

Skywork: A More Open Bilingual Foundation Model 简读
source link: https://finisky.github.io/skywork-summary/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

昆仑的天工模型一直走开源路线,最近放出了技术报告,其中关于预训练模型刷榜作弊的部分引发了广泛的讨论,把大家心照不宣的事情首次放到了台面上 :-)。本文来看下这篇技术报告的亮点(非全文精读,仅摘要有趣的点,细节可阅读原论文)。
# Skywork: A More Open Bilingual Foundation Model
两阶段预训练
用SkyPile-Main和SkyPile-STEM进行两阶段预训练的原因:
SkyPile-STEM的数据与CEVAL、MMLU和GSM8K的数据非常类似,用于SFT阶段直接优化相关指标更合适。而Stage1仅使用SkyPile-Main训练的方式,可以更好评估通用预训练(general-purpose pretraining)和目标性预训练(targeted pretraining)的影响- 提供两份不同的模型,Stage1的通用基座能更好建模自然语言,可应用于不需要STEM场景的任务
一句话总结,仅用SkyPile-Main这种通用语料训练的模型才叫基座模型。
两阶段训练的Trick
为避免灾难性遗忘(catastrophic
forgetting),在Stage2用SkyPile-STEM继续预训练时也要与Stage1的SkyPile-Main混在一起训练。
训练监控指标
只观察训练损失可能会存在过拟合风险。训练损失与验证损失相等的前提条件是:训练数据仅使用一次。而训练大模型时,高质量训练数据常常被多轮训练,此外,即使经过仔细去重的数据,里面依然存在重复。因此,训练监控应该更注重在留存数据集上的验证损失。
实践中,作者们使用混合了各种任务(不同数据分布)的验证集进行训练过程监控。不过作者们也指出在多个留存数据集上观察验证损失并不是一个常见做法。
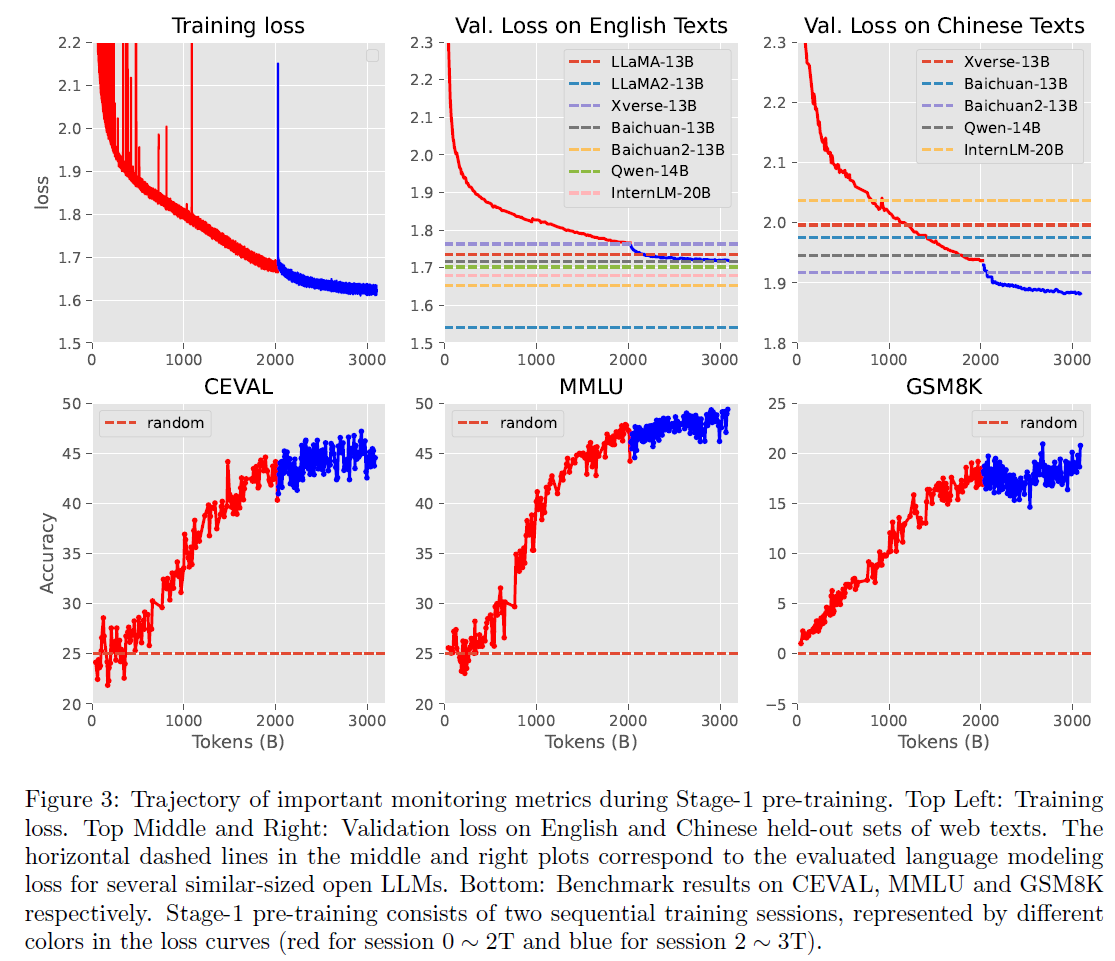
SkyPile语料库
构建语料库主要考虑两个维度:文本质量和信息分布。具体来说构造流水线有四个步骤:结构化提取,数据分布过滤,去重,质量过滤。
为支持中英双语,SkyPile特意加入了一些高质量平行语料,以保证中英双语在段落上的对齐。
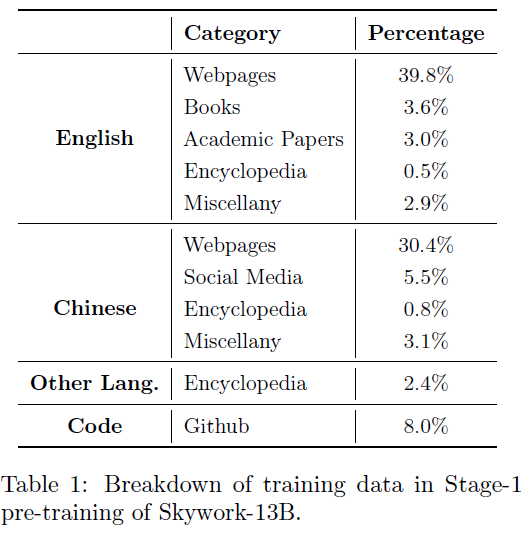
训练Infra
Skywork-13B在有64个NVIDIA-HGX-A800节点的集群上进行,共512块A800(80G)GPU。节点内使用400GB/s
NVLink连接,节点间用800Gb/s
RoCE连接,训练框架采用Megatron-LM。考虑到13B模型的规模,避免使用各种GPU内存优化策略以加速训练,仅使用了数据并行(DP),流水线并行(PP)与ZeRO-1。训练共使用39天。
Stage-2预训练数据混合方案
在用STEM数据继续训练时,由于与Stage-1的Main数据分布显著不同,实验发现缓慢增加STEM数据的混合比例效果最好。实践中STEM数据占比由10%缓慢增加到40%。
刷榜作弊的讨论
预训练模型,或者说基座模型是可被用于迁移学习的基础模型。但基座模型本身仅可做句子补全,所谓用处不大,因此对于基座模型的效果往往要通过在下游任务上的表现得以体现。
Pre-trained language models, or foundation models, are intended to be used in transfer learning as a general purpose backbone. As a foundation model in itself has little usage other than sentence completion, the quality of a foundation model is typically evaluated in terms of its performance in those tasks. Apparently, when it comes to improve a foundation model’s quality as measured by its task performance, it is always far more efficient to train the model on in-domain data of that task, as compared to general-purpose data (web texts).
直白来说就是提升基座模型的能力是练内功,很难,而取巧很容易,在预训练中加入相应下游任务的数据,效果立竿见影。为说明这个问题,作者们做了个实验,用一个仅用0.5T数据预训练的弱模型,在1B下游数据上训练(其实是微调)后就能超过13B模型的效果:
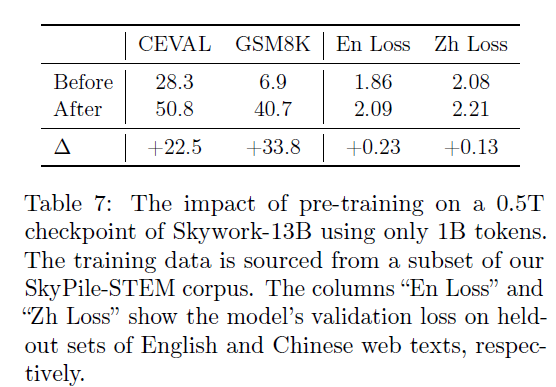
但这样的模型只是花拳绣腿,刷榜效果不错(作弊利器),但实际的语言建模能力会受损(对齐税),从上面的验证损失就能看出来。
为进一步验证,作者们提出了两个指标,用于验证在预训练时是否加入了下游任务数据作弊:
- L(train): GSM8K训练集上的损失
- L(test): GSM8K测试集上的损失
- L(ref): 用GPT-4构造的类GSM8K数据集上的损失
理论上,如果语言模型未见过上述数据,三者的损失应该基本接近。否则,预训练时有可能混入了这些下游数据,导致数据污染。下表展示了一些数据异常的情况:
- D1 = L(test)-L(ref)
- D2 = L(test)-L(train)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK