

自然语言处理之BERTopic
source link: https://www.biaodianfu.com/bertopic.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

主题模型是用来在非结构数据中无监督的发现隐含主题信息的一类重要工具,比较成熟和常用的算法有基于矩阵分解(如:SVD分解)的LSA(Latent Semantic Analysis), 引入概率方法代替SVD的pLSA(Probabilistic Latent Semantic Analysis), 贝叶斯版本的pLSA——LDA(Latent Dirichlet Allocation)。 但这类方法的本质是通过最小化误差从而找到能够复现原有文档分布的主题,对隐含语义的捕获能力非常有限(本质是对信息的distributional representation), 而随着神经网络和Embedding技术(本质是对信息的distributed representation)的发展以及Transformer在NLP领域的爆发,出现了更加有趣的主题模型,其中Maarten Grootendorst提出的BERTopic是一个简洁而强大的算法,论文地址:《BERTopic: Neural topic modeling with a class-based TF-IDF procedure》。
BERTopic简介
BERTopic 是一种基于 BERT (Bidirectional Encoder Representations from Transformers) 的主题模型算法,它结合了 BERT 的强大的自然语言处理能力和主题模型的优点,可以对大规模文本数据进行无监督的主题提取。
BERTopic 算法的主要步骤如下:
- 对文本数据进行预处理,包括清理、分词、停用词去除等。
- 使用 BERT 对每个文本进行表示,并使用聚类算法对表示向量进行聚类。
- 根据聚类结果为每个聚类分配一个主题,并使用 UMAP (Uniform Manifold Approximation and Projection) 算法将聚类结果可视化。
BERTopic 相比传统的主题模型算法,有以下优点:
- 不需要手动设置主题数目,可以自动识别主题数目。
- 对文本表示的方式更加准确,提高了主题模型的准确性。
- 对于大规模文本数据,速度更快,效率更高。
总之,BERTopic 是一种功能强大的主题模型算法,可以有效地对大规模文本数据进行无监督的主题提取。
BERTopic原理说明
BERTopic 是一种主题建模技术,它利用 Transformer 和 c-TF-IDF 来创建密集的集群,允许轻松解释主题,同时在主题描述中保留重要词。
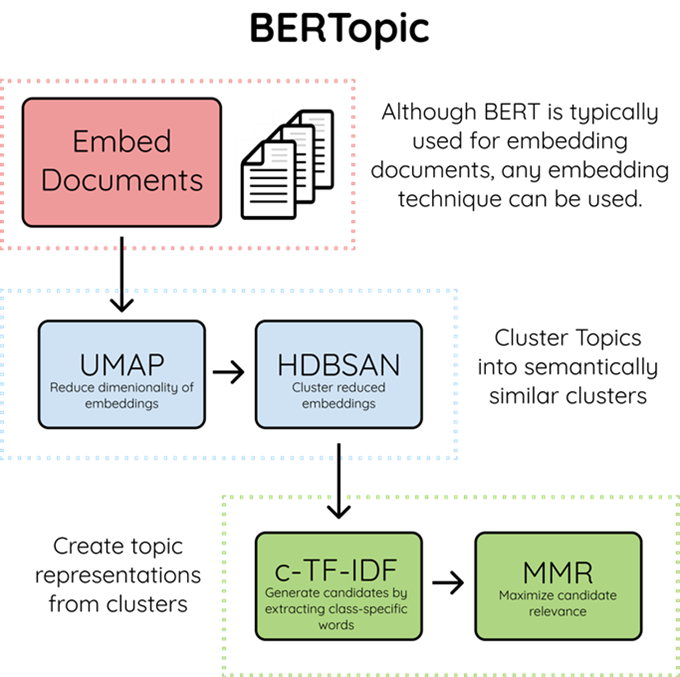
该算法包含3个阶段
- Embed documents: 使用 BERT 或任何其他嵌入技术提取文档嵌入向量
- Cluster Documents:
- 使用UMAP对向量降维(同时保留位置信息)
- 使用HDBSCAN算法去聚类
- Create topic representation(得到主题表示)
- 使用 c-TF-IDF 提取主题词和减少主题数量
- 使用最大边际相关性提高单词的连贯性和多样性
Embed documents
Embed documents这一步是BERTopic模型中的关键步骤,该步骤的目的是将输入的文本转化为数值型向量,以便后续处理。这种转化过程也被称为”文档嵌入”或”文档表示”。
BERTopic 使用BERT(Bidirectional Encoder Representations from Transformers)模型生成文档嵌入。BERT模型是一个深度学习模型,该模型在学习过程中,能够捕捉到词汇之间的复杂关系,并将这些信息编码到生成的嵌入向量中。这与诸如词袋或TF-IDF等传统方法相比,BERT能够提供更丰富,更准确的文本表示。
BERTopic默认使用的是英语版本的词嵌入模型,这个模型由Sentence Transformers库提供,具体为 “all-MiniLM-L6-v2″模型。
如果你想要改变默认的词嵌入模型,可以在初始化BERTopic时,通过embedding_model参数来指定你想要使用的模型。要让BERTopic使用HuggingFace上的模型,如 “bert-base-chinese”,你可以在创建BERTopic实例时将其作为参数传入。
首先,需要安装sentence-transformers库,这个库是基于Hugging Face的Transformers库和PyTorch构建的,专门用于生成BERT模型的句子/文档嵌入。
然后,可以创建自定义的句子转换器模型,如下所示:
from sentence_transformers import SentenceTransformer
from bertopic import BERTopic
# 创建基于 "bert-base-chinese" 的句子转换器模型
sentence_model = SentenceTransformer("bert-base-chinese")
# 将句子转换器模型传入BERTopic
topic_model = BERTopic(embedding_model=sentence_model)
在这个例子中,BERTopic将使用 “bert-base-chinese” 模型来生成文档嵌入,这对于处理中文文本数据非常有用。务必要确保你输入的模型名称是正确的,并且Hugging Face上有对应的预训练模型。
Cluster Documents
UMAP降维
当文本信息被embedding后,每个文档会成为一个高维(通常是几百维以上)稠密向量,但整个语义空间会很稀疏,逻辑上语义相关的文档会因为“距离”接近在空间内“聚集”,而为了识别主题向量,首先想到的是基于密度的聚类算法,但这类算法对向量维度很敏感,维度越高速度越慢,所以有必要把原来几百维的向量压缩降维到个位数维度,比如2~3维,同时也方便数据可视化。 降维方法主要有三类:
- 特征选择法( Feature Selection)
- 基于矩阵分解的方法如PCA(Principal Component Analysis)、SVD(Singular Value Decomposition)等
- 基于邻居图(Neighbor Graphs)的方法SNE(Stochastic Neighbor Embedding)、t-SNE(t-Distributed Stochastic Neighbourh Embedding)、UMAP(Uniform Manifold Approximation and Projection)
其中UMAP更是速度和效果方面的佼佼者。
UMAP描述为: 一种降维技术,假设可用数据样本均匀(Uniform)分布在拓扑空间(Manifold)中,可以从这些有限数据样本中近似(Approximation)并映射(Projection)到低维空间。
各个名词解释
- Projection: 通过投影点在平面、曲面或线上再现空间对象的过程或技术。也可以将其视为对象从高维空间到低维空间的映射。
- Approximation: 算法假设我们只有一组有限的数据样本(点),而不是构成流形的整个集合。因此,我们需要根据可用数据来近似流形。
- Manifold: 流形是一个拓扑空间,在每个点附近局部类似于欧几里得空间。一维流形包括线和圆,但不包括类似数字8的形状。二维流形(又名曲面)包括平面、球体、环面等。
- Uniform: 均匀性假设告诉我们的数据样本均匀(均匀)分布在流形上。但是,在现实世界中,这种情况很少发生。因此这个假设引出了在流形上距离是变化的概念。即,空间本身是扭曲的:空间根据数据显得更稀疏或更密集的位置进行拉伸或收缩。
我们可以将UMAP分为两个主要步骤:
- 学习高维空间中的流形结构
- 找到该流形的低维表示。
下面我们将把它分解成更小的部分,以加深我们对算法的理解。下面的地图显示了我们在分析每个部分工作流程。
学习流形结构
在我们将数据映射到低维之前,肯定首先需要弄清楚它在高维空间中的样子。
寻找最近的邻居
UMAP 首先使用 Nearest-Neighbor-Descent 算法找到最近的邻居。我们可以通过调整 UMAP 的 n_neighbors 超参数来指定我们想要使用多少个近邻点。
试验 n_neighbors 的数量很重要,因为它控制 UMAP 如何平衡数据中的局部和全局结构。它通过在尝试学习流形结构时限制局部邻域的大小来实现。
本质上,一个小的n_neighbors 值意味着我们需要一个非常局部的解释,准确地捕捉结构的细节。而较大的 n_neighbors 值意味着我们的估计将基于更大的区域,因此在整个流形中更广泛地准确。
构建一个图
接下来,UMAP 需要通过连接之前确定的最近邻来构建图。为了理解这个过程,我们需要将他分成几个子步骤来解释邻域图是如何形成的。
正如对 UMAP 名称的分析所述,我们假设点在流形上均匀分布,这表明它们之间的空间根据数据看起来更稀疏或更密集的位置而拉伸或收缩的。
它本质上意味着距离度量不是在整个空间中通用的,而是在不同区域之间变化的。我们可以通过在每个数据点周围绘制圆圈/球体来对其进行可视化,由于距离度量的不同,它们的大小似乎不同(见下图)。
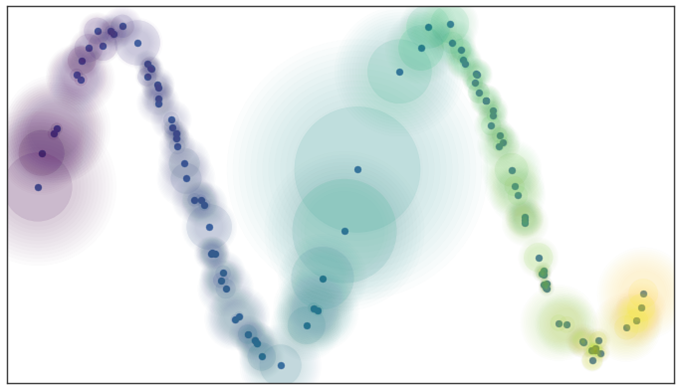
接下来,我们要确保试图学习的流形结构不会导致许多不连通点。所以需要使用另一个超参数local_connectivity(默认值= 1)来解决这个潜在的问题。
当我们设置local_connectivity=1 时,我们告诉高维空间中的每一个点都与另一个点相关联。
你一定已经注意到上面的图也包含了模糊的圆圈延伸到最近的邻居之外。这告诉我们,当我们离感兴趣的点越远,与其他点联系的确定性就越小。
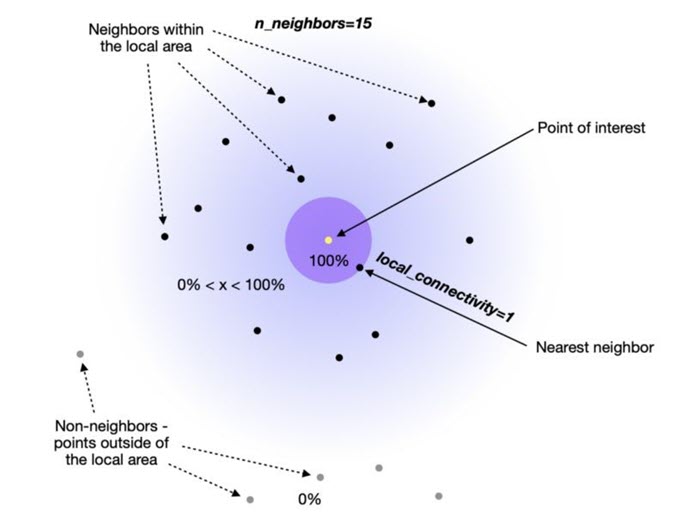
这两个超参数(local_connectivity 和 n_neighbors)最简单的理解就是可以将他们视为下限和上限:
- Local_connectivity(默认值为1):100%确定每个点至少连接到另一个点(连接数量的下限)。
- n_neighbors(默认值为15):一个点直接连接到第 16 个以上的邻居的可能性为 0%,因为它在构建图时落在 UMAP 使用的局部区域之外。
- 2 到 15 : 有一定程度的确定性(>0% 但 <100%)一个点连接到它的第 2 个到第 15 个邻居。
最后,我们需要了解上面讨论的连接确定性是通过边权重(w)来表达的。
由于我们采用了不同距离的方法,因此从每个点的角度来看,我们不可避免地会遇到边缘权重不对齐的情况。 例如,点 A→B 的边权重与 B→A 的边权重不同。
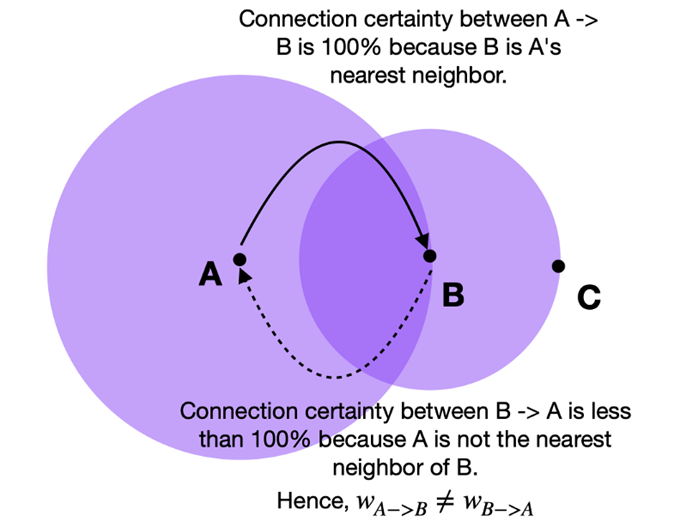
UMAP 通过取两条边的并集克服了我们刚刚描述的边权重不一致的问题。 UMAP 文档解释如下:
如果我们想将权重为 a 和 b 的两条不同的边合并在一起,那么我们应该有一个权重为a+b的单边。考虑这一点的方法是,权重实际上是边(1-simplex)存在的概率。 组合权重就是至少存在一条边的概率。
最后,我们得到一个连接的邻域图,如下所示:
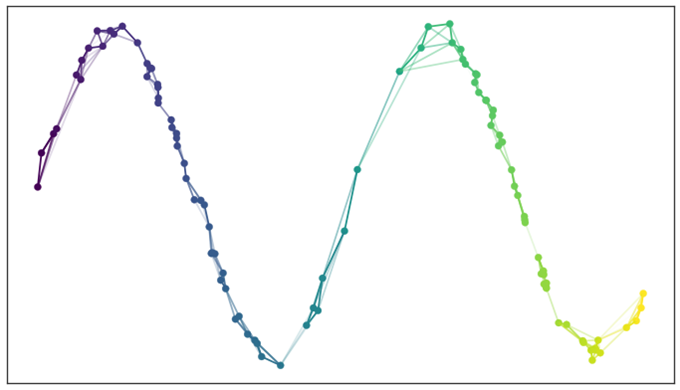
寻找低维表示
从高维空间学习近似流形后,UMAP 的下一步是将其投影(映射)到低维空间。
最小距离
与第一步不同,我们不希望在低维空间表示中改变距离。相反,我们希望流形上的距离是相对于全局坐标系的标准欧几里得距离。
从可变距离到标准距离的转换也会影响与最近邻居的距离。因此,我们必须传递另一个名为 min_dist(默认值=0.1)的超参数来定义嵌入点之间的最小距离。
本质上,我们可以控制点的最小分布,避免在低维嵌入中许多点相互重叠的情况。
最小化成本函数(Cross-Entropy)
指定最小距离后,该算法可以开始寻找较好的低维流形表示。 UMAP 通过最小化以下成本函数(也称为交叉熵 (CE))来实现:
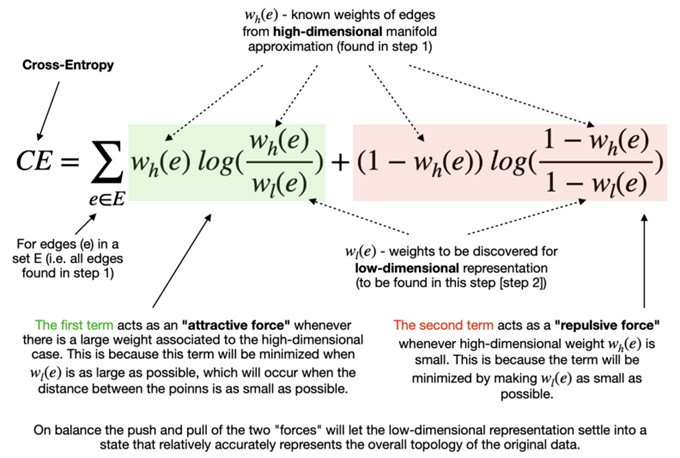
最终目标是在低维表示中找到边的最优权值。这些最优权值随着上述交叉熵函数的最小化而出现,这个过程是可以通过随机梯度下降法来进行优化的
就是这样!UMAP的工作现在完成了,我们得到了一个数组,其中包含了指定的低维空间中每个数据点的坐标。
HDBSCAN聚类
接下来就需要用聚类算法尽可能的把数据中高内聚低耦合的规律找出来,聚类算法大致分为基于扁平或层次结构的聚类和基于质心或密度的聚类,当然两类也可以交叉。扁平聚类可以看做层次聚类的特例,它们有点像决策树,更关注层次关系,典型的例子是:“国家->省->市->县…”这种层次关系的发现, 质心聚类更关注找到每个以质心为中心的“球状”的聚类,密度聚类则可以处理不规则形状的聚类。如果结合密度聚类和层次聚类,就可以得到既能处理不规则形状又能得到解释性比较好还能方便识别异常点的聚类算法,HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)就是一个这类算法。
关于HDBSCAN的原理可以看我之前整理的文章机器学习聚类算法之HDBSCAN
Create topic representation
c-TF-ICF
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF 采用文本逆频率 IDF 对 TF 值加权取权值大的作为关键词,但 IDF 的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以 TF-IDF 算法的精度并不是很高,尤其是当文本集已经分类的情况下。
在本质上 IDF 是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。IDF 的简单结构并不能使提取的关键词, 十分有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同类文本的关键词被盖。
概括起来,有以下不足:
- 没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
- 按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
- 传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
- 对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
为了对每个分类作出表示,Bertopic修改了TF-IDF模型,使得c-TF-ICF基于的是分类好的文本,而不是整个语料得到关键词。

c-TF-IDF是BERTopic中用于提取主题关键词和生成主题描述的关键技术,全称是“Class-based Term Frequency-Inverse Document Frequency”。
c-TF-IDF是TF-IDF的一种变体,它将TF-IDF从文档级别扩展到主题级别。TF-IDF是在BERTopic中,c-TF-IDF是一种用于提取每个主题内关键词的算法,它是传统TF-IDF算法的一个改进版本,专门设计用于主题建模。c-TF-IDF代表的是类条件概率Term Frequency-Inverse Document Frequency(类条件概率词频-逆文档频率)。这个算法的目的是找出哪些词对于一个主题是有辨识度的,也就是说,这些词在特定主题中频繁出现,但在其它主题中不常见。
以下是c-TF-IDF的工作原理:
- Term Frequency (TF)。”词频”(TF)表示某个词在特定文档中出现的频率。在BERTopic中,这个概念被用于一个特定主题的所有文档。如果一个词在给定主题的文档中出现得越频繁,它的TF值就越高。
- Document Frequency (DF)。”文档频率”(DF)表示包含特定词的文档数量。在BERTopic中,这意味着在所有主题的文档中计算每个词的DF值。
- Inverse Document Frequency (IDF)。”逆文档频率”(IDF)是DF的逆数,用来衡量一个词的普遍重要性。越是常见的词(在很多文档中出现的词),它们的IDF值就越低。IDF的一个常见计算方法是取DF的逆数的对数。
- 类条件概率TF-IDF (c-TF-IDF)。在BERTopic中,每个主题都被视为一个”类”或”类别”,而c-TF-IDF就是针对每个类别计算TF-IDF。这意味着计算的不是单个文档的TF-IDF,而是一个主题下所有文档的TF-IDF。
具体而言,对于每个主题,算法计算该主题所有文档中每个词的词频,然后将这个频率除以该词在所有主题中的文档频率的对数。这样,如果一个词在某个主题中非常频繁地出现,但在其他主题中不太常见,它就会在该主题中得到一个高的c-TF-IDF得分。
c-TF-IDF的计算公式如下:
- ft,d是词t 在主题d的文档集中的词频。
- fd是主题d的文档集中所有词的词频总和。
- N是总主题数量。
- dft是包含词t的主题数量。
通过这种计算方式,BERTopic能够为每个主题生成一个按照词重要性排序的词列表,这些词可以很好地代表该主题的内容。
最后,BERTopic会从每个主题的c-TF-IDF得分中选取得分最高的词汇,作为代表该主题的关键词。这有助于用户快速理解每个主题的核心内容。
MMR 算法
BERTopic中的MMR算法指的是Maximal Marginal Relevance(最大边际相关性)算法,这是一种用于文本摘要和信息检索的技术,用来平衡相关性(relevance)和信息多样性(diversity)。虽然MMR最初是在信息检索领域被提出用以改进文档排序,但在BERTopic中,MMR被用于选择代表性词汇,以生成描述主题的关键词。
MMR算法的基本思想是在选择主题关键词时,同时考虑词语的相关性以及它们之间的差异性。算法会优先选择与主题最相关的词语,但同时也会尽量避免选择与已选词语相似的词语,以此提高关键词列表的多样性,使得关键词能够全面覆盖主题的各个方面。
BERTopic中的MMR算法可以用以下步骤描述:
- 计算相关性:对于给定主题,算法首先计算每个候选词语与主题的相关性。这通常是通过与主题相关的文档中的c-TF-IDF得分来衡量的。
- 计算多样性:算法计算每个候选词与已选择关键词之间的相似性。这可以通过诸如余弦相似度等度量来实现。
- 平衡相关性和多样性:MMR算法使用一个权衡参数(通常表示为λ,来调整相关性和多样性在选择关键词时的重要性。
- 选择关键词:算法迭代地选择MMR得分最高的词语作为关键词,直到达到预定的关键词数量或者有其他的停止条件。
在BERTopic中,MMR可以帮助生成的关键词列表不仅包含与主题强相关的高频词汇,而且还能体现主题的多方面特征,从而更好地描述主题内容。通过调整λ,用户可以根据不同的需求,调整在相关性和多样性之间的平衡点。
MMR的具体公式如下:
- term 是当前正在考虑的候选关键词。
- term’ 是已选择的关键词列表中的词。
- Relevance(term) 表示候选词语与主题的相关度。
- Diversity(term, term’) 是候选词语与已选关键词之间的差异性。
- λ是一个介于0和1之间的参数,决定了相关性和多样性的权衡;λ值越大,算法越倾向于选择相关性高的词语,反之则更强调多样性。
BERTopic实战
使用BERTopic非常简单。将文档作为字符串列表加载,然后将其传递给fit_transform方法。
import pandas as pd
from bertopic import BERTopic
from sentence_transformers import SentenceTransformer
import torch
# 检查 CUDA 是否可用,如果可用,设置为默认设备
if torch.cuda.is_available():
torch.cuda.set_device(0) # 如果有多个GPU,你可以选择一个特定的 GPU
df = pd.read_csv('data/text.csv')
texts = df['text'].head(10000).to_list()
# sentence_model = SentenceTransformer("bert-base-chinese")
sentence_model = SentenceTransformer("nghuyong/ernie-3.0-base-zh")
topic_model = BERTopic(embedding_model=sentence_model)
topics, probs = topic_model.fit_transform(texts)
有两个输出产生,topics和probabilities。topics中的值表示它被分配给的主题。另一方面,概率表明文档落入主题的可能性。
在创建BERTopic实例时,可以设置多个参数以自定义主题建模的过程和结果。以下是BERTopic实例中的一些主要参数及其说明:
- language:用于加载预训练的词嵌入的语言。默认为’英语’。如果您的数据集是非英语的,您需要指定正确的语言代码。
- top_n_words:在每个主题中提取的最关键词的数量。默认值是10。
- n_gram_range:三元组提取的n-gram范围。默认为(1, 1),仅提取单个词。
- vectorizer_model:用于将文档转换为向量表示的模型。它可以是CountVectorizer、TfidfVectorizer,或者任何具有.fit_transform方法的向量器。默认使用CountVectorizer。
- umap_model:UMAP模型的参数,用于降维步骤。这是一个字典,可以包含n_neighbors、n_components、metric等参数。
- hdbscan_model:HDBSCAN模型的参数,用于聚类步骤。这是一个字典,可以包含min_cluster_size、min_samples、cluster_selection_epsilon等参数。
- min_topic_size:定义一个主题的最小大小。默认为10。
- nr_topics:要提取的主题数量。如果设置为’auto’,则会自动确定主题的数量。也可以设置为一个整数,以固定主题的数量。
- low_memory:当处理大量数据时,可以设置为True以降低内存使用,但可能会增加训练时间。
- calculate_probabilities:是否计算文档属于每个主题的概率。默认为False,因为这会大大增加训练时间,尤其是数据集较大时。
- diversity:是否通过Maximal Marginal Relevance (MMR) 来优化主题的多样性。默认为None。
- seed_topic_list:预定义的主题关键词列表,用于提升特定主题的提取。默认为None。
- verbosity:控制打印到控制台的信息的详细程度。默认为0。
- zeroshot_topic_list:这个参数允许用户提供一组主题关键词列表。BERTopic会使用这些关键词来执行零样本(zero-shot)主题分类,其中主题不是通过传统的聚类发现他们,而是通过检测文本与这些预设主题关键词的相似性。
- zeroshot_min_similarity:当使用零样本主题分类时,这个参数设置了文本被分配到某个主题的最小相似度阈值。只有在文本与主题关键词的相似度高于这个阈值时,文本才会被分配到该主题。
- embedding_model:这个参数指定用于将文本转换为嵌入向量的预训练模型。BERTopic支持由sentence-transformers库提供的多种嵌入模型。这些嵌入模型基于BERT、RoBERTa、DistilBERT等Transformer架构,并且经过训练以捕获句子级别的语义信息。
- ctfidf_model:ctfidf_model参数是BERTopic特有的,代表 class-based Term Frequency-Inverse Document Frequency (c-TF-IDF) 模型。c-TF-IDF是BERTopic用于表示主题的方法,可以类比于传统的TF-IDF,但是针对每个类(或主题)进行计算,以确定哪些词对于各个主题来说是独特且重要的。
- representation_model:这个参数在BERTopic的早期版本中使用,用于指定计算文档表示的模型。在最新版本的BERTopic中,这个概念通常已经被embedding_model所取代,因为embedding_model就是用来生成文档的嵌入表示。请注意,BERTopic版本的更新可能引入了新的参数或改变了某些参数的用法。因此,建议查看BERTopic的官方文档或GitHub仓库中的最新信息,以获得关于参数的最准确和最新的描述。这里提供的信息可能根据BERTopic的版本和更新历史而有所不同。
数据预处理
BERTopic 是一个基于 Transformer 模型的主题模型工具,它能够自动地从文本数据中识别和提取主题。其独特之处在于,它结合了主题建模和BERT嵌入(通过Sentence Transformers)来创建更有意义和可解释的主题。
在使用 BERTopic 处理英文文本时,通常不需要事先进行分词,因为英文文本的分词较为简单,BERTopic 内部已经处理好了这一步骤。但是,当处理中文或其他需要复杂分词的语言时,进行分词可能是必要的,因为这能帮助模型更好地理解单词边界。
至于去除停用词,BERTopic 内部有处理机制来降低常见词的影响,所以您不一定需要在前期手动去除停用词。然而,在某些情况下,去除停用词可以减少模型需要处理的噪音,可能会提升最终主题的质量和相关性。而且,去除停用词也能减少内存的使用,加快模型的运行速度。
UMAP降维设置
您可以调整降维算法的参数来影响模型的性能和主题的质量。要调整降维设置,您可以在创建 BERTopic 实例时传递参数来指定 UMAP 的不同设置。以下是一些常用的 UMAP 参数及其说明:
- n_neighbors:考虑周围邻居的数量,用于 UMAP。较小的值可能导致更紧密的聚类,而较大的值可以捕捉到全局数据结构。默认值是 15。减少这个参数可能会导致数据在降维空间中更分散,从而在后续的HDBSCAN聚类中产生更多簇。
- n_components:UMAP 降维之后的维度数。默认值是 5。
- min_dist:嵌入空间中点之间的最小距离。较小的值通常会导致更紧密的聚类,适合于强调局部结构的数据。默认值是1。减少这个参数可以使UMAP在低维空间中保持更紧凑的局部结构,这可能有助于更好地区分簇。
- metric:用于计算距离的度量。默认是 ‘euclidean’,但是也可以是 ‘manhattan’、’cosine’ 等。
以下是一个例子,展示了如何创建一个 BERTopic 实例并调整 UMAP 参数:
from bertopic import BERTopic from umap import UMAP umap_model = UMAP(n_neighbors=10, min_dist=0.05) topic_model = BERTopic(umap_model=umap_model)
调整HDBSCAN参数
在创建 BERTopic 实例时,可以调整 HDBSCAN 的参数来影响主题质量和模型性能。
以下是在 BERTopic 中可以调整的一些关键 HDBSCAN 参数及其说明:
- min_cluster_size:集群的最小大小。较大的值可能会导致更少的、更大的簇,而较小的值可能导致更多的、较小的簇。默认值因数据集大小而异。降低这个参数将导致模型创建更多、可能更小的簇。
- min_samples:确定核心样本的密度的点数。较大的值可以帮助抑制噪声,较小的值可以允许更微妙的聚类结构。也可以减少这个参数,以允许算法识别更细微的簇。
- cluster_selection_epsilon:一个距离阈值,使得距离小于此值的簇会被合并。默认值是0,表示不强制合并。
- cluster_selection_method:用于选择簇的方法。可以是 ‘eom’ (Excess of Mass) 或 ‘leaf’,默认是 ‘eom’。
以下是创建 BERTopic 实例时如何调整 HDBSCAN 参数的示例:
from bertopic import BERTopic from hdbscan import HDBSCAN hdbscan_model = HDBSCAN(min_cluster_size=10, min_samples=5) topic_model = BERTopic(hdbscan_model= hdbscan_model)
聚类数量的调整
如果你发现BERTopic生成的主题太少或者过于集中,你可以通过调整一些参数来尝试改进效果。以下是一些可能的措施:
- 调整HDBSCAN参数:
- min_cluster_size:降低这个参数可以导致产生更多的小簇。不过,设置得太低可能会导致过度拟合和噪声增多。
- min_samples:增大这个参数可以帮助在数据中识别更多的噪声点,这可能会导致更精细的聚类。
- cluster_selection_epsilon:减小这个参数可以避免过于相似的簇被合并。
- 调整UMAP参数:
- n_neighbors:降低这个参数可能导致UMAP在降维过程中强调更局部的特征,从而可能会导致数据点更加分散。
- min_dist:减小这个参数可以让UMAP在低维表示中保持更紧密的局部结构,这有助于区分更多的簇。
- 调整文本预处理:
- 考虑对文本进行更彻底的预处理,包括移除停用词、词干提取或词形还原。这有助于模型聚焦于更有意义的词汇特征。
- 调整向量化参数:
- 如果你使用的是自定义的vectorizer_model,可以通过调整其参数来影响文本的向量化。例如,在CountVectorizer或TfidfVectorizer中调整max_df或min_df来控制词汇表的大小。
- 尝试不同的嵌入模型:
- 改变embedding_model可能会对主题的聚类有显著影响。不同的预训练模型可能捕捉到文本中不同的语义特征。
- 修改nr_topics参数:
- 如果nr_topics设置为”auto”,BERTopic会尝试自动确定主题数量。您可以尝试设置成一个特定的较大数字,强制模型生成更多的主题。
- 使主题更多样化:
- diversity参数可以设置为一个正数,这将通过Maximal Marginal Relevance (MMR)算法促使模型生成更多样化的关键词,这可能会有助于更好地区分主题。
在训练后进行主题缩减
如果在花了好几个小时的训练之后,你的主题太多了怎么办?如果仅仅为了试验大量的主题而不得不重新训练你的模型,那将十分耗时。
幸运的是,在训练了BERTopic模型之后,我们可以减少主题的数量。这样做的另一个好处是,你可以在知道实际创建了多少主题之后决定主题的数量:
from bertopic import BERTopic model = BERTopic() topics, probs = model.fit_transform(docs) # 减少主题 new_topics, new_probs = model.reduce_topics(docs, topics, probs, nr_topics=30)
保存/加载BERTopic模型
# 我们可以通过调用save轻松保存经过训练的BERTopic模型:
from bertopic import BERTopic
model = BERTopic()
model.save("my_model")
# 然后我们可以加载模型:
loaded_model = BERTopic.load("my_model")
# 进行新的预测:
topics, probs = model.transform(new_docs)
查看模型数据
# 查看TOP主题 topic_model.get_topic_freq().head(10) # 选择一个主题看关键词 topic_model.get_topic(0)
BERTopic的可视化
BERTopic提供了若干种可视化方法来帮助用户理解和分析生成的主题。以下是一些常见的可视化方法:
主题可视化 (Topic Visualization)
visualize_topics(): 生成一个二维空间的可视化图,其中每个主题都是一个圆点,接近的圆点表示相似的主题。这个方法通常使用降维算法(如UMAP)来实现。
topic_model.visualize_topics()
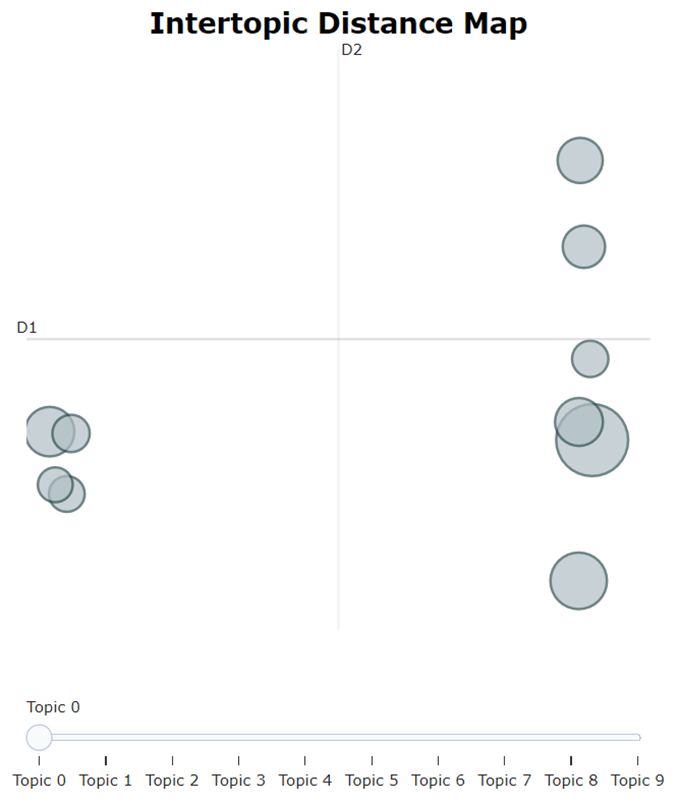
主题关键词展示
visualize_barchart(): 生成一个条形图,显示每个主题中最重要的单词及其相应的权重。
topic_model.visualize_barchart()
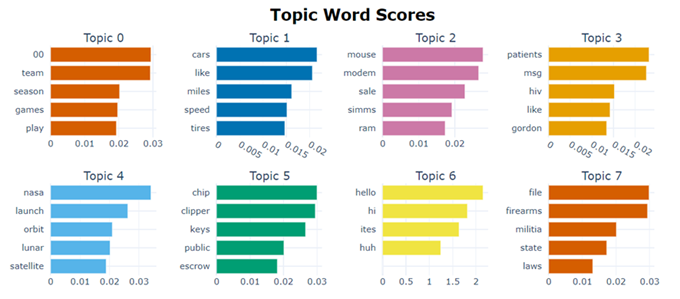
主题树状图 (Hierarchical Topic Visualization):
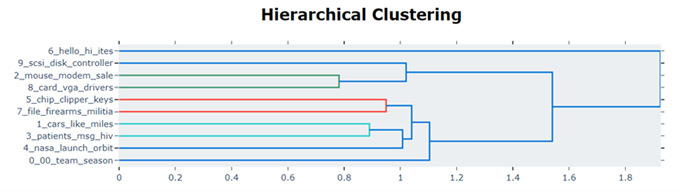
visualize_hierarchy(): 绘制一个树状图,显示主题之间的层次结构。这可以帮助用户理解哪些主题是相互关联的。
topic_model.visualize_hierarchy()
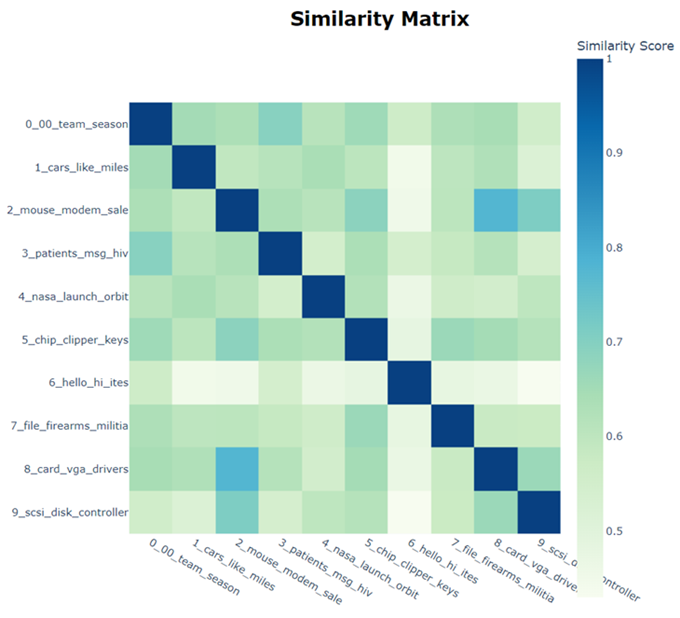
文档相似性热图 (Document Similarity Heatmap):
visualize_heatmap(): 显示文档之间的相似性热图,高亮显示相似性较高的文档对。
topic_model.visualize_heatmap()
相似词可视化 (Similar Words Visualization):
visualize_term_rank(): 展示一个或多个特定词的排名变化,可以指定不同的时间范围来观察词的排名如何变化。
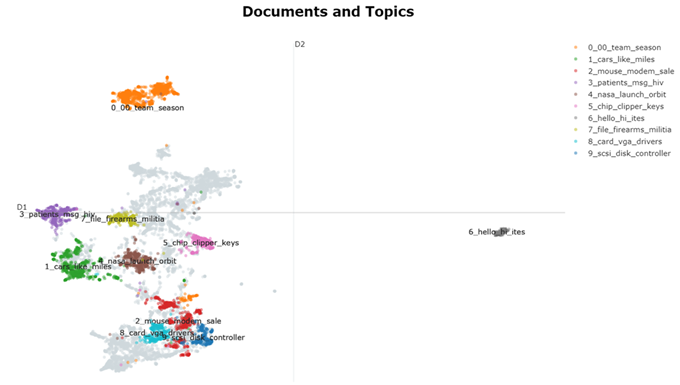
在 2D 中可视化文档及其主题
embeddings = embedding_model.encode(filtered_text, show_progress_bar=False) # Run the visualization with the original embeddings topic_model.visualize_documents(filtered_text, embeddings=embeddings)
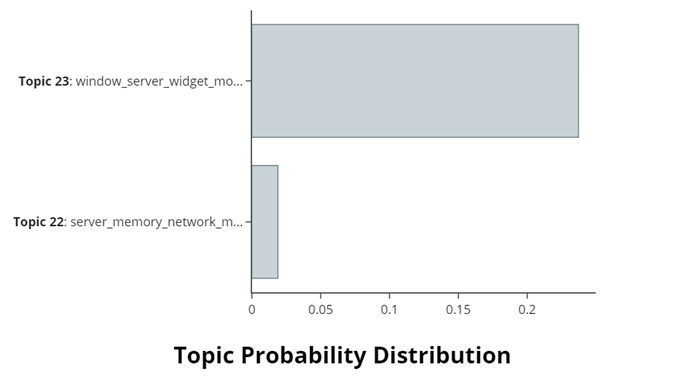
主题概率分布可视化 (Topic Probability Distribution)
visualize_distribution(): 生成一个特定文档的主题分布图,显示了文档在不同主题上的概率分布。
topic_model.visualize_distribution(probabilities[0])
主题随时间变化可视化 (Topic Trends Over Time)
visualize_topics_over_time(): 如果你的数据集包含时间信息,这个方法可以生成主题随时间变化的趋势图。这需要你事先提供每个文档的时间戳。
topics_over_time = topic_model.topics_over_time(docs, timestamps) topic_model.visualize_topics_over_time(topics_over_time)
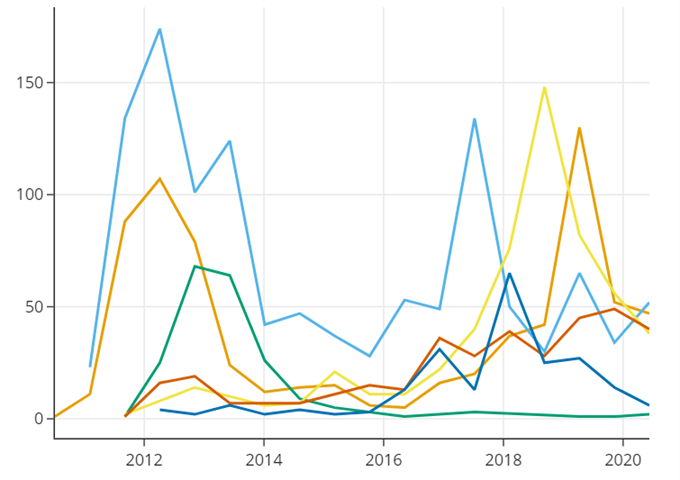
这些可视化方法提供了不同的视角来理解模型生成的主题,从而可以更好地分析文本数据,并帮助用户做出相应的决策。
参考链接:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK