent = students.stream()
.min(Comparator.comparing(Student::getAge)).orElse(null);
// 年龄最小的学生
Student youngStudent = students.stream()
.collect(Collectors.minBy(Comparator.comparing(Student::getAge))).orElse(null);
- reduce操作
reduce用于对流中的元素进行归约操作,得到一个最终的结果。
// 计算学生的总年龄
int totalAge1 = students.stream()
.map(Student::getAge)
.reduce(0, (a,b) -> a+b);
// 也可以使用Integer.sum
int totalAge2 = students.stream()
.map(Student::getAge)
.reduce(0, Integer::sum);
// 也可以不设置初始值0,直接Integer.sum,但是返回的是Optional
int totalAge3 = students.stream()
.map(Student::getAge)
.reduce(Integer::sum).orElse(0);
- findFirst操作
findFirst用于查找流中的第一个元素。也即list.get(0)。
Student firstStu = students.stream()
.filter(student -> Objects.equals("土木工程", student.getMajor()))
.findFirst().orElse(null);
曾经有个小兄弟问我,他有一段代码类似 Student firstStu = students.get(0)。他们组长让他优化优化,然后就用了这种方式优化的。😂
- findAny操作
findAny用于查找流中的任意一个元素。在并行流中,findAny可以更快地获取结果,而在串行流中与findFirst的效果基本一致。
Student anyStu = students.stream()
.filter(student ->Objects.equals("土木工程", student.getMajor()))
.findAny().orElse(null);
- anyMatch操作
anyMatch则是检测是否存在一个或多个满足指定的参数行为,如果满足则返回true。
boolean hasQh = students.stream()
.anyMatch(student -> Objects.equals("清华大学", student.getSchool()));
- noneMatch
noneMatch用于检测是否不存在满足指定行为的元素,如果不存在则返回true.
boolean hasBd = students.stream()
.noneMatch(student -> Objects.equals("北京大学", student.getSchool()));
- allMatch
allMatch用于检测是否全部都满足指定的参数行为,如果全部满足则返回true。
boolean isAdult = students.stream()
.allMatch(student -> student.getAge() > 18);
在Java 8及以上版本,你可以使用并行流(Parallel Stream)来充分利用多核处理器的能力。并行流在处理大量数据时可以提高性能,但并不是在所有情况下都比顺序流更快。当在并行流上进行操作时,需要注意并发问题。确保你的操作是无状态的、无副作用的,或者使用合适的并发工具。一定一定要注意线程安全。并行流本质上基于java7的Fork-Join框架实现,其默认的线程数为宿主机的内核数。
创建并行流,只需要将stream()替换成parallelStream()即可。
List<Student> list = studentMapper.listStudents();
Stream<Student> parallelStream = students.parallelStream();
与顺序流相似,你可以在并行流上执行各种中间和终端操作。
日常中,对于大批量的数据处理转换,我们可以使用并行流去处理。我们可以先把数据切分成100或者其他数值一组的List<List<Student>> 然后使用并行流去处理这些数据。
List<StudentVO> studentVOList = Collections.synchronizedList(Lists.newArrayList());
Lists.partition(students, 100).parallelStream().forEach(pList -> {
// 处理转换数据
List<StudentVO> voList = convertList(pList);
studentVOList.addAll(voList);
});
再比如一些大批量的数据分批次查询,都可以使用并行流去做,但是一定要注意线程安全。
使用Stream API可使Java集合处理更简洁、清晰,充分发挥现代、函数式编程的优势。然而,需注意Stream的惰性求值,只在终端操作触发时执行中间操作,确保操作的必要性,避免不必要计算。Stream鼓励无状态、无副作用的操作,避免在中间操作修改共享状态,以确保流的预测性和可维护性。Stream不可重用,一旦被消费,无法再次使用,需谨慎设计流程。并行流虽提高性能,但需谨慎使用,不适用于所有情况,可能导致额外性能开销。
Java 8中引入的Stream API为开发者带来了全新的编程范式。其链式调用和惰性求值的设计理念,使得数据处理变得更为简单和高效。通过深入理解Stream API,我们能够更好地利用这一强大工具,在实际开发中写出更为优雅和易读的代码。
本文已收录于我的个人博客:码农Academy的博客,专注分享Java技术干货,包括Java基础、Spring Boot、Spring Cloud、Mysql、Redis、Elasticsearch、中间件、架构设计、面试题、程序员攻略等
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK