

译:使用大型语言模型进行开发所需了解的知识
source link: https://weedge.github.io/post/llm/all-you-need-to-know-to-develop-using-large-language-models/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


本文的目的是简单地解释开始开发基于 LLM 的应用程序所需的关键技术。它面向对机器学习概念有基本了解并希望深入研究的软件开发人员、数据科学家和人工智能爱好者。本文还提供了许多有用的链接以供进一步研究。这会很有趣!
注:本文可以作为一个索引目录(进一步阅读资料深入学习),从整体上了解下,毕竟现在LLM发展很快,可以发散或者focus某个领域;大部分LLM相关开源实现,可以手动demo下过程,至于炼丹了解过程即可,主要在场景上结合工程去利用好大力神丸在生产环境落地;还有就是应用场景,国内app应该可以复刻,如果模型和数据有了,缺个落地idea的话~
1. 大型语言模型(LLM)简介
我想你已经听过一千遍什么是大语言模型,所以不会让你负担过重。需要知道的是:大型语言模型(LLM)是一种大型神经网络模型,它根据先前预测的标记来预测下一个标记。就这样。
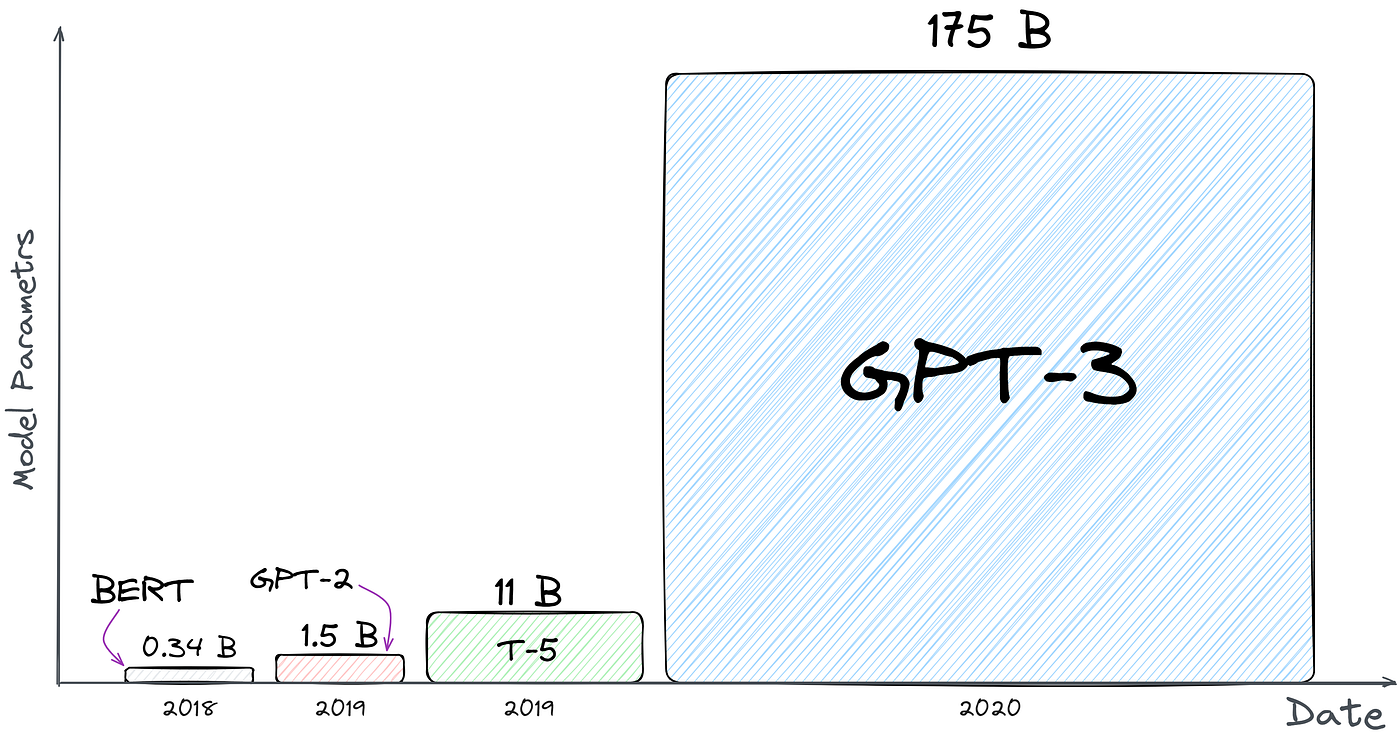
模型参数数量的比较。看看 GPT-3 有多大就知道了。没有人知道 GPT-4……
大语言模型的受欢迎程度归因于其多功能性和有效性。它们完美地应对翻译、摘要、意义分析等任务。
大语言模型能力
使用大语言模型的一些项目示例:
- Notion AI — 帮助提高写作质量、生成内容、纠正拼写和语法、编辑语音和语调、翻译等。
- GitHub Copilot — 通过提供自动完成风格的建议来改进您的代码。
- Dropbox Dash — 提供自然语言搜索功能,并且还专门引用了答案源自哪些文件。
如果想详细了解大语言模型的工作原理,建议您阅读优秀的文章“对大型语言模型的非常温和的介绍,无需炒作”
2. 开源与闭源模型
主要差异:
- 隐私——大公司选择自托管解决方案的最重要原因之一。
- 快速原型制作——非常适合小型初创公司快速测试他们的想法,而无需过多的支出。
- 生成质量——可以针对特定任务微调模型,也可以使用付费 API。
对于什么是好什么是坏,没有明确的答案。强调了以下几点:
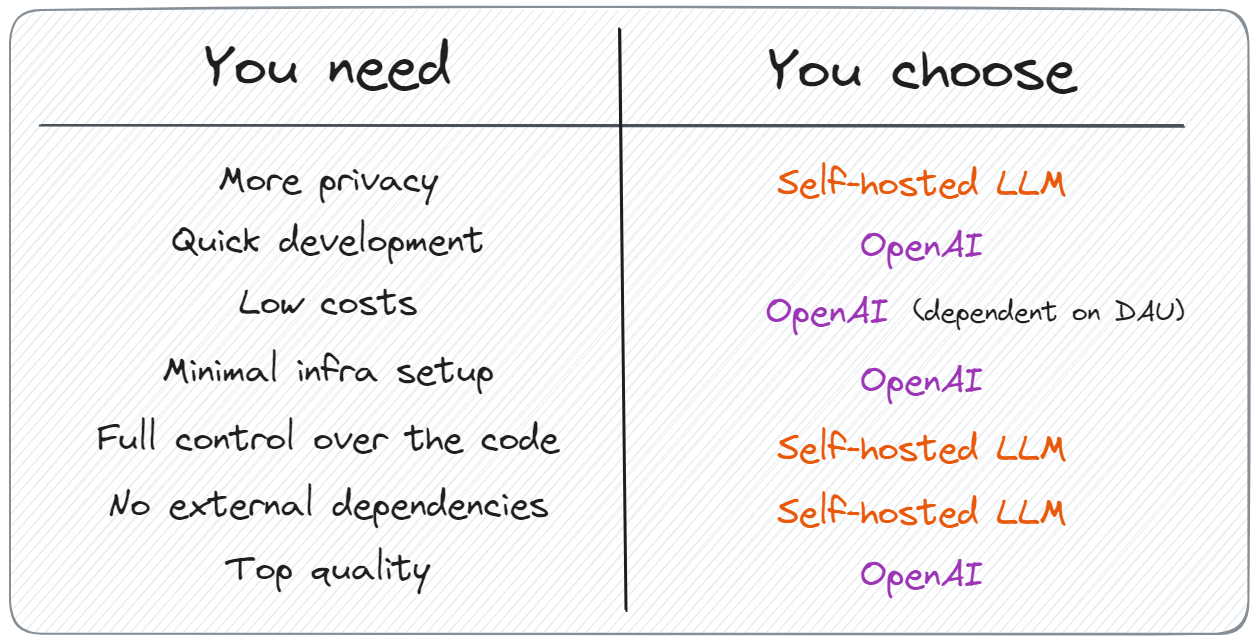
如果有兴趣深入研究细节,建议阅读之前的文章“您不需要托管大语言模型,是吗?”。探索大语言模型系列以查看所有模型。
3. 提示词工程的艺术
许多人认为这是伪科学或只是暂时的炒作。但事实是,我们仍然不完全了解大语言模型是如何运作的。为什么他们有时会提供高质量的答复,有时会捏造事实(产生幻觉)?或者为什么在提示中添加“让我们逐步思考”会突然提高质量?
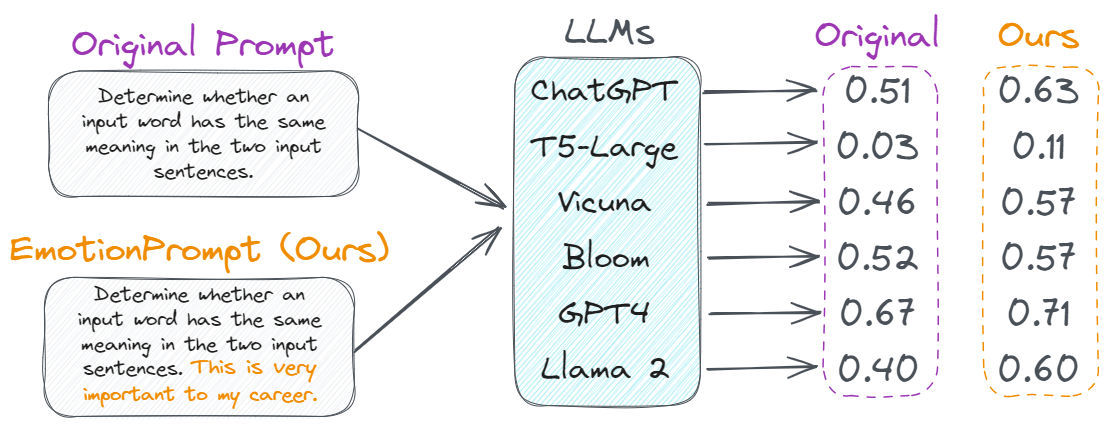
添加情感色彩可以提高任何模型的质量。来源
由于这一切,科学家和爱好者只能尝试不同的提示,试图让模型表现得更好。
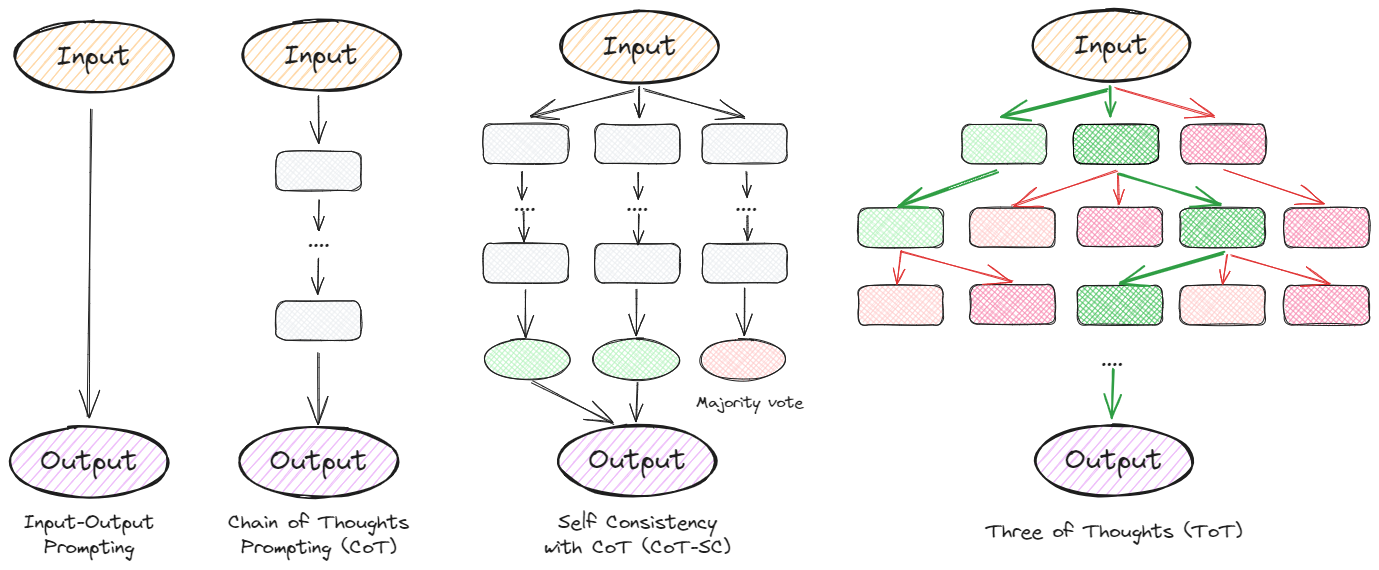
说明大语言模型解决问题的各种方法的示意图
我不会用复杂的提示链让你感到厌烦;相反,我只给出一些可以立即提高性能的示例:
- “让我们一步一步思考” 对于推理或逻辑任务非常有效。
- “深吸一口气,一步步解决这个问题” 上一点的改进版本。它可以增加几个百分点的质量。
- “这对我的职业生涯非常重要” 只需将其添加到提示的末尾,发现质量提高了 5-20%。
另外,我会立即分享一个有用的提示模板:
让我们结合我们的X命令和清晰的思维,以循序渐进的方式快速准确地破译答案。提供详细信息并在答案中包含来源。这对我的职业生涯非常重要。
其中X是您正在解决的任务的行业,例如编程。
我强烈建议您花几个晚上探索快速的工程技术。这不仅可以让您更好地控制模型的行为,还有助于提高质量并减少幻觉。为此,我建议阅读《提示词工程指南》
有用的链接:
- Prompttools — 快速测试和实验,支持两种 LLM(例如 OpenAI、LLaMA)。
- Promptfoo — 测试和评估 LLM 输出质量。
- Awesome ChatGPT Prompts — 用于 ChatGPT 模型的提示示例集合。
4.合并新数据:检索增强生成(RAG)
RAG是一种将LLM与外部知识库相结合的技术。这允许模型将原始训练集中未包含的相关信息或特定数据添加到模型中。
尽管这个名字令人生畏(有时我们会在其中添加“reranker”一词),但它实际上是一种相当古老且出奇简单的技术:
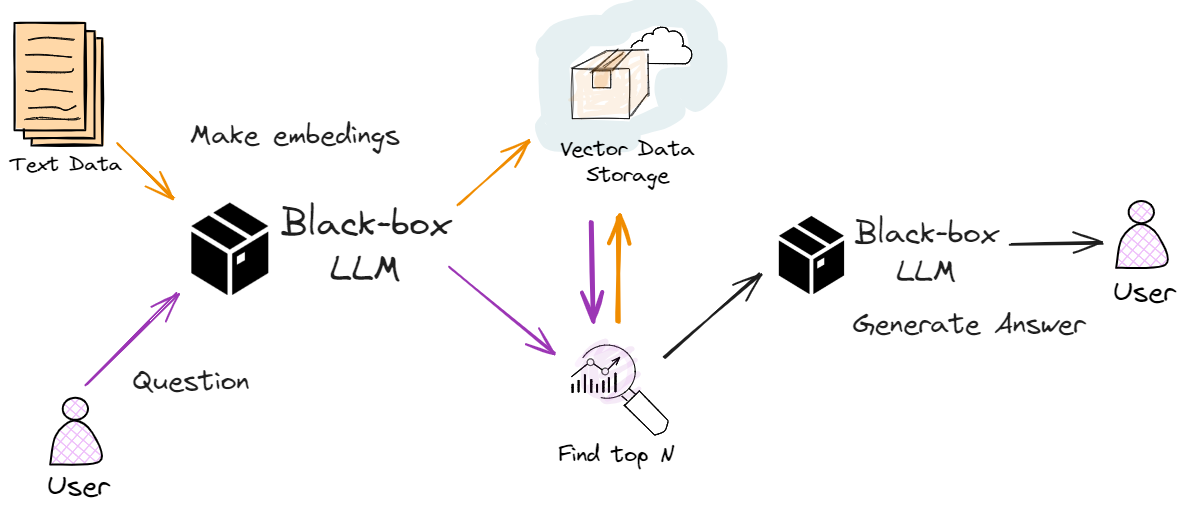
RAG 工作原理示意图
- 将文档转换为数字,称之为嵌入(embedding)。
- 然后,使用相同的模型将用户的搜索查询转换为嵌入。
- 查找前 K 个最接近的文档,通常基于余弦相似度。
- 要求大语言模型根据这些文件生成回复。
- 对当前信息的需求:当应用程序需要不断更新的信息(例如新闻文章)时。
- 特定领域的应用程序:适用于需要大语言模型培训数据之外的专业知识的应用程序。例如,公司内部文件。
何时不使用
- 通用会话应用程序:信息需要通用且不需要附加数据的地方。
- 有限的资源场景: RAG 的检索组件涉及搜索大型知识库,这可能在计算上昂贵且缓慢,但仍然比微调更快且成本更低。
使用 RAG 构建应用程序
一个很好的起点是使用LlamaIndex 库。它允许您快速将数据连接到大语言模型。为此,只需要几行代码:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# 1. Load your documents:
documents = SimpleDirectoryReader("YOUR_DATA").load_data()
# 2. Convert them to vectors:
index = VectorStoreIndex.from_documents(documents)
# 3. Ask the question:
query_engine = index.as_query_engine()
response = query_engine.query("When's my boss's birthday?")
print(response)
在实际应用中,事情明显更加复杂。就像在任何开发中一样,您会遇到许多细微差别。例如,检索到的文档可能并不总是与问题相关,或者可能存在速度问题。然而,即使在这个阶段,也可以显着提高搜索系统的质量。
进一步阅读
- 构建基于 RAG 的 LLM 应用程序用于生产 一篇关于 RAG 主要组件的优秀详细文章。
- 为什么您的 RAG 在生产环境中不可靠 一篇很棒的文章,它以清晰的语言解释了使用 RAG 时可能出现的困难。
- 使用 LlamaIndex 导航知识图的 7 种查询策略 一篇内容丰富的文章,详细而细致地了解了使用 LlamaIndex 构建 RAG 管道。
- OpenAI 检索工具 如果想要最少的工作,使用 OpenAI 的 RAG。
5. 微调大语言模型
微调是在特定数据集上继续训练预训练的 LLM 的过程。可能会问,如果已经可以使用 RAG 添加数据,为什么还需要进一步训练模型。简单的答案是,只有微调才能定制模型以理解特定领域或定义其风格。例如,通过对个人信件进行微调来创建自己的副本:
如果已经相信了它的重要性,那么看看它是如何工作的:
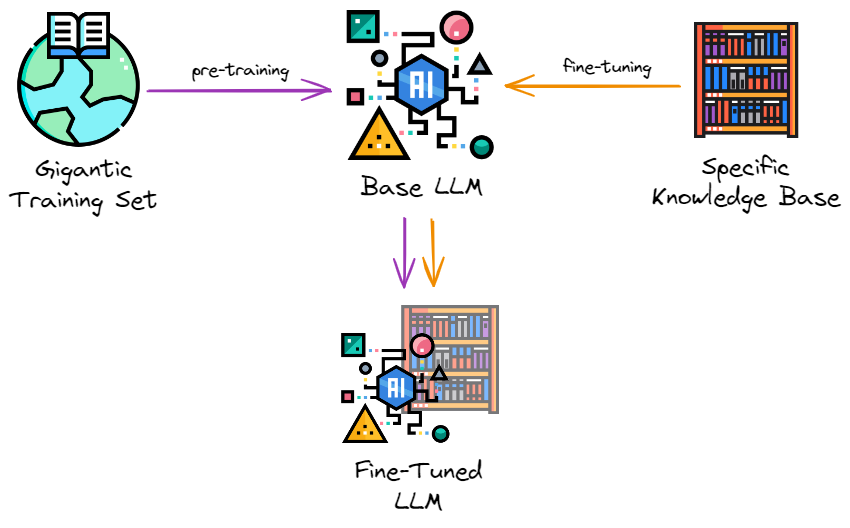
对特定领域数据进行微调的经典方法(所有图标均来自flaticon)
- 接受训练有素的大语言模型,有时称为基础大语言模型。可以从HuggingFace下载它们。
- 准备您的训练数据。只需编写说明和响应即可。这是此类数据集的示例;还可以使用 GPT-4生成合成数据。
- 选择合适的微调方法。目前比较流行的是LoRA和QLoRA。
- 根据新数据微调模型。
- 垂直领域应用程序:当应用程序处理专门或非常规主题时。例如,法律文档应用需要理解和处理法律术语。
- 自定义语言风格:适用于需要特定语气或风格的应用程序。例如,创建一个人工智能角色,无论是名人还是书中的角色。(衍生场景:旅游景点数字人,游戏NPC,二次元社区)
何时不使用
- 广泛的应用:应用范围是一般性的,不需要专业知识。
- 数据有限:微调需要大量相关数据。但是,始终可以使用另一个 LLM 生成它们。例如,今年早些时候,使用包含 52k LLM 生成的指令响应对的Alpaca 数据集创建了第一个微调Llama v1模型。
微调LLM
可以找到大量致力于模型微调的文章。仅在 Medium 上就有数千个。因此,不想太深入地研究这个主题,而是展示一个高级库Lit-GPT,它隐藏了所有的魔力。是的,它不允许对训练过程进行太多定制,但可以快速进行实验并获得初步结果。只需要几行代码:
# 1. Download the model:
python scripts/download.py --repo_id meta-llama/Llama-2-7b
# 2. Convert the checkpoint to the lit-gpt format:
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/llama
# 3. Generate an instruction tuning dataset:
python scripts/prepare_alpaca.py # it should be your dataset
# 4. Run the finetuning script
python finetune/lora.py \
--checkpoint_dir checkpoints/llama/
--data_dir your_data_folder/
--out_dir my_finetuned_model/
就是这样!训练过程将开始:
请注意,该过程可能需要很长时间。在单个 A100 GPU 上微调 Falcon-7B需要大约10 小时和30 GB内存。
当然,我有点过于简单化了,我们只触及了表面。实际上,微调过程要复杂得多,为了获得更好的结果,需要了解各种适配器及其参数等等。然而,即使经过如此简单的迭代,会得到一个遵循特定指示的新模型。
进一步阅读
- 使用微调的大语言模型创建自己的克隆 作者在文章中写了有关收集数据集、使用参数的文章,并提供了有关微调的有用技巧。
- 了解大型语言模型的参数高效微调 如果想了解微调概念和流行的参数高效替代方案的详细信息,这是一个很好的教程。
- 使用 LoRA 和 QLoRA 微调大语言模型:数百次实验的见解 了解 LoRA 功能的文章之一。
- OpenAI 微调 如果想以最小的工作微调 GPT-3.5。
6. 部署 LLM (工程化)
有时,如果有用于推理的计算资源和模型,数据存储资源,想直接利用训练好的开源大模型,仅仅简单地按下“部署”按钮……
幸运的是,这是相当可行的。有大量专门用于部署大型语言模型的框架。是什么让他们如此出色?
- 许多预构建的包装器和集成。
- 大量可用型号可供选择。
- 大量内部优化。
- 快速原型制作。
选择正确的框架
部署LLM应用程序的框架的选择取决于多种因素,包括模型的大小、应用程序的可扩展性要求和部署环境。目前,框架的多样性并不丰富,因此理解它们的差异应该不会太困难。下面,准备了一份备忘单,可以快速入门:
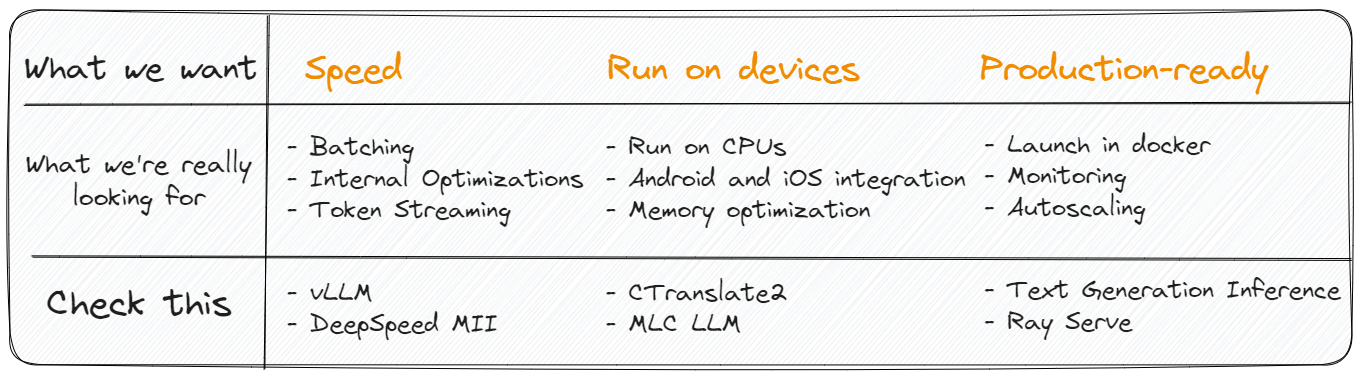
此外,在文章“为大语言模型提供服务的 7 个框架”中,对现有解决方案进行了更详细的概述。如果打算部署模型,建议检查一下。
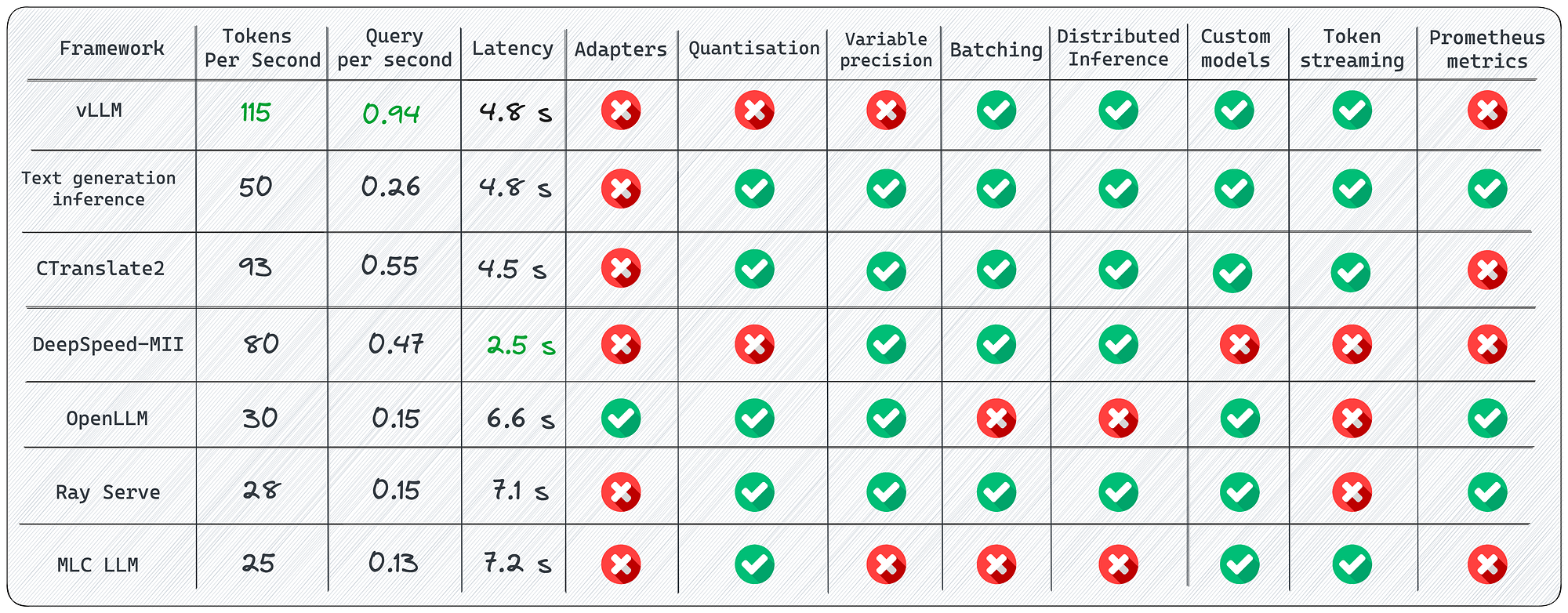
LLM 推理框架比较
部署示例代码
从理论转向实践,并尝试使用文本生成推理(Text Generation Inference)来部署 LLaMA-2 。通过运行已经打包好的模型服务镜像,demo只需要几行代码:
# 1. Create a folder where your model will be stored:
mkdir data
# 2. Run Docker container (launch RestAPI service):
docker run --gpus all --shm-size 1g -p 8080:80 \
-v $volume:/data \
ghcr.io/huggingface/text-generation-inference:1.1.0
--model-id meta-llama/Llama-2-7b
# 3. And now you can make requests:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"Tell me a joke!","parameters":{"max_new_tokens":20}}' \
-H 'Content-Type: application/json'
设置了带有内置日志记录的 RestAPI 服务、用于监控的 Prometheus 端点、令牌流,并且模型已完全优化。这不是很神奇吗?这些工程化实现方案相对成熟,移动互联网时代的工程累积。

API文档
进一步阅读
- 为大语言模型提供服务的 7 个框架 大语言模型推理和服务的综合指南,并进行了详细比较。
- Inference Endpoints HuggingFace 的一款产品,只需点击几下即可部署任何 LLM。当需要快速原型设计时,这是一个不错的选择。
7. 幕后还剩下什么
尽管我们已经介绍了开发基于 LLM 的应用程序所需的主要概念,但将来可能会遇到一些问题。所以,想留下一些有用的链接:
当启动第一个模型时,不可避免地会发现它没有想要的那么快并且消耗了大量资源。需要了解如何对其进行优化。
-
加速托管 LLM 推理的 7 种方法 加速 LLM 推理的技术,以提高令牌生成速度并减少内存消耗。
-
优化 PyTorch 中训练 LLM 的内存使用 文章提供了一系列技术,可以将 PyTorch 中的内存消耗减少约 20 倍,而不会牺牲建模性能和预测准确性。
假设有一个经过微调的模型。但怎么能确定它的质量已经提高了呢?应该使用什么指标?
- 所有关于评估大型语言模型的内容 一篇关于基准和指标的很好的概述文章。
- evals 用于评估大语言模型和大语言模型系统的最流行框架。
向量数据库
如果使用 RAG,在某些时候,将向量存储在内存中转移到数据库中。为此,了解当前市场上的产品及其局限性非常重要。
-
All You Need to Know about Vector Databases 发现并利用向量数据库的力量。
-
选择向量数据库:2023 年的比较和指南 Pinecone、Weviate、Milvus、Qdrant、Chroma、Elasticsearch 和 PGvector 数据库的比较。
注: 尽管大模型提高了输入token数量(长文本),但是对向量数据库的影响不大,特别是多模场景混合搜索的场景。
大语言模型Agents
在我看来,大语言模型最有前途的发展。如果希望多个模型协同工作,建议浏览以下链接:
-
基于 LLM 的自治agents的调查 这可能是基于 LLM 的agents最全面的概述。
-
autogen 是一个框架,允许使用多个agents来开发 LLM 应用程序,这些agents可以相互对话来解决任务。
-
OpenAgents 一个用于在使用和托管语言agents的开放平台。
存储 (补充)
注: 这块主要是聚焦用于训练模型的数据,以及训练好的模型数据,相关链接:
根据人类反馈进行强化学习 (RLHF)
一旦允许用户访问模型,如果对方反应粗鲁怎么办?或者揭示制造炸弹的成分?为了避免这种情况,请查看这些文章:
- 介绍 根据人类反馈进行强化学习(RLHF) 一篇详细介绍 RLHF 技术的概述文章。
- RL4LMs 一个模块化 RL 库,用于根据人类偏好微调语言模型。
- TRL 一组使用强化学习训练 Transformer 语言模型的工具,从监督微调步骤 (SFT)、奖励建模步骤 (RM) 到近端策略优化 (PPO) 步骤。
尽管我们都有点厌倦了炒作,但大语言模型将陪伴我们很长一段时间,并且理解他们的堆栈和编写简单应用程序的能力可以给你带来显着的提升。希望本文已经成功地让您稍微沉浸在这个领域,并向您展示它没有什么复杂或可怕的。
Reference
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK