

Choose Your Own Coding Assistant
source link: https://dev.to/rdentato/choose-your-own-coding-assistant-11gi
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Introduction
In the ever-evolving landscape of AI-powered tools, assistants for software development have carved a niche for themselves, especially in the realm of coding.
This post reports the results of experimenting with four leading Large Language Models (plus a bonus guest star at the end of the article).
OpenAI's GPT-4, Meta CodeLlama70B, Meta CodeLlama7B, and Mistral Mixtral8x7B were tasked with coding challenges to evaluate which one reigns supreme as a coding assistant. The aim is to get an assessment of their capabilities and discern which LLM could be most beneficial for various coding tasks.
For GPT-4, I've selected the last release of GTP-4 Turbo (gpt-4-0125-preview) as it corrects some "laziness" that its predecessor had.
Testing Setup
The battleground for this comparison was set up in Visual Studio Code, enhanced by the "Continue" plugin, allowing for direct interaction with each LLM.
This setup mirrors the functionality of other coding assistants like GitHub Copilot and AWS Codewhisperer and offers more privacy control over your code (for example by running the LLM on private servers) and the option of switching to the best (or less expensive) LLM for the task at hand.
Here is how my setup appears:
Note, on the right end side, the answer I just got from CodeLlama70B.
The Tests
The LLMs were evaluated across eight critical areas in coding:
- Code Generation: Their prowess in crafting code snippets or full modules from scratch based on requirements.
- Code Explanation and Documentation: How well they could elucidate existing code and create meaningful documentation.
- Unit Test Generation: Their ability to autonomously generate unit tests for existing code.
- Debugging and Error Correction: Efficiency in identifying, explaining, and rectifying code bugs or errors.
- Refactoring / Optimization Recommendations: The LLMs' capacity to suggest and implement code improvements for better quality and performance.
- Code Review Assistance: Their ability to aid in code reviews by spotting potential issues and suggesting enhancements.
- Security and Best Practices: Proficiency in detecting security vulnerabilities and enforcing best practices.
- Requirements Analysis: The capability to comprehend software requirements in natural language and translate them into technical specifications. While this not being exactly "coding", it is quite related to that as there might be the need to further refine unclear requirements or somehow transform them (for example, to derive a Finite State Machine that will be further coded in a programming language).
The performance of each LLM has been rated on a scale from 0 to 3, with multiple tests, 19 in total, conducted in each area to ensure fair competition across tasks of the same area.
Throughout the tests, the system prompt has been kept very simple: it just sets up the role of the LLM as a coding assistant and instructs it to be concise and straight to the point (to avoid using too many tokens in lengthy and possibly useless explanations).
This has been done to assess the LLMs' native abilities and opens up the possibility of further increasing their abilities through specific system prompting.
The Results
Here is the summary of the tests:
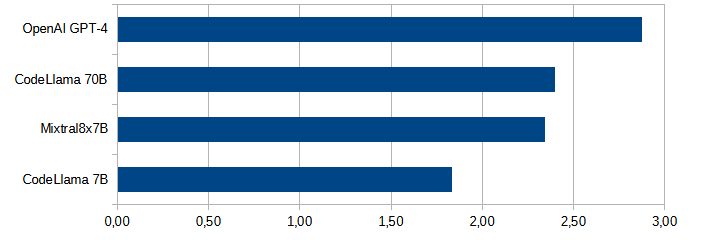
- GPT-4, not surprisingly, emerged as the overall victor, offering the most accurate and comprehensive assistance across all tasks.
- CodeLlama70B and Mixtral8x7B were close competitors, being on par with GPT-4 in some specific areas.
- CodeLlama7B, despite ranking last, showed potential in certain tasks, indicating that tailored prompting could enhance its performance. Its appeal is in its small size which allows it to run on consumer-grade hardware.
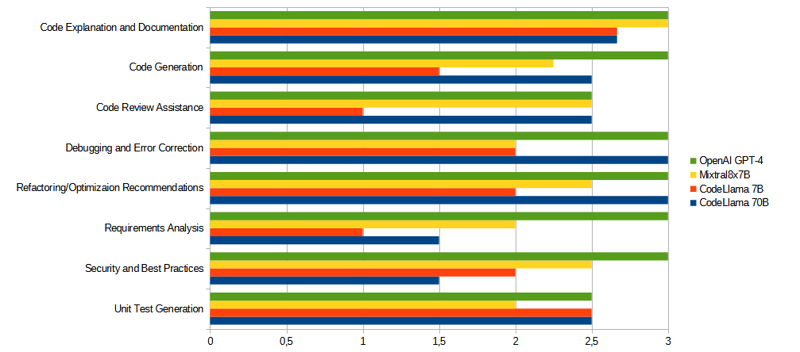
Here are the results for each category:
Some Task Examples
You can find the full list of tasks used for this test, with prompts and the output for each LLM, on Github. Note that I'll update it from time to time with new tests and, possibly, new LLMs.
Here are just a few examples of tasks used in the test.
FEN Counting: This task tested the models' knowledge of FEN strings for chessboard positions. While all four LLMs had some knowledge of what FEN was, only GPT-4 managed to generate completely accurate code. This might be one of those cases when having more "unrelated knowledge" could result in better performance.
Guideline Compliance: Surprisingly, none of the LLMs detected all deviations from a set of coding style guidelines, revealing an area where more work is due to ensure an LLMs can assist. Better prompting or even a RAG approach to ensure the proper guidelines are fully "understood" by the LLM might be needed.
Ambiguity Analysis: Sometimes requirements clash with each other, possibly generating confusion, rework, or bugs. This specific task was aimed to check if the LLM were able to identify conflicting or overlapping requirements. Interestingly, Mixtral8x7B ended up being better than CodeLlama70B at this task.
Conclusions
Setting up a personal coding assistant using these LLMs can mitigate concerns regarding data and code privacy issues, common with cloud-based solutions.
There are also cost factors to be considered, like the costs of hosting your own LLM, the benefits of the higher cost per token of GPT-4 (when compared with other cloud API solutions), and so on.
In conclusion, while GPT-4 stands out for its comprehensive support, smaller models may present viable alternatives depending on your specific needs.
The tests used for this assessment are meant to cover a wide area of tasks and get a feeling of how the different LLMs would perform. Take them as a first cut and conduct specific tests tailored to your use cases to make an informed choice.
One thing is sure: whoever is not using an AI assistant for coding, will need to do so very soon to avoid being left behind.
Now is the time to determine which task should benefit from using an AI assistant for coding and to what extent.
Bonus section
During the preparation of this post, Google launched their new LLM Gemini Advance, showing significant improvements over Google Bard.
I've quickly compared it with GPT-4 across the 8 categories. Further tests are surely needed but, in the meantime, here is a first cut view of how Gemini Advanced scored against GPT-4 overall:

and across the eight areas:
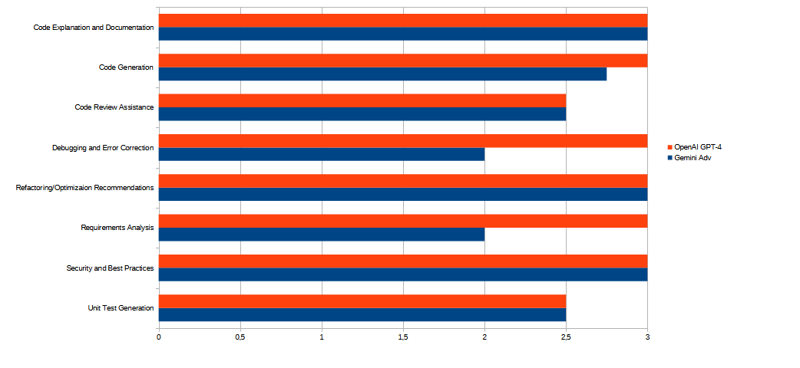
The two LLMs are quite close! Clearly Google's new LLM is a serious contender to the crown of "best LLM overall".
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK