

理解『注意力机制』的本质 - 茴香豆的茴
source link: https://www.cnblogs.com/xing9/p/18006019/attention
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

理解『注意力机制』的本质
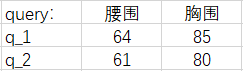
假设有这样一组数据,它们是腰围和体重一一对应的数据对。我们将根据表中的数据对去估计体重。
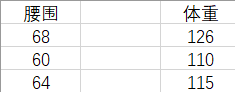
如果现在给出一个新的腰围 62 ,那么体重的估计值是多少呢?
凭经验,我们认为腰围和体重是正相关的,所以我们会自然地『关注』和 62 差距更小的那些腰围,来去估计体重。也就是更加关注表格中腰围是 60 和 64 的『腰围-体重对』(waistline-weight pairs)。即,我们会估计此人的体重在 110 ~ 115 之间。这是一种定性的分析。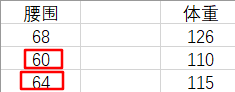
下面我们来算一下具体值。我们选取一种简单直观的方法来计算:
由于 62 距离 60 和 64 的距离是相等的,所以我们取 110 和 115 的平均值作为 62 腰围对应的体重。
也可以这样认为,由于 62 距离 60 和 64 是最近的,所以我们更加『注意』它们,又由于 62 到它俩的距离相等,所以我们给这两对『腰围-体重对』各分配 0.5 的权重。
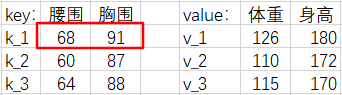
但是,我们到现在还没有用到过 68 --> 126 这个『腰围-体重对』,我们应该再分一些权重给它,让我们的估计结果更准确。
我们上面的讨论可以总结为公式:体重估计值权重体重权重体重权重体重体重估计值权重体重权重体重权重体重体重估计值=权重1×体重1+权重2×体重2+权重3×体重3
这个权重应该如何计算呢?
二、注意力机制
我们把『腰围-体重对』改写成 Python 语法中(字典)的『键-值对』(key-value pairs),把给出的新腰围 62 叫请求(query),简称 q .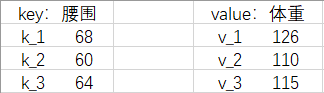
现在我们给那些值起了新的名字,所以公式可以写为:f(q)=α(q,k1)⋅v1+α(q,k2)⋅v2+α(q,k3)⋅v3=Σi=13α(q,ki)⋅vi
这个公式描述了『注意力机制』。其中,f(q) 表示注意力机制的输出。 α(q,ki) 表示『注意力权重』。它和 q,ki 的相似度有关,相似度越高,注意力权重越高。
它是如何计算的呢?方法有很多,在本例中,我们使用高斯核计算:
我们取(−12(q−ki)2)部分进行下一步计算,并把它叫做『注意力分数』。显然,现在这个注意力分数是个绝对值很大的数,没法作为权重使用。所以下面我们要对其进行归一化,把注意力分数转换为 [0, 1] 间的注意力权重(用 α(q,ki) 表示)。本例选用 Softmax 进行归一化:
我们发现,好巧不巧地,α(q,ki) 最终又变成高斯核的表达式。
本例中的高斯核计算的相似度为:GS(62,68)=1.52×10−8GS(62,60)=0.135GS(62,64)=0.135
GS(q,k1) 太小了,我们直接近似为 0 .
注意力权重计算结果为:α(62,68)=0α(62,60)=0.5α(62,64)=0.5
体重估计值为:f(q)=α(62,68)×126+α(62,60)×110+α(62,64)×115=112.5
三、多维情况
当 q, k, v 为多维时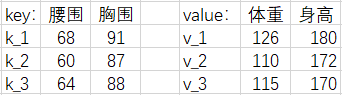
注意力分数 α(qi,ki) 可以用以下方法计算:
| 模型 | 公式 |
|---|---|
| 加性模型 | α(qi,ki)=softmax(Wqqi+Wkki+b) |
| 点积模型 | α(qi,ki)=qi⋅kid |
| 缩放点积模型 | α(qi,ki)=qi⋅kidk |
我们以『点积模型』为例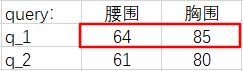
其他注意力分数同理。
那么现在,多维情况下的注意力输出 f(q) 可以表示为下式:
为了方便计算,我们写成矩阵形式。
为了缓解梯度消失的问题,我们还会除以一个特征维度 dk ,即:
这一系列操作,被称为『缩放点积注意力模型』(scaled dot-product attention)
如果 Q, K, V 是同一个矩阵,会发生什么?
四、自注意力机制
我们用 X 表示这三个相同的矩阵:
则上述的注意力机制表达式可以写成:
这个公式描述了『自注意力机制』(Self-Attention Mechanism)。在实际应用中,可能会对 X 做不同的线性变换再输入,比如 Transformer 模型。这可能是因为 X 转换空间后,能更加专注注意力的学习。
三个可学习的权重矩阵 WQ, WK, WV 可以将输入 X 投影到查询、键和值的空间。
该公式执行以下步骤:
- 使用权重矩阵 WQ 和 WK 将输入序列 X 投影到查询空间和键空间,得到 XWQ 和 XWK。
- 计算自注意力分数:(XWQ)(XWK)T,并除以 dk 进行缩放。
- 对自注意力分数进行 Softmax 操作,得到注意力权重。
- 使用权重矩阵 WV 将输入序列 X 投影到值空间,得到 XWV。
- 将 Softmax 的结果乘以 XWV,得到最终的输出。
这个带有权重矩阵的自注意力机制允许模型学习不同位置的查询、键和值的映射关系,从而更灵活地捕捉序列中的信息。在Transformer等模型中,这样的自注意力机制广泛用于提高序列建模的效果。
相关概念推荐阅读:高斯核是什么?,Softmax 函数是什么?
推荐B站视频:注意力机制的本质(BV1dt4y1J7ov),65 注意力分数【动手学深度学习v2】(BV1Tb4y167rb)
Recommend
-
37
自适应注意力机制在 Image Caption 中的应用
-
59
基于注意力机制,机器之心带你理解与训练神经机器翻译系统
-
67
-
62
近期,非循环架构(CNN、基于自注意力机制的 Transformer 模型)在神经机器翻译任务中的表现优于 RNN,因此有研究者认为原因在于 CNN 和自注意力网络连接远距离单词的路径比 RNN 短。本文在主谓一致任务和词义消歧任务上评估了当前 NMT 领...
-
31
介绍 Attention模型形象的比喻就是“图像对焦”。 上图是 Encoder-Decoder 模型,
-
25
作者 | AI小白入门 yuquanle 编辑 | 唐里 本文转自公众号AI小白入门,AI科技评论获授权转载,...
-
3
对注意力机制的一些理解 从 RNN 说起 一个典型的前馈网络结构如下图所示 如果我们简化以下,把每层节点用一个圆圈表示,则如下图 其中 x,h,yx,h,y 分别是输入向量,隐层节点值和输出向量,U,VU,V 分别表示两层的权重矩阵。...
-
2
对注意力机制的一些理解(后篇) 在上一篇文章中,不太正式地介绍了注意力机制,我们从概念上了解到注意力机制的实质是在输出每个预测单词的时候输入单词有不同的权重,本篇文章希望从算法角度来进一步解释。 基于 RNN 的 Encoder-Decoder 结...
-
7
本质思考:时间,管理注意力阶段性达成目标的过程 ...
-
8
.Net 7 托管Main入口的四种写法(茴香豆?)
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK