

号称中文评测超越 GPT-4,百川智能发布超千亿参数大模型 Baichuan 3
source link: https://www.ifanr.com/1574506
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

号称中文评测超越 GPT-4,百川智能发布超千亿参数大模型 Baichuan 3
「清华系」大模型创业公司又放大招了。
1 月 29 日,由搜狗创始人王小川(清华本硕)创立的百川智能,正式发布了超千亿参数的大语言模型 Baichuan 3。该模型不仅在多个权威测试中表现卓越,更是在中文指标上超越了 GPT-4。
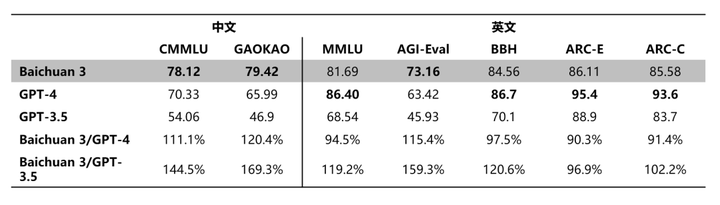
测试结果显示,在 MMLU 等多个英语基准测试中,Baichuan 3 达到接近 GPT-4 九成的水平。在 CMMLU、GAOKAO 等多个中文基准测试中,Baichuan 3 则是遥遥领先,大幅度超越了 GPT-3.5,也全面超越了 GPT-4。

在数学和代码的榜单测试,以及 MT-Bench、IFEval 等对齐榜单的评测中,Baichuan 3 均超越了 GPT-3.5、Claude 等大模型,也位居行业前列,仅略逊于 GPT-4。
AI+医疗是大模型的关键应用领域。医疗问题复杂多变、知识更新迅速、准确性要求高,需要模型在文本、图像、声音等方面全面展现强大的理解和决策能力。
因此,百川智能将其视为大模型的「皇冠上的明珠」。
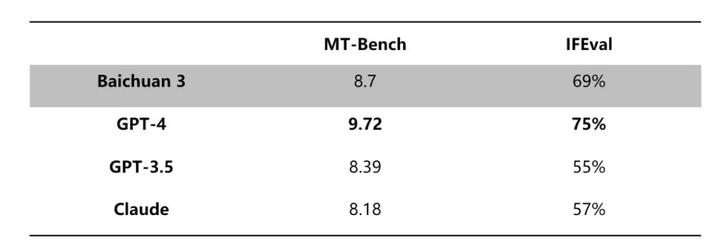
Baichuan 3 在医疗领域进行了大量训练和优化,训练后的效果也很显著,其在 MCMLE、MedExam、CMExam 等中文医疗任务的表现超过 GPT-4,USMLE、MedMCQA 等英文医疗任务也接近 GPT-4 水平,一举夺下了医疗能力最强的中文大模型称号。
据官方透露,为了加强这方面的训练,Baichuan 3 在模型预训练阶段就构建了超过千亿 Token 的医疗数据集,涵盖从理论到实践各个方面的医学知识,以确保在医学领域的专业度和知识深度。
在推理阶段,百川智能通过准确描述任务、恰当选择样本,优化了针对医疗知识的 Prompt,也使得模型输出更加准确以及符合逻辑的推理步骤。
语义理解和文本生成是大模型最基础的底层能力,可以被视为人工智能模型的核心支柱。王小川曾指出,语言是人类认知世界的边界,从技术实现层面来看,感知并理解语言比图像和视频更具难度。

在他看来,牛顿使用三大运动定律将宇宙万物间的规律抽象为数学表达式,这对人类认知是一次重大飞跃。今天的大模型也是如此。掌握语言背后的规律,就意味着掌握了知识本身,以及人类的思考、交流和文化。
语言模型就像原子弹一样,它可能会点燃一个氢弹。未来还会有更好的建模,这是我们在未来需要做的功课。
Baichuan 3 强大的中文语言处理能力是其最大亮点之一。即便面对格式复杂、结构严密、韵律丰富的宋词等高难度文体,Baichuan 3 也能生成内容工整、对仗到位、韵脚和谐的作品。
官方表示,Baichuan 3 结合「RLHF&RLAIF」以及迭代式强化学习的方法使大型语言模型在诗歌创作方面能力大幅提升。相比业内其他顶级模型,其创作可用性提高超过 5 倍,文学造诣完胜 GPT-4。
▲体验链接:https://www.baichuan-ai.com/
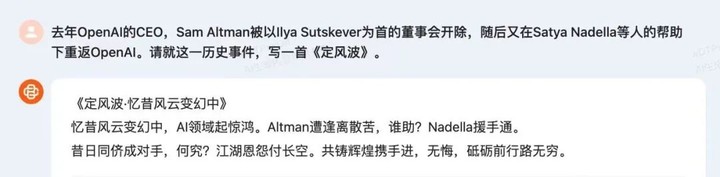
例如,在官方的演示中,让 Baichuan 3 就 OpenAI「宫斗大戏」生成一首定风波,它中英文夹杂的表现倒是别有一番趣味👇
《定风波·忆昔风云变幻中》
忆昔风云变幻中,AI 领域起惊鸿。Altman 遭逢离散苦,谁助? Nadella 援手通。
昔日同侪成对手,何究?江湖恩怨付长空。共铸辉煌携手进,无悔,砥砺前行路无穷。
值得一提的是,百川智能在开源的理念上与其他大模型公司有所不同。王小川在 Baichuan 2 的发布会上的一段讲话便可见一斑。
Llama 2 开源模型的时代已经过去了。我们现在可以获得比 Llama 更友好且能力更强的开源模型,能够帮助扶持中国整个生态的发展。
Llama 2 虽标榜开源,但实际仅限英语环境使用。相比之下,Baichuan 2 系列面向中文用户全面开放,在中英双语环境下均提供免费服务。
百川智能已经陆续开源了 Baichuan-7B、Baichuan-13B、Baichuan2-7B、Baichuan2-13B 等四款低成本部署,支持中英双语的大模型。
此外,当被媒体问及如何做到开源和商业化闭源模型齐头并进、快速迭代时,百川智能技术联合创始人陈炜鹏透露,这得益于他们丰富的搜索技术经验能够被快速迁移应用到大模型研发。
从技术层面看,搜索与大模型有许多共通的技术基础。比如在模型训练的关键数据处理环节,团队根据在搜索领域的经验,进行数据筛选优化,实现了过滤重复、提升质量,从而为模型提供高质量的数据支撑。
去年九月份,当谈到国内大模型与 ChatGPT 的差距时,王小川作出了这样的判断:
GPT-4 一直在不断进步,最近它们推出语音和图像功能,引起了很大的轰动。从时间角度来看,我们认为可能需要两年或三年的时间,才能更接近 GPT-4 目前的水平。
当然,在大模型竞争的刀刃相向中,仅仅停留在技术探索阶段还不够,百川智能下一步仍然是需要加快技术向应用场景的转化。
王小川不止一次在公开场合提到「超级应用」,他甚至预测今年中国会有若干个超级应用产生。而这也或将成为大模型的下一场战事。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK