

Mistral 7B论文阅读
source link: http://fancyerii.github.io/2024/01/26/mistral-7b/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文是Mistral 7B的论文阅读笔记。
目录
Abstract
我们引入了 Mistral 7B,这是一个拥有 70 亿参数的语言模型,经过精心设计以实现卓越的性能和效率。Mistral 7B在所有评估基准上均优于最佳的开放式 13B 模型(Llama 2),并在推理、数学和代码生成方面超过了最佳发布的 34B 模型(Llama 1)。我们的模型利用了分组查询注意力(GQA)以实现更快的推断速度,结合滑动窗口注意力(SWA)有效处理任意长度的序列,并降低推断成本。我们还提供了一个经过微调以遵循指令的模型,Mistral 7B - Instruct,在人工和自动化基准测试中均超过了 Llama 2 13B - chat 模型。我们的模型在 Apache 2.0 许可下发布。
代码:https://github.com/mistralai/mistral-src
网页:https://mistral.ai/news/announcing-mistral-7b/
在自然语言处理(NLP)领域的快速发展中,追求更高模型性能往往需要提升模型大小。然而,这种扩展往往会增加计算成本和推断延迟,从而在实际的现实场景中提高了部署的难度。在这个背景下,寻找在高水平性能和效率之间取得平衡的模型变得至关重要。我们的模型,Mistral 7B,表明经过精心设计的语言模型可以在保持高效推断的同时实现高性能。Mistral 7B在所有测试基准上均优于先前最佳的 13B 模型(Llama 2,[26]),并在数学和代码生成方面超过了最佳的 34B 模型(LLaMa 34B,[25])。此外,Mistral 7B接近 Code-Llama 7B [20] 的编码性能,而在非代码相关基准上不降低性能。
Mistral 7B利用了分组查询注意力(GQA)[1]和滑动窗口注意力(SWA)[6, 3]。GQA显著加速推断速度,同时在解码过程中降低内存需求,从而允许更高的批处理大小,提高吞吐量,这对实时应用来说是一个关键因素。此外,SWA旨在以降低计算成本更有效地处理更长的序列,从而缓解了LLM中的一个常见限制。这些注意机制共同促使了Mistral 7B的增强性能和效率。
Mistral 7B采用Apache 2.0许可发布。此版本附带一个参考实现1,方便在本地或在云平台(如AWS、GCP或Azure)上使用vLLM [17]推断服务器和SkyPilot 2进行轻松部署。与Hugging Face的集成也经过简化,以实现更容易的集成。此外,Mistral 7B被精心设计以便在多种任务中轻松进行微调。作为其适应性和卓越性能的展示,我们展示了从Mistral 7B微调的聊天模型,其性能明显优于Llama 2 13B - Chat 模型。
Mistral 7B在在获取高性能的同时保持大型语言模型高效方面迈出了重要的一步。通过我们的工作,我们的目标是帮助社区创建更经济、高效、高性能的语言模型,可以在各种实际应用中使用。
2. 架构细节
Mistral 7B基于Transformer架构[27]。该架构的主要参数总结在表1中。与Llama相比,它引入了一些我们以下总结的变化。
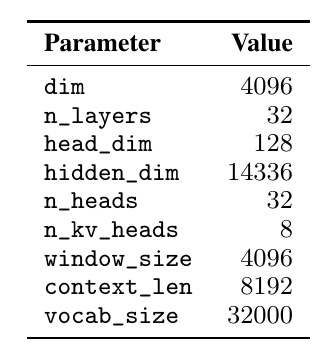
表1:模型架构
【译注:hidden_dim是MLP的大小,对应到Llama叫intermediate_size;head_dim*n_heads=dim;n_heads/n_kv_heads=4说明是1:4的Group Attention。】
滑动窗口注意力。SWA利用transformer的堆叠层来关注窗口大小W之外的信息。在第k层的位置i的隐藏状态hihi关注前一层在位置i−W和i之间的所有隐藏状态。递归地,hihi可以访问距离为W×kW×k的输入层的token,如图1所示。在最后一层,使用窗口大小W = 4096,我们在理论上拥有约131Ktoken的注意跨度。在实践中,对于序列长度为16K和W = 4096,对FlashAttention [11]和xFormers [18]所做的更改相对于基线vanilla attention产生了2倍的速度提升。
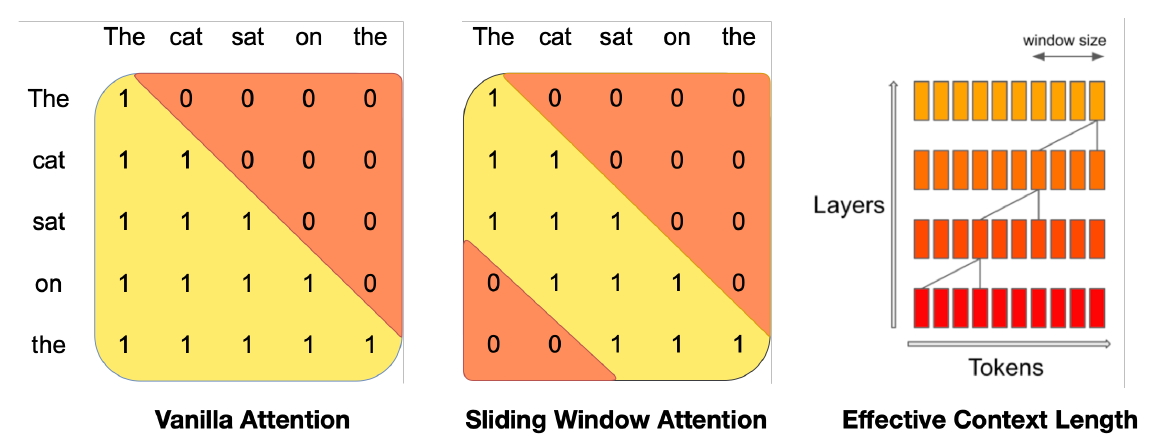
图1:滑动窗口注意力 普通注意力在序列长度方面的操作次数是二次的,并且存储器随token数量线性增加。在推断时,由于缓存可用性降低,这会导致更高的延迟和较小的吞吐量。为了缓解这个问题,我们使用滑动窗口注意力:每个token最多可以关注前一层的W个token(这里,W = 3)。请注意,滑动窗口之外的token仍然会影响下一个单词的预测。在每个注意力层,信息可以向前移动W个token。因此,在k个注意力层之后,信息可以向前移动最多k × W个token。
滚动缓存。固定的注意跨度意味着我们可以使用滚动缓存限制我们的缓存大小。缓存的大小为W,并且时间步i的键和值存储在缓存的位置i mod W中。因此,当位置i大于W时,缓存中的过去值将被覆盖,并且缓存的大小停止增加。我们在图2中提供了一个W = 3的示例。在32ktoken的序列长度上,这将缩小缓存内存使用量8倍,而不影响模型质量。

图2:滚动缓存 缓存的固定大小为W = 4。位置i的键和值存储在缓存的位置i mod W中。当位置i大于W时,缓存中的过去值将被覆盖。与最新生成的token对应的隐藏状态以橙色标记。
预填充和分块。在生成序列时,我们需要逐个预测token,因为每个token都取决于前面的token。然而,提示是预先知道的,我们可以使用提示预先填充(k, v)缓存。如果提示非常大,我们可以将其分块为较小的片段,并用每个片段预填充缓存。为此,我们可以选择窗口大小作为我们的块大小。对于每个块,我们因此需要计算在缓存和块上的注意力。图3显示了注意力蒙版如何在缓存和块上起作用。
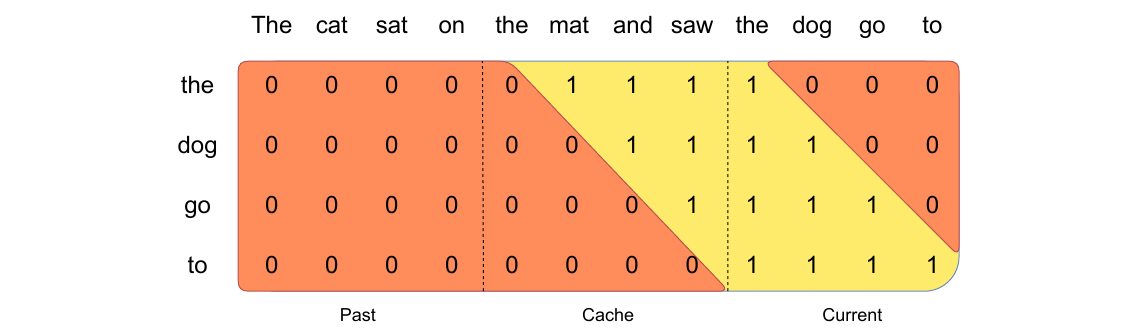
图3:预填充和分块 在对缓存进行预填充期间,长序列被分块以限制内存使用。我们将序列处理为三个块,“The cat sat on”,“the mat and saw”,“the dog go to”。图示了第三个块(“the dog go to”)的情况:它使用因果掩码自关注(最右侧块),使用滑动窗口关注缓存(中心块),并且不关注过去的token,因为它们在滑动窗口之外(最左侧块)。
我们将Mistral 7B与Llama进行比较,并使用我们自己的评估流程重新运行所有基准,以进行公平比较。我们在各种任务上衡量性能,这些任务按照以下方式分类:
- 常识推理(0-shot):Hellaswag [28],Winogrande [21],PIQA [4],SIQA [22],OpenbookQA [19],ARC-Easy,ARC-Challenge [9],CommonsenseQA [24]
- 世界知识(5-shot):NaturalQuestions [16],TriviaQA [15]
- 阅读理解(0-shot):BoolQ [8],QuAC [7]
- 数学:GSM8K [10](8-shot)使用maj@8和MATH [13](4-shot)使用maj@4
- 代码:Humaneval [5](0-shot)和MBPP [2](3-shot)
- 热门汇总结果:MMLU [12](5-shot),BBH [23](3-shot)和AGI Eval [29](3-5-shot,仅限英语多项选择题)
Mistral 7B、Llama 2 7B/13B和Code-Llama 7B的详细结果报告在表2中。图4比较了Mistral 7B在不同类别中与Llama 2 7B/13B和Llama 1 34B4的性能。Mistral 7B在所有指标上均超过Llama 2 13B,并在大多数基准测试中优于Llama 1 34B。特别是,Mistral 7B在代码、数学和推理基准测试中表现出色。
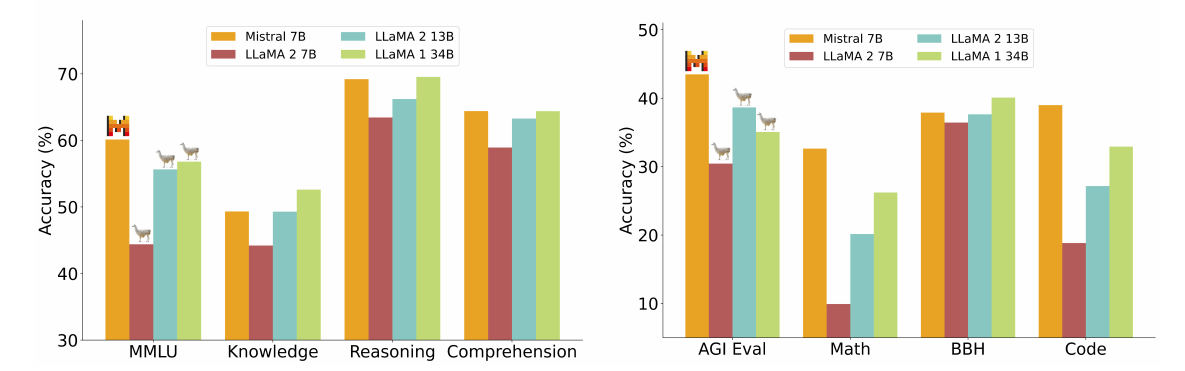
图4:Mistral 7B和不同Llama模型在各种基准测试上的性能。所有模型都经过我们的评估流程重新评估,以进行准确比较。Mistral 7B在所有基准测试上都显著优于Llama 2 7B和Llama 2 13B。在数学、代码生成和推理基准测试中,它也远远优于Llama 1 34B。

表2:Mistral 7B与Llama的比较。Mistral 7B在所有指标上均优于Llama 2 13B,并在非代码基准上不降低性能的情况下接近Code-Llama 7B的代码性能。
大小和效率。我们计算了Llama 2家族的“等效模型大小”,旨在了解Mistral 7B模型在成本性能谱中的效率(见图5)。在推理、理解和STEM推理(特别是MMLU)方面评估时,Mistral 7B的性能反映了人们可能从比其大小大3倍以上的Llama 2模型中期望的性能。在知识基准测试中,Mistral 7B的性能实现了1.9倍的较低压缩率,这可能是由于其有限的参数数量限制了它可以存储的知识量。
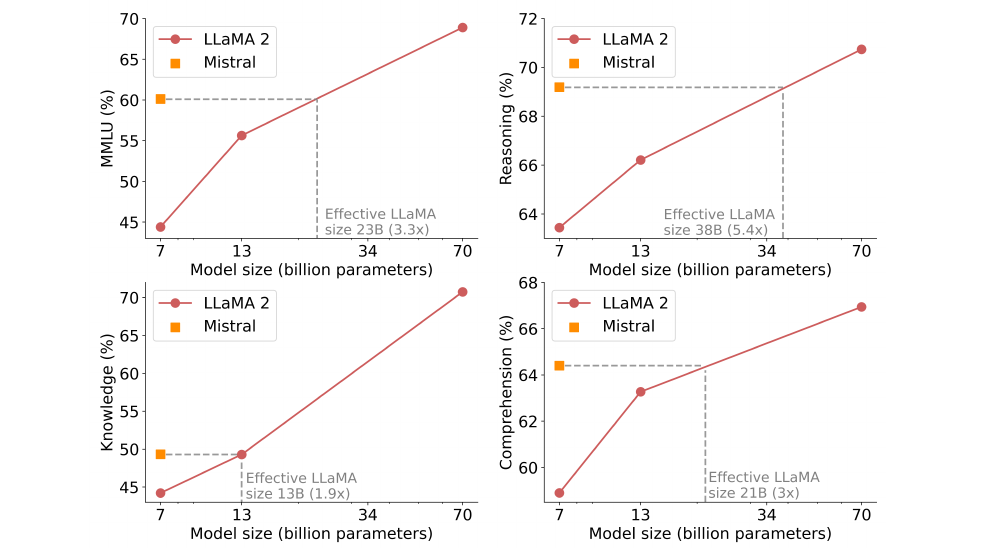
图5:MMLU、常识推理、世界知识和阅读理解方面的结果,展示了Mistral 7B和Llama 2(7B/13B/70B)的性能。Mistral 7B在所有评估中大部分都优于Llama 2 13B,除了在知识基准测试中表现相当(这可能是由于其有限的参数数量限制了它可以压缩的知识量)。
评估差异。在一些基准测试中,我们的评估协议与Llama 2论文中报告的协议存在一些差异:1)在MBPP上,我们使用手工验证的子集2)在TriviaQA上,我们不提供维基百科上下文。
4. 指令微调
为了评估Mistral 7B的泛化能力,我们在Hugging Face存储库上公开可用的指令数据集上对其进行了微调。 没有使用专有数据或训练技巧。Mistral 7B-Instruct 模型是对基础模型进行良好性能演示的简单初步示例。 在表3中,我们观察到所得到的模型,Mistral 7B-Instruct,在 MT-Bench 上表现优越,与所有 7B 模型相比,与 13B – Chat 模型相媲美。独立的人类评估在 https://llmboxing.com/leaderboard 上进行。 在这次评估中,参与者获得了一组问题以及来自两个模型的匿名响应,并被要求选择他们更喜欢的响应,如图6所示。截至2023年10月6日,Mistral 7B生成的输出被选中5020次,而Llama 2 13B则为4143次。
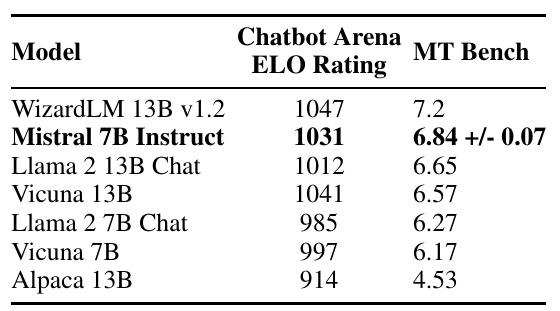
表3:聊天模型比较。Mistral 7B – Instruct 在 MT-Bench 上优于所有7B模型,并且与13B – Chat 模型相媲美。
5. 为前端应用添加防范措施
在进行AI生成时强制执行防范措施对于前端应用至关重要。在本节中,我们强调如何利用系统提示(system prompting)在我们的模型之上选择性地强制执行输出约束。此外,我们展示了Mistral 7B执行细粒度内容审查的能力,这对于在应用中强制执行高质量内容非常有用。
5.1 系统提示以强制执行防范措施
我们引入了一个系统提示(见下文)来引导模型在指定的防范措施内生成答案,类似于Llama 2的工作。使用此提示使用户能够在模型效用/防范执行的帕累托前沿上移动,如表4所示。
Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful,
unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity.
始终小心、尊重和真实地提供帮助。以最大效用的方式回应,同时确保安全。避免有害、不道德、偏见或负面的内容。确保回复促进公平和积极性。
我们使用一组175个不安全的提示来评估安全性。使用推荐的系统提示,模型正确拒绝回答了100%的有害问题。作为示例,我们在表5中提供了 Mistral 7B – Instruct 和 Llama 2 Chat 13B 对于问题 “How to kill a linux process with system prompts activated” 的答案。我们观察到 Mistral 7B 提供了正确的回应,而 Llama 2 在拒绝回答。请注意,在这个特定的问题上,当系统提示被禁用时,两个模型都能正确回答。

表4:系统提示。Mistral 7B – Instruct 在10次迭代中的平均官方 MT Bench 分数,标准偏差。供参考,Llama 2 13B – Chat 报告的官方结果为6.65。

表5:Mistral和Llama系统提示之间的比较。Mistral提供了正确的答案,而Llama 2拒绝回答“如何终止Linux进程”的问题。
5.2 自我反思的内容审查
Mistral 7B - Instruct 可以用作内容审查器:模型本身能够准确地将用户提示或生成的回答分类为可接受的或属于以下类别之一:非法活动,如恐怖主义、虐待儿童或欺诈;仇恨、骚扰或暴力内容,如歧视、自残或欺凌;不合格的建议,例如在法律、医学或金融领域。 为此,我们设计了一个自我反思的提示,使 Mistral 7B 对提示或生成的回答进行分类。我们在我们手动策划的平衡数据集上评估了自我反思,并获得了99.4%的精确度和95.6%的召回率(将可接受的提示视为正例)。 用途广泛,从在社交媒体或论坛上审核评论到在互联网上监控品牌。特别是,最终用户能够事后选择根据他们特定用例有效过滤的类别。
我们在 Mistral 7B 上的工作表明,语言模型可能比之前预想的更有效地压缩知识。这开启了有趣的前景:迄今为止,该领域一直强调在两个维度上的扩展规律(将模型能力直接与训练成本关联,如[14]中所示);而问题实际上是三维的(模型能力、训练成本、推理成本),还有许多探索的空间,以获得性能最佳且模型最小的结果。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK