

My scuffed game streaming adventure – PyroFling
source link: https://themaister.net/blog/2023/11/12/my-scuffed-game-streaming-adventure-pyrofling/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

My scuffed game streaming adventure – PyroFling
My side projects have a tendency to evolve from a tiny weekend experiment into something that ends up satisfying a very specific niche use case after multiple weekends of nerdsniping myself. This is one of those projects where I started experimenting with how to use external memory in Vulkan and file descriptor flinging on Linux, and it just … grew from there.
This is a wild braindump ride with some of the topics being:
- Basic Unix IPC
- Fling those file descriptors like a champ
- Writing a Vulkan layer that captures a swapchain
- Knowing how to write a layer is pretty useful for any hardcore Vulkan programmer
- A deeper understanding of how Vulkan WSI can be implemented under the hood
- Acquire elite, arcane knowledge
- Techniques for audio/video sync with low latency
- A million MPV flags will not save you
- Bespoke hacks will, however
- How to coax FFmpeg into encoding video with very low latency
- All the AVOptions, oh my!
- Using /dev/uinput to create virtual gamepads
- Tie it all together
Making a custom WSI implementation
The first part of this project was to make my own custom WSI implementation and a “server” that could act as a compositor of some sorts. The main difference was that rather than putting the swapchain on screen – which is a rabbit hole I’m not getting myself into – I just wanted to dump the results to a video file. At the end of last year, I was fiddling around with Vulkan video + FFmpeg, and this was the perfect excuse to start considering encoding as well. It would be pretty neat to get a swapchain to stay in VRAM, be encoded directly in Vulkan video and then get back H.264/H.265/AV1 packets.
Rather than redirecting WSI to a different “surface” which can get very tricky, this approach is very simple. This is implemented in a Vulkan layer where we hook the swapchain.
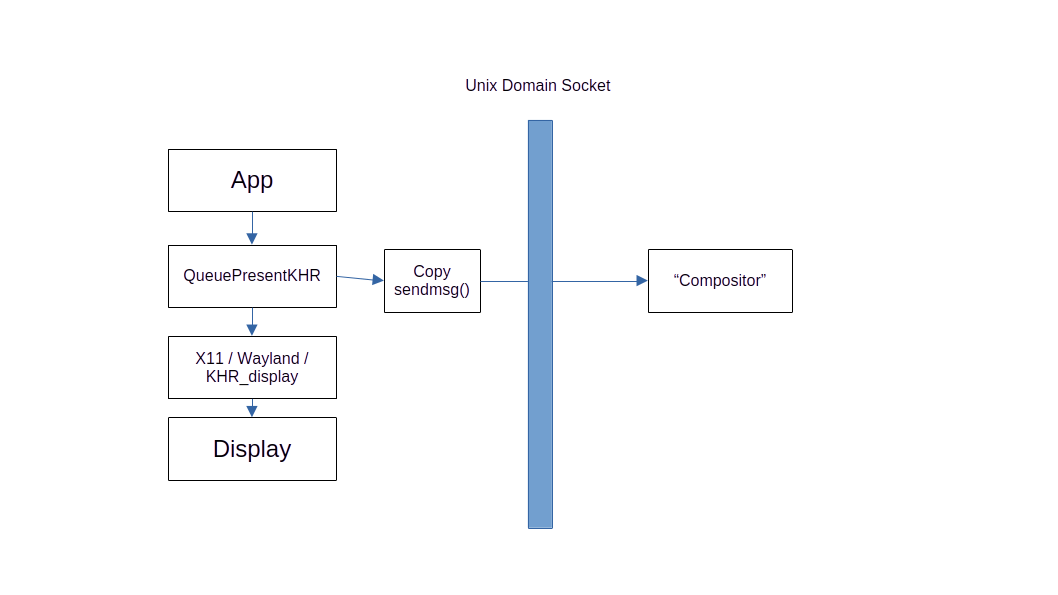
The basic gist is that we copy any presented swapchain image to an image owned by a layer, which is then sent over to the “compositor” with external memory. Synchronization is all explicit using external semaphores, because of course!
The protocol needed for a Vulkan swapchain is pretty simple. In Linux, we can use a Unix domain socket with SOCK_SEQPACKET. This is kinda like a reliable datagram that can also send and receive file descriptors as side band information.
// name is a path, e.g. /tmp/pyrofling-server
int fd = socket(AF_UNIX, SOCK_SEQPACKET, 0);
struct stat s = {};
if (stat(name, &s) >= 0)
{
if ((s.st_mode & S_IFMT) == S_IFSOCK)
{
fprintf(stderr, "Rebinding socket.\n");
unlink(name);
}
}
struct sockaddr_un addr_unix = {};
addr_unix.sun_family = AF_UNIX;
strncpy(addr_unix.sun_path, name, sizeof(addr_unix.sun_path) - 1);
bind(fd.get_native_handle(),
reinterpret_cast<const sockaddr *>(&addr_unix),
sizeof(addr_unix));
From here, clients can connect to the server using e.g. connect() and server can listen() / accept() clients, just like normal TCP. The main difference is that SEQPACKET is not stream based, so we can send individual messages instead, ala UDP, using sendmsg() rather than plain send().
msghdr msg = {};
// data
msg.msg_iov = iovs;
msg.msg_iovlen = iov_count;
if (fling_fds_count)
{
// control payload
msg.msg_control = cmsg_buf;
msg.msg_controllen = CMSG_SPACE(sizeof(int) * fling_fds_count);
struct cmsghdr *cmsg = CMSG_FIRSTHDR(&msg);
cmsg->cmsg_type = SCM_RIGHTS;
cmsg->cmsg_level = SOL_SOCKET;
cmsg->cmsg_len = CMSG_LEN(sizeof(int) * fling_fds_count);
auto *fds = reinterpret_cast<int *>(CMSG_DATA(cmsg));
for (size_t i = 0; i < fling_fds_count; i++)
fds[i] = fling_fds[i].get_native_handle();
}
ssize_t ret = sendmsg(fd.get_native_handle(), &msg, MSG_NOSIGNAL);
On the receiving end:
msghdr msg = {};
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_control = cmsg_buf;
msg.msg_controllen = sizeof(cmsg_buf);
ssize_t ret = recvmsg(fd.get_native_handle(), &msg, 0);
and then we grab the FDs. These FDs are tied to the message, so we know if this is an image, a semaphore, etc.
// Capture any FDs we receive.
std::vector<FileHandle> received_fds;
for (auto *cmsg = CMSG_FIRSTHDR(&msg); cmsg;
cmsg = CMSG_NXTHDR(&msg, cmsg))
{
if (cmsg->cmsg_level == SOL_SOCKET &&
cmsg->cmsg_type == SCM_RIGHTS &&
cmsg->cmsg_len > CMSG_LEN(0))
{
size_t data_len = cmsg->cmsg_len - CMSG_LEN(0);
size_t num_fds = data_len / sizeof(int);
auto *fds = reinterpret_cast<const int *>(CMSG_DATA(cmsg));
for (size_t i = 0; i < num_fds; i++)
received_fds.emplace_back(fds[i]);
}
}
The protocol from here is pretty simple. Most WSI implementations would be some kind of variant of this under the hood I think.
Physical device (client -> server)
To use external memory in Vulkan we must be sure that the devices are compatible. We can get compatibility information in VkPhysicalDeviceIDProperties.
struct Device
{
uint8_t device_uuid[16];
uint8_t driver_uuid[16];
uint8_t luid[8];
uint32_t luid_valid;
};
For OPAQUE_FD external types in Vulkan, these must match. There is no particular need to be fancy and use DRM modifiers here. Client sends this information over once. Each VkSurfaceKHR has one connection associated with it. In Vulkan, there can only be one active non-retired swapchain assigned to a surface, so this model works well.
Create a group of images (client -> server)
When using external memory in Vulkan, the creator and consumer of the external memory must agree on VkImageCreateInfo parameters, so we just fling that information over as-is. If this were a more normal WSI, like X or Wayland, this is where DRM modifiers becomes important, because the consumer is probably not Vulkan, but I only really care about OPAQUE_FD for my use case since I know the image is being consumed in Vulkan.
struct ImageGroup
{
// Assumptions made:
// Layers = 1
// Type = 2D
// Levels = 1
uint32_t num_images;
uint32_t width;
uint32_t height;
// VkSurfaceFormatKHR
// Assume that server can deal with anything reasonable.
// We don't have to actually flip on display.
uint32_t vk_format;
uint32_t vk_color_space; // sRGB or HDR10? :3
uint32_t vk_image_usage;
uint32_t vk_image_flags;
uint32_t vk_external_memory_type; // OPAQUE or DRM modifier.
uint32_t vk_num_view_formats;
uint32_t vk_view_formats[15]; // If MUTABLE and vk_num_formats != 0.
uint64_t drm_modifier; // Unused atm.
};
Along with this message, num_image FDs are expected. The server will then import the memory, create images and bind.
If the server’s Vulkan device differs from the client, we can round-trip through system memory with VK_EXT_external_host_memory. Two separate GPUs can import the same system memory. This is very useful to me since I have two GPUs installed and being able to render on one GPU and encode on another GPU is pretty nifty. Can also be very nice to let iGPU do hardware accelerated encode down the line.
Present (client -> server)
struct PresentImage
{
// Serial from image group.
uint64_t image_group_serial;
// If period > 0, FIFO semantics.
// If period == 0, MAILBOX semantics.
uint16_t period;
// Must be [0, VulkanImageGroup::num_images).
uint16_t index;
// OPAQUE or something special. Binary semaphores only.
uint32_t vk_external_semaphore_type;
// Represents the release barrier that client performs.
uint32_t vk_old_layout;
uint32_t vk_new_layout;
// An ID which is passed back in FrameComplete.
uint64_t id;
};
One binary semaphore is expected as FD here. Explicit sync, yay. I could of course have used timeline semaphores here, but I really didn’t need anything more fancy than binary semaphores and Vulkan WSI requires binary semaphores anyway. If I ever want to port this to Windows, I’ll run into the problem that AMD does not support external timeline OPAQUE_WIN32, so … there’s that 
The client needs to perform an image barrier to VK_QUEUE_FAMILY_EXTERNAL. The server side completes the transition with an acquire barrier from EXTERNAL into whatever queue family it uses.
The present ID is used later so we can implement KHR_present_wait properly.
Acquire (server -> client)
struct AcquireImage
{
// Serial from image group.
uint64_t image_group_serial;
// Must be [0, VulkanImageGroup::num_images).
uint32_t index;
// OPAQUE or something special. Binary semaphores only.
// If type is 0, it is an eventfd handle on host timeline.
uint32_t vk_external_semaphore_type;
};
Acquire is async as intended. Typically, the server side does RGB -> YUV conversion and once that “blit” is done, we can release the image to client as long as there are new pending presents that are done.
Fortunately, we don’t have to hook vkAcquireNextImageKHR in this implementation since we’re still rendering to the display as normal. In QueuePresentKHR, we’ll do:
- Wait for QueuePresentKHR semaphores
- Acquire image from server (in the common case, this never blocks)
- Queue wait for our acquire semaphore
- Copy WSI image to internal image (transition image layouts as necessary)
- Resignal QueuePresentKHR semaphores + signal external OPAQUE_FD semaphore
- Send present message to server
- Call QueuePresentKHR as normal
However, if we were redirecting the WSI completely, implementing the semaphore and fence parameters in vkAcquireNextImageKHR is actually quite awkward since there is no host vkSignalSemaphore and vkSignalFence in Vulkan sadly. Some bonus tips how to do it properly for the curious:
acquire has temporary import semantics
The semaphore you give to vkAcquireNextImageKHR isn’t really signaled as you’d expect, rather, it has temporary import semantics with a magic payload, i.e. the semaphore is replaced with a temporary payload of unknown type. When you subsequently wait on that semaphore, the temporary payload is consumed and freed and the semaphore is reverted to its original state. This is very useful, since we should implement AcquireNextImageKHR with vkImportSemaphoreFd and vkImportFenceFd.
From spec:
Passing a semaphore to vkAcquireNextImageKHR is equivalent to temporarily importing a semaphore payload to that semaphore.
NOTE:Because the exportable handle types of an imported semaphore correspond to its current imported payload, and vkAcquireNextImageKHR behaves the same as a temporary import operation for which the source semaphore is opaque to the application, applications have no way of determining whether any external handle types can be exported from a semaphore in this state. Therefore, applications must not attempt to export external handles from semaphores using a temporarily imported payload from vkAcquireNextImageKHR.
As long as we can import a payload, we can do whatever we want, neat!
Async acquire (easy)
This is trivial, just import the binary semaphore we got from AcquireImage message.
sync acquire
If the server gives us back a CPU-side eventfd or something similar, this is more awkward. On Linux, we can import SYNC_FD with fd -1. This means it’s already signaled, and it’s a way to signal a binary semaphore from CPU. However, not all implementations support SYNC_FD, although I believe the last holdout (NVIDIA) added support for it in a recent beta, so maybe relying on SYNC_FD on Linux is feasible soon.
If that isn’t available we have to go into really nasty hackery, having a pool of already signaled binary OPAQUE_FD semaphores for example. On present, we can signal a new payload on the side, place that in our “pool” of binary semaphores that we can import into an acquire later. Supremely scuffed, but hey, gotta do what you gotta do.
Retire (server -> client)
I don’t think it was a good idea in the end, but I tried splitting the acquire process in two. The basic idea was that I could aggressively signal acquire early, letting the CPU start recording commands, but before you’d actually submit rendering, you’d have to block until the retire event came through. Alternatively, you could wait for acquire + retire events to come through before considering an acquire complete.
In practice, this ended up being a vestigial feature and I should probably just get rid of it. It maps rather poorly to Vulkan WSI.
Completion (server -> client)
struct FrameComplete
{
// Serial from image group.
uint64_t image_group_serial;
// All processing for timestamp is committed and submitted.
// Will increase by 1 for every refresh cycle of the server.
// There may be gaps in the reported timestamp.
uint64_t timestamp;
// The current period for frame latches.
// A new frame complete event is expected after period_ns.
uint64_t period_ns;
// When an image is consumed for the first time,
// it is considered complete.
uint64_t presented_id;
FrameCompleteFlags flags;
// Number of refresh cycles that frame complete
// was delayed compared to its target timestamp.
// If this is consistently not zero, the client is too slow.
uint32_t delayed_count;
uint64_t headroom_ns;
};
This event represents a “vblank” event. A completion event is fired when an image was done rendering and was consumed by a “vblank” (i.e. encoding) event.
This can be used to implement KHR_present_wait, proper frame pacing, latency control, etc. I didn’t implement all of the fields here fully, but when you control the protocol you can do whatever you want 
Overall, this protocol ended up looking vaguely similar to X11 DRI3 Present protocol with the improvement of being explicit sync, async acquire by default, and a better FIFO queue model that does not require insane hackery to accomplish. Implementing FIFO well on X11 is actually a nightmare requiring worker threads juggling scissors to ensure forward progress. Don’t look at wsi_common_x11.c in Mesa if you value your sanity, just saying.
Frame pacing
A common concern I have with typical screen recording software is that the video output is not well-paced at all. If I record at 60 fps and I’m playing at 144 fps, there’s no way the output will be well paced if it’s just doing the equivalent of taking a snapshot every 16.6 ms. To fix this, I added some modes to optimize for various use cases:
Prefer server sync
The client becomes locked to the server refresh rate. Frame limiting happens either in QueuePresentKHR or WaitForPresentKHR. If the application is using presentIds, we can just redirect WaitForPresentKHR to wait for completion events from our server, instead of the actual swapchain. If it does not use present_wait, we can fall back to frame limiting in QueuePresentKHR. (Frame limiting in AcquireNextImageKHR is broken since you can acquire multiple images in Vulkan and may happen at arbitrary times).
Depending on the use case it can be useful to force MAILBOX present mode on the swapchain to avoid a scenario where we’re blocking on two separate clocks at the same time. If I’m playing on a 144 Hz VRR monitor while being frame limited to 60 fps, that’s not a problem, but recording at 60 fps with a 60 Hz monitor could be a problem. If frame pacing of recording is more important than frame pacing of local monitor, the swapchain that goes on screen should have MAILBOX or IMMEDIATE.
Prefer client sync
Client renders unlocked and server will use whatever latest ready image is. Basically MAILBOX.
Adaptive
Choose between above modes depending if application is using FIFO or non-FIFO presentation modes.
Server side swapchain implementation
Since we’re not tied to a particular display, we can pretend that every N milliseconds, we’re woken up to encode a video frame. At this point, we pick the last ready image whose requested earliest present time has not been reached, simple enough.
We can implement present interval quite neatly as well. When a present request is received, we compute the earliest timestamp we should present based on existing images in the queue.
The timestamp_completed here is in number of frames.
uint64_t compute_next_target_timestamp() const
{
uint64_t ts = 0;
for (auto &img : images)
{
if (img.state != State::ClientOwned)
{
uint64_t target_ts = img.target_timestamp + img.target_period;
if (target_ts > ts)
ts = target_ts;
}
}
// If there are no pending presentations in flight,
// lock-in for the next cycle.
// Move any target forward to next pending timestamp.
uint64_t next_ts = timestamp_completed + 1;
if (ts < next_ts)
ts = next_ts;
return ts;
}
This is pretty simple and handles any presentation interval. If the period is 0, we can have multiple presentations in flight where they all have target_ts being equal. In that case we use the largest presentation ID to make sure we’re picking the last image.
Now the image is queued, but it is still in-flight on GPU. Now we kick off a background task which waits for the presentation to complete. At that point we transition the state from Queued to Ready.
Once an image becomes Ready, we can retire old images since we know that they will never be used again as an encode source. If this were a normal fullscreen FLIP-style swapchain, we’d have to careful not to signal acquire semaphores until the newly Ready image was actually flipped on screen. We’re doing a BLIT-style swapchain due to our encoding however, so we can retire right away.
bool retire_obsolete_images(uint64_t current_present_id)
{
for (size_t i = 0, n = images.size(); i < n; i++)
{
auto &img = images[i];
if ((img.state == State::PresentReady ||
img.state == State::PresentComplete) &&
img.present_id < current_present_id)
{
img.state = State::ClientOwned;
if (!send_acquire_and_retire_with_semaphores(i))
return false;
}
}
return true;
}
At vblank time, we’ll pick the appropriate image to encode.
int get_target_image_index_for_timestamp(uint64_t ts)
{
int target_index = -1;
for (size_t i = 0, n = images.size(); i < n; i++)
{
auto &img = images[i];
if (img.state != State::PresentReady &&
img.state != State::PresentComplete)
continue;
if (img.target_timestamp > ts)
continue;
// Among candidates, pick the one with largest present ID.
if (target_index < 0 ||
img.present_id > images[target_index].present_id)
target_index = int(i);
}
return target_index;
}
If this image is in the Ready state, this is the time to transition it to Complete and send a complete event.
There are some quirks compared to a normal FIFO swapchain however. If the server is being very slow to encode, it’s possible that it misses its own vblank intervals. In this case, we might end up “skipping” ahead in the FIFO queue. E.g. an application might have queued up images to be encoded at frame 1000, 1001 and 1002, but server might end up doing 1000, drop, 1002 where frame 1001 is just skipped. This is technically out of spec for Vulkan FIFO, but I don’t care 
I considered keeping up the pace more important rather than slowing down the client progress just because the encoder was too slow for a split second.
From here, video and audio can be encoded fairly straight forward with FFmpeg.
For video:
- Async compute shader that rescales and converts RGB to YUV420
- Ideally, we’d pass that on to Vulkan video encode directly, but for now, just read back YUV image to system memory
- Copy into an AVFrame
- If using hwaccel, av_hwframe_transfer (so many copies …)
- Send AVFrame to codec
- Get AVPacket out
- Send to muxer (e.g. MKV)
For audio:
- Create a recording stream
- Either monitor the soundcard output as an input device
- … or use pipewire patch bay to record specific audio streams
- Automating this process would be cool, but … eh
After all this, I felt the side project had kind of come to an end for the time being. I removed some old cobwebs in the IPC parts of my brain and got a deeper understanding of WSI on Linux and got basic hwaccel encoding working with NVENC and VAAPI, mission complete.
Now I could do:
// Client. use explicit_environment in layer JSON to make it opt-in. // We all know how broken implicit layers that hook WSI by default can be, // don't we, RTSS :') $ PYROFLING=1 ./some/vulkan/app // Server ./pyrofling /tmp/dump.mkv --encoder blah --bitrate blah ...
The pyrofling layer automatically connects to the server if it’s spawned after game starts, and you can restart the server and it reconnects seamlessly. Neat!
The plan at this point was to wait until Vulkan video encode matured and then hook up the encode path properly, but … things happened, as they usually do.
Scratching an itch – playing a single-player game together over the web
Replaying a classic game with friends and family during the holidays tends to be quite enjoyable, and at some point we ended up trying to recreate the experience remotely. The ideal situation was that one of us would host the game and play it while the other would watch the stream and we could banter.
The first attempt was to do this over Discord screen sharing, but the experience here was abysmal. Horrible video quality, stutter, performance, and no good solution for piping through high quality game audio. This testing included Windows. Maybe there’s a way, but I couldn’t find it. I don’t think Discord is designed for this use case.
Bad frame pacing completely breaks immersion, simply unacceptable.
At this point, I figured OBS might be a solution. Just stream to Twitch or something and people could watch that stream while talking over Discord.
While this “worked” in the sense that video was smooth and audio quality good, there were some major drawbacks:
- Twitch’s idea of “low latency” mode is misleading at best. Expect between 1 and 2 seconds of delay, and as much as 3 in some cases. This was completely useless in practice. It might be barely okay for a streamer watching comments and interacting with an audience. When communicating with “the audience” over voice, and hearing reactions delayed by seconds, it was unusable.
- Horrible video quality. Twitch caps you to about 6 mbit/s + 8-bit H.264 which has very questionable video quality for game content even with a competent encoder. (Popular streamers get more bandwidth, or so I hear.) This basically forced me into 720p. Surely we can do better than this in 2023 …
- OBS did not like my multi-GPU setup on Linux and trying to hardware encode on top of that was … not fun
At this point, I wanted to test if OBS was adding more buffering than expected, so I dusted off pyrofling, added an option to mux to RTMP / FLV which Twitch expects, and that’s about all you need to stream to Twitch, really. It worked just fine, but latency did not improve.
Targeting decent latency – 100-200 ms range
For just watching a stream and talking / commenting alongside it, I needed to find a way to get it down to about 100-200 ms, which is the middle ground of latency. I figured most of the delay was due to buffering on Twitch’s end, so I wondered if it’d be possible to host something similar locally. I’d only need to serve one client after all, so bandwidth was not a concern.
This venture quickly failed. The closest I found was https://github.com/ossrs/srs, but I couldn’t get it to work reliably and I couldn’t be arsed to troubleshoot some random Github project.
Hacking PyroFling encoder – MPEG-TS over TCP
The first idea I came up with was to use MPEG-TS as a muxer, add an IO callback, so that instead of writing the MPEG-TS to file I’d beam the data over a socket to any TCP client that connected. FFmpeg can do something similar for you by using “tcp://local-ip:port?listen=1” as the output path, but this is blocking and not practical to use with the FFmpeg API in a multiplexed server.
Video players like MPV and VLC can easily open a raw stream over TCP with e.g. tcp://ip:port. It’ll figure out the stream is MPEG-TS and start playing it just fine.
This actually worked! But again, I ran into issues.
Even in low-latency / no-buffer modes in MPV / VLC, the latency was questionable at best. At the start of the stream, I could observe usable levels of latency, but there seemed to be no internal system to keep latency levels stable over time, especially when audio was also part of the stream. The buffer sizes would randomly grow and eventually I’d sit at over half a second latency. I spent some time searching for random comments from people having the same problems and trying a million different CLI commands that “supposedly” fix the problem, but none of them satisfied me.
At this point, I was too deep in, so … Time to write a no-frills custom video player designed for stable low latency streaming.
Presentation Time Stamp – PTS
FFmpeg and most/all container formats have a concept of a PTS, when to display a video frame or play back audio. This is used to guide A/V synchronization.
Off-line media scenario – sync-on-audio
I already had this path implemented in Granite. Audio playback is continuous, and we can constantly measure the playback cursor of the audio. If we’re a typical media player with a long latency audio buffer to eliminate any chance of audio hick-ups, we take the audio buffer latency into account as well, so at any instantaneous time point, we can estimate current audio PTS as:
estimated_pts = pts_of_current_audio_packet +
frame_offset_in_audio_packet / sample_rate -
audio_latency
This raw form of PTS cannot be used as is, since it’s too noisy. Audio is processed in chunks of about 10 ms in most cases, so the estimate will be erratic.
The solution is to smooth this out. We expect the audio PTS to increase linearly with time (duh), so the way I went about it was to fuse wall clock with audio PTS to stay in sync and avoid drift.
// elapsed_time is current wall time
// yes, I use double for time here, sue me.
// Unsmoothed PTS.
double pts = get_estimated_audio_playback_timestamp_raw();
if (pts == 0.0 || smooth_elapsed == 0.0)
{
// Latch the PTS.
smooth_elapsed = elapsed_time;
smooth_pts = pts;
}
else
{
// Smooth out the reported PTS.
// The reported PTS should be tied to the host timer,
// but we need to gradually adjust the timer based on the
// reported audio PTS to be accurate over time.
// This is the value we should get in principle if everything
// is steady.
smooth_pts += elapsed_time - smooth_elapsed;
smooth_elapsed = elapsed_time;
// Basically TAA history accumulation + rejection :D
if (muglm::abs(smooth_pts - pts) > 0.25)
{
// Massive spike somewhere, cannot smooth.
// Reset the PTS.
smooth_elapsed = elapsed_time;
smooth_pts = pts;
}
else
{
// Bias slightly towards the true estimated PTS.
// Arbitrary scaling factor.
smooth_pts += 0.005 * (pts - smooth_pts);
}
}
Now that we have a smooth estimate of PTS, video sync is implemented by simply displaying the frame that has the PTS closest to our estimate. If you have the luxury of present timing, you could queue up a present at some future time where you know audio PTS will match for perfect sync. In my experience you can be off by about 40 ms (don’t quote me on that) before you start noticing something’s off for non-interactive content.
Fixed video latency – sync-on-video
While sync-on-audio is great for normal video content, it is kinda iffy for latency. At no point in the algorithm above did we consider video latency, and that is kinda the point here. Video latency is the more important target. Correct audio sync becomes less important when chasing low latency I think.
In a real-time decoding scenario, we’re going to be continuously receiving packets, and we have to decode them as soon as they are sent over the wire. This means that at any point, we can query what the last decoded video PTS is.
Based on that, we can set our ideal target video PTS as:
target_video_pts = last_decoded_video_pts - target_latency
Again, this estimate will be very noisy, so we smooth it out as before using wall time as the fused timer:
double target_pts = get_last_video_buffering_pts() - target_latency;
if (target_pts < 0.0)
target_pts = 0.0;
smooth_pts += elapsed_time - smooth_elapsed;
smooth_elapsed = elapsed_time;
if (muglm::abs(smooth_pts - target_pts) > 0.25)
{
smooth_elapsed = elapsed_time;
smooth_pts = target_pts;
}
else
{
smooth_pts += 0.002 * (target_pts - smooth_pts);
}
Now we have another problem. What to do about audio? Frame skipping or frame duplication is not possible with audio, even a single sample of gap in the audio has disastrous results.
The solution is to dynamically speed audio up and down very slightly in order to tune ourselves to the correct latency target. The idea is basically to sample our estimated audio PTS regularly and adjust the resampling ratio.
latch_estimated_audio_playback_timestamp(smooth_pts);
auto delta = smooth_pts - get_estimated_audio_playback_timestamp_raw();
// Positive value, speed up. Negative value, slow down. delta = clamp(delta, -0.1, 0.1); // This is inaudible in practice. // Practical distortion will be much lower than outer limits. // And should be less than 1 cent on average. stream->set_rate_factor(1.0 + delta * 0.05);
This of course requires you to have a high quality audio resampler that can do dynamic adjustment of resampling ratio, which I wrote myself way back in the day for retro emulation purposes. While this technically distorts the audio a bit by altering the pitch, this level of funging is inaudible. 1 cent of a semitone (about 0.05%) is nothing.
I believe this is also how MPV’s sync-on-video works. It’s a useful technique for displaying buttery smooth 60 fps video on a 60 Hz monitor.
Success! Kinda …
By targeting a reasonably low latency in the new player, we were able to get an acceptable stream going over the internet. We did some basic comparisons and Discord voice came through at the same time as the video feed according to my testers, so mission accomplished I guess!
The main drawback now was stream robustness. TCP for live streaming is not a great idea. The second there are hick-ups in the network, the stream collapses for a hot minute since TCP does not accept any loss. When we were all on ethernet instead of Wi-Fi, the experience was generally fine due to near-zero packet loss rates, but right away, a new use case arose:
Wouldn’t it be really cool if we could switch who controls the game?
This is basically the idea of Steam Remote Play Together, which we have used in the past, but it is not really an option for us based on past experience:
- Latency too high
- Video quality not great
- Only supported by specific games
- And usually only multi-player co-op games
- Won’t help us playing non-Steam stuff
At this point I knew I had work cut out for me. Latency had to drop by an order of magnitude to make it acceptable for interactive use.
Chasing low latency
The first step in the process was to investigate the actual latency by the encoder and decoder chains, and the results were … kinda depressing.

On the right, my test app was running, while the left was the video feedback over localhost on the same display. The video player was hacked to always present the last available image. 100 ms latency, yikes …
I eventually narrowed part of this down to MPEG-TS muxer in FFmpeg adding a lot of latency, over 50 ms just on its own. It was pretty clear I had to get rid of MPEG-TS somehow. Around this point I started to investigate RTP, but I quickly rejected it.
RTP does not support multiple streams. It cannot mux audio and video, which is mildly baffling. Apparently you’re supposed to use two completely different RTP streams on different ports. Some kind of external protocol is used to provide this as side band information, and when trying to play an RTP stream in FFmpeg you get hit with:
[rtp @ 0x55b3245fd780] Unable to receive RTP payload type 96 without an SDP file describing it
Apparently this is https://en.wikipedia.org/wiki/Session_Description_Protocol, and the whole affair was so cursed I just rejected the entire idea, and rolled my own protocol. I just need to bang over some UDP packets with some sequence counters, payloads and metadata after all, how hard can it be, right?
Turns out it wasn’t hard at all. The rest of the latency issues were removed by:
- Disabling frame queue in NVENC
- Disabling encoding FIFO in server
- Just encode as soon as possible and blast the packet over UDP
- Pacing be damned
- We’ll solve frame pacing later
- Remove B-frames and look-aheads
- Well, duh :p
- “zerolatency” tune in libx264
For example, here’s some options for NVENC.
// This is critical !!! av_dict_set_int(&opts, "delay", 0, 0); av_dict_set_int(&opts, "zerolatency", 1, 0); av_dict_set(&opts, "rc", "cbr", 0); av_dict_set(&opts, "preset", "p1", 0); av_dict_set(&opts, "tune", "ll", 0); // There's an ull for ultra-low latency, // but video quality seemed to completely die // with no obvious difference in latency.
Some local results with all this hackery in libx264.


On my 144 Hz monitor I could sometimes hit a scenario where the video stream and application hit the same vblank interval, which means we just achieved < 7 ms latency, very nice!
NVENC also hits this target, but more consistently, here with HEVC encode.



AMD with VAAPI HEVC on RX 6800 isn’t quite as snappy though … Hoping Vulkan encode can help here. There might be some weird buffering going on in the VAAPI backends that I have no control over, but still. We’re still in the ~10 ms ballpark. I had better results with AV1 encode on my RX 7600, but I couldn’t be arsed to swap out GPUs just to get some screenshots.



Of course, we’re working with the most trivial video footage possible. The true test is real games where I expect encode/decode latency to be more obvious.
Intra-refresh – the magic trick
When doing very low-latency streaming like this, the traditional GOP structure completely breaks down. Intra frames (or I-frames) are encoded as still images and tend to be fairly large. P- and B-frames on the other hand consume far fewer bits. Low latency streaming also requires a lot more bitrate than normal high-latency encoding since we’re making life very difficult for the poor encoder.
In a constant bit-rate world where we’re streaming over a link with limited bandwidth, the common solution to this bitrate fluctuation is to just buffer. It’s okay if an I-frame takes 100ms+ to transmit as long as the decode buffer is large enough to absorb the bandwidth difference, but we cannot rely on this for low latency streaming.
Here’s a link to the 2010 post by x264 legend Dark Shikari. The solution is intra-refresh where parts of the image is continuously refreshed with I-blocks. Effectively, we have no GOP structure anymore at this point. This allows us to avoid the huge spikes in bandwidth.
libx264 and NVENC support this, but sadly, VAAPI implementations do not Hoping we can get this working in Vulkan video encode somehow …
av_dict_set_int(&opts, "intra-refresh", 1, 0); av_dict_set_int(&opts, "forced-idr", 1, 0); video.av_ctx->refs = 1; // Otherwise libx264 gets grumpy.
The forced-idr option is used so that we can still force normal I-frames at will. Clients can request “pure” I-frames when connecting to the server to kick-start the decode process. Technically, with intra-refresh you can just keep decoding until the image has been fully refreshed at least once, but I had various issues with FFmpeg decoding errors when trying to decode raw intra-refresh without ever seeing a keyframe first, especially with HEVC, so I went with the dumb solution It worked fine.
Fixing frame pacing
When I try to just display the frames as they come in over the network, the results are … less than ideal. The pacing is completely butchered due to variability in:
- GPU time for game to render
- Encoding time (scene dependent)
- Network jitter
- Decoding time
Under ideal conditions over a local network, network jitter is mostly mitigated, but the variability in encode/decode time is still noticeable on a fixed rate display, causing constant frame drops or dupes. My solution here was to re-introduce a little bit of latency to smooth over this variability.
Step 1 – Set up a low latency swapchain on client
VK_KHR_present_wait is critical to ensure we get the lowest possible latency. On a 60 Hz monitor, we want this frame loop:
while (gaming)
{
wait_for_last_present_to_flip(); // vkWaitForPresentKHR(id);
// 16.6ms until next flip.
wait_for_next_video_frame_in_decode_queue(timeout = N ms);
// Should just take a few microseconds on GPU.
yuv_to_rgb_render_pass();
// Ideally the GPU is done just before the deadline of compositor.
present(++id);
}
Just in case we barely miss deadline due to shenanigans, FIFO_RELAXED is useful as well.
step 2 – send feedback to server
This is fairly magical and I don’t think any generic “screen capturing” software can and will do this. The idea is that there is an ideal time target when new video frames should be done. If they arrive too early, we can ask the game to slow down slightly, and if it arrives too late, speed up a bit.
Basically, this is a phase locked loop over the network. One nice property of this is that we don’t really need to know the network latency at all, it’s self stabilizing.
while (gaming)
{
wait_for_last_present_to_flip(); // vkWaitForPresentKHR(id);
// 16.6ms until next flip.
auto phase = get_current_time();
if (wait_for_next_video_frame_in_decode_queue(deadline))
{
auto arrive_time = video_frame.decode_done_time;
// If 0, the packet arrived in sync with WaitForPresentKHR.
// If negative, it was completed before we waited for it.
auto phase_offset = arrive_time - phase;
phase_offset -= target_phase_offset;
// Continuously notify server by feedback.
client.send_phase_offset(phase_offset);
}
else
{
// Could be used to adapt the target_phase_offset maybe?
missed_frames++;
}
// ... render
}
Since the server controls when to send Complete events to the game running, we have full control over whether to render at 60.0 FPS, 60.01 FPS or 59.99 FPS. Tiny adjustments like these is enough to keep the system stable over time. It can also handle scenarios where the refresh rates are a bit more off, for example 59.95 Hz.
Of course, large network spikes, lost packets or just good old game stutter breaks the smooth video, but it will recover nicely. With target_phase_offset = -8ms and deadline of 8ms, I have a very enjoyable gaming experience with smooth frame pacing and low latency over local network.
Step 3 – Adjust audio buffering algorithm
At this point, we don’t really care about A/V sync by PTS. The assumption is that audio and video packets arrive together with very similar PTS values. Rather than trying to target a specific PTS, we just want to ensure there is a consistent amount of audio buffering to safely avoid underrun while keeping latency minimal. This strategy is good enough in practice.
double current_time = get_audio_buffering_duration(); double delta = current_time - target_buffer_time; // 30ms is good tradeoff set_audio_delta_rate_factor(delta);
Adding a virtual gamepad
As cherry on top, we just need to let the client send gamepad events. Using /dev/uinput on Linux, it’s very simple to create a virtual gamepad that Steam can pick up and it “just werks” in all games I tested. It works fine in other programs too of course. It’s trivial to hook this up.

Cranking the quality
For game content in darker regions, I noticed that 10-bit HEVC looked dramatically better than 8-bit, so I went with that. >30mbit/s 10-bit streams with HEVC or AV1 looks basically flawless to me on a TV even with really difficult game content that tends to obliterate most streams. Good luck getting game streaming services to provide that any time soon!
Putting it all together

Remaining problems
The main problem left is that packet loss recovery isn’t really there. I’m not sure if FFmpeg has facilities to recover gracefully from dropped packets other than freaking out about missing reference frames in the logs, and this is a bit outside my wheelhouse. Intra refresh does a decent job of quickly recovering however.
I have some hopes that using Vulkan video decode directly will allow me to fake the presence of missed reference frames to mask most of the remaining issues, but that’s a lot of work for questionable gain.
Audio is a bit more YOLO, I just ignore it. That seems to be the general strategy of VoIP anyways.
There’s also zero security / encryption. I don’t really care.
Sadly, I haven’t had much luck getting the work in progress Vulkan encode work to run yet. Hooking up a fully Vulkan encode -> decode chain will be nice when that matures. The decode path is already working.
Conclusion
If you actually made it this far, congratulations. I mostly aimed to make this post a braindump of the techniques I went through to make this and I achieved what I set out to do, useful low-latency game streaming tailored exactly for my needs.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK