

4090成A100平替?token生成速度只比A100低18%,上交大推理引擎火了
source link: https://www.51cto.com/article/777304.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

4090成A100平替?token生成速度只比A100低18%,上交大推理引擎火了
不仅如此,PowerInfer 与最先进的本地LLM推理框架 llama.cpp 相比,在单个 RTX 4090 (24G) 上运行 Falcon (ReLU)-40B-FP16,实现了 11 倍多的加速,还能保持模型的准确性。
具体来说,PowerInfer 是一个用于本地部署 LLM 的高速推理引擎。与那些采用多专家系统(MoE)不同的是,PowerInfer 通过利用 LLM 推理中的高度局部性,巧妙的设计了一款 GPU-CPU 混合推理引擎。
它的工作原理是这样的,将频繁激活的神经元(即热激活,hot-activated)预加载到 GPU 上以便快速访问,而不常激活的神经元(冷激活,cold-activated)(占大多数)则在 CPU 上计算。
这种方法显著减少了 GPU 内存需求和 CPU-GPU 数据传输。

- 项目地址:https://github.com/SJTU-IPADS/PowerInfer
- 论文地址:https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf
PowerInfer 可以在配备单个消费级 GPU 的 PC 上高速运行 LLM。现在用户可以将 PowerInfer 与 Llama 2 和 Faclon 40B 结合使用,对 Mistral-7B 的支持也即将推出。
一天的时间,PowerInfer 就获得了 2K 星标。
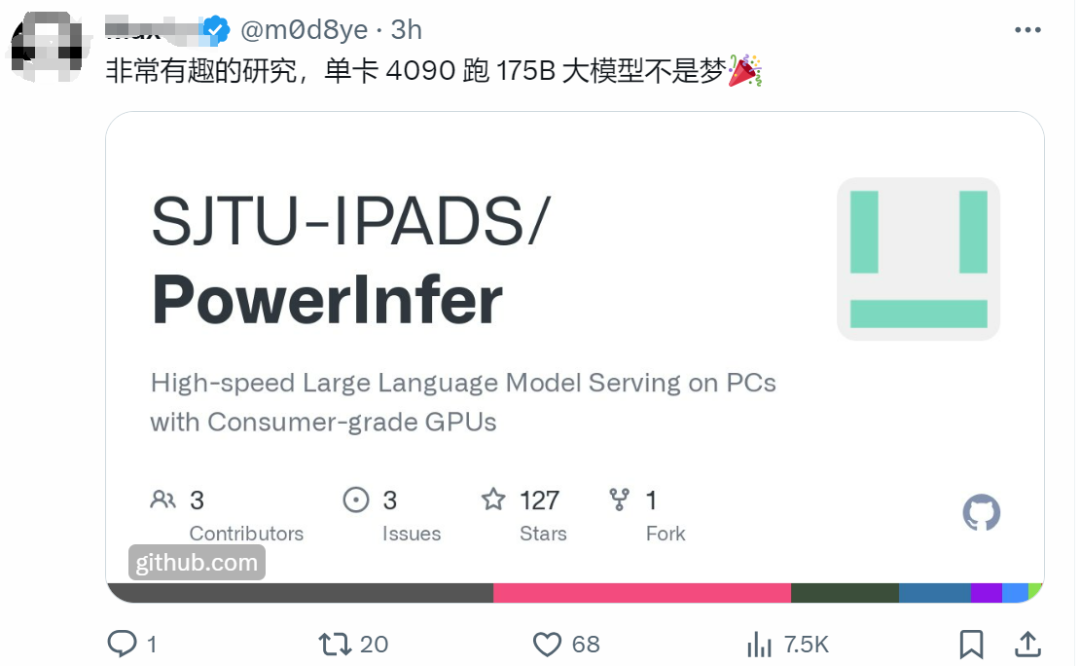
看到这项研究后,网友激动的表示:单卡 4090 跑 175B 大模型不再是梦。
PowerInfer 架构
PowerInfer 设计的关键是利用 LLM 推理中固有的高度局部性,其特征是神经元激活中的幂律分布。这种分布表明,一小部分神经元(称为热神经元)跨输入一致激活,而大多数冷神经元则根据特定输入而变化。PowerInfer 利用这种机制设计了 GPU-CPU 混合推理引擎。
下图 7 展示了 PowerInfer 的架构概述,包括离线和在线组件。离线组件处理 LLM 的激活稀疏,区分热神经元和冷神经元。在线阶段,推理引擎将两种类型的神经元加载到 GPU 和 CPU 中,在运行时以低延迟服务 LLM 请求。
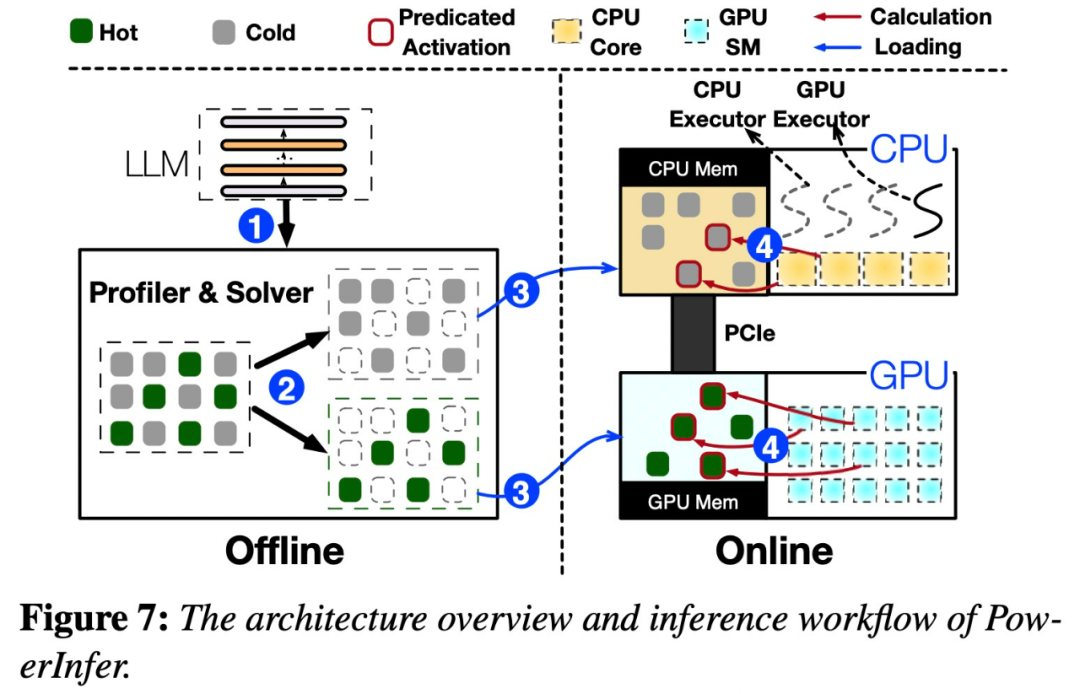
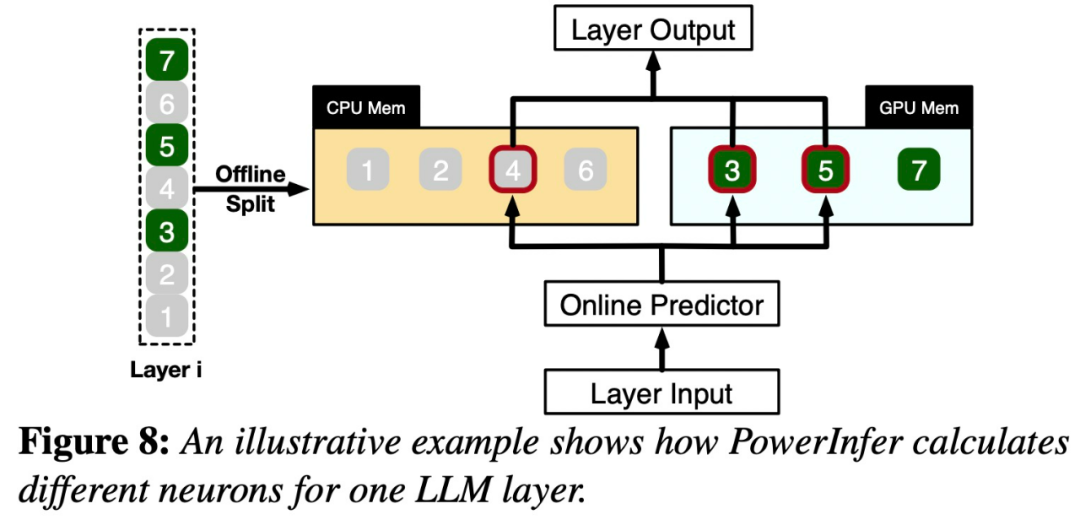
图 8 说明了 PowerInfer 如何协调 GPU 和 CPU 来处理层之间的神经元。PowerInfer 根据离线数据对神经元进行分类,将热激活的神经元(例如索引 3、5、7)分配给 GPU 内存,将其他神经元分配给 CPU 内存。
一旦接收到输入,预测器就会识别当前层中哪些神经元可能会被激活。值得注意的是,通过离线统计分析识别的热激活神经元可能与运行时激活行为不一致。例如,神经元 7 虽然标记为热激活,但事实却并非如此。然后,CPU 和 GPU 都会处理激活的神经元,忽略没有激活的神经元。GPU 计算神经元 3 和 5,而 CPU 处理神经元 4。神经元 4 的计算完成后,其输出将发送到 GPU 进行结果集成。
该研究使用不同参数的 OPT 模型进行了实验,参数从 6.7B 到 175B 不等,还包括 Falcon (ReLU)-40B 和 LLaMA (ReGLU)-70B 模型。值得注意的是,175B 参数模型的大小与 GPT-3 模型相当。
本文还将 PowerInfer 与 llama.cpp 进行了比较,llama.cpp 是最先进的本地 LLM 推理框架。为了便于进行比较,该研究还扩展了 llama.cpp 以支持 OPT 模型。
由于本文专注于低延迟设置,因此评估指标是端到端生成速度,量化为每秒生成 token 的数量(tokens/s)。
该研究首先比较了 PowerInfer 和 llama.cpp 的端到端推理性能,批大小为 1。
图 10 展示了在配备 NVIDIA RTX 4090 的 PC-High 上各种模型和输入输出配置的生成速度。平均而言,PowerInfer 实现了 8.32 tokens/s 的生成速度,最高可达 16.06 tokens/s, 显着优于 llama.cpp,比 llama.cpp 提高了 7.23 倍,比 Falcon-40B 提高了 11.69 倍。
随着输出 token 数量的增加,PowerInfer 的性能优势变得更加明显,因为生成阶段在整体推理时间中扮演着更重要的角色。在此阶段,CPU 和 GPU 上都会激活少量神经元,与 llama.cpp 相比,减少了不必要的计算。例如,在 OPT-30B 的情况下,每生成一个 token,只有大约 20% 的神经元被激活,其中大部分在 GPU 上处理,这是 PowerInfer 神经元感知推理的好处。
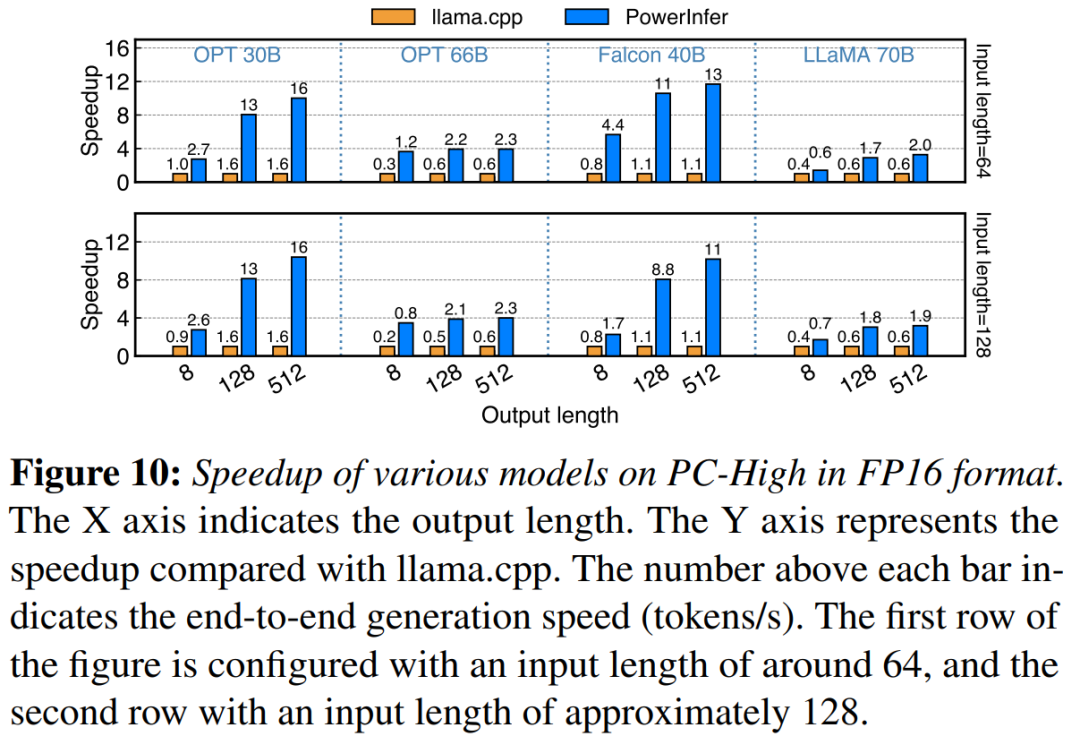
图 11 显示,在 PC-Low 上,PowerInfer 仍然比 llama.cpp 获得了相当大的性能增强,平均加速为 5.01 倍,峰值为 7.06 倍。然而,与 PC-High 相比,这些改进较小,主要是由于 PC-Low 的 11GB GPU 内存限制。此限制会影响可分配给 GPU 的神经元数量,特别是对于具有大约 30B 参数或更多参数的模型,导致更大程度地依赖于 CPU 来处理大量激活的神经元。
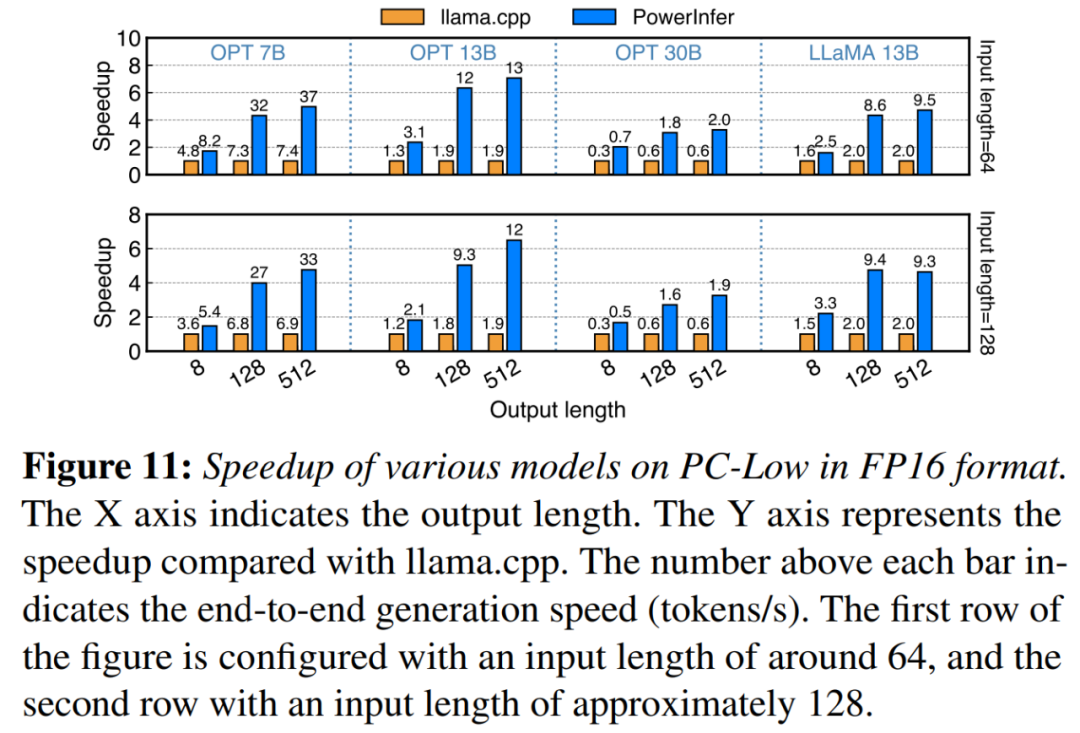
图 12 显示了 PowerInfer 和 llama.cpp 的 CPU 和 GPU 之间的神经元负载分布。值得注意的是,在 PC-High 上,PowerInfer 显着增加了 GPU 的神经元负载份额,从平均 20% 增加到 70%。这表明 GPU 处理了 70% 的激活神经元。然而,在模型的内存需求远远超过 GPU 容量的情况下,例如在 11GB 2080Ti GPU 上运行 60GB 模型,GPU 的神经元负载会降低至 42%。这种下降是由于 GPU 的内存有限,不足以容纳所有热激活的神经元,因此需要 CPU 计算这些神经元的一部分。

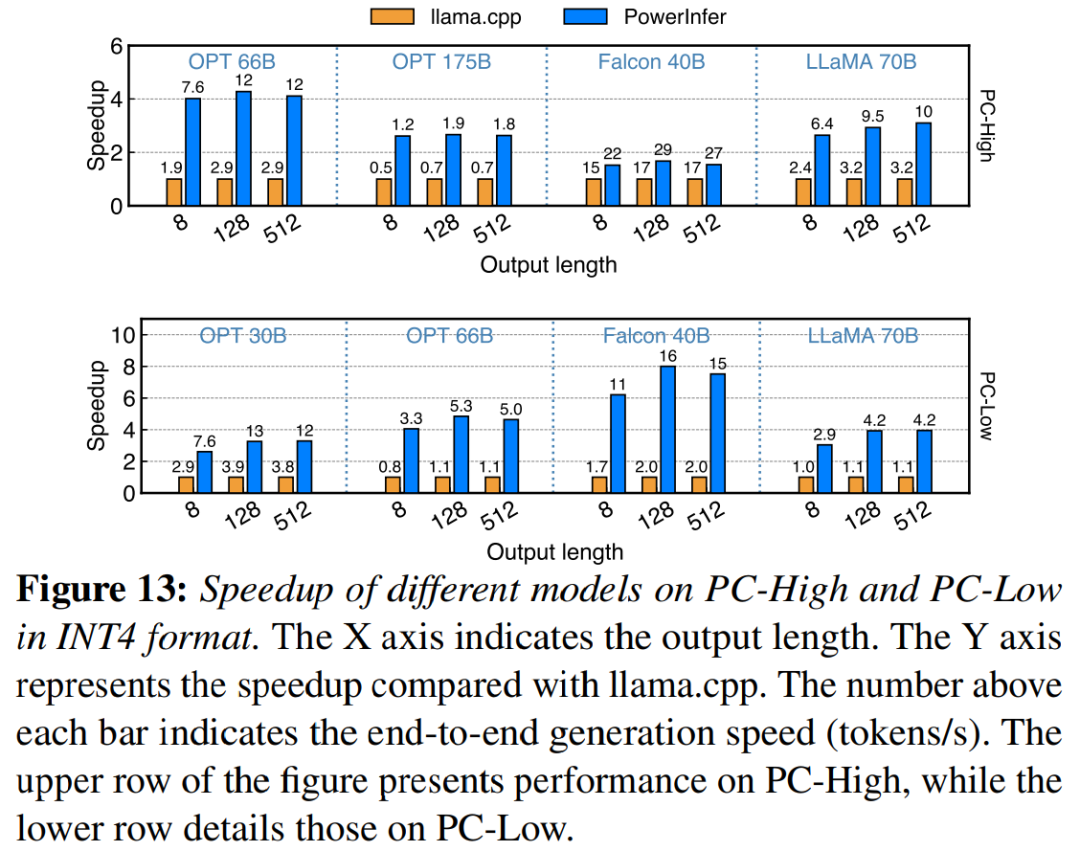
图 13 说明 PowerInfer 有效支持使用 INT4 量化压缩的 LLM。在 PC-High 上,PowerInfer 的平均响应速度为 13.20 tokens/s,峰值可达 29.08 tokens/s。与 llama.cpp 相比,平均加速 2.89 倍,最大加速 4.28 倍。在 PC-Low 上,平均加速为 5.01 倍,峰值为 8.00 倍。由于量化而减少的内存需求使 PowerInfer 能够更有效地管理更大的模型。例如,在 PC-High 上使用 OPT-175B 模型进行的实验中,PowerInfer 几乎达到每秒两个 token,超过 llama.cpp 2.66 倍。
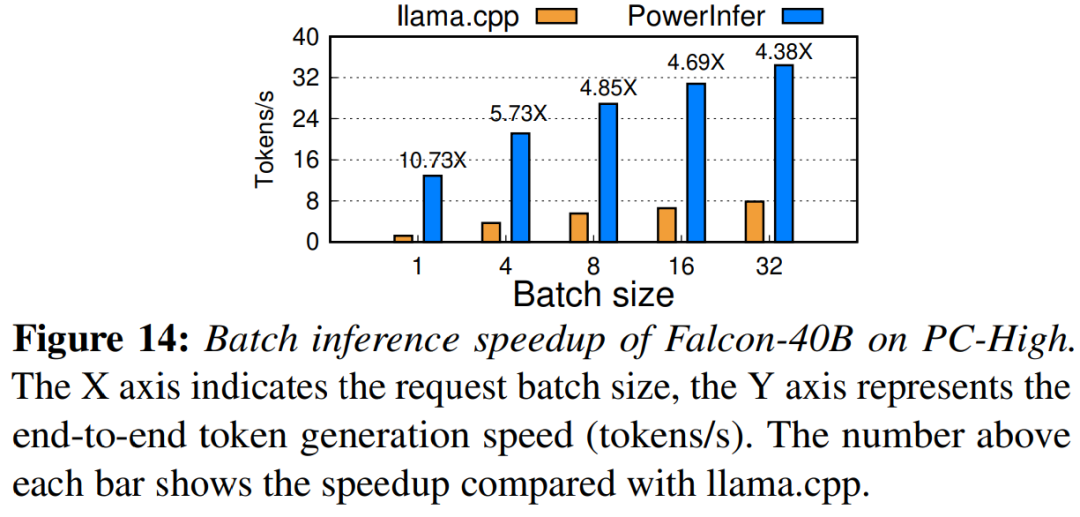
最后,该研究还评估了 PowerInfer 在不同批大小下的端到端推理性能,如图 14 所示。当批大小小于 32 时,PowerInfer 表现出了显着的优势,与 llama 相比,性能平均提高了 6.08 倍。随着批大小的增加,PowerInfer 提供的加速比会降低。然而,即使批大小设置为 32,PowerInfer 仍然保持了相当大的加速。
参考链接:https://weibo.com/1727858283/NxZ0Ttdnz
了解更多内容,请查看原论文。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK