

【论文阅读】HTTP 流量和恶意 URL 的异常检测 - 我记得
source link: https://www.cnblogs.com/Zyecho/p/17903004.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Part 1关于论文
- 题目:HTTP 流量和恶意 URL 的异常检测
- 源码:sec2vec源代码
在本文中,我们将展示如何利用自然语言处理(NLP)中已知 的方法来检测 HTTP 请求中的异常情况和恶意 URL。目前大 多数针对类似问题的解决方案要么基于规则,要么使用人工 选择的特征进行训练。然而,现代 NLP 方法在深入理解样本 并因此改进分类结果方面具有巨大潜力。其他依赖于类似想法 的方法往往忽略了结果的可解释性,而这一点在机器学习中 非常重要。我们正试图填补这一空白。此外,我们还展示了 所提出的解决方案在多大程度上能够抵御概念漂移。在我们 的工作中,我们比较了三种不同的矢量化方法:简单 BoW、 fastText 和当前最先进的语言模型 RoBERTa。获得的向量随 后将用于分类任务。为了解释我们的结果,我们使用了 SHAP 方法。我们在四个不同的数据集上评估了我们方法的可行性 :CSIC2010, UNSW-NB15, MALICIOUSURL 和 ISCXURL2016.前两个与 HTTP 流量有关,另外两个包含恶意 URL 。我们展示的结果与其他结果不相上下,甚至更好,最重要 的是,这些结果是可解释的。
- NLP机器学习的可解释性
- 抵御概念漂移
- 比较了三种矢量化方法:简单 BoW、 fastText 和当前最先进的语言模型 RoBERTa
1. 什么是机器学习的的解释性?
关于机器学习可解释性(Interpretability),又或者是XAI(Explainable Artificial Intelligence )其实就是搞机器学习的研究者们始终存在的一个担忧:很多现在的深度神经网络没有办法以一种从人类角度完全理解模型的决策。我们知道现在的模型既可以完胜世界围棋冠军电竞冠军,图形识别语音识别接近满分,然而我们对这些预测始终抱有一丝戒备之心,就是我们因为不完全了解他们的预测依据是什么,不知道它什么时候会出现错误。这也是现在几乎所有的模型都没法部署到一些对于性能要求较高的关键领域,例如运输,医疗,法律,财经等。(引用自https://zhuanlan.zhihu.com/p/141013178)
2. 什么是概念漂移?
如果要对概念漂移下定义的话,它的定义是:概念漂移是一种现象,即目标领域的统计属性随着时间的推移以一种任意的方式变化。 下面这张图很直观:当模型学到的模式不再成立时,就会发生概念漂移。 这种变化可快可慢,比如慢一点的情况: 宏观经济条件不断变化。随着一些借款人拖欠贷款,信用风险被重新定义。计分模型需要学习它。 而突然变化的案例就是,covid-19,几乎在一夜之间,流动性和购物模式发生了转变。它影响了各种模式,甚至是原本 "稳定 "的模式。 家居服,随着政府的隔离政策颁布,开始销量猛增,口罩也是一样。 简而言之一句话,数据没有变化,但是世界变了。 (引用自:https://zhuanlan.zhihu.com/p/406281023)
解决的问题
- 目前NLP检测方法基于规则和人工特征工程进行训练
Part 2背景
当前研究进度
自然语言处理(NLP)的快速发展,已经开发 出了许多文本矢量化方法,其中既有简单的方法,如 bag-of-words、 tf-idf 或 bag-of-n-grams ;也有更先进的方法,如 Doc2Vec、 fastText、ELMo 或 BERT。其中一些已成功用于解决 HTTP 流量或恶意 URL 中的异常检测问题。
当前相关方法的优缺点
- 缺少可解释性
- 没有讨论概念漂移的问题--分类器运行的环境是不断变化的, 很难说这会如何影响其有效性。
Part 3本文主要方法
(1)我们提出了一种 HTTP 流量和恶意URL 的矢量化方法,称为 "Sec2vec"("Security to vector"), 它建立在 RoBERTa 模型的基础上。我们将其与简单的 BoW 和 fasText 方法进行了比较。我们使用随机森林( Random Forest)在下游分类任务中对这些模型进行了评估。
(2) 为了验证我们的矢量化模型(概念漂移)的通用性,我们在不同的数据集上对其进行了验证(这就是为什么我们需要 至少两个同类数据集)。
(3) 我们还展示了如何利用矢量表示 法来分析数据,并识别与所发现的异常情况相关的可解释标记模式。
对比三种方法
在我们的工作中,我们比较了下面描述的三种流行的矢量化方法。
- BoW。BoW(Bag-of-words)是一个简单的模型,它使用单词的频率(获得的向量中的每个位置对应一个单词)来表示文档,或者在我们的示例中,使用从标记化阶段获得的标记来表示文档。矢量大小仅使用最常见的标记进行限制。此外,在我们的实现中,我们决定在向量的最后一个位置表示词汇外 (OOV) 标记。
什么是OOV?
未登录词就是训练时未出现,测试时出现了的单词。在自然语言处理或者文本处理的时候,我们通常会有一个字词库(vocabulary)。这个vocabulary要么是提前加载的,或者是自己定义的,或者是从当前数据集提取的。假设之后你有了另一个的数据集,这个数据集中有一些词并不在你现有的vocabulary里,我们就说这些词汇是Out-of-vocabulary,简称OOV。
fastText。fastText [1] 是一个类似于 word2vec 的词矢量化模型。fastText 的主要功能是利用每个标记的内部表示,使用有关其 n-gram 的信息。每个 n-gram 的表示由所有令牌共享,部分解决了 OOV。在我们的工作中,标记被矢量化,然后它们的平均值产生线向量,这些线向量用于生成最终的表示向量。
RoBERTa。RoBERTa[14]是一种基于transformer神经网络架构的语言模型。它是对 BERT [4] 的修改——作者删除了下一句话预测 (NSP) 目标,并决定使用更大的小批量和学习率进行训练。删除 NSP 目标可以在缺乏明确句子边界的文档中更好地表示标记——从我们的任务角度来看,这很重要。在我们的工作中,最终表示向量是样本中每条线的平均值,每条线都是标记表示的平均值。令牌表示是通过连接模型的最后四层来获得的(如原始 BERT 论文中所建议的那样)。模型的选择大小为“基本”,最大序列长度为 512,层数设置为 6,以及 12 个注意头和 15% 的掩蔽标记。
Part 4实验
工作重点是不利用特征工程的半监督方法的可解释性。这方面在文献中经常被忽略,但可解释性技术的使用在任何IDS的实施、维护和使用中都具有相当大的潜力。尽管如此,我们的目标是我们的结果不会比表中显示的结果更差。这个目标已经实现。
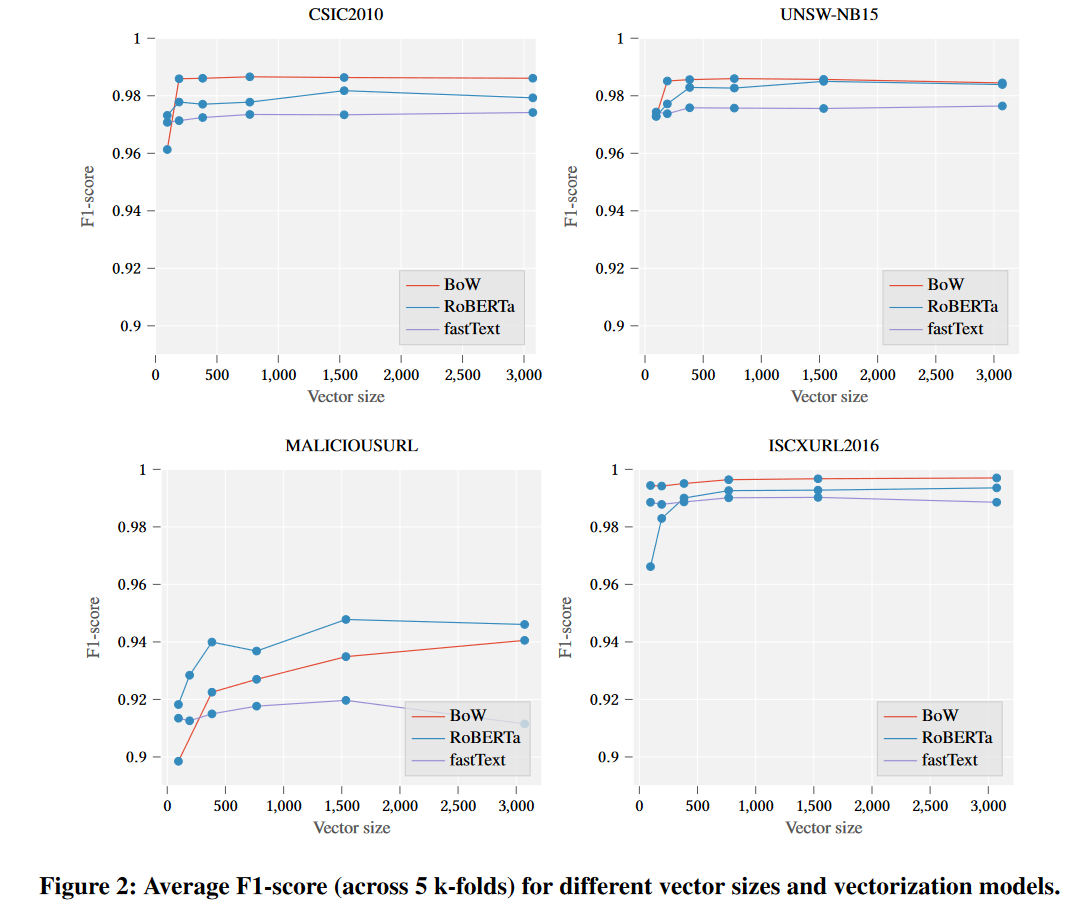
首先,我们使用不同的向量长度(即:96、192、384、768、1536、3072)多次训练矢量化模型(BoW、fastText、RoBERTa)。这个想法背后的主要动机是展示分类分数如何随着特征空间的维度而变化。
图 2 显示了被视为正类(跨越 5 个 k 倍)的异常类的平均 F1 分数与测试向量大小之间的关系。可以看出,最简单的矢量化方法(BoW)几乎总是能给我们带来最好的结果(尽管所有分类器都表现良好,但差异几乎不明显)。这证明数据集实际上很容易处理,并且分词器会产生有意义的(至少对于分类器而言)标记。请记住,此矢量化器不是上下文相关的(如 fastText 或 RoBERTa),因此只有“单词”的频率很重要。此外,向量大小的增加会导致模型未知值的减小(OOV – BoW 实现中的最后一个位置)。还值得注意的是,仅在正常样本上训练的矢量化器似乎也显示出高效率。
最容易解释的模型是 BoW,因为生成的向量中的每个位置都有意义——它以表格形式描述样本中给定标记的频率(因此,无需从语言模型中重新推断修改后的样本)。图 3 显示了分类器的前五个特征(基于使用 SHAP 库获得的重要性)。在纵轴上显示所选的标记(例如,在CSIC2010数据集中,重要的标记是:“OOV”、“%”、“/”、"<s>"、“modo”)。
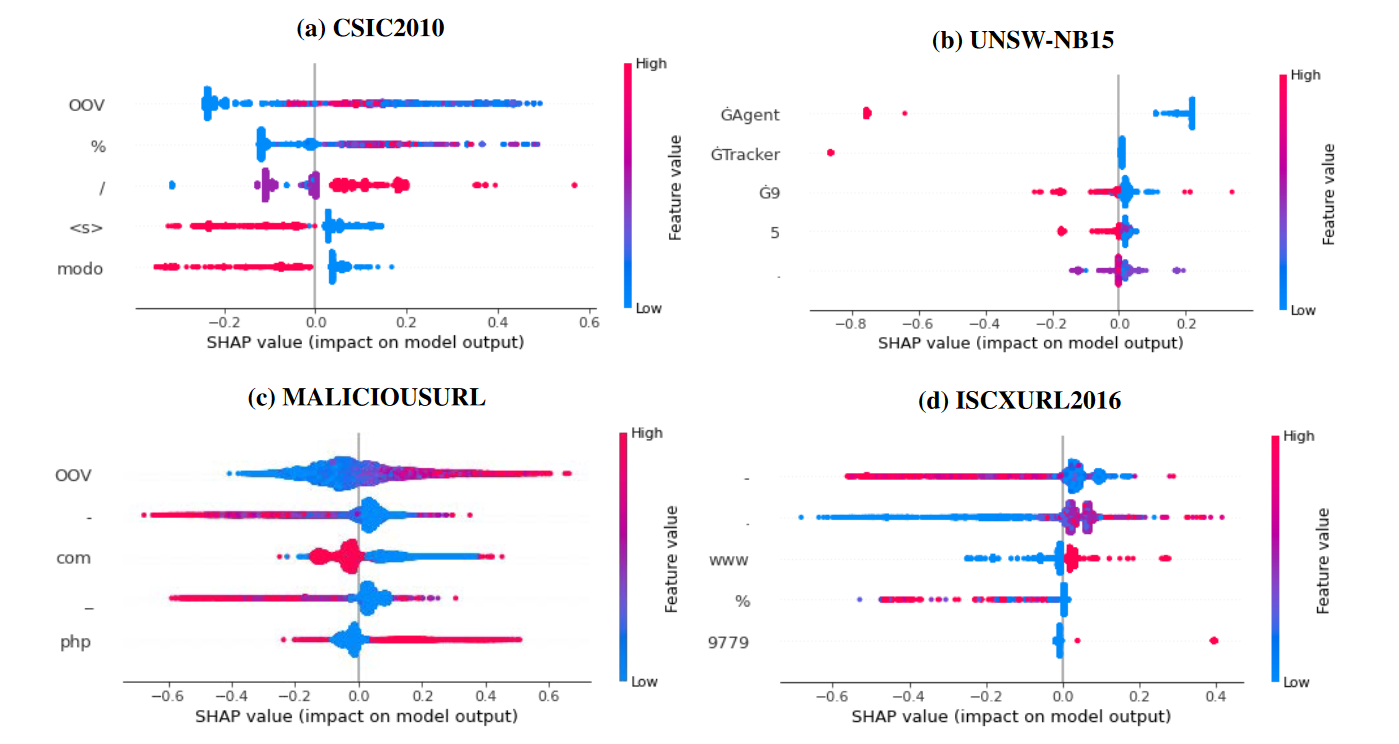
颜色编码给定标记的数量,与异常类的相关性由正 SHAP 值给出。可以很容易地看出,这些特征(标记)与模型输出密切相关。例如,如果“/”符号的数量很高(红色),则很可能是异常。为了进一步研究这些标记的重要性,我们决定构建一个仅基于它们的简单决策树。表 4 显示了我们的发现——尽管新构建的分类器无法正确地为 MALICIOUSURL 数据集分配标签,但这些数据集非常容易分类。请注意,事实上,这是 RoBERTa 矢量化器表现最好的唯一数据集。为了解释fastText或RoBERTa,我们使用了SHAP方法。该库能够通过屏蔽样本中的每个标记并重新计算分类概率来生成文本的特征重要性。由于这个过程很耗时,我们决定只分析每个数据集的一个子集。我们只展示了CSIC2010数据集的发现,但我们得出的结论也适用于所有其他数据集。首先,我们从CSIC2010数据集中选择一个随机异常样本,然后使用RoBERTa模型和欧几里得距离生成其邻域。如表5所示(请注意,样本相似,与注入攻击有关)。然后,我们计算了上述的 SHAP 值。表 6 显示了与攻击相关的标记的标准化总和。 RoBERTa 模型的结果比 BoW 的结果直观得多,因为该表包含明显与注入攻击相关的标记(例如“DROP”)。此外,得分最高的特征可以与百分比编码字符相关联,这些字符通常用于绕过输入过滤(input sanitation)。另一方面,BoW 方法的重要性分数向我们展示了我们已经建立的东西——如果“/”的数量很高(或者“Accept-Language”标头设置为“en”),那么样本很可能是异常。虽然它不是一个毫无意义的陈述,但此功能在很大程度上依赖于给定的数据集。这种方法还允许对任何样品中的重要区域进行着色——如图 4 所示。
样本“0”,其中包含使用 SHAP 获得的彩色相关标记。第一张图片(从上到下)与BoW模型相关,第二张图片与fastText相关,第三张图片与RoBERTa相关。红色表示应与异常相对应的标记,蓝色表示样本的“正常”部分
可以看出,在RoBERTa模型中,样本的整个异常部分以红色突出显示(查询的正常部分以蓝色标记,大部分是正确的)。fastText 和 BoW 模型都不是这种情况。在这一点上,我们表明,尽管 RoBERTa 没有得到最佳结果,但是分类所基于的特征是可解释的(分类并非纯粹基于数据中的强伪影)。与BoW一样,fastText模型获得的特征也是不可解释的(可能是由于多次平均操作)。
这里强调RoBERTa模型获得的效果虽然不是很好,但是结果都是可解释的。
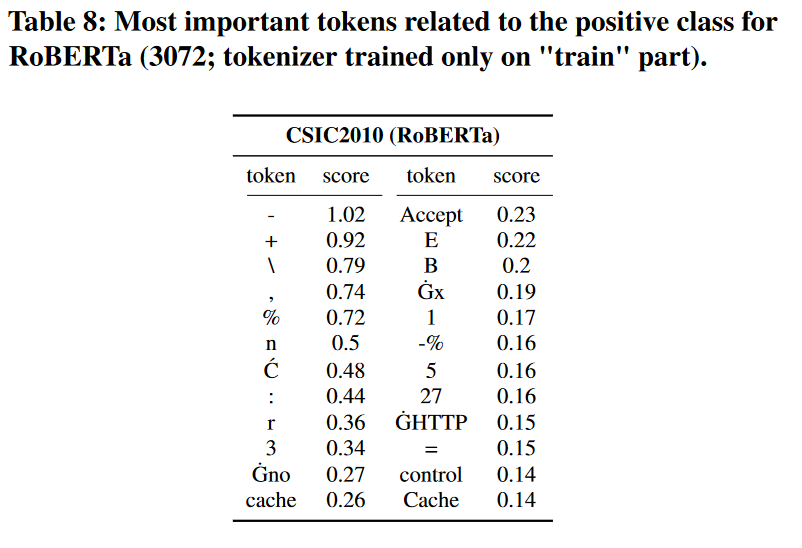
更详细讨论的一个主题是分词器训练过程。一般来说,如果标记是未知的,它们要么被分成更小的块,要么被替换为“〈unk〉”标记(这种情况很少见),因此,表 6 将更难解释(例如,单词“DROP”可以分解为单个字母)。为了证明这一点,我们只使用“训练”部分数据来训练我们的分词器,并重新运行我们的实验。表8给出了新获得的全局(与表6中相同的子集)重要性。尽管所呈现的令牌不再与攻击明确相关,但它们仍然比使用更好的字典(例如,百分比编码字符)的 BoW 方法更令人信服。针对先前引入样本(图 6)的新生成的局部重要性仍然有用(异常部分标记得很好),尽管分类器也考虑了它的其他部分。大多数分类分数保持稳定(表7),尽管RoBERTa模型的CSIC2010数据集的结果有所下降。
图6中原始选择的特征
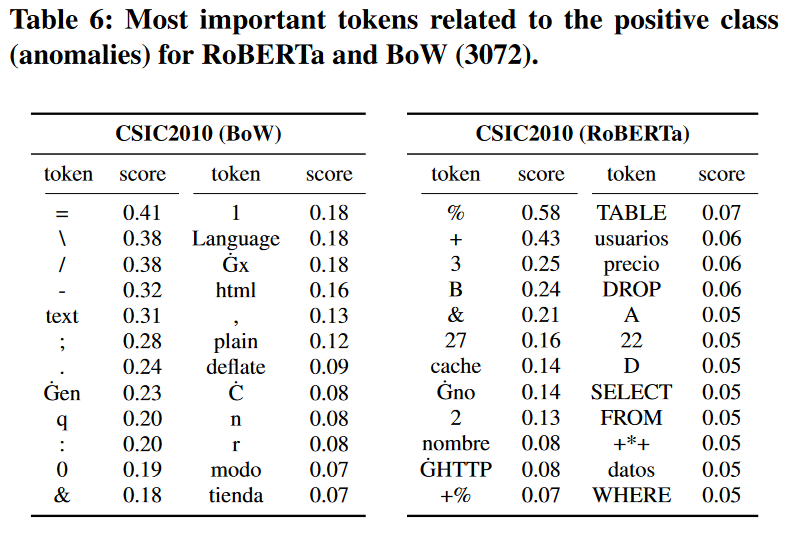
图8中的新特征
Part 5结果
我们得到的结果非常接近所有样本都被归类为异常时得到的结果。这表明,领域的快速变化可能会对分类产生可怕的后果。另一方面,我们还在真实世界的未标记数据(服务器日志)上测试了其中一个 RoBERTa 模型(和相关分类器),我们成功发现了 50 次新 Log4j 漏洞利用尝试中的 47 次(图 5)和许多更常见的攻击尝试(使用预测概率作为异常分数)。
对于四个数据集中的三个数据集,分类结果保持在同一水平,但是,CSIC2010问题为概念漂移带来了另一个方面。尽管 RoBERTa 解决了词汇量不足的问题,但从我们任务的角度来看,所有标记的知识仍然很重要。为了克服这个问题,需要一个更好的分词器。一种解决方案是使用其他数据源(例如 SQL 查询)对其进行训练。理想情况下,应该有公开可用的数据集,其中包含来自各个网络安全领域的文本样本。另一种选择是手动扩展词汇表或构建也可以利用 BBPE 的自定义分词器。由于HTTP请求结构良好,使用语法树似乎是一个很有前途的研究方向。然而,在现实中,字典中缺少特定的令牌不应该是一个常见的问题 - 新的攻击很少引入许多以前看不见的攻击(在我们的实验中,模型不知道单个恶意令牌,但成功标记了异常)。在现实世界中,嵌入的二进制数据(例如,会话 ID、cookie 的内容、base64)可能是一个更大的问题。为了保持解决方案的质量,可能应该将其替换为自定义令牌,特别是为此目的创建的令牌。仅就较差的分类结果而言,微调应该会增加它们,但全局解释仍然不清楚。请注意,微调意味着将分类器与语言模型一起训练。在我们的实验中,我们决定使用冻结表示,因为一个没有被引入异常概念的功能良好的语言模型,能在一个完全无监督的系统中带来了更大的潜力。这是我们未来的工作之一。
Part 6总结
我们认为,获得良好的矢量表示是构建正确 IDS 系统的关键。我们在研究中使用的分类器几乎无关紧要,因为获得的特征提供了精细的类别分离。请记住,我们以完全无监督的方式训练矢量化器。获得的模型可以很容易地应用于其他情况。因此,未来最重要的任务是准备一个基于各种来源的数据进行训练的RoBERTa模型。
我们相信,它可以像自然语言模型一样使用——作为任何其他主题相关任务的坚实基础。其次,我们想仅使用无监督的下游方法来检查这种模型的有效性,因为当前的方法需要标签来训练分类器。这也是我们没有将RoBERTa模型与分类器一起训练的原因之一(另一个是与其他模型进行公平的比较),尽管性能可能会提高。然而,展示尽可能高的结果并不是我们的目标(但我们给出的分数是令人满意的)。接下来,正如我们在上一节中所描述的,开发一个更好的分词器也很重要。最后,值得如何以增量方式训练模型(和分类器)。换句话说,如何提高准确性以及如何处理真实场景中的概念漂移。
一个只记录最真实学习网络安全历程的小木屋,最新文章会在公众号更新,欢迎各位师傅关注!
公众号名称:奇怪小木屋
博客园主页:
博客园-我记得https://www.cnblogs.com/Zyecho/
Recommend
-
151
404 页面不存在 404. 抱歉,您访问的资源不存在。 可能是网址有误,或者对应的内容被删除,或者处于私有状态。 代码改变世界,联系邮箱 [email protected]
-
34
猫:你这个喷嚏我记住了
-
77
一、 背景 网络测量是SDN发展的基础,是优化网络结构、改善网络服务质量、实现网络故障诊断和恢复的重要手段。在SDN网络中, 网络管理员通过网络测量及时了解、监控、掌握网络状态,调整网络的性能参数,及时发现可能...
-
15
问与答 - @npm - Windows 系统的电脑是 PC,那苹果系统的就不是 PC ?不是个人电脑了吗?Linux 系统的电脑就不是 PC ?不是个人电脑了吗?还是我记错了?
-
5
《你读我记》小程序reading keeper 85 | Posted by hhking on 2019-08-12上班通勤时间很长,在地铁上竟成了我看书最多的地方。看过很多书、小说,也忘了很多。小说 App 和 iR...
-
6
作者:the5fire | 标签: Django Django源码解析 ...
-
9
对象检测数据集和度量 以较少的偏差构建更大的数据集对于开发高级计算机视觉算法至关重要。在目标检测方面,在过去的10年里,已经发布了一些著名的数据集和基准。 数据集:Pascal VOC PASCAL视觉对象类(VOC)挑战赛(2005-2012)是早期计...
-
3
早期的黑暗知识 早期的目标检测(2000年以前)并没有遵循统一的检测理念。当时的探测器通常是基于低级和中级视觉设计的。 组件、形状和边缘 一些早期的研究人员将物体检测定义为物体成分、形状和轮廓之间的相似性度量。尽管最初的结果很...
-
6
BitWarden:妈妈再也不用担心我记不住密码啦 2019.05.15 |
-
7
Black Lotus警告异常复杂的ZuoRAT恶意软件已盯上大量路由器-51CTO.COM Black Lotus警告异常复杂的ZuoRAT恶意软件已盯上大量路由器 2022-06-30 13:18:23 Lumen Technologies 旗下 Bla...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK