

模型服务化(未完成)
source link: https://qiankunli.github.io/2024/01/23/trition.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

模型服务化(未完成)
2024年01月23日模型推理服务化框架Triton保姆式教程(一):快速入门Triton 是 Nvidia 发布的一个高性能推理服务框架,可以帮助开发人员高效轻松地在云端、数据中心或者边缘设备部署高性能推理服务。其中主要特征包括:
- 支持多种深度学习框架(Triton 称之为backend,tf、pytorch、FasterTransformer都有对应backend),Triton Server 可以提供 HTTP/gRPC 等多种服务协议。同时支持多种推理引擎后端,如:TensorFlow, TensorRT, PyTorch, ONNXRuntime 等。Server 采用 C++ 实现,并采用 C++ API调用推理计算引擎,保障了请求处理的性能表现。
- 模型并发执行
- 动态批处理(Dynamic batching)
- 有状态模型的序列批处理(Sequence batching)和隐式状态管理(implicit state management)
- 提供允许添加自定义后端和前/后置处理操作的后端 API
- 支持使用 Ensembling 或业务逻辑脚本 (BLS)进行模型流水线
- HTTP/REST和GRPC推理协议是基于社区开发的KServe协议
- 支持使用 C API 和 Java API 允许 Triton 直接链接到您的应用程序,用于边缘端场景
- 支持查看 GPU 利用率、服务器吞吐量、服务器延迟等指标 PS:基本上对一个推理服务框架的需求都在这里了。
深度学习部署神器——triton-inference-server入门教程指北 未细读。
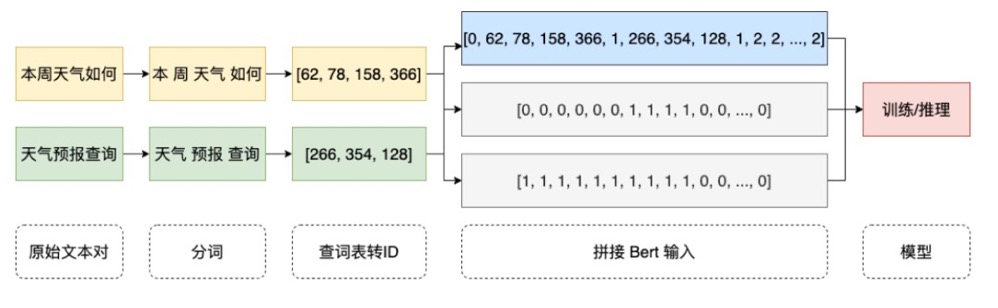
PyTorch/TensorFlow 等框架相对已经解决了模型的训练/推理统一的问题,因此模型计算本身不存在训推一体的问题了。完整的服务通常还存在大量的预处理/后处理等业务逻辑,这类逻辑通常是把各种输入经过加工处理转变为 Tensor,再输入到模型,之后模型的输出 Tensor 再加工成目标格式。核心要解决的问题就是:预处理和后处理需要提供高性能训推一体的方案。
2023年10月19日,NVIDIA正式宣布TensorRT-LLM开放使用,TensorRT-LLM的主要特性有:
- 支持多GPU多节点推理
- 包含常见大模型的转换、部署示例(LLaMA系列、ChatGLM系列、GPT系列、Baichuan、BLOOM、OPT、Falcon等)
- 提供Python API支持新模型的构建和转换
- 支持Triton推理服务框架
- 支持多种NVIDIA架构:Volta, Turing, Ampere, Hopper 和Ada Lovelace
- 除了FastTransformer中针对transformer结构的优化项,新增了多种针对大模型的优化项,如In-flight Batching、Paged KV Cache for the Attention、INT4/INT8 Weight-Only Quantization、SmoothQuant、Multi-head Attention(MHA)、Multi-query Attention (MQA)、Group-query Attention(GQA)、RoPE等。 大模型推理实践-1:基于TensorRT-LLM和Triton部署ChatGLM2-6B模型推理服务
Related Issues not found
Please contact @qiankunli to initialize the comment
Recommend
-
53
原文请访问 5 Things You Have Never Done with a REST Specification 。 大多数的前后端开发人员以前就已经...
-
49
作者:何保实入驻商家涉违法销售违禁药品风波下,医药营销平台“药师帮”对于相关问题进行了修正。不过,根据本报的后续调查,问题仍然存在。作为中国知名的药品B2B第三方销售服务平台,11月27日,本报报道了“药师帮”入驻商家,涉违法销售毒性、终止
-
46
图片来源:视觉中国 文|智能相对论(ID:aixdlun),作者|颜璇 随着移动互联网流量红利的消失,用户下沉是互联网行业的必...
-
54
README.md RxHttp RxHttp是基于OkHttp的二次封装,并于RxJava做到无缝衔接,一条链就能发送一个完整的请求。 主要功能如下: 支持Get、Post、Put、De...
-
41
-
31
Jacob Walker 2019 年 4 月 18 日 介绍 在我的第一篇文章Goroutine 泄露 中,我提到并发编程是一个很有用的工具,但是使用它也会带来某些非并发编程中不存在的陷阱。为了继续这个主题,我将介绍一个新的陷阱,这个陷阱...
-
19
二维数组中的查找 240. Search a 2D Matrix II https://leetcode.com/problems/search-a-2d-matrix-ii/ Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the...
-
20
新浪科技讯北京时间12月30日晚间消息,据国外媒体报道,美国投资银行Cowen今日发布报告称,特斯拉今年将交付大约35.6万辆电动汽车,略低于公司之前预期的36万辆至40万辆。Cowen分析师杰弗里·奥斯本(JeffreyOsborne)在
-
25
相关新闻:小米、美团申请专项再贷款?央行初步调查:未列入名单央行:小米美团因参与防疫需要贷款银行会给予支持美团回应申请抗疫专项再贷款:此前传言多处不实新浪科技讯2月16日午间消息,针对“获得50亿疫情贷款”传闻一事,小米今日在官微发布声明称
-
20
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK