

领域模型实例分析之-论坛
source link: https://www.jdon.com/43021.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

领域模型实例分析之-论坛
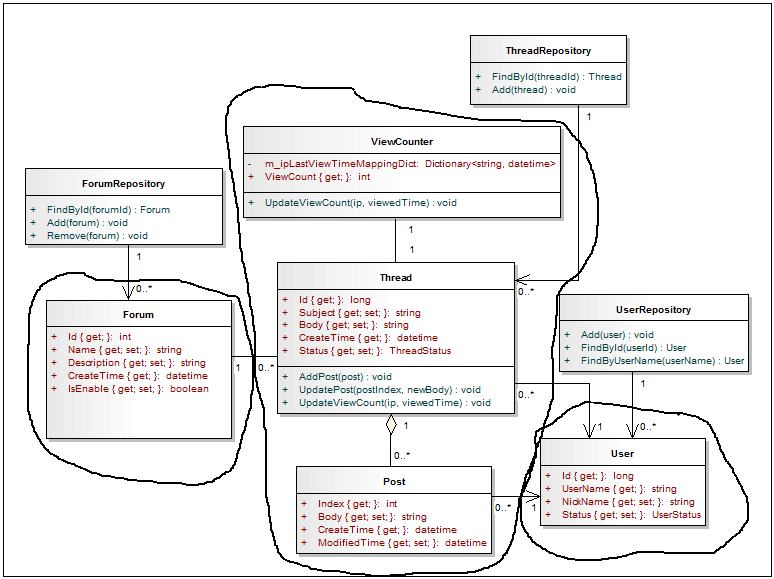
说明:
1)上面的领域模型在设计时借鉴了DDD和CQRS的思想;
2)利用DDD的思想来设计实体、值对象、聚合、聚合根;图中有三个聚合根,分别是Forum、Thread、User;其中Thread聚合根聚合了Post和ViewCounter两个对象;Post是Thread的回复,显然Post离开Thread没有意义,但是Post在Thread聚合内有一个本地标识,即只要在当前Thread下唯一即可,不需要全局唯一。
3)由于CQRS思想的引入,可以确保我们在设计领域模型时不必考虑由于对象关联而产生的统计信息该如何存放,从而让领域模型更精简明了;如帖子的总回复数、最新回复时间、最新回复人,等等,这些信息只是统计信息,只用于在界面上显示,即我们只有在查询时才需要这些信息,因此可以在CQRS的Q端实现。
4)由于CQRS思想的引入,也可以让仓储更精简,不需要提供用于查询领域对象并在界面上显示结果的接口,而只需要提供用于查询单个聚合根或Add以及Remove的操作;
5)上面的领域模型只关注一个标准论坛的基本功能;
希望大家能多给些意见。之前学了很多的理论知识,现在是该通过一些建模例子锻炼一下的时候了。
[该贴被tangxuehua于2011-10-27 00:53修改过]
memeory image内存映像
不变性immutablity设计
经过一些后续的思考后,我发现上面的领域模型中的帖子(Thread)的一些职责的设计有点问题。详细分析如下:
如果直接让帖子(Thread)维护回复(Post),那么当我们要添加一个回复时,必须把帖子的所有回复取出来,然后才能添加,这样势必会导致性能低下。本来依据信息专家模式,我们应该将添加回复的职责交给帖子来完成,但是因为遇到性能问题,我们必须考虑选择其他方案来即能在业务上保持帖子和回复的业务关系完整性,又不会有性能问题。
经过我的思考,我认为在ThreadRepository中完成这个职责比较合理。原因是:ThreadRepository是维护Thread的,因此它知道所有的Thread以及每个Thread聚合的内部细节,否则ThreadRepository无法对Thread进行持久化。所以,我们可以给ThreadRepository增加一个职责:AddThreadPost(threadId, post),该职责表示为某个帖子增加一个回复。AddThreadPost内部实现时不必先把Thread取出来到内存,而是可以直接操作关系数据库;依照这个推理,UpdatePost方法也可以这样实现;
我的这个解决方案如何呢?
从我上面的分析,大家有没有看到一个规律呢?那就是分析业务时,领域对象之间的关系并不代表在设计阶段必须在领域对象之间通过引用来表达,因为这很可能会导致性能低下,DDD告诉我们领域模型设计时不仅要考虑如何实现业务需求,也要遵循一些基本的软件设计原则以及性能方面的一些问题。实际上我认为领域对象之间的关系是从业务角度理解的一种业务关系,而在OO设计阶段并非一定要通过对象关联来表达这种关系,而可以采用其他替代方案但必须同样也要能表达业务关系。
从中我总结的规律是:
1)这种情况发生在1:N的时候;
2)当N这一端的明细项会在1这一段的对象之后逐步添加时;
3)N很大时;
这种情况下,我们往往需要采用上面的方案。
举个例子:
电子商务系统中,创建一个订单Order时,我们可以把Order的明细项OrderItem作为一个集合放在Order内,因为OrderItem总是和Order一起创建,不会在Order被创建后再逐步添加到Order中;
而在论坛中则不同,我们首先创建一个帖子Thread,然后回复会在Thread被创建后慢慢逐个增加,此时在当Post很多的时候,如果还是为Thread建立一个Post的集合的话,会导致性能低下。
[该贴被tangxuehua于2011-10-28 12:42修改过]
你可以这么想,回复不是查出来的,而是一早就存在了,咋样?“如果还是为Thread建立一个Post的集合的话”,我只能说,这只能更快,不会更慢。你说的性能底下,只会存在于对象和数据间的转换过程,很多人认为“转换”是必然,是真理,不敢去打破,至于敢于打破的人就想到了IMDG(In-Memory Data Grid)、内存模型等。
额外地,运用key/value方式去思考,可能会更好,实体就是一个key,这与jivejdon查询是查id集合的思维是一样的。
还有关于“也要遵循一些基本的软件设计原则以及性能方面的一些问题”,这个是领域思维一直想摆脱的,我们思考领域逻辑,和用代码来描述逻辑时,不应该受到技术性因素影响。
这样下去 ThreadRepository和ThreadService或ThreadManager等非模型之外的工具类有什么区别呢?最后Thread还是变成数据,被这些工具类操作来操作去,非常被动,这失去MDD模型驱动的本质。
Thread当然应该知道自己内部规则,为了性能问题,可以把POST的ID代表形成一个树形结构放在内存中,以后有新的回复,追加append新ID到内存中这个树形结构就可以,这类似X++操作。JiveJdon的TreeModel模型类就是做这个的。
当然,如果是SpeedVan所说,如果是一个很大内存,我们完全可以认为Thread的所有Post集合都在内存中,DDD提出考虑设计性能是完全基于对象的,而对象如何持久的性能是不属于基于对象的操作,而是应该对象内部机制,我们不能把我们基于数据库性能设计的思维习惯带到DDD中。
我理解你们所说的,听你们这么说来,我确实在有些方面理解错了。把数据库方面的性能问题考虑进了DDD建模的过程中。但是如果在Thread中只保留PostID的集合的话,如果我想更新某个Post的内容怎么做?谁去获取Post的内容?另外如果用In Memory的方式话,是不是不太符合实际?难道用想用DDD的设计方式,只能用In Memory的方式才能做到真正的OO吗?难道用传统数据库来持久化对象的方式就无法做到好的DDD了吗?Evans也说了,实体是有生命周期的,其中就包括了状态持久化到持久化介质或从持久化介质中重建。所以,我们不能用In Memory这种方式来“逃避”现实。对象状态存储起来然后再重建是一种很正常的思维逻辑,我们不能指望任何应用程序都能做到In Memory方式。
你的问题太多了,不是一个方向上问题,很难跳跃回答哦,只回答你这个问题,更新某个Post,只要根据PostID这个Key在缓存(In-memeory)中获得其Post对象,然后更新这个Post对象。
Post中不同部分更新方式不一样,如果是Post的值对象,依据不变性直接替换,如果是一个Tree数据结构,采取追加append方式,见:不变性immutablity设计。
不过,我可以肯定回答,只有In Memory的方式才能做到真正的OO,因为对象生活在内存中,我在以前帖子已经嚼烂舌头说这句话。
如果你担心当机等问题,你可以把对象状态持久保存在数据库,然后启动时重建,但这一过程只是技术底层层面,就象windows操作系统启动时要加载一些东西到内存,关机时要正常关机写入一些东西到磁盘上一样,这些动作边界是可以超越我们的应用程序的,你也可以在你的应用系统启动或停止做同样这些重建和持久动作,但是他们不应该纳入正常业务活动分析实现中,考虑持久在DDD中是次要的,不是主要的。
老外最新这篇文章有说服力:MemoryImage内存图像。其中有一段:
But the important property for memory images is that it means that there is no longer any need to worry about keeping the application state in an up-to-date persistent store. Instead you can just keep the application state in main memory. Should the process crash, you can rebuild it from the events
memory images 的主要好处是:它意味着再也不需要将应用系统的状态保存在一个时刻更新的持久化存储系统,而是你应该让应用状态保持在主内存中,当处理发生冲突崩溃,你可以从Event事件开始重新构建(Event Sourcing)
我刚刚翻译了这篇文章,见这里memeory image内存映像
[该贴被banq于2011-10-29 11:26修改过]
经过最近的一段时间的思考后,我认为帖子和回复是两个独立的聚合根。因为:
1)帖子和回复的关系比较弱;没有聚合的关系,只是普通的关联关系,这点不像订单和订单项,订单和订单项之间才是内聚的关系;
2)帖子不关系它下面有多少个回复;
3)虽然从依赖性来说,回复离不开帖子,从生命周期来说,回复的生命周期也从属于帖子;但这并不表示回复必须要被内聚在帖子中;
4)Evans告诉我们,聚合内实体之间应该是因为不变性(Invariant)而聚合在一起的,而不是因为简单的关联关系或生命周期等原因;
5)因为帖子和回复之间并无不变性约束;新增一个回复时,完全可以不必让帖子知道,帖子也不关心是否有人回复它了;帖子和回复都可以独立变化;
6)至于帖子和回复之间的关联如何表示,我现在认为应该用ID表示,只要在回复上设计一个帖子ID即可,至于帖子是否应该有一个回复ID的列表,我觉得没必要,要这个集合来干什么呢?
7)帖子与回复之间的关系不是帖子在管理维护回复,如果你说帖子应该有一些如总回复数,最后回复人,最后回复时间,最后回复ID之类的统计信息,那我真觉得是冗余,这些信息放在domain中实现,只会增加domain的负担,统计信息只会在查询时需要知道,只会在界面上显示时需要这些信息;统计信息种类繁多,每个人需要看的统计信息完全不同,如果要把这种因人而异的各种统计信息放在domain中处理和维护,那我觉得domain就太臃肿了。按照CQRS的思想,命令和查询应该分开,统计信息属于查询端需要解决的问题,如果要在命令端做一些额外的不属于领域业务逻辑的操作去维护这些统计信息,那无疑会让领域模型沉重不堪。按照这样的思路,那么我们在领域中,只要维护好帖子和回复的关系,即只要确保每个回复有一个对应的帖子ID,且确保帖子ID是只读的即可。这样就意味着已经建立了回复和帖子的关系了。然后在查询端,如果并发量不大的情况下,则可以在每次查询时通过表关联来获取这些统计信息,如果并发量比较大,那么可以采用缓存等技术,也可以设计一张额外的表,里面存放界面上需要显示的前十页的帖子,然后我们每隔5分钟去更新这个表,然后每次查询时,我们只要从这张表中获取数据即可,在加上缓存等技术,相信性能不是什么问题。在确保数据一致的情况下,要解决查询快的问题还是有很多方法可以用的呢,但是要解决高并发的情况下,让domain去维护一些不该维护的统计信息,那我觉得是方向错误了。
8)domain中其实很纯净,就是一个个的聚合,每个聚合维护了一定的不变性,当然大部分聚合都是简单的单个实体,很少比例的聚合内会包含一些其他的本地实体;聚合设计出来的目的是为了在领域中维护数据的不变性规则,目的是确保数据一致性;所以我们强调聚合应该总是作为一个整体来看待,当我们持久化一个聚合时,应该总是采用完全覆盖的方式保存,而不是以追加或合并的方式去保存,否则聚合在内存中做的所有关于不变性方面的控制努力就都白费了;
9)聚合与聚合之间的通信,以及关于如何维护聚合与聚合之间数据一致性的问题。我现在认为通信方式应采用领域事件加异步响应的方式,数据一致性采用最终一致性,这样可以提高系统的整体性能和可用性;这方面Event Source就是这个思想;为什么聚合之间可以异步的方式在不同的时间分别各自更新呢?因为聚合与聚合之间本质上没有强一致性需要维护的不变性规则,如果真的有这种规则,那就意味着聚合边界没有设计好。我们只要确保每个聚合内部是强一致性的,聚合之间是最终一致性的,这样就能确保整个domain能达到最终一致性,并提供整体不错的性能和可用性。
10)关于聚合内部的状态是否应该由事件驱动,是否应该用事件来表示domain所经历的所有相关事实,我也非常认同这样的做法和认知观,但我认为只要做到的上面提到的这些点,即便是用经典的DDD,也是一个不错的设计;
[该贴被tangxuehua于2011-12-15 23:42修改过]
[该贴被tangxuehua于2011-12-15 23:46修改过]
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK