

OpenAI开撕纽约时报:故意引导ChatGPT得出抄袭结论
source link: https://www.qbitai.com/2024/01/112476.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

OpenAI开撕纽约时报:故意引导ChatGPT得出抄袭结论

“我使用版权数据训练合理,不乐意可以退出!”
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI的反击来了。
针对被纽约时报提起史上最受关注的侵权诉讼一案,OpenAI公开发表长文表明立场。
文章直接表示:整个诉讼毫无根据,并指出纽约时报:
- 存在故意引导ChatGPT之嫌疑
- 隐瞒信息,没有讲出完整的事情经过
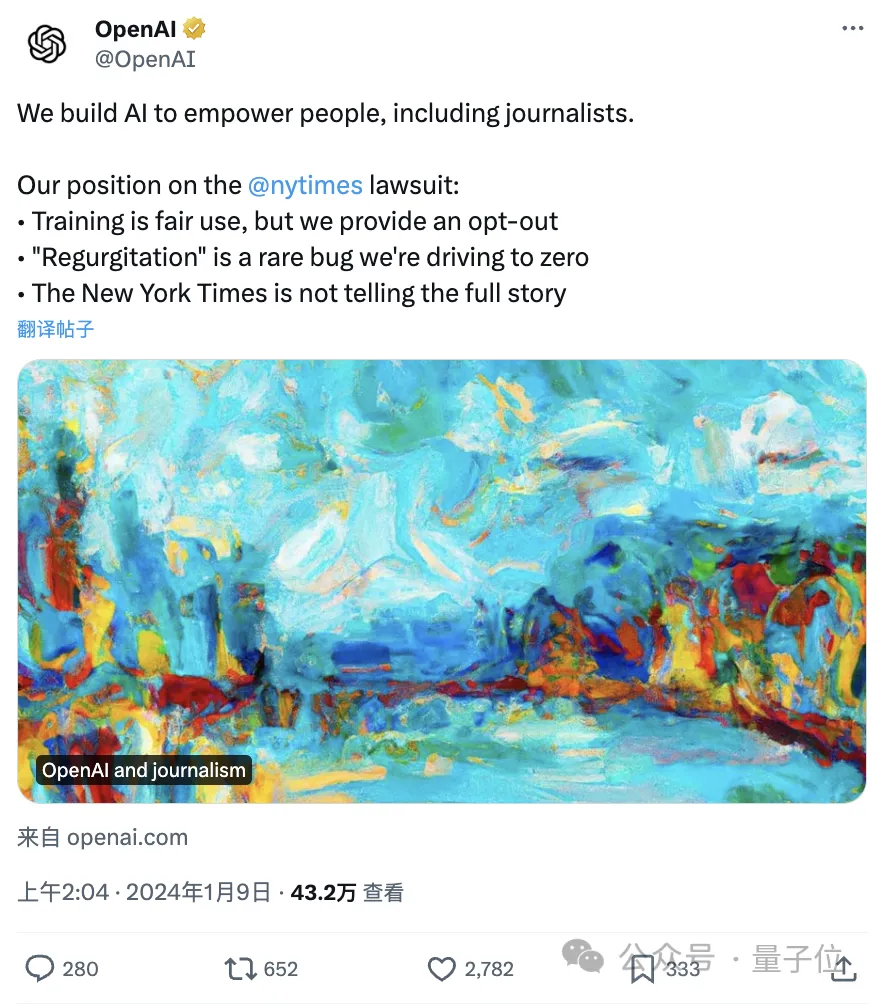
以及OpenAI的总体观点是:
(1)使用版权数据训练合理。没有它们,哪来的当今世界上最先进的模型?
(2)如果你不想被训练?可以退出。单一数据源(包括纽约时报在内)的缺失也不会对模型的表现造成重要影响。
消息一出,吃瓜群众再次火速聚集,吵成一团。
支持OpenAI的直接“虾仁猪心”:
纽约时报退出训练数据集,反而会让模型输出质量更好(Doge)

有人则问了当事模型GPT-4的看法,结果AI也把纽约时报无情嘲讽了一番:
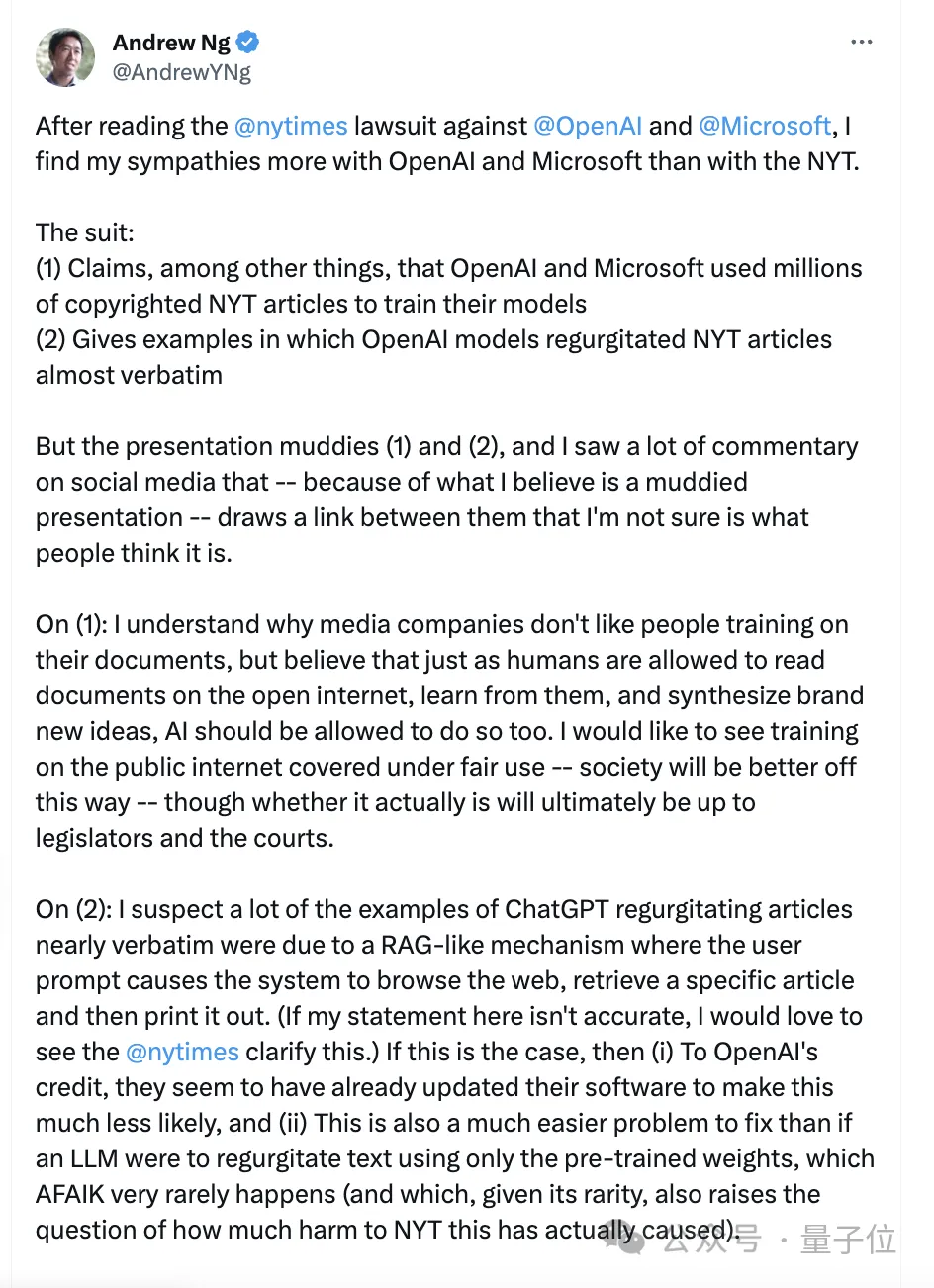
吴恩达也洋洋洒洒写了一大堆,总结来说就是:
同情OpenAI多于纽约时报,后者所说的全文抄袭更可能是RAG机制所致,并且实测OpenAI已经堵住漏洞,质疑纽约时报究竟受到了多少实际损失。
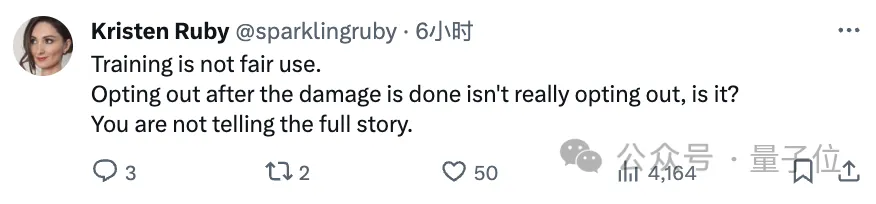
不过,反方网友也毫不留情,直接指着鼻子骂:
OpenAI,你太双标了,什么训练合理,都是为了你的利益最大化罢了。

你才是那个没有讲出完整故事的人。
OpenAI具体回应
先来看看OpenAI回应的具体立场,一共包含四个点:
1、非常乐意与新闻机构合作
OpenAI表示,自己在技术设计过程中努力行动支持新闻机构,会见了数十家相关媒体,聆听他们提出的担忧,并提供解决方案。
其本意也是支持健康的新闻生态系统,并实现互利互惠,具体包括:
(1)通过部署他们的产品,来协助新闻从业者完成一些耗时的任务,比如分析大量公共记录和翻译故事,最终让编辑和记者从中受益。
(2)通过对历史、非公开内容进行训练,向他们的AI模型传授世界知识。
(3)在ChatGPT回答中显示带有归属信息的实时内容,为新闻发布者与读者建立联系。
2、训练属于合理使用,提供退出机制
OpenAI此前就在提交给英国上议院的一份意见书中警告称:
如果没有受版权内容的训练,我们的模型就将无法运行。
在此,OpenAI再次表示,使用公开的互联网材料训练AI模型是合理的,既对创作者公平、对创新者必要,也对国家的竞争力至关重要。
并指出这一观点已经在美国得到很多团体、学者的支持,在其他国家和地区例如欧盟、日本、新加坡等甚至有法律支持对受版权保护的内容进行训练。
不过,话锋一转,本着“合法权利对我们来说不如成为好公民重要”,OpenAI表示自己提供了一个简单的退出流程,可以防止他们的AI模型再次访问这些网站数据。
据介绍,纽约时报已经于2023年8月采用这一机制,退出OpenAI的训练。
3、“反流”是罕见错误,希望用户也不要故意引导
所谓“反流”(Regurgitation),其实就是指模型输出和训练数据一模一样的内容。
纽约时报在诉讼中就列出ChatGPT和该家新闻惊人雷同的情况:

对于这一文绉绉的表达,有网友是不满的:不就是抄袭(plagarism)吗?
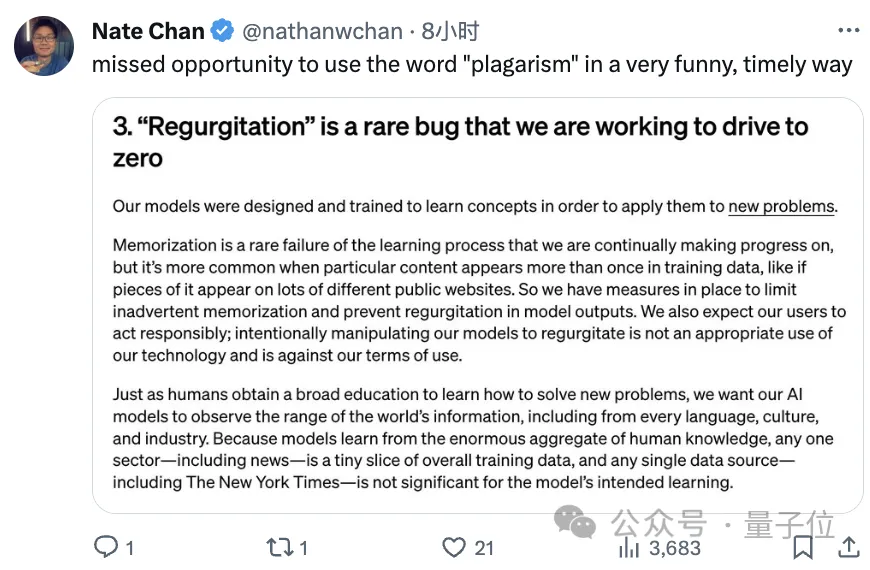
但不管怎么说,OpenAI的解释是:
当特定内容在训练数据中多次出现时就会出现这种罕见的错误,不过我们已经采取了措施来防止情况出现。
以及,OpenAI也特别劝诫用户:
采取负责任的行为,不要故意操纵模型进行反流,这既是对我们技术的不当使用,也违反了我们的使用条款。
然而,马库斯和一位数字插画家几天前曾联合撰文,列出包括 DALL-E 3在内的AI模型如何在没有明确提示的情况下的不少“反刍数据”,也就是给出一些明显和已有作品场景基本相似的图片等内容。
而这,就使得OpenAI的说法有些矛盾。
最后,在本段末尾,OpenAI还来了一句:
模型是从人类知识的巨大集合中学习的,因此任何一类数据(包括新闻)都只是整体训练数据的一小部分,任何单一数据源(包括纽约时报在内),对于模型的知识学习都并不重要。
4、完整故事被隐藏,收到起诉后惊讶又失望
OpenAI透露,在去年12月19日时,其实已经和纽约时报取得了建设性谈判进展,包括在回答中实时显示来源和跳转等,并和纽约时报解释:
与任何单一来源一样,你们的内容对我们现有模型的训练没有任何有意义的贡献,也不会对未来的训练产生足够的影响。
然而OpenAI表示没想到,12月27号就被直接起诉了,并且还是通过纽约时报的消息才知道——心情整个就是一个既惊讶又失望。
在此,OpenAI指出,对于纽约时报指出的”反流”情况(也就是回答逐字抄写纽约时报新闻),他们很努力解决这个问题,拿出了诚意,并曾要求后者分享示例,但一再遭到拒绝。
更有趣的是,OpenAI发现,所谓的“反流”内容,其实是多年前多个第三方网站上大量传播的文章(即并非来自纽约时报)。
以及纽约时报可能涉嫌故意操纵提示词——放进去大段原文让模型“上当”。
OpenAI表示,按照他们这么操作,模型其实也并没有像纽约时报展示的那样夸张。
这说明:他们要么故意引导模型,要么进行过精挑细选。
综合以上,OpenAI认为:
纽约时报的诉讼毫无根据。
不过缓和的场面话也是有的:
我们仍然希望与其建立合作伙伴关系,毕竟它曾在60年前报道了第一个有效工作的神经网络。
前情回顾
去年12月27日,纽约时报突然一纸状书、220000页附件,递交到地方法院状告OpenAI侵权,当然还包括微软。
诉状中指出,纽约时报的文章构成了Common Crawl中用于训练GPT的最大单个专有数据集。
基于此,他们找到了多达100个铁证,证明ChatGPT输出内容与纽约时报新闻内容几乎一模一样。
并且有时由于幻觉问题,模型还会以纽约时报的名义“造谣”,生成一些假新闻,例如橙汁会导致淋巴癌,这也对他们的名声造成了困扰。
对此,纽约时报的诉求是:
要求OpenAI和微软销毁包含侵权材料的模型和训练数据,并对非法复制和使用《纽约时报》独有价值的作品相关的“数十亿美元的法定和实际损失”负责。
由于证据充足、律师团队强大,网友直呼这是一起“见证AI侵权里程碑式的案件”、“恐怕不能再像之前摆平其他出版商那样三瓜两枣就打发了”。

据了解,去年4月份时,纽约时报就与OpenAI谈判,但没谈妥,OpenAI拒绝达成协议。
原因可能是金额巨大,特别是考虑到OpenAI利润的增长以及类似案例的增多。
有一个大胆猜测是,OpenAI可能想用七至八位数金额(百万美元/千万美元)解决此事,但纽约时报所追求的是更高的赔偿和持续的版税收入。
Ps. OpenAI年收入在16亿美元左右,每年用于买授权文章和材料进行训练的金额在100万美元至500万美元之间。
这次,网友站哪边?
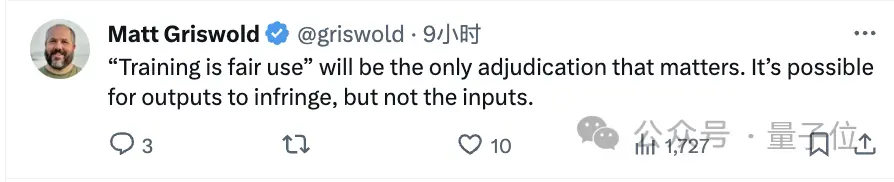
有网友指出,这起案子的关键是“训练是否为合理使用”,而他认为:
模型的输出可能会侵权,但输入不会。
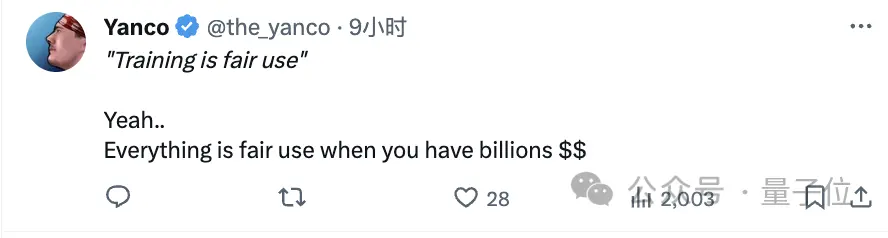
但有人讽刺道:
当你拥有数十亿美元时,一切都是合理使用。
也有人提出:
我同意为合理使用,但前提是你开源。

并有人附和:
确实强调非营利性组织很重要。

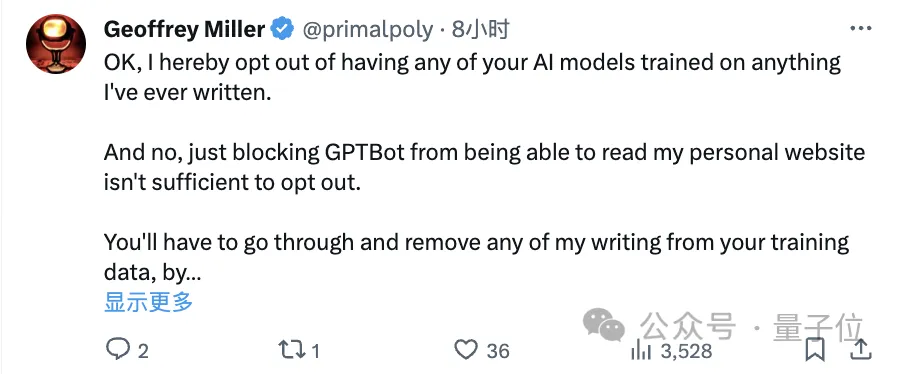
此外,对于OpenAI提出的退出机制,有一位作家网友不满的声音也得到了很多支持:
光退出,也就是禁止你们的模型读取我的个人网站还不够,我还需要你仔细检查并从训练数据中完全删除我的内容。
结局究竟会如何?
一项调查显示,有59%的受访者认为,不应允许人工智能公司使用出版商内容来训练模型。
而70%的人表示,如果公司想在模型训练中使用受版权保护的材料,则应向出版商进行补偿。
看起来,舆论似乎是站在纽约时报这一边的。
你觉得这个案子应该怎么判?
参考链接:
[1]https://openai.com/blog/openai-and-journalism
[2]https://x.com/OpenAI/status/1744419710635229424?s=20
[3]https://www.ft.com/content/04861d1e-2e9f-4b92-a294-8d0c223a8287
[4]https://techcrunch.com/2024/01/08/openai-claims-ny-times-copyright-lawsuit-is-without-merit/
[5]https://www.theregister.com/2024/01/08/midjourney_openai_copyright/
[6]https://x.com/AndrewYNg/status/1744433663969022090?s=20
[7]https://x.com/futuristflower/st
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK