

调协大模型时代存算矛盾的HBM,如何入局其中寻找机会?
source link: https://www.qianzhan.com/analyst/detail/329/231220-6a4b8077.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

调协大模型时代存算矛盾的HBM,如何入局其中寻找机会?
作者|叶子 来源|奇偶派(ID:jioupai)
近日,HBM的热度不可谓不高,无论是相关半导体大厂“激进”扩产的计划,还是产品供不应求的消息,都将这个内存领域的“新”技术,推到了资本市场与相关投资者的眼前。
在相关大厂的扩产方面,两大存储芯片巨头持续加码:三星、SK海力士拟将HBM产量提高至2.5倍的消息曝出,使得HBM概念股倍受市场关注。
据媒体报道,三星显示(Samsung Display)在天安厂区内部分建筑及设备进行扩产,计划在天安厂建立一条新封装线,用于大规模生产HBM。公司已花费105亿韩元购买上述建筑和设备等,预计追加投资7000亿-1万亿韩元。
而早在今年6月,SK海力士就已经被报道出正在着手扩建HBM产线,目标将HBM产能翻倍。扩产焦点在于HBM3,SK海力士正在准备投资后段工艺设备,将扩建封装HBM3的利川工厂。预计到今年年末,后段工艺设备规模将增加近一倍,相关投资也在1万亿韩元左右。
能让三星、SK海力士抛出如此大手笔的扩产计划,自然是下游客户极为旺盛的需求,在10月末的财报会议上,SK海力士已透露,2024年的HBM3与HBM3E产能已全部售罄,正在与客户、合作伙伴讨论2025年HBM产量与供应。而后又有报道指出,不仅是2024年的产能,SK海力士HBM 2025年的预期产能也出现了完全售罄的迹象。
而这一切的“爆点”,都是由于NVIDIA H200的发布。11月13日,相比于H100,英伟达今日发布了下一代人工智能超级计算机芯片H200,作为英伟达最新一代产品,H200首次搭载HBM3e,在GPU架构无调整的情况下,完成了1.4倍内存带宽和1.8倍内存容量的提升,能以每秒4.8 TB的速度提供 141GB 的内存,顺利让推理速度达到了H100的两倍。

在摩尔定律放缓、GPU核心利用率不足的背景下,英伟达针对存储端的改进让行业再一次认识到了存力的重要性,而在当前这轮市场与产业的热潮追捧叙事中,HBM或许能成为那个破局的关键技术。
那么,为什么内存有着如此的重要性?HBM究竟是怎样的存力技术?从投资者的角度来看,相关受益行业又有哪些?
HBM
能补上AI算力的阿喀琉斯之踵?
在市场的刻板印象中,算力的大小是决定AI大模型产出速度的决定性因素,这样的观点固然有部分正确但并不严谨,与现实有着很大的出入,因为在简单的算力指标之外,还有许许多多其他影响产出速度的因素。
我们当代电子计算体系的最终表现,依赖于处理器与内存之间的“孰低值”,其个中原因也十分易于理解——当运算速度跟不上数据运输速度之时,便会在处理器处形成数据的“堰塞湖”,反之也亦然,也就意味着存力与算力的重要性等级是相同的。
根据冯诺伊曼的设想,两者之间的速度应该非常接近,但摩尔定律的出现,却让这一理想的设想落了空——代表着算力的处理器性能按照摩尔定律规划的路线不断飙升,而存力领域内所使用的DRAM却从工艺演进中获益很少,性能提升速度远慢于处理器速度。
从具体数据来看,据EEPW预计,处理器的峰值算力每两年增长3.1倍,DRAM的带宽每两年增长1.4倍,相差1.7倍,这样巨大的增长速度之间的差值,让存储器的性能远远落后于了处理器,导致数据写入与读出的时间成为处理器运算所消耗时间的几十倍或几百倍,数据交换通路窄以及其引发的高能耗,导致DRAM的性能成为制约计算机性能的一个重要瓶颈,即所谓的“内存墙”。

如果说“内存墙”的问题在过去体现得没有那么明显的话,那么AI时代的来临,让其成为了必须要攻克的关口,毕竟,面对语言大模型这种动辄便需要重复访问N次数十亿到数百亿、数千亿甚至上万亿的参数,所消耗的时间也并不是一个小数目。可以说,内存已经成为了AI算力的阿喀琉斯之踵。
于是,为满足海量数据存储以及日益增长的繁重计算要求,半导体存储器领域也迎来新的变革,HBM技术从幕后正式走向台前,而要谈起为什么HBM能受到市场与厂商们的一致青睐,则要从另一GPU主流存储方案,曾经也是AI算力选择的路线GDDR说起。
目前,GPU的主流存储方案有GDDR和HBM两种,GDDR采用的是传统的方法,将标准PCB和测试的DRAMs与SoC连接在一起,是将DRAM芯片直接放置在PCB上并围着处理器转一圈的独立封装。
如GDDR的独立封装方式有两个无法避免的缺点,一是会受到PCB面积的约束,无法完成更多DRAM芯片的封装,此外,也因与SOC之间的距离拉大,导致互联联线长/带宽以及通讯延迟的增大。
这样的差距在日常消费、商业场景的使用中是感觉不出来的,在一定程度上甚至还具有便捷性与经济性,但在AI领域中,随着图形芯片性能的日益增长,使处理器对高带宽的需求也不断增加,GDDR满足高带宽需求的能力开始减弱,且单位时间传输带宽功耗也显著增加,逐步了成为阻碍图形芯片性能的重要因素。
HBM的出现,则就是为了解决封装数量与通讯距离两个问题。针对现存带宽不足的情况,HBM选择在硅中阶层上通过TSV堆栈的方式,将DRAM裸片垂直堆叠放在一起,这样能在底面积相同的情况下布置过去数倍的DRAM颗粒,以达到更高的I/O数量,使得显存位宽达到1024位,几乎是GDDR的32x,这样的堆叠空间节约空间,还带来了更短的颗粒间距以缩短传输延迟。

在将多个DRAM裸片堆叠在一起的同时,也HBM Stack将其与GPU封装在一起,极大地缩短HBM与GPU的距离,提高了GPU与存储芯片之间传输的速度。
而至于HBM产品为何现在才“上车”,除了过去存力的问题没有那么明显之外,HBM也是近十年来才飞速发展出的一种新产品,但自2014年问世以来,相关技术已经发展至第四代,无论是带宽、堆叠高度,还是容量、I/O速率等较初代均有多倍提升,并伴随着高性能计算(HPC)、超级计算机、大型数据中心、AI、云计算等领域的发展快速占领市场,几乎成为了当前先进AI计算中必备的技术。

HBM标准迭代历史
资料来源:海力士官网,中金公司
可以这么说,HBM是目前能提供大规模存力的最好技术路线,但HBM也只是在AI加速卡领域有特定的优势,要想作为如GDDR一样普适性极强的消费级产品,还有很长的路要走。
最先制约HBM发展的,是其居高不下的成本——HBM由于其复杂的设计及封装工艺导致产能较低同时,成本也水涨船高,平均售价至少是DRAM的三倍,此前受ChatGPT的拉动同时受限产能不足,HBM的价格一路上涨,与性能最高的DRAM相比,HBM3的价格上涨了有五倍之多。
Cadence IP团队产品营销总监Marc Greenberg也表示:“目前存在的HBM脱离了消费者领域,并更牢固地放置在服务器机房或数据中心,存在许多系统成本。相比之下,GDDR6等图形内存虽然无法提供与HBM一样多的性能,但成本却显著降低,GDDR6的单位成本性能实际上比HBM好得多。”
此外,使用2.5D/3D封装的HBM结构会积聚许多热量,而DRAM与GPU封装在一起会加剧这种情况的发生,这就对散热冷却也提出了更多的挑战,迫使制造者需要在时延与散热之间做出抉择,很显然,无论哪一种选择,都将从另一角度上推高总成本。
而在成本居高不下、散热需求更多的缺陷外,HBM与主芯片出厂时便封装在了一起,不存在扩容的可能;同时,HBM的容量偏小,据ittbank报道,采用128GB RDIMM最多能达到12TB,HBM8层die也不过32GB,再结合成本考虑,更加无法满足数据中心要求。
所以从当前的进展来看,HBM在未来数年内还是只能应用于服务器、数据中心等领域,对于成本十分敏感的消费领域,对于HBM暂时还是可望而不可即的禁区。
但这些在商用领域中的缺点在火热的AI需求的对比之下显得微不足道,有媒体更是喊出了7年200倍的口号,产业链上的各个环节也正在被不断挖掘出来。
二
先进封装
成为HBM产业链核心价值增量
谈及产业链,HBM作为存力领域的技术,自然离不开上游材料端与设备端的更新支持,但在材料与设备外,作为通过2.5D与3D封装工艺实现更新迭代的技术,HBM在封测端核心工艺自然是最重要,也是价值量最高的部分。
而封测端的相关工艺,其实看过HBM的示意图后,相关的技术难点已经一目了然:如何将组成HBM各个DRAM Die之间一一串联起来,并连接至下方的逻辑控制die(Base Die),形成完整个HBM Stack;如何将HBM Stack整体封装至硅中介基板上方;是如何将CPU/GPU等逻辑芯片与HBM Stack一般,同样封装至硅中介基板上方。

HBM结构图及用到的封装工艺
图源:台积电,Wikichip,招商证券整理
简而言之,便是组装HBM Stack、将HBM Stack封装至基板、将CPU/GPU封装至基板三个步骤,而这三个步骤中,主要涉及TSV、CoWoS、FC工艺。
三者中,TSV(硅通孔)技术又是重中之重,它是通过铜、钨、多晶硅等导电物质的填充来实现硅通孔的垂直电气互联的技术,将DRAM Die完成通孔封装,其也是目前唯一的垂直电互联技术,能够以最低的能耗提供极高的带宽和密度。
据招商证券报道,如图所示,TSV与传统的SIP等封装技术相比,其垂直连接可以允许更多数量的连接,因此具备更好的电势能、更低的功耗、更宽的带宽、更高的密度、更小的外形尺寸、更轻的质量等优势,是实现电路小型化、高密度、多功能化的首选解决方案,也成为了解决出现在SOC(二维系统级芯片)技术中的信号延迟等问题的利器,可以说,HBM相较于GDDR最大的改进与优势,就是TSV的“上车”。
TSV封装

也正是因为TSV技术有如此多的优点,2.5D/3D TSV技术才被广泛用于AI GPU基板上的HBM中,也成为了HBM 3D封装中成本占比最高的工艺,根据3DinCites,考虑4层DRAM Die和1层逻辑die堆叠的HBM结构,在99.5%和99%的芯片键合(die bonding)良率下,TSV制造和TSV通孔露出工艺分别占其成本的30%和29%。
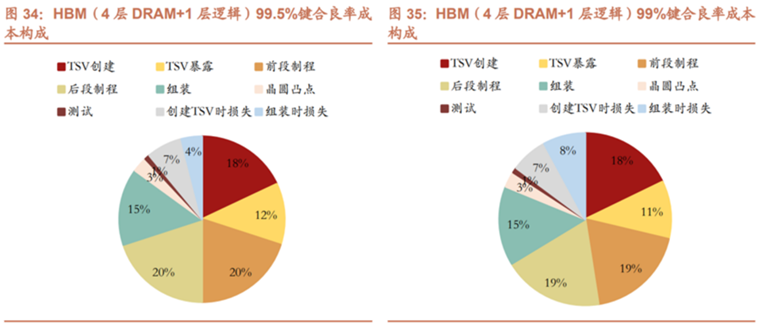
资料来源: 3DInCites、招商证券
TSV完成HBM Stack的键合后,用于AI GPU的整体封装的CoWoS,也是先进封装中必不可少的关键技术。
CoWoS技术,简单来说便是先将芯片通过Chip on Wafer(CoW)的封装制程连接至硅晶圆,再把CoW芯片与基板连接,整合成CoWoS;利用这种封装模式,使得多颗芯片可以封装到一起,透过Si Interposer互联,达到了封装体积小,功耗低,引脚少的效果。
目前,台积电的CoWoS技术全球领先,英伟达AIGPUDGXA100、H100、H200等均由其生产,而据台积电预计,目前其相关产能供应极为紧张,将于2024-2025年进行扩产,2024年CoWos产能将实现倍增。
此外,在先进封装工艺中取代引线键合,将CPU/GPU芯片封装于基板上的倒片封装(FC)也是必不可少的工艺。
在半导体行业内,现存的封装工艺无非芯片粘接、引线键合、倒装连接技术三种,而载带连接技术因为有一定的局限性,故已经被封装逐渐淘汰。

而在引线键合与倒装连接之间,倒片封装不存在如引线键合对于可进行电连接的输入/输出引脚的数量和位置限制,也不再受制于以为摆放,可全部排列于芯片的同一侧面,同时电信号传输路径更短,也就有了更加优良的性能。
于是,倒片封装(FC)也成为了HBM制造过程中的一大必备工艺。
至此,封测端的三种最重要的技术工艺便已介绍完成,而封测工艺离不开的,则是产业链上的诸多设备,并且在HBM制造过程中,除去那些较为通用的微电子设备外,大多都是为了这些先进封测增添的的设备,但却几乎全部被海外厂商所垄断。
据招商证券整理,HBM中大量增加前道工序,前道检、量测设备主要增量来自微凸点、TSV、硅中介层等工艺,另外HBM中增加的预键合晶圆级测试和KGSD相关的封装级测试也带动分选机、测试机、探针台等后道测试设备的数量和精度提升;由于HBM堆叠结构增多,要求晶圆厚度不断降低,进而提升了减薄、键合等设备需求。
此外,HBM多层堆叠结构要求超薄晶圆和铜-铜混合键合工艺,增加了临时键合/解键合以及混合键合设备需求,各层DRAM Die的保护材料也非常关键,对注塑或压塑设备提出较高要求;另外,诸如划片机、固晶机、回流焊机/回流炉等传统设备需求也均受益于HBM封装带来的工艺步骤提升和工艺变革带来的价值量提升。

而在设备之外,材料的重要性也不容小觑。其中,环氧塑封料(EMC)通过其优异的性能成为封装必需的材料。
环氧塑封料是用于半导体封装的一种热固性化学材料,具有较高的机械和电气性能、良好的着色性和优异的耐热性。作为半导体封装材料防止芯片受到冲击并耐候,覆盖电感、连接器、电源等电子元件,全球90%以上电子器件采用EMC封装。
但在先进封装中,传统EMC还远远不够,需要有更好的耐潮性、低应力、低α射线、耐浸焊和回流焊性能,同时还得保证塑封性,因此环氧塑封料必须在无机树脂基体内掺杂无机填料,市场份额被全球少数几家厂商完成了寡头垄断。
纵观封测端、设备端与材料端,我们不难看出,HBM作为代表着目前世界最尖端微电子技术融合为一推出的产品,大多环节都被国际大厂牢牢掌握在手中,那么,有哪些国产企业的产品介入了相关产业链呢?
写在最后
在封测端,HBM核心封装技术增量主要存在于TSV、CoWoS、Bumping、RDL等工艺之上,但掌握这些先进封装工艺的企业均为一体化国际大厂,如韩系厂商三星、台系厂商台积电等企业。
而其下设备端的格局也大抵相同。即便相关设备涵盖了众多制造领域,中国微电子产业企业却因技术能力所限,并没有太多的涉足。在谈及有关先进TSV工艺的设备之时,据界面新闻报道,有半导体行业资深人士表示,“国内对TSV技术虽然也研发了很多年,但其成本很高,技术难度大,应用面窄,主要应用于摄像头,国内外虽然都将此技术称为TSV,但技术难度上完全是两码事。”
“在这一技术水平上,二者不是一个量级的,国外能做3纳米芯片,而我们只能做14纳米芯片,工艺水平不足。加之国内没有企业可以做HBM这一存储器,对TSV技术自然没有需求,因此国内几乎没有企业真正投入研发TSV技术。”前述业内人士表示。
同时,对方还补充道,“更为重要的是,国内现在没有一家企业能够制造出HBM存储芯片,又怎么会去用TSV工艺呢?”
不过,虽然在封测端与设备端国内并没有出现真正的玩家,但是在材料端中,却存在许多有竞争力的企业,而华海诚科便是其中之一。
华海诚科成立于2010年,是⼀家专注于半导体封装材料的研发及产业化的国家级专精特新小巨人企业,主要产品为环氧塑封料和电子胶黏剂,也是国内少数同时布局FC底填胶与LMC的内资半导体封装材料厂商。
环氧塑封材料作为一种重要的半导体封装材料,受益于全球封装产能逐步转移至大陆,大陆塑封材料增速高于全球市场,也为公司带来了良好的发展机遇。
在传统封装领域,公司应⽤于DIP、TO、SOT、SOP等封装形式的产品已具备品质稳定、性能优良、性价⽐⾼等优势,且应⽤于SOT、SOP领域的⾼性能类环氧塑封料的产品性能已达到了外资⼚商相当⽔平,并在⻓电科技、华天科技等部分主流⼚商逐步实现了对外资⼚商产品的替代,市场份额持续增⻓。
在先进封装领域,公司研发了应⽤于QFN、BGA、FC、SiP以及FOWLP/FOPLP等封装形式的封装材料,其中应⽤于QFN的产品已实现小批量生产与销售,颗粒状环氧塑封料(GMC)以及FC底填胶等应⽤于先进封装的材料已通过客户验证,液态塑封材料(LMC)正在客户验证过程中,上述应用于先进封装的产品有望逐步实现产业化,并打破外资⼚商的垄断地位。
写在最后
HBM,作为当今最先进的内存封装技术,已经在H200性能提升的过程中证明了自己价值,而HBM的价值则主要集中于先进封装的领域,在算力需求催生存力风口的机遇下,先进封装的重要性已经不言而喻。
但纵观整个产业链,能“插手”其中的中国企业却寥寥无几,并且大多还都集中于最上游的材料端,这与被禁运的GPU加速卡形成了鲜明且刺眼的对比。
可以说,无论从国产自主角度还是市场竞争角度,唯拥有自主研发能力和技术优势方能更具竞争力,在先进微电子产业发展的浪潮中占据一席之地。
参考资料:
1.《HBM很贵,但你必须买!》,芯长征科技;
2.《GDDR6 vs DDR4 vs HBM2?为什么CPU还不用GDDR?异构内存的未来在哪里?》,老狼;
3.《HBM火了,它到底是什么?》,枫哥;
4.《存储行业深度报告:算力需求推动HBM市场数倍增长》,报告研究所;
5.《HBM技术,如何发展?》,半导体行业观察
6.《一文读懂HBM:高带宽内存吸引各大科技巨头抢购的“魔力”到底是什么?》,EEPW;
8.《新兴的DRAM解决方案HBM产业链》,ittbank;
9.《存储行业深度报告:AI服务器存储量价齐升,算力需求推动HBM市场数倍增长全屏放大》,招商证券。
编者按:本文转载自微信公众号:奇偶派(ID:jioupai),作者:叶子
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK