

2023时间序列预测热门研究点总结
source link: https://www.51cto.com/article/778083.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

2023时间序列预测热门研究点总结
这篇文章给大家总结一下2023年中,时间序列预测领域的几个热门研究点。通过这些研究点,我们可以挖掘时间序列预测领域的研究中,业内在朝什么样的方向发展,启发我们在自己的工作中寻找合适的创新点。
总结下来,2023年有几个非常热的点,在很多论文中被提起。主要包括以下几个:
多元序列预测中变量的独立、联合建模;
大模型+时间序列;
多粒度时间序列建模
PatchTST框架的后续改进方法
1、独立/联合建模
多元时间序列预测问题中,从多变量建模方法的维度有两种类型,一种是独立预测(channel independent,CI),指的是把多元序列当成多个单变量预测,每个变量分别建模;另一种是联合预测(channel dependent,CD),指的是多变量一起建模,考虑各个变量之间的关系。
CI方法只考虑单个变量,模型更简单,但是天花板也较低,因为没有考虑各个序列之间的关系,损失了一部分关键信息;而CD方法考虑的信息更全面,但是模型也更加复杂。
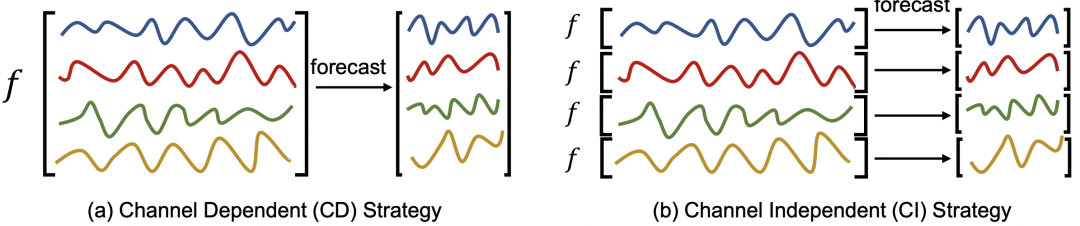
在最初的多元时间序列模型中,大家没有特别关注这个问题,都是把各个变量直接杂糅到一起输入到模型中。PatchTST提取每个变量独立的建模,完全抹掉各个变量之间的关系,并且取得了比多变量融合更优的效果。这也开启了2023年对独立预测、联合预测的探讨。文章主要围绕着联合预测有什么弊端,以及如何改进展开。
比如The Capacity and Robustness Trade-off: Revisiting the Channel Independent Strategy for Multivariate Time Series Forecasting这篇文章分析出大多数任务上独立建模效果更好,是由于联合建模太过复杂,更容易出现过拟合问题,对时间序列分布变化的鲁棒性差。
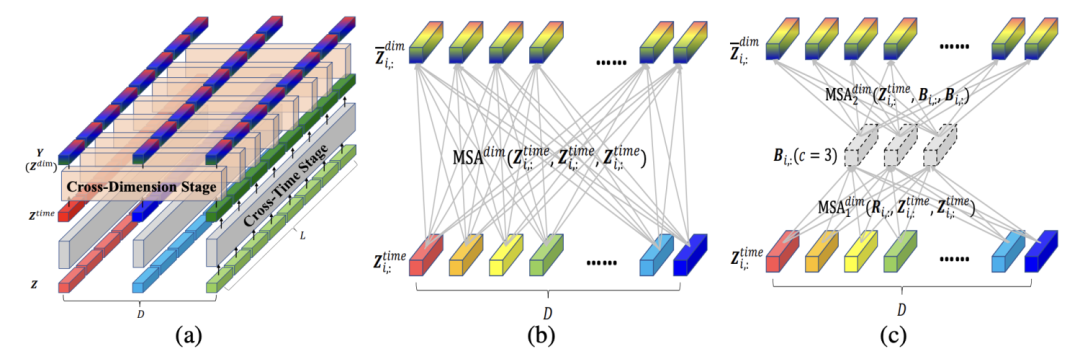
而CROSSFORMER: TRANSFORMER UTILIZING CROSSDIMENSION DEPENDENCY FOR MULTIVARIATE TIME SERIES FORECASTING等一系列文章则没有放弃联合建模,对联合建模进一步深入优化,通过更精细化的多变量关系学习,以及将时间维度预测和多变量间关系预测拆分成互不干扰的两个模块,提升多变量联合建模的鲁棒性。
2、大模型+时间序列
在大模型的浪潮下,2023年涌现了一大批大模型+时间序列的工作。这篇文章为大家整理了2023年大模型时间序列模型的相关工作。大模型应用到时间序列,有2种应用类型。一种是将其他领域训练好的大模型,通过跨域自适应的方式,迁移到时间序列领域;另一种是使用时间序列域内本身的数据,从头开始训练一个时间序列大模型,解决各类任务。
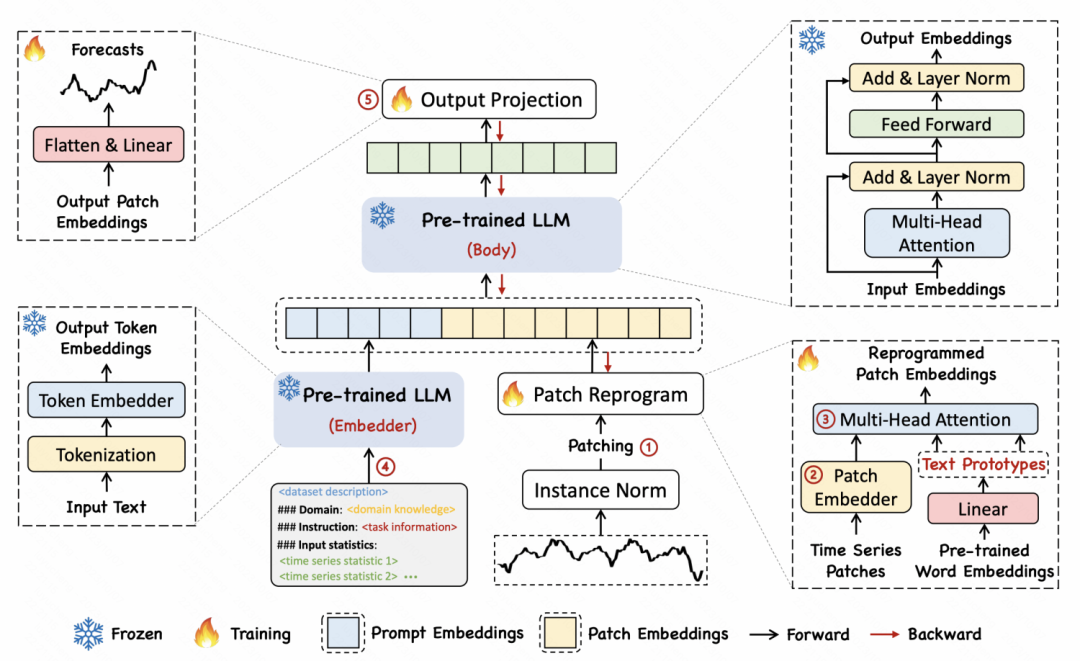
比如Large Language Models Are Zero-Shot Time Series Forecasters、TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS等文章,就是将NLP领域的预训练GPT适配到时间序列领域。适配方法,也从最初简单的将时间序列数据转换成适配语言模型的输入,到在模型中引入Adaptor的方式逐渐发展。
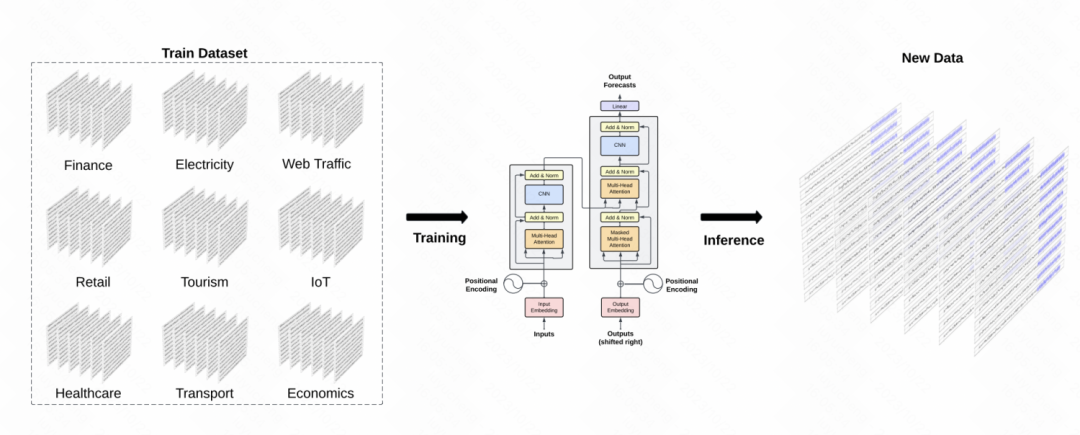
而Lag-Llama: Towards Foundation Models for Time Series Forecasting、TimeGPT-1等文章,则是直接使用时间序列领域的数据,训练时间序列大模型,模型结构则和NLP中的GPT、Llama等保持一致,只做少量时间序列领域的适配。
3、多粒度建模
使用patch进行时间序列数据处理+Transformer模型结构的方式逐渐成为时间序列预测的主流模型。然而,之前的很多工作,都使用一个固定的时间窗口进行patch处理,降低了模型对于不同scale规律性的捕捉。这也衍生出一个研究点:如何设计多粒度的patch方法,增强patch+Transformer的建模能力。
A Multi-Scale Decomposition MLP-Mixer for Time Series Analysis、Multi-resolution Time-Series Transformer for Long-term Forecasting等工作中,都提出了非常多多粒度建模的方式。这些建模方法引入了一个信息增益,就是时间序列具有不同粒度的季节性,一种粒度难以刻画,并且patch窗口的大小也不好设置。那就不如设置多种patch窗口大小,然后再用一个可学习的融合网络,将这些不同粒度的信息融合到一起。
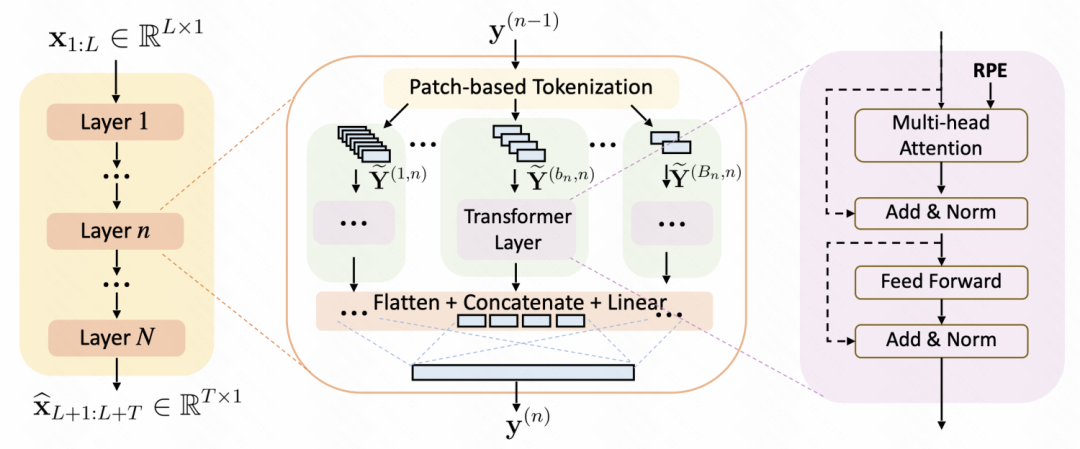
这种多粒度建模的方法,后续也逐渐会成为Transformer时间序列建模方法的标配。
4、PatchTST框架改进
基于Patch+Transformer的时间序列预测模型在2022年成为主流,自然在2023年引入了一系列改进,包括输入数据的组织形式、模型结构、频域等其他维度信息引入等多个方面。
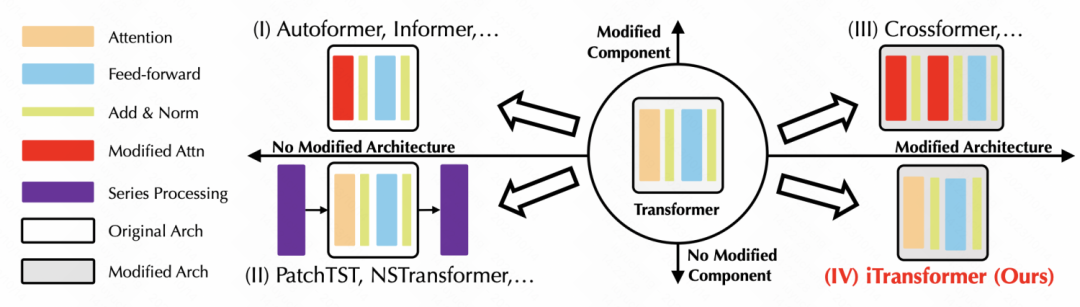
像ITRANSFORMER: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING这篇文章,将Transformer直接做了个反向操作,将原来在时间维度上构建token embedding,改成了序列维度构建token embedding,并利用attention学习各个变量序列之间的关系。非常简单的一个代码实现,就提升了Transformer在时间序列预测上的效果。
而Take an Irregular Route: Enhance the Decoder of Time-Series Forecasting Transformer中,则是通过对Decoder的改进,使Transformer具备了层次信息融合的能力,从多个粒度利用Encoder各个编码阶段的信息,提升Transformer的时序预测效果。

2023年的时间序列领域的技术发展,除了上述一些研究点外,还有非常多其他的创新,整体感觉是越来越和NLP、CV等主流深度学习领域的研究融为一体了,这对于时间序列的发展也是极大的利好。为了更多的CV、NLP中成功的经验,都可以在时间序列中进行适配和应用。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK