

Introducing the Accessibility Checker Beta API
source link: https://blog.developer.adobe.com/introducing-the-accessibility-checker-beta-api-08ed594ebc8b
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Introducing the Accessibility Checker Beta API
Our new beta API will help you assess how well your documents meet accessibility standards

A few months ago, we launched the Accessibility Auto-Tag API, a powerful tool that intelligently examines your source PDF documents and attempts to tag them by identifying reading order, tables, and more.
While this is not meant to be a “complete” accessibility solution, it can go a long way in automating a good chunk of the work required to properly make documents more accessible.
As part of support for this service, today we’re happy to announce the beta release of a new API: the Accessibility Checker API.
This API will take your document and check how well it conforms to accessibility standards. It returns both a human-readable HTML report as well as a machine-friendly JSON result.
Let’s take a look at how this service operates.
Prerequitistes
First and most importantly, at this time the beta for the API is in private testing only. That means you’re free to read the docs, but using the API requires reaching out to us and describing your use case.
Fill out the form here and someone from our team will reach out shortly.
Secondly, you cannot use existing credentials to test this API. Once you’ve been approved to kick the tires, create new credentials here and use them in your testing.
Note that currently we only have SDK support in Java, but the REST API will work just fine and that’s what we’ll demonstrate here.
Sample Code
All of the Acrobat Services operate virtually the same via the REST APIs. These new APIs were first introduced in September of last year and the beauty of them is that once you’ve written one integration, you can re-use nearly all of your code for other parts of the service as well. We covered the ‘flow’ last year (see “Announcing the New Adobe Document Services REST APIs”) so we’ll only briefly cover it here.
Get an Access Token
To use the Accessibility Checker API via REST, first you‘ll need to exchange your credentials, a Client ID and Secret, for an access token. Here’s sample code in Node.js:
Create an Asset and Upload the PDF
In order for the API to scan your PDF, you need to upload it (external cloud storage support will come later).
This is a two-step process. First, you tell us what kind of file you are uploading. This is done by hitting the assets endpoint with your access token, client ID, and the type of file, in this case, application/pdf.
This returns an asset record that includes a URL that allows you to upload your binary data:
Create the Job
Like every other API in the offering, you create a “job” that includes various arguments dependant on the specific operation.
At this time, our docs cover three arguments. The only required argument is the ID of the asset created earlier. Then there are two optional arguments to let you define a page start and end range. This could be useful in cases where you know that some pages do not need to be checked, or perhaps limit the check to a portion of a large PDF document.
Once again, here’s sample Node.js code hitting the endpoint to create the job. Notice that on a good result, you get a URL in the Location here.
Poll the Job
You can now poll the job to see if it’s done. In this example, we’ve used a simple interval to check the result and return it when it is successful:
The two-second delay here is mostly arbitrary. In general, the jobs complete after a few seconds so this will only need to run a few times.
When (successfully) done, the result looks like this:
Download the Result
Finally, you can download the result. As mentioned above, you get both an HTML report attached to a PDF and a JSON result. You may not need both, but here’s a utility method to grab them and an example of using it:
Working with the Results
Once you have the results, what do they look like?
First, in the PDF, be sure to open the Attachments panel and double-click on the HTML file. This gives you a report like so:
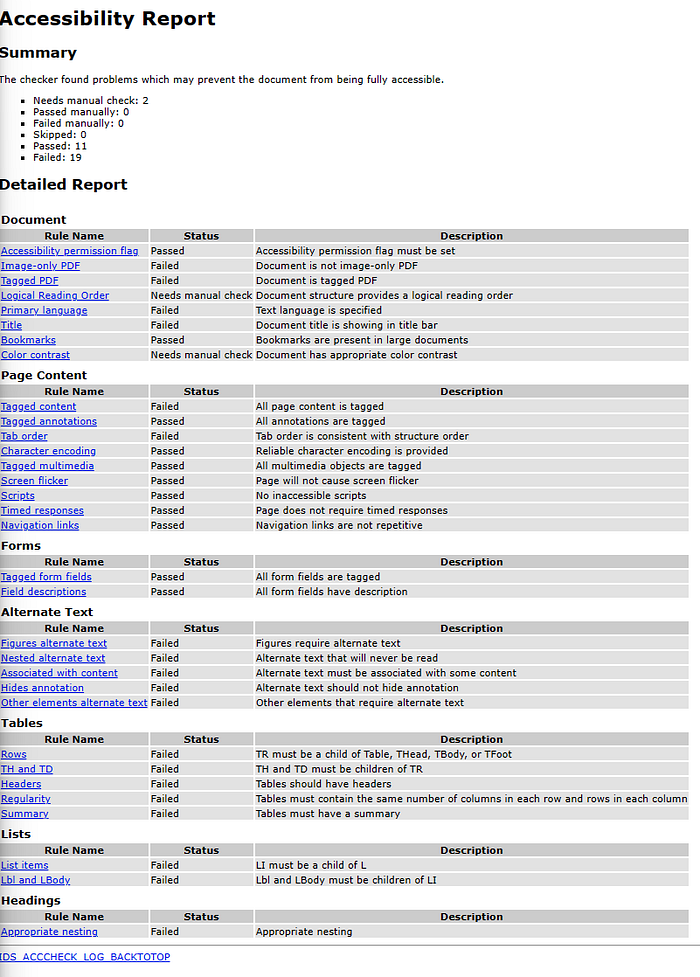
In the screenshot above, you can see a high-level summary and then a detailed breakdown of the issues. Each link goes to a page that gives much more information about the issue.
The JSON report contains the same information, minus links to educational resources:
Next Steps
Hopefully, this quick introduction demonstrates just how easy, and powerful, this new API can be for your document processes. The entire Node.js script used above may be found here, and of course, can be adapted to any other language via the REST API. Be sure to visit the forums with your questions!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK