

AFL 语法变异插件 Grammar-Mutator 的基本使用
source link: https://paper.seebug.org/3108/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

作者:0x7F@知道创宇404实验室
时间:2024年1月11日
0x00 前言
变异算法是 fuzzing 中非常重要的一个环节,良好的变异算法能产出较高的路径覆盖率,从而提高发现 crash 的概率;AFL/AFL++ 默认提供的变异算法在通用情况下表现优秀,但对于格式要求严格的数据则显得无能为力,基于语法的变异是一种优秀的变异算法优化方案,并具有良好的普适性,安全研究人员通过对理解数据格式编写对应的语法树生成器,从而可以准确的生成符合要求的数据,极大的提高路径覆盖率。
最近工作中和同事 @ghost461 一起研究学习 AFL++ 的语法变异插件 Grammar-Mutator,本文对此进行梳理,并详细介绍 Grammar-Mutator 的使用和基本原理。
本文实验环境:
Ubuntu 22.04
AFL++ 4.09c
Grammar-Mutator
(commit:74f8e136b94b66ec7e5ff0c1ef97be281a8b8ba0)0x01 Grammar-Mutator
首先配置 AFL++ 环境以便下文使用:
$ git clone https://github.com/AFLplusplus/AFLplusplus.git
$ cd AFLplusplus/
$ make随后配置 Grammar-Mutator 环境,Grammar-Mutator 依赖 antlr4 运行,需要先配置 antlr4 如下:
# 从 github 拉取 Grammar-Mutator
$ git clone https://github.com/AFLplusplus/Grammar-Mutator.git
# 配置 antlr4
$ cd Grammar-Mutator/
$ sudo apt install valgrind uuid-dev default-jre python3
$ wget https://www.antlr.org/download/antlr-4.8-complete.jarGrammar-Mutator 使用 json 格式描述语法,在 [src]/grammars/ 提供了几个示例语法文件:http/javascript/json/test/ruby,其中 test.json 的语法文件如下:
{
"<A>": [["I ", "<B>"]],
"<B>": [["like ", "<C>"]],
"<C>": [["C"], ["C++"]]
}json 主要描述语法的前后关系以及终结符值,这种方法非常简单易懂(类似BNF范式);使用尖括号 <token> 表示非终结符,其他则为终结符,每个符号使用一个二维数组表示其可选值,其中每一个一维数组对应符号的可选值(一维数组之间为并列关系),一维数组内部的值表示该选项具体的值(一维数组内部的值为串联关系);所以以上语法可以生成的数据为:
I like C
I like C++我们通过以下语句编译 Grammar-Mutator 项目:
$ make ANTLR_JAR_LOCATION=./antlr-4.8-complete.jar GRAMMAR_FILE=grammars/test.json执行如下,成功编译后将生成 grammar_generator-test 用于生成种子文件,以及 libgrammarmutator-test.so 用于 AFL++ 变异算法插件,如下:
我们可以使用 grammar_generator-test 生成 fuzzing 种子文件,或检查测试语法是否正确:
# ./grammar_generator-test <max_num> <max_size> <output_dir> <tree_output_dir> [<random seed>]
$ ./grammar_generator-test 10 1000 seeds trees执行如下:

其他示例语法可以自行尝试测试。
0x02 常规fuzzing
我们首先使用 AFL++ 进行常规 fuzzing,为了方便演示和对比,我们编写「10以内的加减法」的小工具作为 fuzzing 目标(ten-addsub.c) :
#include <stdio.h>
#include <string.h>
char VALID_CHARS[] = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '-'};
// valid-format: 1+2+3+4-5
int check_character(char* data, int len) {
int vc_len = strlen(VALID_CHARS);
if (len % 2 != 1) {
return 0;
}
int opflag = 0;
for (int i = 0; i < len; i++) {
int valid = 0;
for (int j = 0; j < vc_len; j++) {
if (data[i] == VALID_CHARS[j]) {
valid = 1;
}
}
if (valid == 0) {
return 0;
}
if (data[i] == '+' || data[i] == '-') {
if (opflag == 0) {
return 0;
}
opflag = 0;
} else {
if (opflag == 1) {
return 0;
}
opflag = 1;
}
}
return 1;
}
int addsub(int sum, char op, char v) {
if (op == '+') {
return sum + (v - 0x30);
} else {
// op == '-'
return sum - (v - 0x30);
}
}
int main(int argc, char* argv[]) {
char data[1025] = {};
printf("please input expr:\n");
scanf("%1024s", data);
int data_len = strlen(data);
if (check_character(data, data_len) == 0) {
printf("error: invalid characters\n");
return 0;
}
int sum = (data[0] - 0x30);
for (int i = 1; i < data_len; i+=2) {
sum = addsub(sum, data[i], data[i+1]);
// crash
if (data_len == 9 && data[i+1] == '5' && sum == 0) {
char *crash = NULL;
crash[0] = 1;
}
}
printf("result = %d\n", sum);
return 0;
}我们埋了一个 crash 的点,当输入长度为 9(即五个数字参与运算),当前数字为 '5',任意一轮计算结果为 0 时,手动抛出 Null-Pointer Write Exception。
我们对该测试用例进行常规 fuzzing:
# 编译 harness (关闭优化以便更符合代码预期)
$ ../AFLplusplus/afl-gcc -Wall -O0 ten-addsub.c -o harness
# 准备种子文件
$ mkdir in
$ echo "1+2" > in/1
# 启动fuzzing(并开启确定性变异)
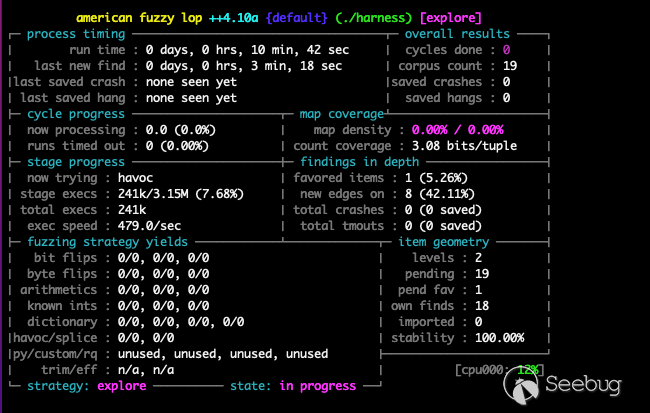
$ ../AFLplusplus/afl-fuzz -D -i in/ -o out/ -t 1000 ./harness执行如下:
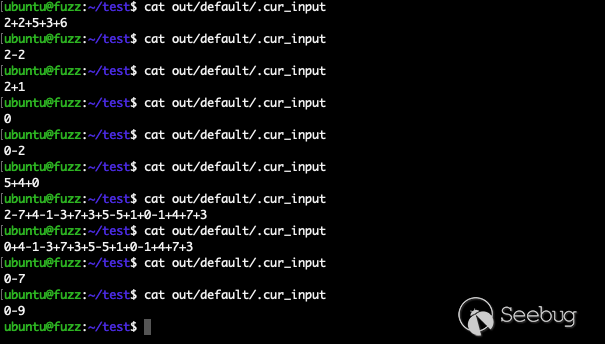
我们可以通过 cat out/default/.cur_input 查看 AFL++ 的当前输入数据,以此来抽样评估变异的输入数据,如下:
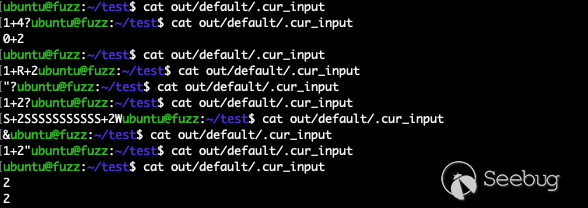
可以看到输入数据变异得比较发散,其中大多数都无法通过 check_character() 函数的检查。
0x03 语法变异fuzzing
我们使用语法变异来进行 fuzzing,首先为我们的「10以内的加减法」小工具编写语法 addsub.json:
{
"<EXPR>": [["<NUMBER>", "<OPERATION>", "\n"]],
"<OPERATION>": [["<SYMBOL>", "<NUMBER>", "<OPERATION>"], []],
"<SYMBOL>": [["+"], ["-"]],
"<NUMBER>": [["0"], ["1"], ["2"], ["3"], ["4"], ["5"], ["6"], ["7"], ["8"], ["9"]]
}以上语法描述的是:
- 每条
EXPR,以NUMBER开头,后跟OPERATION,结尾为\n字符 - 每个
OPERATION由[SYMBOL, NUMBER]串联组成,可以有 0 个或多个OPERATION - 每个
SYMBOL从+-字符二选一 - 每个
NUMBER从0123456789字符中十选一
使用 Grammar-Mutator 编译以上语法:
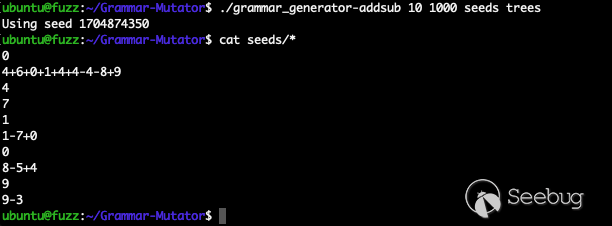
make ANTLR_JAR_LOCATION=./antlr-4.8-complete.jar GRAMMAR_FILE=grammars/addsub.json使用 grammar_generator-addsub 生成种子数据,可以生成的数据非常符合预期,如下:
我们将 libgrammarmutator-addsub.so 拷贝至 fuzzing 工作目录下,目录结构如下:
├── harness
├── in
│?? └── 1 // “1+2”
├── libgrammarmutator-addsub.so
├── out
└── ten-addsub.c这里我们仍使用上文的
1+2作为输入种子,这样可以方便我们更好的进行对比;在实际场景下,可以直接使用语法变异器生成的种子。
使用 AFL_CUSTOM_MUTATOR_LIBRARY 指定语法变异插件模块,还需要使用 AFL_CUSTOM_MUTATOR_ONLY=1 设置仅使用自定义变异(即不使用 AFL++ 默认的变异算法,因为默认变异可能大幅破坏语法结构从而导致 Grammar-Mutator 报错退出),启动 fuzzing 如下:
AFL_CUSTOM_MUTATOR_ONLY=1 AFL_CUSTOM_MUTATOR_LIBRARY=./libgrammarmutator-addsub.so ../AFLplusplus/afl-fuzz -i in/ -o out/ -t 1000 ./harness执行如下:
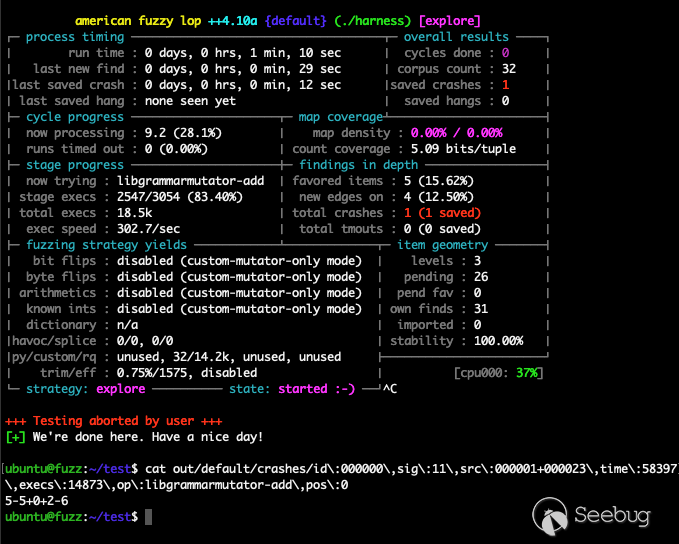
同样通过 cat out/default/.cur_input 查看 AFL++ 的当前输入数据,可以看到变异数据也非常符合预期:
通过语法变异 1min 就发现了 crash,对比常规 fuzzing 在路径覆盖率和效率上都有显著的提高。
0x04 antlr4拓展
antlr4 是著名的语法解析引擎,Grammar-Mutator 底层依赖 antlr4 进行工作,其 json 文件需要首先翻译为 g4 语法文件,才能被 antlr4 解析加载,其编译过程示意如下:
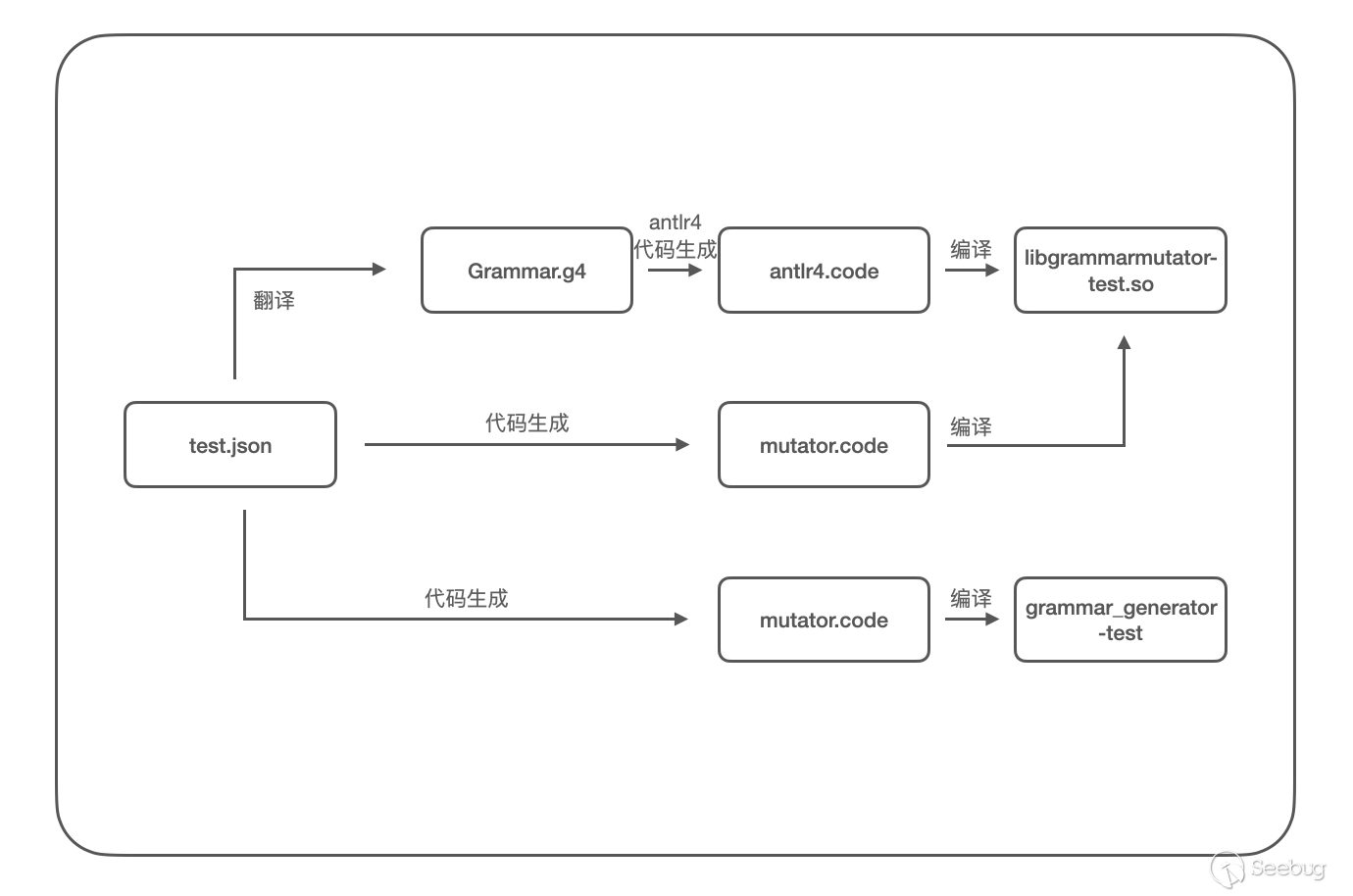
上文中 Grammar-Mutator 提供的示例语法 test.json 对应的的 g4 语法如下:
grammar Grammar;
entry
: node_A EOF
;
node_A
: 'I ' node_B
;
node_B
: 'like ' node_C
;
node_C
: 'C'
| 'C++'
;实际上 antlr4 应用非常广泛,从 fuzzing 的角度考虑可以直接基于 antlr4 的语法文件构建自定义变异器,从而复用 antlr4 大量现有的描述文法,为对应的应用进行高效的 fuzzing。
0x05 References
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/3108/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/3108/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK