

“十亿行挑战“显示 Java 可在两秒内处理十亿行文件
source link: https://www.techug.com/post/the-one-billion-row-challenge-shows-that-java-can-process-a-one-billion-rows-file-in-two-seconds/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

“十亿行挑战“显示 Java 可在两秒内处理十亿行文件
2024 年的第一天,Decodable 高级软件工程师 Gunnar Morling 向 Java 社区发起了 “十亿行挑战”(1BRC)。这项持续进行的挑战赛将持续到 1 月底,目的是找到能在最快时间内处理 10 亿行的 Java 代码。到目前为止,领奖台上只有在 2.5 秒内完成处理的算法。
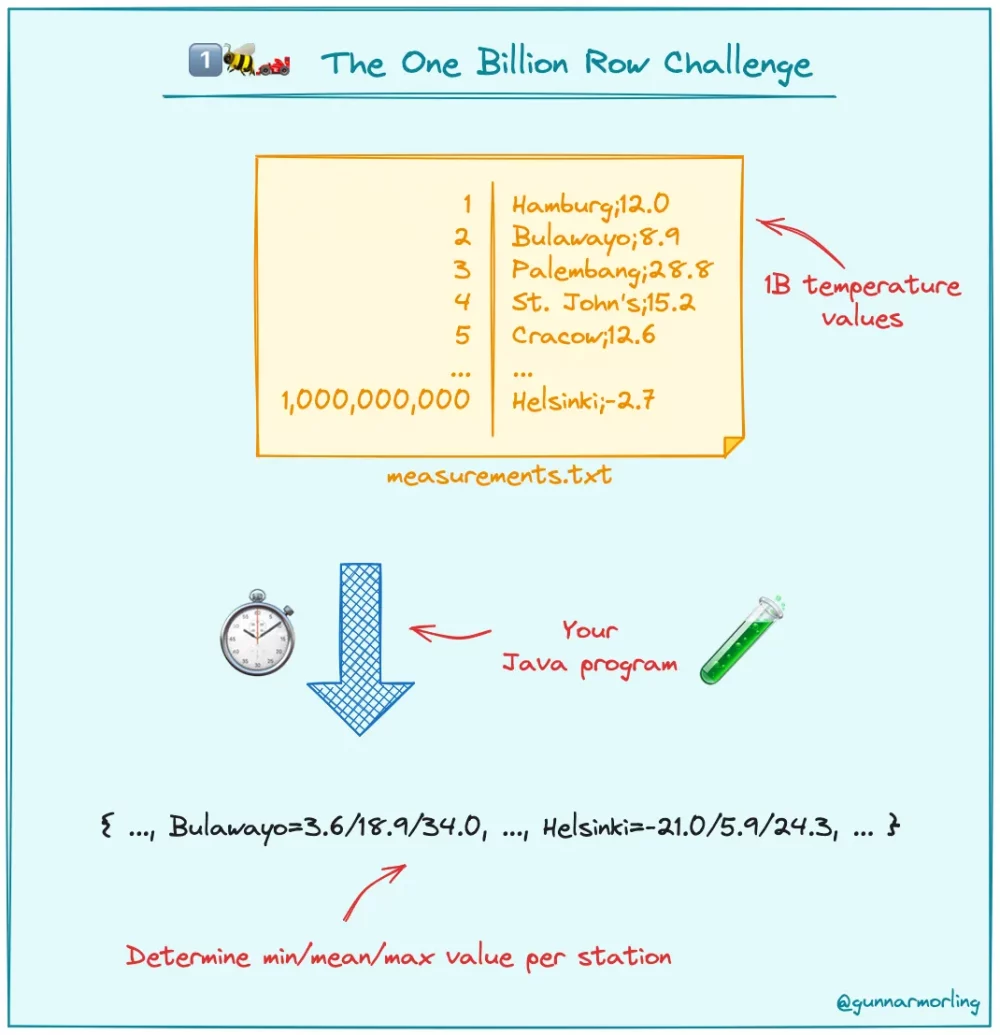
挑战赛的规则很简单:只能使用在任何 Java 发行版上运行的 SDK 功能。因此,解决方案中不包括外部库或数据存储。InfoQ联系了Morling、GoTo首席软件工程师Eliot Barlas、鹿特丹OpenValue公司总监Roy van Rijn以及甲骨文公司软件开发副总裁、GraalVM创始人Thomas Wuerthinger,以更好地了解这项挑战。
InfoQ:这是一个令人兴奋的挑战。能请您描述一下吗?背后的动机是什么?
Morling:1BRC是一项基于简单任务的编码挑战:解析文本文件中的温度测量值,并确定每个气象站的最低、最高和平均温度。需要注意的是:文件中有 1,000,000,000 个条目!
我希望创造机会,探索高性能编程技术、新的 API(如向量 API,它利用了 CPU SIMD 指令)、不同 Java 发行版的功能,以及其他任何可以证明 Java 速度有多快的东西。
InfoQ:怎样才能让所有人都参与到挑战中来?
Morling:从
README文件和克隆repo开始。尝试实现你的解决方案,然后看看其他人也尝试了什么–最终都是为了学习。
InfoQ:在解决方案领域,你遇到过什么令人惊讶的事情吗?
Morling:黑客就是黑客:很多解决方案都针对特定的关键字集(如气象站名称)进行了优化。这只适用于这个特定的数据集。在社区的帮助下,我们明确了目的。
有很多有趣的解决方案:使用 SIMD 和新的 Java 本机内存 API(这是我所希望的),以及高度优化的解析函数,包括 SWAR(寄存器内的 SIMD),这是我没有想到的。现在,研究最快条目的人已经深入到本地优化领域,计算 CPU 指令、评估分支错误预测等。
InfoQ:请描述一下你的解决方案。有没有特别想尝试的技巧或技术?
Eliot Barlas:
我的解决方案是将文件划分为与可用处理器数量相等的范围。每个分区都有一个任务,在不同的线程上计算每个气象站的统计数据。这些任务完成后,最终结果会汇总到一个最终的统计表中。
每个分区中的数据都进行了内存映射,并通过覆盖整个分区字节范围的 MappedByteBuffer 进行访问。任务通过 ByteBuffer 在分区中逐个字节或逐个 int 地移动数据。气象站名称使用 sun.misc.Unsafe 提取并存储为整数序列。
Roy van Rijn:我们的解决方案是不断演进的,一开始是使用 SDK 提供的普通数据结构和 API(如 BufferedInputStream 或 HashMap)。后来逐步演变成使用 Unsafe 直接访问内存。并行性、无分支代码和实施 SWAR(SIMD 作为寄存器)等决策使我的解决方案成为迄今为止挑战赛中最优秀的竞争者之一。在存储方面,我实施了自己的 “非常简单 “的哈希表,并以基于线性探测概念的数组为后盾。
Thomas Wuerthinger: 解决方案的第一部分是根据目标处理器上可用的内核数量来分割工作负载,以便实现并行化。它利用 Java 的功能对输入文件进行内存映射,以实现最高效的直接内存访问。解析数据的最内层循环采用的技术是尽量创建没有分支的代码,而是执行一些复杂的算术和位操作。对于这个特定问题,由于输入的随机性,分支经常会被处理器错误预测,因此避免分支是最大化性能的关键。
InfoQ:是否有可能进一步改进你们的解决方案?
Barlas:我一直在关注巴拿马项目,但1BRC提供了一个以应用方式探索外存能力的机会。[……]我还没有成功地利用巴拿马项目的向量应用程序接口(Project Panama Vector API)实现提速。例如,早期我曾尝试使用 ByteVector API 来执行快速的气象站名称比较。我想使用其他类型的矢量或结合 MemorySegment 接口重新研究这个问题。
Wuerthinger:现在可能的改进在很大程度上取决于目标硬件。具体来说,我们可以在内存带宽、计算带宽和分支预测依赖性等方面进行权衡。
Roy van Rijn:在顶层,方法是相似的。我目前正在尝试探索的概念是 “机械共鸣mechanical sympathy“,试图以最适合我们正在测试的机器的方式改进需要执行的指令。
InfoQ:对于这个有趣的年初挑战,你的结论是什么?
Morling:可以肯定的是,Java、其生态系统和社区比以往任何时候都更加蓬勃发展!看到有这么多人参加了挑战,包括一些非常知名的开发者,这实在是太令人鼓舞了。每个人都在学习:通过编码或阅读代码。社区的帮助确实让人谦卑,也让挑战赛有了如此大的发展。
挑战赛受到了编码员社区的热烈欢迎,Morling 形容挑战赛的成功 “远远超出了我的预期”。尽管领奖台似乎被运行在 GraalVM 上的解决方案所占据,但也有使用 OpenJDK 构建、Amazon Corretto 或 Eclipse Temurin 提交的解决方案。Morling 进一步评论说:”Graal 非常适合手头的任务,可以免费提供额外百分之几的性能。
挑战超越了 Java 生态系统解决方案的界限,这些解决方案是用 Rust、Go、C++ 甚至 SQL 和 Shell 编写的。
Morling 对社区和提供评估机器的 Decodable 表示感谢。
本文文字及图片出自 The One Billion Row Challenge Shows That Java Can Process a One Billion Rows File in Two Seconds
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK