

bpf_tail_call特性介绍
source link: https://blog.spoock.com/2024/01/11/bpf-tail-call-intro/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

bpf_tail_call特性介绍
在学习代码中发现了eBPF中的一个新的用法,bpf_tail_call。
eBPF(扩展的Berkeley数据包过滤器)是一个高效的内核编程框架,它允许用户态代码以一种安全的方式运行在内核态。eBPF程序可以在内核中的多个挂钩点上执行,例如在网络包进出时、系统调用执行前后、内核跟踪点等,这使得它可以用于性能监测、网络安全、系统调试等多种场景。
bpf_tail_call 是一个 eBPF 提供的机制,它允许一个 eBPF 程序调用另一个 eBPF 程序,类似于函数调用。然而,与传统的函数调用不同,bpf_tail_call 实际上是将当前程序替换为另一个程序,而不是创建一个新的函数调用栈帧。这意味着被调用的程序(尾调用程序)会接管当前程序的执行上下文,并且当尾调用程序开始执行时,原始程序的执行就结束了。
在Linux内核中,尾调用是通过一个特殊的eBPF映射类型BPF_MAP_TYPE_PROG_ARRAY来实现的。这个映射包含了eBPF程序的文件描述符,可以在运行时被其他eBPF程序查找并执行。
具体应用场景
- 链式处理:bpf_tail_call 允许开发者创建一组可以动态链式执行的 eBPF 程序。例如,在处理网络包时,可以根据包的内容动态决定调用哪个 eBPF 程序进行处理。
- 避免复杂的条件分支:在某些情况下,一个 eBPF 程序可能需要根据不同的条件执行不同的逻辑。使用 bpf_tail_call 可以将这些逻辑分割成多个独立的程序,避免了在一个大型程序中使用复杂的条件分支。
- 模块化和可扩展性:通过 bpf_tail_call,开发者可以创建模块化的 eBPF 程序,每个程序都可以独立更新和维护,而不需要重新编译或重启整个系统。
- 性能监测和追踪:在性能监测和追踪场景中,bpf_tail_call 可以用来根据事件类型或者数据内容动态切换不同的监控逻辑,使得监控更加灵活和高效。
- 安全和过滤:在网络安全应用中,可以根据数据包的特征动态选择不同的安全检查或过滤策略,从而实现精细化的安全控制。
bpf_tail_call 在使用时有一些限制,比如:
- 尾调用的程序必须已经加载到了 eBPF 程序的同一个 bpf_map 类型的数据结构中。
- bpf_tail_call 的调用深度是有限的(通常是32),以防止无限循环。
- 尾调用不会传递任何参数,被调用的程序需要通过共享的 bpf_map 或者上下文数据来访问需要的信息。
正因为这些特性和限制,bpf_tail_call 成为了 eBPF 编程中一个强大且灵活的工具,但也需要精心设计以适应具体的应用场景。
Tail Calls介绍
Tail call并非eBPF编程中所独有的。tail call的通用目的是为了避免当函数递归调用时,栈帧无限地增加(这会导致栈溢出)。具体而言,可以重新编排函数代码,使得递归调用函数后,没有任何其他需要干的内容——即递归调用就是函数体的最后一行代码。这样,tail call允许一系列的函数调用不会增长栈的大小。毕竟,当递归调用时,上一个栈帧的函数体不再被需要了,可以被优化掉。在eBPF中,栈帧大小仅有512B。
Tail call通过helper function: bpf_tail_call()来使用,其函数签名如下:
long bpf_tail_call(void *ctx, struct bpf_map *prog_array_map, u32 index);
referer:https://man7.org/linux/man-pages/man7/bpf-helpers.7.html
参数含义如下:
- ctx用来将当前eBPF程序的上下文传递给被调用的eBPF程序
- prog_array_map是一个eBPF map,类型为BPF_MAP_TYPE_PROG_ARRAY,包含了一系列的文件描述符,每个文件描述符都表示一个eBPF程序
- index表示prog_array_map中哪个eBPF程序应该被调用
这里存在两种情况:
- 如果bpf_tail_call执行成功,对应的eBPF程序将会执行并替换当前栈帧(当前eBPF的函数体就不再被执行了)
- 如果bpf_tail_call执行失败,当前eBPF程序的函数体会继续执行
referer:https://www.torch-fan.site/2023/04/11/eBPF%E4%BD%BF%E7%94%A8/
针对Tail call有两个非常重要的特性,分别是接管当前程序的执行上下文和执行流程替换。
eBPF 的尾调用(tail calls)特性允许一个 eBPF 程序可以调用另一个 eBPF 程序, 并且调用完成后不会返回原来的程序。 因为尾调用在调用函数的时候会重用调用方函数的 stack frame,所以它的开销比普通的函数 调用会更低。
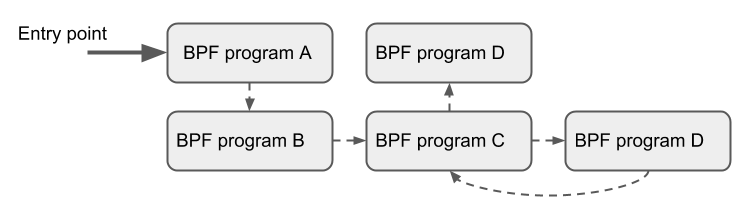
尾调用涉及两个步骤:
- 定义一个类型为 BPF_MAP_TYPE_PROG_ARRAY 的 map , map 的 value 是在尾调用中被调用的 eBPF 程序的文件描述符。 我们可以在用户态程序中更新这个 map 的 key/value,也可以直接在eBPF中直初始化好map的结构。
- 在 eBPF 程序中,我们可以通过 bpf_tail_call() 这个辅助函数 从第1步的 map 中获取 eBPF 程序然后执行该程序进行尾调用。
referer:https://mozillazg.com/2022/10/ebpf-libbpf-use-tail-calls.html
map定义
bpf_tail_call 通常与一种特殊类型的 eBPF 映射(map)一起使用,称为程序数组(prog array)。程序数组映射允许 eBPF 程序通过索引来动态地决定要调用的下一个 eBPF 程序。
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__type(key, u32);
__type(value, u32);
__uint(max_entries, 3);
__array(values, int());
} packet_processing_progs SEC(".maps")
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);:这指定了映射的类型为程序数组。__type(key, u32);:这定义了映射的键类型为 u32(无符号 32 位整数)。__type(value, u32);:这定义了映射的值类型为 u32。在程序数组中,值通常是 eBPF 程序的文件描述符(fd),但在 BPF CO-RE(Compile Once - Run Everywhere)上下文中,通常直接引用程序的符号。__uint(max_entries, 2);:这设置了映射的最大条目数为 2。__array(values, int());:这定义了一个数组,用于存储映射的实际值。在程序数组中,这些值是 eBPF 程序的标识符。
内核态初始化Map
可以直接在定义BPF_MAP_TYPE_PROG_ARRAY结构体时直接初始化。如下所示:
SEC("xdp/icmp")
int handle_icmp(struct xdp_md *ctx) {
return XDP_PASS;
}
SEC("xdp/tcp")
int handle_tcp(struct xdp_md *ctx) {
return XDP_PASS;
}
SEC("xdp/udp")
int handle_udp(struct xdp_md *ctx) {
return XDP_PASS;
}
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__type(key, u32);
__type(value, u32);
__uint(max_entries, 3);
__array(values, int());
} packet_processing_progs SEC(".maps") = {
.values =
{
[0] = &handle_icmp,
[1] = &handle_tcp,
[2] = &handle_udp,
},
};
其中.values关键代码就是完成了BPF_MAP_TYPE_PROG_ARRAY数组初始化的工作。将索引 0 关联到 handle_icmp 程序,将索引 1 关联到 handle_tcp 程序,将索引2关联到 handle_udp 程序。这意味着当 bpf_tail_call 使用索引 0 调用 packet_processing_progs 时,它将执行 handle_icmp 程序;依次类推。
具体代码可以参考:https://github.com/spoock1024/ebpf-example/tree/main/bpf_tail_call_case2
用户态初始化Map
除了可以直接在eBPF内核态初始化BPF_MAP_TYPE_PROG_ARRAY数组之外,还可以在用户态初始化。下面的代码利用了cilium的ebpf库演示。
// Load XDP programs from the collection
icmpProg := coll.Programs["handle_icmp"]
tcpProg := coll.Programs["handle_tcp"]
udpProg := coll.Programs["handle_udp"]
//
// Get the packet_processing_progs map
packetProgsMap := coll.Maps["packet_processing_progs"]
// Update map entries with the program file descriptors
keysAndProgs := map[uint32]*ebpf.Program{
0: icmpProg,
1: tcpProg,
2: udpProg,
}
for key, prog := range keysAndProgs {
if prog == nil {
log.Fatalf("program with key %d not found", key)
}
fmt.Println(fmt.Sprintf("key: %d, prog: %v", key, prog))
if err := packetProgsMap.Update(key, uint32(prog.FD()), ebpf.UpdateAny); err != nil {
log.Fatalf("updating packet_processing_progs map: %v", err)
}
}
功能和内核态初始化的作用完全是一致的。
用户态程序(例如用 Go 写的程序)通常负责将这些 eBPF 程序加载到内核中,并设置必要的映射和钩子。用户态程序的优势在于:
- 易于调试:用户态程序可以使用传统的调试工具,如 gdb 或 delve(对于 Go 程序)。
- 用户友好:用户态程序可以提供更友好的接口和错误处理机制。
- 更多语言选择:可以选择多种编程语言来编写用户态程序,这为开发人员提供了更多的灵活性。
具体代码可以参考:https://github.com/spoock1024/ebpf-example/tree/main/bpf_tail_call
执行流程替换
- 如果bpf_tail_call执行成功,对应的eBPF程序将会执行并替换当前栈帧(当前eBPF的函数体就不再被执行了)
- 如果bpf_tail_call执行失败,当前eBPF程序的函数体会继续执行
执行成功情况验证
通过一段简单的示例代码验证这样的情况。
首先验证的情况是,如果bpf_tail_call执行成功,那么对应的eBPF程序替换当前栈帧,当前eBPF函数体不会执行。
SEC("xdp/udp")
int handle_udp(struct xdp_md *ctx) {
// UDP包的处理逻辑
bpf_printk("new udp packet captured (XDP)\n");
return XDP_PASS;
}
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__type(key, u32);
__type(value, u32);
__uint(max_entries, 3);
__array(values, int());
} packet_processing_progs SEC(".maps") = {
.values =
{
[0] = &handle_udp,
},
};
SEC("xdp_classifier")
int packet_classifier(struct xdp_md *ctx) {
bpf_printk("before tail_call handle_udp\n");
bpf_tail_call(ctx, &packet_processing_progs, 0);
bpf_printk("after tail_call handle_udp\n");
return XDP_PASS;
}
char _license[] SEC("license") = "GPL";
主体函数是packet_classifier,整个代码流程十分简单清晰。
- 在执行bpf_tail_call之前,打印before tail_call handle_udp
- 在bpf_tail_call调用函数handle_udp函数中,打印new udp packet captured (XDP)
- 在执行bpf_tail_call之后,打印after tail_call handle_udp
按照bpf_tail_call特性,如果bpf_tail_call执行成功,对应的eBPF程序将会执行并替换当前栈帧(当前eBPF的函数体就不再被执行了)。
运行之后,查看eBPF的打印日志:
[011] dNs.1 1883799.469438: bpf_trace_printk: before tail_call handle_udp
[011] dNs.1 1883799.469438: bpf_trace_printk: new udp packet captured (XDP)
打印了before tail_call handle_udp和new udp packet captured (XDP),没有执行bpf_printk("after tail_call handle_udp\n");这行代码,说明是bpf_tail_call函数确实替换了packet_classifier执行流程。
执行失败情况验证
为了构造出bpf_tail_call调用失败的场景,通过在 bpf_tail_call 调用时故意传递一个超出映射的最大索引的数值实现。
SEC("xdp/udp")
int handle_udp(struct xdp_md *ctx) {
// UDP包的处理逻辑
bpf_printk("new udp packet captured (XDP)\n");
return XDP_PASS;
}
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__type(key, u32);
__type(value, u32);
__uint(max_entries, 3);
__array(values, int());
} packet_processing_progs SEC(".maps") = {
.values =
{
[0] = &handle_udp,
},
};
SEC("xdp_classifier")
int packet_classifier(struct xdp_md *ctx) {
bpf_printk("before tail_call handle_udp\n");
bpf_tail_call(ctx, &packet_processing_progs, 10);
bpf_printk("after tail_call handle_udp\n");
return XDP_PASS;
}
在初始化packet_processing_progs时只有handle_udp一个元素,但是调用bpf_tail_call时,采用的是:
bpf_tail_call(ctx, &packet_processing_progs, 10);
导致bpf_tail_call就会调用失败。运行之后,查看eBPF的打印日志:
[011] dNs.1 1886771.320803: bpf_trace_printk: before tail_call handle_udp
[011] dNs.1 1886771.320817: bpf_trace_printk: after tail_call handle_udp
发现before tail_call handle_udp和after tail_call handle_udp成功打印,new udp packet captured (XDP)没有打印。
验证了如果bpf_tail_call执行失败,当前eBPF程序的函数体会继续执行的特性。
指的是被调用的程序(尾调用程序)会接管当前程序的执行上下文。在 eBPF 中,尾调用程序(被调用的程序)并不能直接访问调用程序(当前程序)中的局部变量。这是因为当尾调用发生时,原程序的栈帧被抛弃,尾调用程序开始执行时会有一个全新的栈帧。因此,两个程序的执行上下文是隔离的。
尾调用程序可以通过 eBPF 映射来访问调用程序设置的数据。映射在 eBPF 程序之间共享数据是一种常用的方法。
示例代码如下:
#include "vmlinux.h"
#include "bpf_helpers.h"
#include "bpf_tracing.h"
#include "bpf_core_read.h"
struct bpf_map_def SEC("maps") shared_data_map = {
.type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(long),
.max_entries = 1,
};
SEC("xdp/udp")
int handle_udp(struct xdp_md *ctx) {
u32 key = 0;
long *value;
// Attempt to access the shared data set by the caller program
value = bpf_map_lookup_elem(&shared_data_map, &key);
if (value) {
bpf_printk("Callee program has taken over the execution context. Shared value: %ld\n", *value);
// Modify the value to show that the callee has executed
*value = 2;
}
return XDP_PASS;
}
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__type(key, u32);
__type(value, u32);
__uint(max_entries, 3);
__array(values, int());
} packet_processing_progs SEC(".maps") = {
.values =
{
[0] = &handle_udp,
},
};
SEC("xdp_classifier")
int packet_classifier(struct xdp_md *ctx) {
u32 key = 0;
long value = 1; // Set a value to share with the callee program
// Set the shared value before making the tail call
bpf_map_update_elem(&shared_data_map, &key, &value, BPF_ANY);
bpf_printk("Caller program before tail call. Shared value set to: %ld\n", value);
// Perform the tail call
bpf_tail_call(ctx, &packet_processing_progs, 0);
// This line should not be printed if the tail call is successful
bpf_printk("Caller program after tail call - this should not be printed if tail call was successful.\n");
return XDP_DROP; // Default action if tail call fails
}
char _license[] SEC("license") = "GPL";
在这个例子中,packet_classifier` 设置了一个在 shared_data_map` 映射中的值,然后尝试执行一个尾调用。如果尾调用成功,handle_udp` 将接管执行上下文,并且可以访问和修改 packet_classifier 设置的值。这个修改可以作为 handle_udp 成功执行的证据。
最终执行日志如下:
[011] d.s.1 1890948.966678: bpf_trace_printk: Caller program before tail call. Shared value set to: 1
[011] d.s.1 1890948.966679: bpf_trace_printk: Callee program has taken over the execution context. Shared value: 1
成功输出了bpf_trace_printk: Callee program has taken over the execution context. Shared value: 1
说明在handle_udp成功访问到了shared_data_map中的数据。
参考代码:https://github.com/spoock1024/ebpf-example/tree/main/bpf_tail_call_case4
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u32));
__uint(max_entries, 3);
} packet_processing_progs SEC(".maps");
SEC("xdp/icmp")
int handle_icmp(struct xdp_md *ctx) {
// ICMP包的处理逻辑
bpf_printk("new icmp packet captured (XDP)\n");
return XDP_PASS;
}
SEC("xdp/tcp")
int handle_tcp(struct xdp_md *ctx) {
// TCP包的处理逻辑
bpf_printk("new tcp packet captured (XDP)\n");
return XDP_PASS;
}
SEC("xdp/udp")
int handle_udp(struct xdp_md *ctx) {
// UDP包的处理逻辑
bpf_printk("new udp packet captured (XDP)\n");
return XDP_PASS;
}
SEC("xdp_classifier")
int packet_classifier(struct xdp_md *ctx) {
// bpf_printk("new packet_classifier (XDP)\n");
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
struct iphdr *ip;
// 检查是否有足够的数据空间
if ((void *)(eth + 1) > data_end) {
return XDP_ABORTED;
}
// 确保这是一个IP包
if (eth->h_proto != bpf_htons(ETH_P_IP)) {
return XDP_PASS;
}
ip = (struct iphdr *)(eth + 1);
// 检查IP头部是否完整
if ((void *)(ip + 1) > data_end) {
return XDP_ABORTED;
}
bpf_printk("protocol: %d\n", ip->protocol);
bpf_printk("icmp: %d,tcp:%d,udp:%d\n", IPPROTO_ICMP, IPPROTO_TCP, IPPROTO_UDP);
switch (ip->protocol) {
case IPPROTO_ICMP:
bpf_printk("icmp\n");
bpf_tail_call(ctx, &packet_processing_progs, 0);
break;
case IPPROTO_TCP:
bpf_printk("tcp\n");
bpf_tail_call(ctx, &packet_processing_progs, 1);
break;
case IPPROTO_UDP:
bpf_printk("udp\n");
bpf_tail_call(ctx, &packet_processing_progs, 2);
break;
default:
bpf_printk("unknown protocol\n");
break;
}
return XDP_PASS;
}
1.handle_icmp, handle_tcp, handle_udp 函数:这些函数分别处理 ICMP, TCP, 和 UDP 数据包。每个函数打印一条消息到内核日志,表明它捕获了一个新的数据包,并返回 XDP_PASS,这意味着数据包将按照正常的网络栈路径继续传递。
2 packet_classifier函数:这是一个 XDP 程序,用于分类网络数据包。它首先检查以太网头部是否完整,然后确认是否是 IP 数据包。如果是 IP 数据包,它会检查 IP 头部是否完整,并根据 IP 头部中的 protocol 字段确定数据包类型(ICMP, TCP, UDP 或其他)。根据确定的类型,它会使用 bpf_tail_call 函数调用相应的处理程序。如果 bpf_tail_call 调用失败(例如,对应的处理程序没有注册在 packet_processing_progs 映射中),则会执行 packet_classifier 函数的剩余代码。
用户态代码
在用户态中实现针对packet_processing_progs初始化工作。由于整体的代码较长,所以就不全部贴出来了,整个代码使用的是cilium库实现的。在之前的代码中也讲到了。下面只展示有关packet_processing_progs初始化相关的代码。
// Load XDP programs from the collection
icmpProg := coll.Programs["handle_icmp"]
tcpProg := coll.Programs["handle_tcp"]
udpProg := coll.Programs["handle_udp"]
//
// Get the packet_processing_progs map
packetProgsMap := coll.Maps["packet_processing_progs"]
// Update map entries with the program file descriptors
keysAndProgs := map[uint32]*ebpf.Program{
0: icmpProg,
1: tcpProg,
2: udpProg,
}
for key, prog := range keysAndProgs {
if prog == nil {
log.Fatalf("program with key %d not found", key)
}
fmt.Println(fmt.Sprintf("key: %d, prog: %v", key, prog))
if err := packetProgsMap.Update(key, uint32(prog.FD()), ebpf.UpdateAny); err != nil {
log.Fatalf("updating packet_processing_progs map: %v", err)
}
}
packetProgsMap := coll.Maps["packet_processing_progs"]获得eBPF程序中的packet_processing_progskeysAndProgs定义了索引和对应函数之间的对应关系packetProgsMap.Update(key, uint32(prog.FD()), ebpf.UpdateAny)设置packet_processing_progs
运行之后通过查看cat /sys/kernel/debug/tracing/trace_pipe执行日志:
[011] d.s.1 1892694.649197: bpf_trace_printk: protocol: 6
[011] dNs.1 1892694.649223: bpf_trace_printk: icmp: 1,tcp:6,udp:17
[011] dNs.1 1892694.649224: bpf_trace_printk: tcp
[011] dNs.1 1892694.649227: bpf_trace_printk: new tcp packet captured (XDP)
发现bpf_trace_printk: new tcp packet captured (XDP)被打印出来了,说明bpf_tail_call成功调用了handle_udp函数。整个程序按照预期成功执行了。
完整代码:https://github.com/spoock1024/ebpf-example/tree/main/bpf_tail_call
内核中也存在一些的例子也是很好的学习资料,例如 ockex3_kern.c
https://github.com/spoock1024/ebpf-example/tree/main/bpf_tail_call
https://mozillazg.com/2022/10/ebpf-libbpf-use-tail-calls.html
https://www.torch-fan.site/2023/04/11/eBPF%E4%BD%BF%E7%94%A8/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK